一种基于多种检索模型的实时微博分类器的制作方法
本发明涉及微博检索分类器,具体为一种基于多种检索模型的实时微博分类器。
背景技术:
目前,不同的微博检索技术都是应用一种检索模型或者一种分类技术,且不具备实时性的特点。一般可以利用多种检索模型中的一种,比如:布尔模型,向量空间模型,概率模型,语言模型,词嵌入模型。分类技术也有很多种,比如:朴素贝叶斯分类,最近邻分类,逻辑回归分类,随机森林分类,决策树分类,梯度提升分类,支持向量机分类。
当前分类器都是基于一种检索模型,常见的是向量空间模型,采用TF-IDF加权,应用某种分类技术对微博进行分类,且没有针对微博实时性的特点。向量空间模型实现简单但是对训练集和测试集有限制,训练与测试模型时必须是针对相同的检索问题,如果出现不同的检索问题,则需要重新训练模型。不能针对不同用户,不同检索问题实现实时的检索。
技术实现要素:
本发明的目的在于提供一种基于多种检索模型的实时微博分类器,以解决上述背景技术中提出的问题。
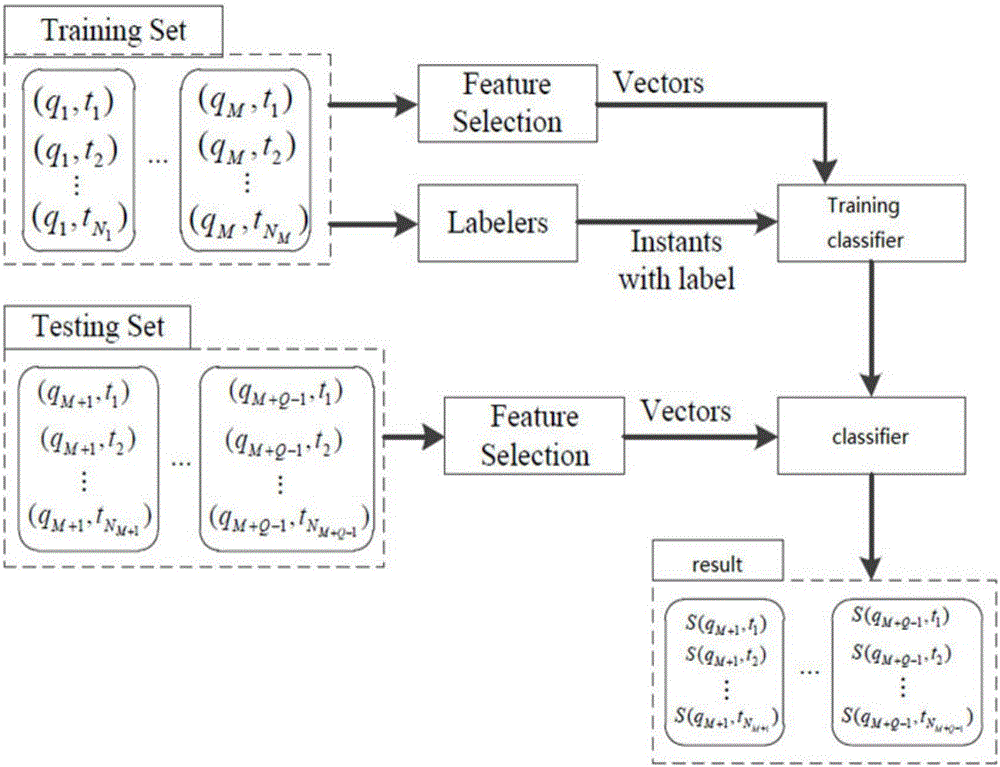
本发明的目的是通过下述技术方案予以实现:一种基于多种检索模型的实时微博分类器,其特征在于,包括:
(1)用户在指定网站下载指定电脑版微博检索软件或者手机版微博检索软件;
(2)用户在微博检索软件注册成功后,使用手机或者电脑向微博检索软件信息统计处理中心发送检索信息内容;
(3)信息统计处理中心接收到用户发出的检索内容后,首先采用布尔模型信息检索模型,文字、数字或者单词等用户查询的内容由其包含的单词集合来表示,两者的相似性则通过布尔代数运算来进行判定,随后得出初级检索结果。
在本发明一个较佳的实施例中,所述得出的初级检索结果后由处理器将用户输入的搜索内容编辑成由t维特征组成的一个向量,同时处理器将得出的初级检索结果编辑成若干个t维特征组成的若干个个向量,进而检索内容向量与初级检索结果向量相互对比,得出更进一步的匹配结果。
在本发明一个较佳的实施例中,所述随后系统根据进一步的匹配结果与谷歌搜索引擎向结合,将用户所需要搜索的内容与谷歌网实时进行相似度计算,得到不同的相似度计算结果,每种相似度作为一个高级特征,这样将一条博文转换为高级特征向量,还有一些其他高级特征包括词性统计,重合单词统计、博文客观度,博文极性等,再根据有标注的训练集对分类器进行训练,分类器选择了以上所有分类器进行测试,通过训练测试找出最佳分类器,分类特征综合话题、话题扩展和上述各种检索模型计算得出进一步结果。
在本发明一个较佳的实施例中,所述最后中央处理器将上述得出更进一步的匹配结果与谷歌搜索引擎分类得出的结果进行对比排除,进而得出具有实时意义的匹配结果。
