一种基于ZYNQ的侧扫声纳信号处理方法与流程
本发明属于数字信号处理及水下探测领域,涉及一种侧扫声纳的信号处理方法,具体地说是一种基于zynq的侧扫声纳信号处理方法。
背景技术:
侧扫声纳是一种利用回波测深原理来探测海底地貌和水下物体的海洋探测设备,又称旁侧声纳或海底地貌仪。侧扫声纳系统的换能器阵一般安装在水下拖曳体或是舰底的两侧,左右2条换能器线阵分别向水中倾斜发射声脉冲,照射出一片以换能器为中心的窄梯形海底,然后通过处理海底后向散射回波强度生成明暗不同的声纳图像。侧扫声纳在上位机组成图像之后,会受到水下复杂环境和设备本身的影响,相比于光学图像,其具有噪声污染重,对比度低等显著特点,需要后期结合数字图像处理技术进行改善。
侧扫声纳技术起源于上世纪50年代,经过半个多世纪的发展,已经从传统的单波束侧扫声纳延伸为测深侧扫声纳、多波束侧扫声纳等。但是目前这些侧扫声纳的信号处理系统不仅电路结构非常复杂,而且通用性和灵活性受到很大限制。随着科学技术的发展,对侧扫声纳的功能要求越来越高,比如需要实时上传声纳数据,因此需要利用最新的处理器实现这些功能要求。
对于脉冲体制的侧扫声纳来说,作用距离和距离分辨率是相互制约相互影响的矛盾关系。为了解决这个矛盾关系,提出了脉冲压缩理论,试图通过发射大时宽的信号来实现大的作用距离,在接收的时候将信号进行脉冲压缩处理,使宽脉冲变成窄脉冲以实现更好的距离分辨率。
zynq平台是美国xilinx公司推出的行业第一个可扩展处理平台(extensibleprocessingplatform,epp),是一款将双核cortex-a9arm处理器与低功耗可编程逻辑紧密集成在一起的全可编程片上系统(allprogrammablesoc),它将arm处理器的软件可编程能力及强大的控制能力与fpga的硬件可编程能力完美结合,能够实现可扩展、可定制、优化系统的功能,其应用主要涉及视频监控、汽车驾驶员辅助以及工业自动化等需要高速处理与计算性能的高端嵌入式领域。
zynq平台由ps与pl两部分组成,ps部分以双核cortex-a9arm处理器为核心,集成了内存控制器和大量的外设,提供了全面的操作系统支持。pl部分基于xilinx7系列fpga架构,采用28nm技术,具有低功耗、小型化、信号处理能力强大等特点,提供了通用硬件可编程资源,可用于扩展子系统,具有丰富的扩展能力。因此zynq平台受到了人们越来越多的关注,其应用也越来越广。
技术实现要素:
为了克服现有侧扫声纳信号处理方法的处理速度较慢、效率较低的不足,本发明提供了一种基于zynq的侧扫声纳信号处理方法,其可极大地提升信号处理速率和效率,从而缩短计算时间,提升效能。
本发明解决其技术问题所采用的技术方案是:
一种基于zynq的侧扫声纳信号处理方法,包括以下步骤:
1)在pl端利用fifo(firstinputfirstoutput,fifo)存储器、自定义dma读取数据模块、emio以及axi_hp接口等逻辑单元搭建读取ps端外部ddr3共享内存里的ad原始采集数据的通路;
2)在pl端利用fpga独有的并行计算的优势,利用ip核实现数字正交解调、低通滤波降采样、匹配滤波处理;
3)在pl端利用fifo(firstinputfirstoutput,fifo)存储器、自定义dma存储数据模块、pl-ps中断以及axi_hp接口逻辑单元搭建存储到ps端外部ddr3共享内存里的信号处理算法结果的通路。
进一步地,所述步骤1)中,ad原始采集数据的传输通道包括可编程逻辑单元pl与处理系统ps两部分,处理系统ps需要移植linux系统,通过千兆网口接收带宽为230.4mbps的ad原始采集数据,并且分别将左右两通道原始数据存储到相应的ddr3共享内存空间中;可编程逻辑单元包括fifo存储器,自定义dma数据读取模块、2位emio、axi_hp0通道、axi_hp1通道以及axi互联结构等,包括以下过程:
首先,当ps端将ad采集原始数据存储到外部ddr3共享内存空间中后,通过2位的emio发送上升沿触发信号给pl端,pl端根据触发信号开始获取ddr3共享内存中的数据x1(i,n),左通道原始数据存储空间的基地址是0x10000000,右通道原始数据存储空间的基地址是0x14000000;
为了避免axi4总线协议中读取数据的burst传输之间的空隙而造成读空数据,采用fifo储存器解决跨时钟域传输问题,以左通道为例,首先设置fifo的写数据和读数据的宽度都为32位,写数据和读数据的深度都为1024个,可编程空标志prog_empty阈值设置为200个数据,当触发读数据信号有效以及fifo中的数据个数小于可编程空标志阈值的时候,进行一次读数据操作也就是burst一次,直到读取到最后的地址结束读外部ddr数据操作,读取右通道ad采集原始数据步骤同上。
再进一步,所述步骤2)中,利用blockram、fir、multiplier、cordic实现数字正交解调、低通滤波降采样、匹配滤波器处理过程,步骤如下:
2.1)数字正交解调
取出fifo存储器中缓存的ad原始采集数据x1(i,n),因为选用的是24位ad芯片,所以要截取fifo存储器缓存数据的低24位作为x1(i,n),i=1表示左通道数据,i=2表示右通道数据,n为0、1、2……时间序列,正弦余弦函数为周期函数,做正交基带调制处理,公式表达式如下:
x2(i,n)=x1(i,n)×cos(-πn/2)+jx1(i,n)×sin(-πn/2)(1)
实部信号x2re(i,n)为ad原始采集数据和1、0、-1、0循环相乘的结果,虚部信号x2im(i,n)为ad原始采集数据和0、-1、0、1循环相乘的结果,变为复数形式,得到混频信号;
2.2)低通滤波降采样
每一路ad原始采集数据信号经过数字正交解调之后都可分出一路实部信号和一路虚部信号,fir数字低通滤波器ip核需要对2路实部信号和2路虚部信号进行同时滤波,滤波之后得到24位的实部信号x3re(i,n)和虚部信号x3im(i,n);
降采样的实现过程是将滤波之后出来的数据每10个提取一个,则降采样之后的信号如下式所示:
x4(i,n)=x3(i,n×10)(2)
2.3)匹配滤波处理
按照匹配滤波理论,首先根据发射信号形式产生匹配滤波系数y4(i,n),包含实部系数y4re(i,n)和虚部系数y4im(i,n),然后利用4个firip核、2个乘法器ip核、cordicip核实现卷积相乘,公式如下。
更进一步,所述步骤3)中,原始数据处理结果的传输通道包括可编程逻辑单元pl与处理系统ps两部分,处理系统ps需要移植linux系统,将左右两通道处理结果从外部ddr3共享内存空间中读取出来,通过千兆网口上传到pc机上进行实时成像,所述可编程逻辑单元包括fifo存储器,自定义dma数据存储模块、2个pl-ps中断、axi_hp2通道、axi_hp3通道以及axi互联结构等,包括以下过程:
首先,当pl端处理完两路数据之后,将原始数据处理结果x7(i,n)分别存储到外部ddr3响应的共享内存空间中后,通过2个pl-ps中断发送上升沿中断信号给ps端,ps端根据中断信号开始获取共享ddr3内存中的数据,左通道处理结果存储空间的基地址是0x18000000,右通道处理结果存储空间的基地址是0x1c000000;
