一种艇用离心泵滚动轴承故障诊断方法与流程
本发明属于故障诊断的技术领域,特别涉及一种艇用离心泵滚动轴承故障诊断方法。
背景技术:
离心泵作为常用的液压泵,其在船舶、核电、水利机械中有着广泛的应用,尤其是对水下装备,作为疏排水和供油的重要设备,一旦离心泵发生故障,可能会对整个设备产生严重影响,甚至有带来设备报废的危险。滚动轴承作为离心泵的重要部件,其作用是支承离心泵主轴旋转,一旦滚动轴承发生故障,会造成主轴偏心、卡死等故障,从而引起离心泵的停机。据统计,离心泵故障的30%以上往往是由于滚动轴承故障产生的,因此针对离心泵的滚动滚动轴承进行诊断具有重要的意义。
由于轴承振动信号相对于电流、流量等缓变信号会表现出非线性非稳态的特点,并且振动信号中包含大量的、复杂的、难以提取的信息,利用振动信号进行诊断也是故障诊断研究中的难点,传统的基于傅里叶变换的信号分析方法只能处理线性和平稳信号,而滚动轴承信号的非平稳、非线性的特点,使得傅里叶变换存在一定的局限性。针对上述问题,专家学者发明了多种时频联合分析方法,如短时傅里叶变换(short-timefouriertransform,stft)、wigner-ville分布(wigner-villedistribution,wvd)、小波变换(wavelettransform,wt)、希尔伯特黄变换(hilbert-huangtransform,hht)等,但是stft的时频窗口是固定不可调的,wvd得到的时频分布图存在交叉项的干扰,wt母小波的选择和分解层数等不具有自适应性,并且需要提前获取分析信号的先验知识,hht作为一种新的自适应的时频分析方法,虽然实现了信号的自适应分解,但分解过程中会产生拟合误差、模态混叠和端点效应等,经验模态分解(empiricalmodedecomposition,emd)和局部均值分解(localmeandecomposition,lmd)也有计算量大、频率混淆和平滑次数的选择等问题。
技术实现要素:
本发明的目的在于针对上述技术需求而提供一种艇用离心泵滚动轴承故障诊断方法,通过局部特征尺度分解对降噪后的离心泵滚动轴承振动信号进行自适应分解得到若干个内禀尺度分量,然后提取各内禀尺度分量的样本熵作为监测振动信号的故障特征,最后通过构建多棵决策树来建立随机森林分类器对不同的离心泵滚动轴承故障进行诊断,从而获得诊断结果。
为了实现上述目的,本发明采用如下技术方案:一种艇用离心泵滚动轴承故障诊断方法,其特征在于:首先采用小波降噪的方法对振动信号进行降噪处理,然后采用局部特征尺度分解对降噪后的振动信号进行时频分析,获取各故障模式信号的内禀尺度分量,之后提取各内禀尺度分量的样本熵作为振动信号的故障特征,在故障诊断时,利用提取的各故障模式内禀尺度分量的样本熵对随机森林进行训练,并利用bagging的方式随机抽取训练样本对决策树进行训练,建立多棵决策树,然后利用训练好的随机森林对测试数据进行诊断测试,从而获得故障诊断结果。
按上述方案,所述小波降噪具体包括如下步骤:
s1)信号分解:选定小波函数和分解层数j,对信号进行j层小波分解;
s2)小波细节系数去噪:对于每一层小波,设定一个阀值,对细节系数进行阀值处理;
s3)信号重构:基于第j层的原始概貌系数和第1层到第j层修正的细节系数,进行信号的重构。
按上述方案,所述局部特征尺度分解具体包括如下步骤:
s1)定义内禀尺度分量:基于极值点的局部特征尺度参数,定义瞬时频率具有物理意义的单分量信号-内禀尺度分量,在满足此单分量信号瞬时频率具有物理意义的条件上提出了局部特征尺度分解,假设任何复杂的信号由不同的内禀尺度分量组成,任何两个内禀尺度分量之间相互独立,把任何一个信号x(t)分解为有限个内禀尺度分量之和;
