一种基于分布式计算的智能电网计量处理方法与流程
本发明涉及电力信息化技术领域,尤其涉及一种基于分布式计算的智能电网计量处理方法。
背景技术:
现阶段智能电网技术快速发展,智能计量分析技术也开始运用在智能电网中产生的计量数据中,但是我国智能电网的发展正从传统的计量方法向高科技计量方式上发展。在智能电网中现阶段的计量技术还存在着不足。
智能电网计量数据的采集设备智能化程度低,传统的电磁型互感器计量方式以串口传送计量结果还没有完全替代、新老计量设备更新换代不够完善,导致采集回来的计量数据的处理不够完善;同时在计量数据的自动化归档的过程中信息归档存在着信息缺失、数据不准确、数据不同步、传输不及时的缺点。
在对归档的计量数据进行处理时,现有的方法在处理海量的数据时存在无法批量处理数据、访问归档数据的时间过长等缺点,对海量的智能电网数据处理效率低,无法满足现阶段对电力信息化的要求。且现阶段大量的计量数据采集回来后却无法得到有效的利用。
另外,国内还有大量老式的电表在老旧小区中使用,如何通过低成本的高效率的将传统电表并入智能电网中,有着重要的意义,将这类老式电表以较低成本纳入到智能化的智能电网中有利于降低抄表人员的投入,加速电网智能化联网。
技术实现要素:
本发明的目的是提供一种基于分布式计算的智能电网计量处理方法。
为了实现本发明目的,本发明提供一种基于分布式计算的智能电网计量处理方法,包括:
获取电网计量数据;
采用基于hdfs的分布式运行数据存储方式对电网计量数据进行存储;
采用分布式计算框架spark的计量数据抽取快速模式;
采用分布式计算框架spark的迭代计算方式,将抽取出来的电网计量数据转化成为rdd抽象数据,再对rdd抽象数据进行迭代计算;采用airflow的数据计算调度方法,对迭代计算后的数据进行调度计算,将调度计算后的数据存储到hdfs分布式文件系统中。
更进一步的方案是,采用基于hdfs的分布式运行数据存储方式对电网计量数据进行存储的步骤,包括:
构建hdfs分布式文件存储系统,hdfs分布式文件存储系统包含namenode节点和多个datanode节点;
利用mobus通信协议在namenode节点和多个datanode节点之间进行对电网计量数据进行存储读写操作。
更进一步的方案是,采用分布式计算框架spark的迭代计算方式对rdd抽象数据进行迭代计算的步骤,包括:
通过分布式计算框架spark的调度器接口dagscheduler根据抽象数据rdd组成有向无环图dag,并分解成多个调度阶段;
通过分布式计算框架spark的调度器接口dagscheduler将调度阶段分解成任务集,并将任务集提交到work节点中进行运算。
本发明的有益效果是,基于智能电网海量的电网计量数据,采用基于hdfs的分布式运行数据存储方式对计量数据进行存储,再采用分布式计算框架spark的计量数据抽取快速模式和迭代计算方式,有效缩短访问时间、提高数据处理效率,再把处理后的数据传送到airflow中进行数据计算调度,实现数据的批量处理、缩短数据的访问时间,提高访问效率和处理效率,本案在对智能电网计量数据的处理上最大的特点在数据的传输过程中保证数据的完整性、准确性、同步性,在处理过程中缩短访问时间、提高数据处理效率,有助于电力信息化的发展。
附图说明
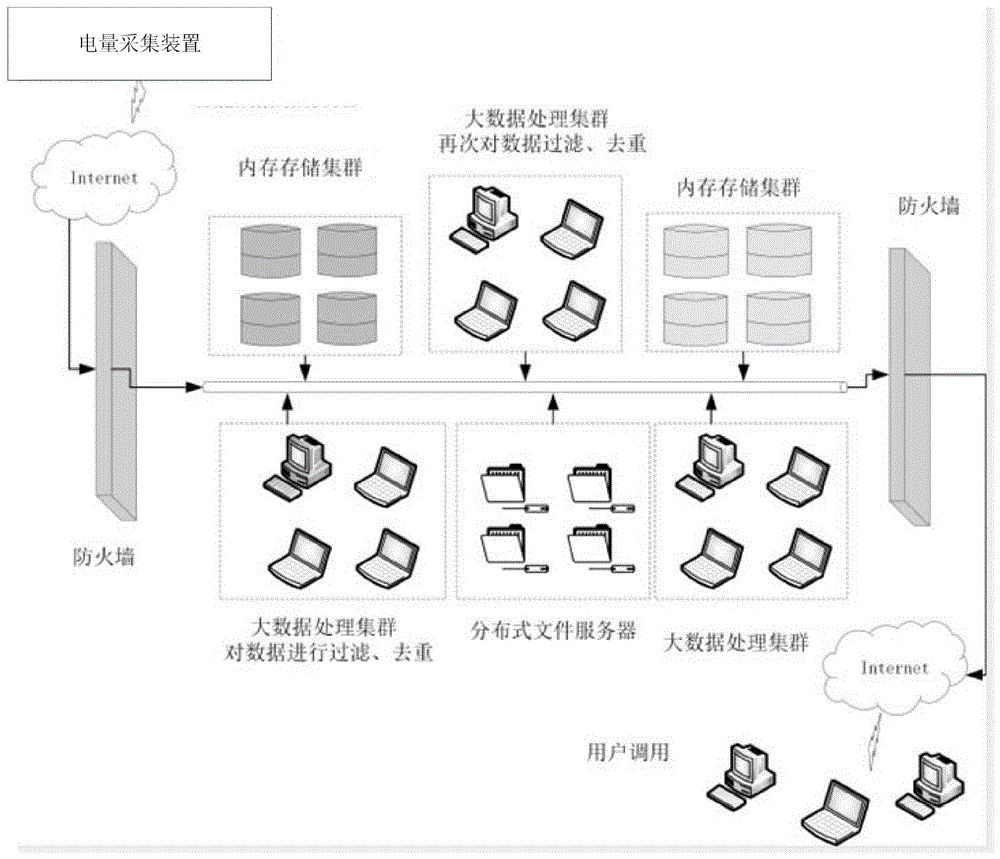
图1是本发明智能云采集系统实施例的系统框图。
图2是本发明智能云采集系统实施例中电量采集装置的正视图。