因为算法处理结果是流水线型,而axi4总线存储数据需要有burst传输间隙,所以采用fifo储存器解决跨时钟域传输问题,首先fifo的写数据和读数据的宽度都为32位,写数据和读数据的深度都为1024个,可编程满标志prog_full阈值设置为266个数据,当fifo中的数据等于阈值的时候,进行一次写数据操作也就是burst传输一次,直到写到最后的地址结束写外部ddr数据操作,存储右通道原始数据处理结果步骤同上。
本发明的有益效果是:
1)本发明采用的是全球首款将双核cortex-a9arm处理器与可编程逻辑集成在一起的zynq7020系列处理器,利用arm运行linux操作系统从前端采集板通过千兆网口获得ad原始采集数据并将处理结果上传到pc机实时显示,利用fpga进行数字信号处理,可同时发挥软件可编程能力和硬件可编程能力,使整个系统能达到最优化。
2)本发明在pl端进行数字信号处理,可以进行多个乘法器的并行运算,pl端的运算速度较高;利用fir、blockram、乘法器以及cordic等ip核,大量重复运算可以在pl端进行处理,具有一定的应用价值。
附图说明
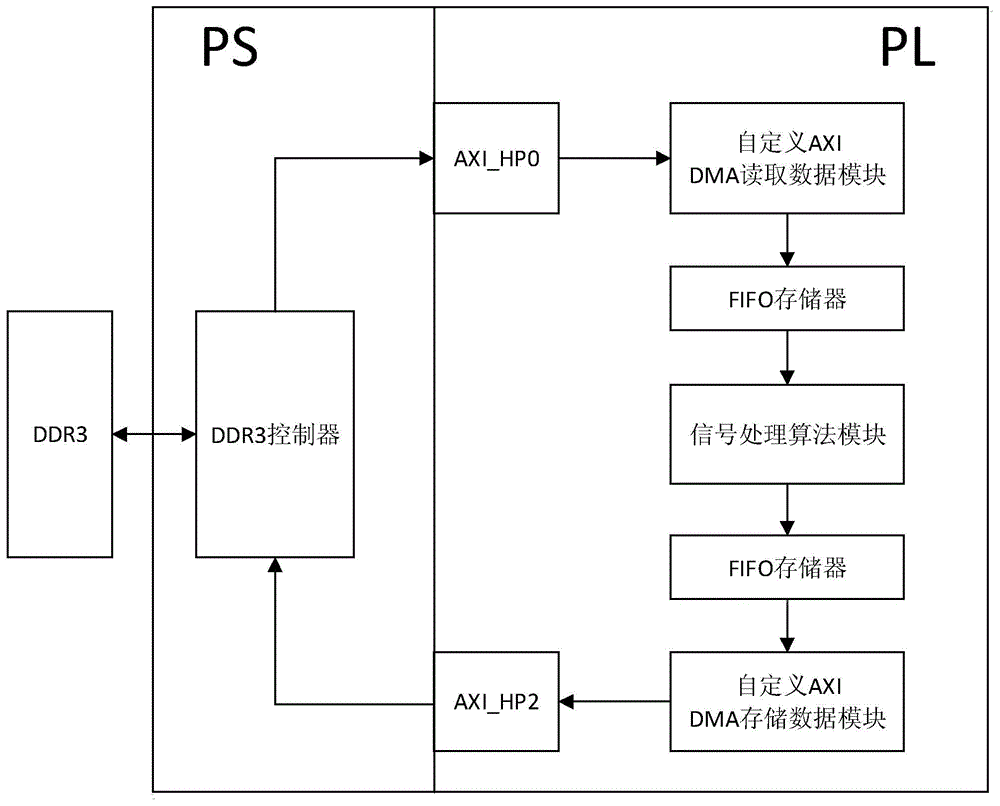
图1为基于zynq的侧扫声纳左通道信号处理方法的流程图;
图2为侧扫声纳左通道数据的信号处理过程图。
图3为数字正交解调计算结构图。
图4为低通滤波降采样计算结构图。
图5为匹配滤波处理计算结构图。
具体实施方式
为了使本发明的实现方法更加明了,下面结合附图进一步阐述本发明。
参照图1、图2、图3、图4和图5,一种基于zynq的侧扫声纳信号处理方法,包括以下步骤:
1)搭建ad原始采集数据的传输通道
ad原始采集数据的传输通道包括可编程逻辑单元pl与处理系统ps两部分。处理系统ps需要移植linux系统,通过千兆网口接收带宽为230.4mbps的ad原始采集数据,并且分别将左右两通道原始数据存储到相应的ddr3共享内存空间中。可编程逻辑单元包括fifo存储器,自定义dma数据读取模块、2位emio、axi_hp0通道、axi_hp1通道以及axi互联结构等,过程如下:
参照图1,首先当ps端将ad采集原始数据存储到外部ddr3共享内存空间中后,通过2位的emio发送上升沿触发信号给pl端,pl端根据触发信号开始获取ddr3共享内存中的数据x1(i,n)。左通道原始数据存储空间的基地址是0x10000000,右通道原始数据存储空间的基地址是0x14000000。
为了避免axi4总线协议中读取数据的burst之间的空隙造成读空数据,采用fifo储存器解决跨时钟域传输问题。以左通道为例,首先设置fifo的写数据和读数据的宽度都为32位,写数据和读数据的深度都为1024个,可编程空标志prog_empty阈值设置为200个数据,当触发读数据信号有效以及fifo中的数据个数小于可编程空标志阈值的时候,进行一次读数据操作也就是burst一次,直到读取到最后的地址结束读外部ddr数据操作。读取右通道ad采集原始数据步骤同上。
2)计算侧扫声纳左右两通道数据
参照图1、图2、图3、图4和图5,因为pl端可以实现侧扫声纳左右两通道数据并行计算,所以这里以计算侧扫声纳左通道数据为例,步骤如下:
2.1)数字正交解调
参照图2和图3,取出fifo存储器中缓存的ad原始采集数据x1(i,n),因为选用的是24位ad芯片,所以要截取fifo存储器缓存数据的低24位作为x1(i,n),i=1表示左通道数据,i=2表示右通道数据,n为0、1、2……时间序列,正弦余弦函数为周期函数,做正交基带调制处理,公式表达式如下。实部信号x2re(i,n)为ad原始采集数据和1、0、-1、0循环相乘的结果,虚部信号x2im(i,n)为ad原始采集数据和0、-1、0、1循环相乘的结果,变为复数形式,得到混频信号。