s2)确定物理意义的条件:
(ⅰ)在信号的整个数据中,任意两个相邻的极大值与极小值之间要具有单调性;
(ⅱ)在信号的整个数据中,设所有极值为xk(k=1,2,…,m),对应的时刻为τk(k=1,2,…,m),m为极值点的个数,连接任意两个相邻的极大值点(或极小值点(τk,xk)、(τk+2,xk+2)),确定的直线为lk,见公式(1):
在二者之间的极值点相对应的时刻τk+1函数值,记为ak+1,由公式(2)得ak+1的值为:
让ak+1与xk+1的比值保持不变,一般情况下:
aak+1+(1-a)xk+1=0a∈(0,1)(3)
即要满足:
取
s3)局部特征尺度分解过程:
(ⅰ)确定x(t)所有极值xk及其相对应的时刻τk,k=1,2,…,m;
(ⅱ)根据公式(2)计算ak+1的值,上式(3)中的值一般取0.5,然后依据公式计(5)算出所有的值,
lk=aak+(1-a)xk(5);
(ⅲ)所有的l1,l1,…,lm由三次样条连接,得到均值曲线或基线bl1(t);
(ⅳ)将基线从原信号中分离出来,见公式(6),
h1(t)=x(t)-bl1(t)(6)
h1(t)满足条件(i)、(ii),即是一个isc分量,令isc1=h1(t);
(ⅴ)h1(t)不满足条件(i)、(ii),将h1(t)作为原始数据重复上述步骤,可以得到:
h11(t)=h1(t)-bl11(t)(7)
h11(t)不满足条件(i)、(ii),则重复上述步骤k次,直到h1k(t)满足isc分量条件,为第一个isc分量,记为isc1=h1k(t),对于判断满足isc分量的第二个条件,依据式(3),ak+1与xk+1之和不可能都等于0,采用标准偏差法作为终止判据来终止迭代循环,标准偏差值小于0.5即可得到理想的isc分量了。sd定义式如下:
(ⅵ)将isc1从原始信号中分离出来,见公式(9):
r1(t)=x(t)-isc1(9)
再将r1(t)作为原始数据重复上述步骤①~⑤,循环n次,直到剩余量rn(t)为一个单调函数,从而将x(t)分解为n个isc和一个单调函数的参与量之和,见公式(10):
s4)提取样本熵:已知序列{x(i)},其中i=1,2,…,n为{x(i)}第i点数据值,n为数据长度,
(ⅰ)选定m,组成m维矢量x(i):
x(i)=[x(i),x(i+1),…,x(i+m-1)](12)
式中,i=1,2,…,n-m+1,m为模式维数;
(ⅱ)定义矢量x(i)与x(j)之间的距离为两者所对应元素中的最大差值,用d[x(i),x(j)]表示,即:
d[x(i),x(j)]=max[|x(i+k)-x(j+k)|](13)
式中,k=1,2,…,m-1,i,j=1,2,…,n-m+1,i≠j;
(ⅲ)设定相似容限r的阈值,
统计d[x(i),x(j)]<r的数目,为num=d[x(i),x(j)]<r,
并将其余矢量总数n-m作比,记为
式中,i,j=1,2,…,n-m+1,i≠j
将n-m+1个
式中,为两个序列在下匹配个点的概率;
(ⅳ)将m增加到m+1,重复步骤(ⅰ)-(ⅲ),得:
式中,bm+1(r)为两个序列在r下匹配m+1个点的概率;
(ⅴ){x(i)}的样本熵为:
为有限值时,则样本熵的计算值为:
s5)随机森林对测试数据进行诊断测试:
假设随机森林是由k棵cart决策树组成的,假设产生第i棵决策树的函数表示为:fi(x,θi):x→y,i=1,2,…,k,其中x就是输入向量,θ是独立同分布的随机向量,随机森林可以表示为:f={f1,f2,…,fk},其中k为森林的规模;