在本发明一个较佳的实施例中,所述该微博分类器具有机械学习功能,能够在日常工作中进行自我学习,通过算法让机器自我减少误差,可以根据函数预测结果,通过有监督学习方式训练的分类器在性能具有优势。
本发明的有益效果是:该发明一种基于多种检索模型的实时微博分类器,通过使用这种方法,通过多种检索方式可以得出最佳分类器,由于分类器采用高级特征,可以对任意不同话题做检索,同时通过与谷歌检索可以得到最新的检索结果,实现排除陈旧信息的目的,同时使用多重检索方式,使检索效率和检索的准确率上升,进而增加检索分类器的工作量,同时可以实现实时检索的功能。
附图说明
图1为本发明整体示意图。
具体实施方式
下面结合具体实施方式进一步的说明,但是下文中的具体实施方式不应当做被理解为对本体发明的限制。本领域普通技术人员能够在本发明基础上显而易见地作出的各种改变和变化,应该均在发明的范围之内。
实施例
如图1所示:一种基于多种检索模型的实时微博分类器,包括:
(1)用户在指定网站下载指定电脑版微博检索软件或者手机版微博检索软件;
(2)用户在微博检索软件注册成功后,使用手机或者电脑向微博检索软件信息统计处理中心发送检索信息内容;
(3)信息统计处理中心接收到用户发出的检索内容后,首先采用布尔模型信息检索模型,文字、数字或者单词等用户查询的内容由其包含的单词集合来表示,两者的相似性则通过布尔代数运算来进行判定,随后得出初级检索结果。
所述得出的初级检索结果后由处理器将用户输入的搜索内容编辑成由t维特征组成的一个向量,同时处理器将得出的初级检索结果编辑成若干个t维特征组成的若干个个向量,进而检索内容向量与初级检索结果向量相互对比,得出更进一步的匹配结果。
所述随后系统根据进一步的匹配结果与谷歌搜索引擎向结合,将用户所需要搜索的内容与谷歌网实时进行相似度计算,得到不同的相似度计算结果,每种相似度作为一个高级特征,这样将一条博文转换为高级特征向量,还有一些其他高级特征包括词性统计,重合单词统计、博文客观度,博文极性等,再根据有标注的训练集对分类器进行训练,分类器选择了以上所有分类器进行测试,通过训练测试找出最佳分类器,分类特征综合话题、话题扩展和上述各种检索模型计算得出进一步结果。
所述后中央处理器将上述得出更进一步的匹配结果与谷歌搜索引擎分类得出的结果进行对比排除,进而得出具有实时意义的匹配结果。
所述该微博分类器具有机械学习功能,能够在日常工作中进行自我学习,通过算法让机器自我减少误差,可以根据函数预测结果,通过有监督学习方式训练的分类器在性能具有优势。
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!