x2(i,n)=x1(i,n)×cos(-πn/2)+jx1(i,n)×sin(-πn/2)(1)
2.2)低通滤波降采样
参照图2和图4,每一路ad原始采集数据信号经过数字正交解调之后都可分出一路实部信号和一路虚部信号。fir数字低通滤波器ip核需要对2路实部信号和2路虚部信号进行同时滤波。滤波之后得到24位的实部信号x3re(i,n)和虚部信号x3im(i,n)。
降采样的实现过程是将滤波之后出来的数据每10个提取一个,则降采样之后的信号如下式所示。
x4(i,n)=x3(i,n×10)(2)
2.3)匹配滤波处理
参照图2和图5,按照匹配滤波理论,首先根据发射信号形式产生匹配滤波系数y4(i,n),包含实部系数y4re(i,n)和虚部系数y4im(i,n)。然后利用firip核实现卷积相乘,具体公式如下。
x7(i,n)=x4(i,n)*y4(i,n)(3)
利用4个firip核将降采样之后的24位实部信号x4re(i,n)和匹配滤波系数y4re(i,n)进行运算得到28位的x5rere(i,n),将降采样之后的24位实部信号x4re(i,n)和匹配滤波系数y4im(i,n)进行运算得到28位的x5reim(i,n);将降采样之后的24位虚部信号x4im(i,n)和匹配滤波系数y4re(i,n)进行运算得到28位的x5imre(i,n),将降采样之后的24位虚部信号x4im(i,n)和匹配滤波系数y4im(i,n)进行运算得到28位的x5imim(i,n)。将x5rere(i,n)和x5imim(i,n)相减得到实部数据x6re(i,n),将x5reim(i,n)和x5imre(i,n)相加得到虚部数据x6im(i,n)。
利用2个乘法器ip核分别对实部数据x6re(i,n)和虚部数据x6im(i,n)进行平方运算,然后相加,再利用cordicip核进行开平方运算得到最终32位的运算结果x7(i,n)。
3)搭建原始数据处理结果的传输通道
原始数据处理结果的传输通道包括可编程逻辑单元pl与处理系统ps两部分。处理系统ps需要移植linux系统,将左右两通道处理结果从外部ddr3共享内存空间中读取出来,通过千兆网口上传到pc机上进行实时成像。所述可编程逻辑单元包括fifo存储器,自定义dma数据存储模块、2个pl-ps中断、axi_hp2通道、axi_hp3通道以及axi互联结构等,过程如下:
参照图1,首先当pl端处理完两路数据之后,将原始数据处理结果x7(i,n)分别存储到外部ddr3响应的共享内存空间中后,通过2个pl-ps中断发送上升沿中断信号给ps端,ps端根据中断信号开始获取共享ddr3内存中的数据。左通道处理结果存储空间的基地址是0x18000000,右通道处理结果存储空间的基地址是0x1c000000。
因为算法处理结果是流水线型,而axi4总线存储数据需要有burst间隙,所以采用fifo储存器解决跨时钟域传输问题。首先fifo的写数据和读数据的宽度都为32位,写数据和读数据的深度都为1024个,可编程满标志prog_full阈值设置为266个数据,当fifo中的数据等于阈值的时候,进行一次写数据操作也就是burst传输一次,直到写到最后的地址结束写外部ddr数据操作。存储右通道原始数据处理结果步骤同上。
上述实施方式为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的修改、替代、组合、裁剪,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!