用随机森林对样本数据分类,形式化的表示如下:
其中,i(·)是示性函数,它的取值范围是0和1,当括号中的条件成立时值为1,否则为0,随机森林就是选择投票最多的类别作为样本数据的最终类别。
本发明的有益效果是:1、提供一种艇用离心泵滚动轴承故障诊断方法,首先通过局部特征尺度分解对降噪后的离心泵滚动轴承振动信号进行自适应分解得到若干个内禀尺度分量,然后提取各内禀尺度分量的样本熵作为监测振动信号的故障特征,最后通过构建多棵决策树来建立随机森林分类器对不同的离心泵滚动轴承故障进行诊断,从而获得诊断结果,避免了信号分解过程中过包络、欠包络、端点效应、频率混淆等情况的发生,对信号的分析更加精确;2、利用样本熵刻画轴承时间序列的复杂度,弥补近似熵存在偏差的不足;3、利用集成学习的思想,生成多棵决策树,使故障诊断准确率相对于基分类器明显提高。
附图说明
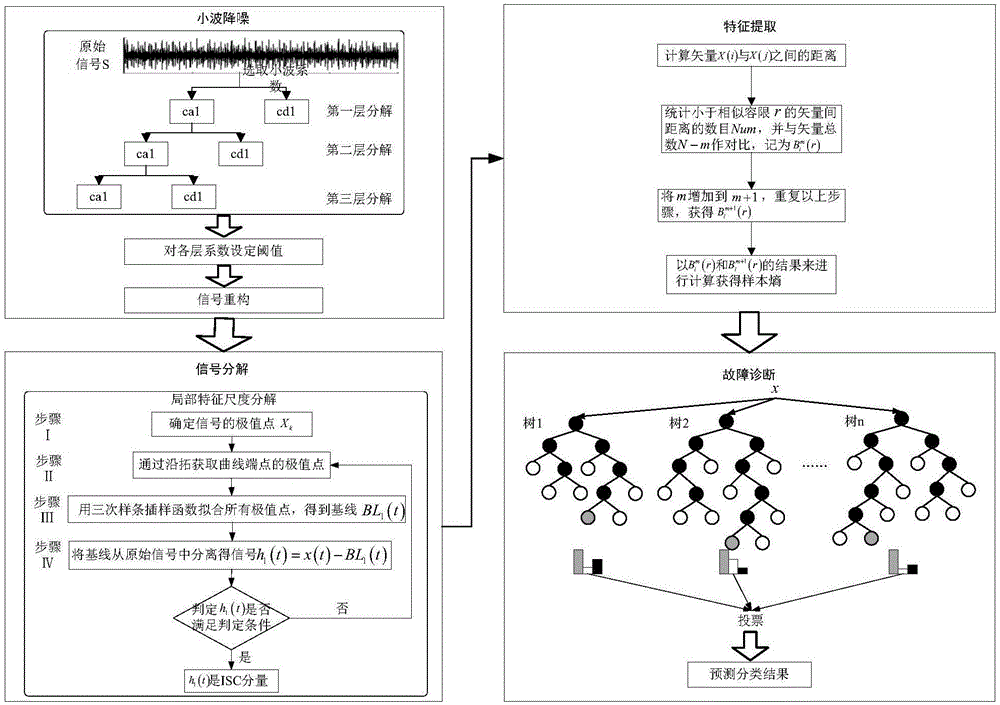
图1为本发明一个实施例的流程图。
图2为本发明一个实施例的二分类决策树示意图。
图3为本发明一个实施例的随机森林结构图。
图4为本发明一个实施例的各种故障模式的特征三维散点图。
图5为本发明一个实施例的随机森林诊断结果。
具体实施方式
现结合附图对本发明实施方式进行说明,本发明并不局限于下述实施例。
一种艇用离心泵滚动轴承故障诊断方法,其具体实施方式如图1所示,由于在振动信号采集的过程中,环境因素会对信号采集产生很大干扰,首先采用小波降噪的方法对振动信号进行降噪处理,然后采用局部特征尺度分解对降噪后的振动信号进行时频分析,获取各故障模式信号的isc分量,之后提取各isc分量的样本熵作为振动信号的故障特征,在故障诊断时,利用提取的各故障模式isc分量的样本熵对随机森林进行训练,并利用bagging的方式随机抽取训练样本对决策树进行训练,建立多棵决策树,然后利用训练好的随机森林对测试数据进行诊断测试,从而获得故障诊断结果。
所述的小波降噪方法,其特征主要包含如下步骤:
1、信号分解:选定小波函数和分解层数j,对信号进行j层小波分解;
2、小波细节系数去噪:对于每一层小波,设定一个阀值,对细节系数进行阀值处理;
3、信号重构:基于第j层的原始概貌系数和第1层到第j层修正的细节系数,进行信号的重构。
利用局部特征尺度分解对降噪后的振动信号进行自适应分解获取信号的多个内禀模态分量,所述的局部特征尺度分解,其特征主要包含:
a.内禀模态分量
局部特征尺度分解方法基于极值点的局部特征尺度参数,定义了一种瞬时频率具有物理意义的单分量信号-内禀尺度分量(intrinsicscalecomponent,isc),在满足此单分量信号瞬时频率具有物理意义的条件上提出了lcd方法。
lcd方法假设任何复杂的信号由不同的内禀尺度分量isc组成,任何两个isc分量之间相互独立,这样可以把任何一个信号x(t)分解为有限个isc分量之和,其中任何一个isc分量都要满足以下两个条件:
(i)在信号的整个数据中,任意两个相邻的极大值与极小值之间要具有单调性。
(ii)在信号的整个数据中,设所有极值为xk(k=1,2,…,m),对应的时刻为τk(k=1,2,…,m),m为极值点的个数,连接任意两个相邻的极大值点(或极小值点(τk,xk)、(τk+2,xk+2)),确定的直线为lk,见公式(1):
在二者之间的极值点相对应的时刻τk+1函数值,记为ak+1,由公式(2)得ak+1的值为:
让ak+1与xk+1的比值保持不变,一般情况下:
aak+1+(1-a)xk+1=0a∈(0,1)(3)
即要满足:
一般地,取