图3是本发明智能云采集系统实施例中电量采集装置的侧视图。
图4是本发明智能电网计量处理方法实施例的流程图。
图5是本发明智能电网计量处理方法实施例中hdfs体系结构图
图6是本发明智能电网计量处理方法实施例中hbase处理机制原理图。
图7是本发明智能电网计量处理方法实施例中hdfs系统数据列表时序图。
图8是本发明智能电网计量处理方法实施例中spark运行框架。
图9是本发明智能电网计量处理方法实施例中airflow基本框架图。
图10是本发明智能电网计量处理方法实施例中airflow的数据计算调度步骤的流程图。
以下结合附图及实施例对本发明作进一步说明。
具体实施方式
参照图1至图3,智能云采集系统包括多个电量采集装置和服务器群组,多个电量采集装置分散布置在各地的居民楼或商用楼,服务器群组包括多个服务器、多个内侧存储装置集群和分布式文件服务器,其通过mobus通信协议连接。
电量采集装置1包括电表箱、水平移动组件、竖直移动组件和采集组件23,电表箱包括箱体11和设置在箱体11内的多个电表12,多个电表12呈矩阵排列在箱体11内。水平移动组件包括两个水平支撑架211、水平驱动电机212、第一螺杆213、第一导杆214和水平移动滑块215,两个水平支撑架211分别设置在箱体11的顶部的水平两端上,第一导杆214沿水平方向固定设置在两个水平支撑架211之间,第一螺杆213沿水平布置并可转动地设置在水平支撑架211上,第一螺杆213通过轴承与水平支撑架211连接,水平驱动电机212设置在第一螺杆213的轴向端并与第一螺杆213的轴向端驱动连接,水平驱动电机212驱动第一螺杆213绕其轴线转动,水平移动滑块215贯穿设置有第一驱动螺孔和第一定位孔,第一螺杆213穿过第一驱动螺孔并与第一驱动螺孔啮合,第一导杆214沿水平方向布置并穿过第一定位孔,使得在水平驱动电机212的旋转驱动作用下,带动第一螺杆213的转动,继而驱动水平移动滑块215沿水平方向移动。
竖直移动组件包括竖直驱动电机223、第二螺杆221、第二导杆222和竖直移动滑块224,第二螺杆221沿竖直方向布置并可转动地设置在水平移动滑块215上,竖直驱动电机223设置在水平移动滑块215上,竖直驱动电机223与第二螺杆221的轴向端连接并驱动第二螺杆221绕其轴线转动,第二螺杆221通过轴承与水平移动滑块215连接,竖直移动滑块224贯穿设置有第二驱动螺孔和第二定位孔,第二螺杆221穿过第二驱动螺孔并与第二驱动螺孔啮合,第二导杆222沿竖直方向布置并穿过第二定位孔,定位架237设置在第二螺杆221相对于竖直驱动电机223的轴向端处,第二螺杆221可转动地设置在定位架237上,第二导杆222固定连接水平移动滑块215和定位架237之间。在竖直驱动电机223的旋转驱动作用下,带动第二螺杆221的转动,继而驱动竖直移动滑块224沿竖直方向移动。
采集组件23包括机壳231、摄像头232和主控电路板235,摄像头232、主控电路板235均设置在机壳231上,机壳231设置在竖直移动滑块224上,摄像头232和电源模块分别与主控电路板235连接,机壳231上设置有凸透镜233,多个led灯234位于凸透镜233的外周,摄像头232与凸透镜233相对。
主控电路板235通过数据线236和数据线216分别与竖直驱动电机223、水平驱动电机212连接,数据线236和数据线216分别设置有拖链,通过驱动采集组件23能够沿水平方向和竖直方向移动,led灯234朝向电表12补光照明,摄像头232朝向电表12设置,摄像头232透过凸透镜233可对电表12的读数进行拍摄,继而获取原始电网计量数据,由于主控电路板235上设置有远程通讯模块,继而主控电路板235能够通过远程通讯模块与多个服务器连接。
