一种基于盲领域自适应的电子鼻漂移补偿方法
1.本发明属于电子鼻的气味识别领域,涉及一种基于盲领域自适应的电子鼻漂移补偿方法。
背景技术:
2.电子鼻又称为人工嗅觉系统,是一个由气体传感器阵列和模式识别算法组成的用于气体识别的系统。电子鼻能够模拟人类嗅觉系统以实现气体识别的关键在于其内部的气体传感器能够根据不同气体的特性产生对应的电信号响应,这些响应通过模式识别算法的处理最终转换为气体识别结果。
3.由于传感器老化或外界气体中毒等原因传感器会发生漂移现象。漂移会引起相同环境条件下传感器输出响应发生变化,使得同一外界条件下,发生漂移后的传感器采集到的样本特征与未发生漂移时所采集到的样本特征存在差异,进而使得识别算法精度下降。传感器漂移问题普遍存在于电子鼻系统中且无法避免。
4.近年来许多针对传感器漂移补偿的算法被提出,这些算法虽然能够在一定程度上实现传感器的漂移补偿,但它们在模型训练过程中均使用了漂移后的传感器输出响应即目标域样本,而在实际应用场景下,气体识别模型训练时传感器并未发生漂移,故仅能够使用未漂移的输出响应即源域样本进行训练。这种模型训练阶段无法使用目标域样本的领域自适应问题也被称为盲领域自适应问题。因此,如何在盲领域条件下完成目标域样本的有效自适应对电子鼻气体判别结果的正确性影响很大。基于盲领域自适应的电子鼻漂移补偿方法能够在不借助任何目标域样本的情况下实现传感器漂移补偿,在现实使用场景下更具有合理性。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于盲领域自适应的电子鼻漂移补偿方法,利用稀疏极限学习机自编码器的特征学习和稀疏极限学习机分类器的标签判别,在无目标域样本参与模型训练的情况下,通过自编码器获得目标域样本在源域空间下的表示,而后将源域与目标域内的相似特征增强以拉近域间距离,进而提高分类器判别的准确率,实现电子鼻漂移补偿。
6.为了说明简单,本说明书中规定了以下符号:
7.源域和目标域分别使用s和t来代表。源域样本由和表示,其中表示源域中第i个样本的特征向量,表示该样本对应的标签。目标域样本则使用和表示。n
s
和n
t
分别为源域样本和目标域样本的数量,隐藏层节点个数均为n
h
,d为样本的特征维数,c为样本中不同标签类别数。
8.本发明主要解决的技术问题是通过这样的技术方案实现的,它包括有以下步骤:
9.步骤1)构建稀疏极限学习机自编码器;
10.步骤2)构建稀疏极限学习机分类器;
11.步骤3)通过训练完成的稀疏极限学习机自编码器和稀疏极限学习机分类器实现漂移样本的正确分类,完成电子鼻的漂移补偿。
12.进一步,所述步骤1)具体包括以下步骤:
13.步骤11)将源域样本特征x
s
带入稀疏极限学习机自编码器的训练过程中,设定隐藏层节点数n
h
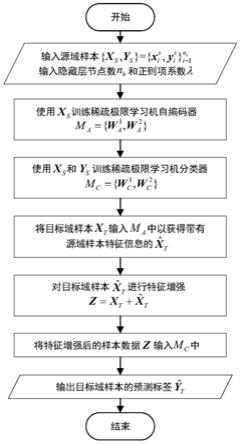
和正则项系数λ,其中n
s
为源域样本数,d为样本的特征维数;
14.步骤12)搭建三层神经网络模型,其中网络输入层与输出层的节点数设置为d,隐藏层节点数设置为n
h
,输出层目标设置为o
j
,n
h
>d,o
j
=x
s
,输入层与隐藏层间的输入权重矩阵表示为隐藏层与输出层间的输出权重矩阵为和也被称为编码器和解码器权重矩阵,j表示自编码器训练的阶段数;
15.步骤13)输入权重矩阵初始化为随机生成的正交矩阵,同时将其值固定,训练过程中不对该矩阵进行调整,而后通过源域样本x
s
完成第一阶段的自编码器训练以获得输出权重矩阵
16.步骤14)取出矩阵作为第二阶段训练的输入权重矩阵以传递第一阶段学习到的样本特征信息,即固定后再次带入源域样本x
s
进行第二阶段的自编码器训练以获得输出权重矩阵训练完毕后即可获得稀疏极限学习机自编码器模型其中所述步骤2)具体包括以下步骤:
17.步骤21)将源域样本特征x
s
和源域样本标签y
s
带入稀疏极限学习机分类器的训练过程中,其中同时带入样本中不同标签类别数c;
18.步骤22)构建三层神经网络模型,其中网络输入层节点数设置为d,隐藏层节点数设置为n
h
,输出层节点数设置为c,n
h
>c,输出目标设置为源域样本标签y
s
,输入层与隐藏层间的输入权重矩阵表示为w
i
,隐藏层与输出层间的输出权重矩阵为w
h
;
19.步骤23)输入权重矩阵w
i
初始化为稀疏极限学习机自编码器中的权重矩阵同时将其值固定,训练过程中不对该矩阵进行调整,而后通过源域样本x
s
和源域样本标签y
s
完成稀疏极限学习机分类器的训练,其中所述步骤3)具体包括以下步骤:
20.步骤31)通过m
a
获得目标域样本特征x
t
在源域空间下的表示其中n
t
为目标域样本数;
21.步骤32)使用x
t
和通过特征增强获得z,即其中
22.步骤33)将z作为网络输入带入到m
c
中以获得最终的分类预测结果其中
23.本发明的有益效果在于:本发明提供的一种基于盲领域自适应的电子鼻漂移补偿方法,该方法能够有效地获取源域样本的特征信息并通过特征增强将这些信息添加到目标域样本特征空间中,从而在没有目标域样本参与模型训练的情况下获得较好的分类精度,有效地实现了传感器的漂移补偿。
附图说明
24.为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
25.图1为本方法发明流程图;
26.图2为本方法模型训练过程框图;
27.图3为本方法模型预测过程框图。
具体实施方式
28.下面将结合附图,对本发明的实施例进行详细的描述。
29.本发明提供的一种基于盲领域自适应的电子鼻漂移补偿方法,如图1所示该方法包括以下步骤:
30.步骤1)使用x
s
训练稀疏极限学习机自编码器
31.进一步,步骤1)包括以下几个步骤:
32.步骤11)稀疏极限学习机自编码器的训练模型如图2所示,输入源域样本隐藏层节点数n
h
和正则化系数λ;
33.步骤12)在第一阶段模型训练中,将编码器权重矩阵随机初始化,为了使得输入特征更加有效的映射到随机子空间中,选择随机生成的正交矩阵来初始化此时隐藏层节点的输出为:
[0034][0035]
式中b表示隐藏层节点的偏置向量,g(
·
)表示激活函数relu,和b需满足正交条件:
[0036][0037]
为了保证投影的稀疏性,引入了l1范数对隐藏层节点的输出进行约束,λ表示正则项系数,故在第一阶段训练中,稀疏极限学习机自编码器的输出结果o1表示为:
[0038][0039]
步骤13)第一阶段训练结束后,选择使用相同的网络结构和输入样本进行第二阶
段训练以获得取出矩阵作为第二阶段训练的编码器权重参数来传递第一阶段学习到的样本特征信息,即模型训练过程与第一阶段相同,隐藏层输出和网络输出可分别由下述两式表示:
[0040][0041][0042]
此时稀疏极限学习机自编码器模型即构建完成,表示为其中其中
[0043]
步骤2)使用x
s
和y
s
训练稀疏极限学习机分类器
[0044]
进一步,步骤2)包括以下几个步骤:
[0045]
步骤21)稀疏极限学习机分类器的训练模型如图2所示,输入源域样本特征x
s
,源域样本标签y
s
和样本中不同标签类别数c,其中
[0046]
步骤22)将稀疏极限学习机自编码器的输入权重矩阵带入到稀疏极限学习机分类器的构建过程中,网络输入层节点数设置为d,隐藏层节点数设置为n
h
,输出层节点数设置为c,其中n
h
与稀疏极限学习机自编码器保持一致且n
h
>c,输出目标设置为源域样本标签y
s
,输入权重矩阵表示为w
i
,输出权重矩阵表示为w
h
,其中网络的隐藏层输出为:
[0047]
h(x
s
)=g(w
i
x
s
+b)
[0048]
由于selm-c的输出为样本标签,不像selm-ae的输出近似于输入样本的特征,故输出层的节点数设置为分类样本的类别数c,激活函数s(
·
)选择为softmax函数,分类器的输出表示为:
[0049]
o=s(h(x
s
)w
h
)
[0050]
此时稀疏极限学习机分类器模型即构建完成,表示为其中其中隐藏层输出表示为h
c
(x
s
)=h(x
s
)。
[0051]
步骤3)通过稀疏极限学习机自编码器的特征学习和稀疏极限学习机分类器的分类预测完成目标域样本的正确分类,进而实现电子鼻的漂移补偿;
[0052]
进一步,步骤3)包括以下几个步骤:
[0053]
步骤31)分类预测过程如图3所示,将目标域样本特征x
t
输入到m
a
中以获得目标域样本在源域空间下的表示
[0054][0055]
式中n
t
为目标域样本数;
[0056]
步骤32)使用对目标域样本x
t
进行特征增强以获得增强后的样本z:
[0057][0058]
步骤33)通过m
c
完成对样本数据z的分类预测,输出目标域样本的预测标签
[0059][0060]
即为漂移气体样本特征x
t
所对应的气体类别预测标签。
[0061]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过上述实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1