在满足以上(i)、(ii)两个条件下的单分量信号称之为内禀尺度分量,在每一时刻只有单一频率成分,这样以上两个条件保证了内禀尺度分量是具有物理意义的单分量信号。
b.局部特征尺度分解过程
局部特征尺度分解是一种自适应的时频处理方法,可以把非线性、非平稳的时变信号分解为一系列的内禀尺度分量和一个残余项,lcd方法的具体实现步骤如下:
①确定x(t)所有极值xk及其相对应的时刻τk,k=1,2,…,m。
②根据公式(2)计算ak+1的值,上式(3)中的值一般取0.5,然后依据公式计(5)算出所有的值。
lk=aak+(1-a)xk(5)
①所有的l1,l1,…,lm由三次样条连接,得到均值曲线或基线bl1(t)。
④将基线bl1(t)从原信号中分离出来,见公式(6)。
h1(t)=x(t)-bl1(t)(6)
如果h1(t)满足条件(i)、(ii),即是一个isc分量,令isc1=h1(t)。
⑤否则将h1(t)作为原始数据重复上述步骤,可以得到:
h11(t)=h1(t)-bl11(t)(7)
如果h11(t)仍不满足条件(i)、(ii),则重复上述步骤k次,直到h1k(t)满足isc分量条件,为第一个isc分量,记为isc1=h1k(t)。对于判断满足isc分量的第二个条件,依据式(3),ak+1与xk+1之和不可能都等于0,本发明采用标准偏差法(standarddeviation,简称sd)作为终止判据来终止迭代循环,sd小于0.5即可得到理想的isc分量了。sd定义式如下:
⑥将isc1从原始信号中分离出来,见公式(9):
r1(t)=x(t)-isc1(9)
再将r1(t)作为原始数据重复上述步骤①~⑤,循环n次,直到剩余量rn(t)为一个单调函数。从而可将x(t)分解为n个isc和一个单调函数的参与量之和,见公式(10):
所述的样本熵,其特征主要包含如下步骤:
已知序列{x(i)},其中i=1,2,…,n为{x(i)}第i点数据值,n为数据长度。
①首先选定m,组成m维矢量x(i):
x(i)=[x(i),x(i+1),…,x(i+m-1)](12)
式中,i=1,2,…,n-m+1,m为模式维数。
②定义矢量x(i)与x(j)之间的距离为两者所对应元素中的最大差值,用d[x(i),x(j)]表示,即:
d[x(i),x(j)]=max[|x(i+k)-x(j+k)|](13)
式中,k=1,2,…,m-1,i,j=1,2,…,n-m+1,i≠j。
③设定相似容限r的阈值,
统计d[x(i),x(j)]<r的数目,为num=d[x(i),x(j)]<r,
并将其余矢量总数n-m作比,记为
式中,i,j=1,2,…,n-m+1,i≠j
将n-m+1个
式中,bm(r)为两个序列在r下匹配m个点的概率。
②将m增加到m+1,重复步骤①-③,得:
式中,bm+1(r)为两个序列在r下匹配m+1个点的概率。
⑤{x(i)}的样本熵为:
若为有限值时,则样本熵的计算值为:
所述的随机森林分类器,是一种以决策树为基础学习器的集成学习算法,决策树是随机森林的基础分类器,其特征主要包含:
决策树是一种由节点和有向边构成的树状结构。训练时,在每一个非叶子节点针对某一属性进行分裂,迭代这一过程,直到每个叶子节点上的样本均处于单一的类别或者每个属性都被选择过为止。叶子节点代表分类的结果,从根节点到叶子节点的完整路径代表一种决策过程。决策树的算法本质上是节点如何进行分裂的方法,常见的有id3,c4.5p,cart等算法。决策树算法得到的结果一般是二叉树,少数情况下也存在非二叉树的情况。具体的算法步骤如下:
①构造该树的根节点,为全体训练样本的集合t;
②通过计算信息增益或基尼系数选择出t中区分度最高的属性,分割形成左子结点和右子节点;