参照图4,本案提供的基于分布式计算的智能电网计量处理方法包括,首先执行步骤s1,通过上述电量采集装置1的智能电网计量设备采集原始计量数据,通过图像识别可对拍摄到的原始电网计量图像数据识别,继而能够获取电网计量数据。
随后执行步骤s2,采用基于hdfs的分布式运行数据存储方式对所述电网计量数据进行存储,hadoop基于google提出的googlefilesystem文件系统模型实现了一个分布式文件系统hdfs。hdfs一般部署在若干普通的电脑主机上,保证集群中如果只有一个或少数几个节点出现故障,整个系统仍然可以正常工作,正常发挥分布式文件系统的体系结构。同时,拥有较高的数据访问能量,非常适合目前海量数据的处理。hdfs提供类似于通用的文件系统的操作接口以及表现形式,用户可以进行文件相关操作,例如重新命名、移动、删除和创建。
参照图5,hdfs分布式文件系统采用主从结构分布,在系统中主机上运行独一无二的namenode,每一个节点上都可以运行数据节点,namenode和多个datanode组成一个完整的系统。其中namenode作为唯一的主机,对这个系统的命名具有决策性,解析客户端对文件的访问操作,如添加、删除文件、读取文件等操作。datanode进行管理数据。在datanode中数据是以块(block)的形式进行存储的,而这些block通过namenode中的记录可以组成一个文件或者目录,最关键的namenode建立一个备份节点第二名称节点(secondarynamenode),以防namenode在运行过程中出现故障。
namenode负责存储hdfs所有数据的元数据,包括文件信息、每一个文件对应的文件及文件块在datanode中的信息。当客户端对系统进行操作时,只需要获取或更新namenode上的元数据,而真正的数据操作是与对应datanode进行交互的,这样就大大降低了namenode的工作量和网络压力。
hdfs体系结构图中,namenode,datanode和client之间使用tcp/ip进行可靠通信,程序内部使用远程过程调用实现。
在读操作的过程中,client向namenode请求相应文件的元信息,然后去读取相应datanode中的相应块;
在读写操作的过程中,client利用mobus通信协议在所述namenode节点和多个所述datanode节点之间进行对所述电网计量数据进行存储读写操作时,其先缓存这些需要写入的数据,放入缓存文件夹中,当缓存的数据达到预先配置的块大小时,client向namenode发出写入文件信息,namenode添加相应元数据,然后反馈datanode需要存放新数据的位置,即datanode信息及模块信息,然后client将数据写入namenode指定的位置。
hdfs通过采取了冗余策略来保证系统的可靠性和可用性。hdfs中文件会根据需要保存多个副本,一般默认为三个,分别分配在不同的节点上,由近及远,分别为本节点,同一机架中的另一个节点,另一个不同的机架中的某个节点。
参照图6,hbase是一个分布式的、面向列的分布式数据库,是现阶段大数据领域存储数据的首选工具,hbase构建在hadoop的hdfs文件系统之上,hbase是一种hadoop数据库,经常被描述为一种稀疏的、分布式的、持久化的、多维有序映射,它基于行键、列键以及时间戳建立索引关系,是一个可以随机访问的存储和检索数据平台。hbase不限制存储的数据的种类,不强调数据之间的关系,hbase被设计为一个服务器集群上运行,可以相应地横向扩展。被广泛的应用在互联网搜索、信息的交互、抓取增量数据等领域,其中抓取增量数据功能可以实现抓取监控指标、抓取用户交互数据、遥测技术、定向投放广告等。
hdfs系统数据列表子模在由于数据处理模块涉及到的类过多,在进行类图设计时,将接口类与对应的实现类合二为一,以接口类的名字命名,表示一个类对象,hdfs系统数据列表时序图如图7所示。
(1)getdirectoryfromhdfs():遍历hdfs上的文件和目录,获取文件和目录的详细信息hdfslist,其中包括所属用户、文件大小、创建日期等信息;
(2)refresh():重新加载hdfs文件列表;
(3)createfile(dst,contents):创建新文件,dst表示路径,contents为内容;
(4)mkdir(path):新建目录,path为所在的路径;
(5)deletefile(filepath):根据文件路径删除文件;
(6)upload(src,dst):上传本地文件到hdfs系统上,src表示文件所在本地路径,dst表示hdfs系统上的目标路径;
(7)download(src,dst):下载hdfs上的文件到本地,src表示hdfs系统上的文件所在的路径,dst表示本地的目标路径;
(8)renamefile(fromfilename,tofilename):文件重命名,fromfilename表示修改前文件名,tofilename表示修改后文件名;
(9)readfile(filepath):根据文件路径显示文件内容,filepath表示文件路径;
(10)iffileexits(filename):根据文件名查看hdfs系统上的某个文件是否存在,filename表示文件名。
由上步骤可以得出在系统中计量数据在hdfs系统上的处理过程,为spark分布式计算框架对智能电网计量设备采集回来的计量数据的计算做进一步的处理,使得在spark上计算出来的结果更加具有效率。
随后执行步骤s3,采用分布式计算框架spark的计量数据抽取快速模式,在spark的运行中,主要有三种模式:sparkonyarn模式、standalone模式、sparkonmesos模式。其中,standalone模式是spark自带的资源管理模式,可以独立进行部署在spark集群内部实现资源的管理和容错机制;sparkonyarn模型是利用yarn来管理资源,每个executor运行在yarn容器内;sparkonmesos模式是利用mesos来进行资源管理。sparkonyarn和sparkonmesos这两种部署模式使用外部资源管理组件进行资源管理,这两种模式都是在standalone模式的基础上进行开发的,实现和hadoop系统的兼容,实现资源的统以管理。
在spark集群中采用standalone模式部署具有3个节点的集群,节点名称分别为a,b,c,其中a节点为master节点,其余为工作节点。如图8所示,在a节点通过spark-submit提交spark任务,集群会在a节点上创建一个主进程,该进程负责作业的资源分配,dag的生成以及任务调度,该进程为driver进程。而任务被driver分配到worker节点上,该节点是任务执行的地方,创建作业执行的进程,该进程为executor进程。