③在剩余的属性空间中,针对每一个子节点中的样本,重复步骤②的过程,若满足以下条件之一则标记为叶子节点,此节点分裂结束。
a)该节点上所有样本都属于同一类
b)没有剩余的属性可以用以分裂
简单的决策树结构示意图如图2所示。
本发明中的随机森林(randomforest)是由一系列的cart决策树组合而成的,并由决策树进行投票决策,其结构如图3所示:
其中对训练集的随机性策略如下:
①训练样本的选择:利用bagging方法,重采样原始训练样本。
②特征属性的选择:分裂属性是在随机的子特征空间中选取的,其中子特征空间可以通过重采样或随机选取得到。
假设随机森林是由k棵cart决策树组成的,假设产生第i棵决策树的函数表示为:fi(x,θi):x→y,i=1,2,…,k,其中x就是输入向量,θ是独立同分布的随机向量,该向量是作用在训练样本的一种机制,比如对训练样本的有放回的随机重采样或是在决策树构建时每个分裂节点特征集的随机采样等。所以随机森林可以表示为:f={f1,f2,…,fk},其中k为森林的规模。
构造好随机森林学习器,最终是用随机森林对样本数据分类,而随机森林和其它大多数的集成学习算法一样,都采用了投票机制来确定类别,形式化的表示如下:
其中,i(·)是示性函数,它的取值范围是0和1,当括号中的条件成立时值为1,否则为0,随机森林就是选择投票最多的类别作为样本数据的最终类别。
实施例一
a.试验设置
本发明采用50cl-30a立式离心泵为试验对象进行故障诊断试验验证,该离心泵使用6306型滚动轴承,待测轴承为驱动端轴承。试验通过电火花加工技术对滚动轴承的内环、外环进行单点故障注入,注入故障切槽的宽度为1mm,利用砂轮对滚动体打磨进行单点故障注入,打磨深度为0.5mm。试验过程中控制离心泵组电机转速为2950r/min,试验数据通过构建的16通道的硬件采集系统进行采集,采样频率为20000hz,采样时间为每隔2.5小时采集1s振动数据,每种故障模式的振动数据共采集10次形成10组故障数据。
b.试验执行
本发明首先将采集到的每种故障模式的10组数据进行整合,将其按时间顺序组合成一个数据列,由于试验数据采集设备的采样率较高,超过滚动轴承故障频率的10倍以上,因此对原始数据直接进行处理将消耗大量计算资源,故对原始数据先进行降采样处理,通过降采样处理后数据采样频率改为10000hz,然后利用小波降噪的方法对信号进行降噪处理,提高所采集数据的信噪比。本方法中,选取db1小波函数进行强制降噪。
将每种故障模式数据进行分段处理,每段选取数据长度为10000个点,通过滑移取值获得100组数据,然后利用lcd对每段数据进行分解,分解层数设定为5层。
在将所有故障模式数据分解结束之后,提取lcd分解的每组信号的样本熵作为故障特征,生成每种故障模式的5维特征,正常状态、内环故障、滚动体故障、外环故障的故障特征分别为100组,为了更加直观的对所提取的特征进行表示,将4种故障模式的特征三维散点图绘制如图4所示。从图4中可以看出,滚动轴承不同故障模式的特征具有很好的可分性。
在提取滚动轴承故障特征之后,选取随机森林作为分类器进行故障诊断。分别赋予正常、内环故障、滚动体故障、外环故障数据特征标签为1、2、3、4,并随机抽取每种故障模式数据的30%作为训练数据,训练随机森林,随机森林中树的数量设定为100棵,在将随机森林训练完成之后,对所有故障数据的所以特征进行故障诊断,随机森林诊断结果与测试数据标签对比如图5所示。经过计算,400个特征中,只有1个内环故障特征诊断为滚动体故障,因此本发明对滚动轴承故障诊断准确率达到99.75%。
- 还没有人留言评论。精彩留言会获得点赞!