在运行架构中主要包含的组件有:(1)数据存储组件:spark用hdfs文件系统存储数据,它可用于存储任何兼容于hadoop的数据源,包括hdfs、hbase等。(2)计算机接口组件:应用开发者可以利用标准的api接口创建基于spark的应用,spark的应用接口可以适用于java、python等程序设计语言。(3)资源管理器组件:spark既可以部署在一个单独的服务器上,也可以部署在像mesos分布式计算框架之上。
随后执行步骤s4,采用分布式计算框架spark的迭代计算方式,将抽取出来的电网计量数据转化成为rdd抽象数据,再对rdd抽象数据进行迭代计算。
具体包括如下步骤,首先,hdfs分布式文件系统中存储的智能电网电能计量数据加载到分布式计算框架spark中进行数据提取,把经过筛选后的数据进行迭代计算。
随后,在driver中首先把加载的计量数据进行抽象化转换成rdd抽象数据,并向任务管理器注册信息,并申请计算资源的分配。
然后,通过spark中高级的调度器接口dagscheduler将抽象数据rdd和他们之间的边组成一个有向无环图dag进行分解成不同类型的调度阶段(stage)。
下一步,通过spark中高级的调度器接口dagscheduler将不同的调度阶段stage分解成任务集taskset,并将任务集taskset提交到work节点中进行执行运算。
随后,在work节点执行前会向driver进程中进行注册,注册完成后并处在就绪状态,可以执行任务task。
随后,work节点在执行任务的过程中会向任务管理器反馈该节点执行任务的情况,同时接受任务管理器进行数据的处理情况的监督,保证在数据执行的过成中,work节点充分利用。
最后,在对分布式文件存储系统内的计量数据进行处理完成后,任务管理器把driver注册的信息进行消除,以备下次计算使用。
随后执行步骤s5,采用airflow的数据计算调度方法,对迭代计算后的数据进行调度计算,将调度计算后的数据存储到hdfs分布式文件系统中。参照图9,在airflow架构中集群的角色包括如下:
webserver:提供web端服务,以及会定时生成子进程去扫描对应目录下的dag,并更新数据库。
scheduler:生成调度服务,根据dag生成任务,并提交到消息中间件对列中(redis或rabbitmq)。
celeryworker:分布在不同的机器上,作为任务真正的执行节点。通过监听消息中间件:redis或rabbitmq领取任务,celery是列队机制,一般情况下,celery是由broker(代理)和resultbackend(结果后端)两个组件组成,broker负责存储执行的命令,resultbackend负责存储完成执行命令的状态信息。
airflower:监控worker进程的存活性,启动或关闭worker进程,查看运行的task。
exector:执行操作。
参照图10,为了充分利用智能电网的计量数据,设计基于airflow的数据计算调度方法,对经过spark迭代计算后的数据进行调度运用起来,在这个过程充分利用airflow的优点,提高对历史数据的处理效率。
基于airflow的数据计算调度方法的具体工作步骤为:
首先,开始任务,生成任务列表并经过分布式计算框架spark处理,得到迭代计算后的数据。
随后,在开始任务后,进行schedule安排定时服务,dag生成定义任务和依赖与schedule扫描定时服务的同时输入至所有任务存储在数据库中判断是否满足定时条件,当满足定时条件时进行解析模型;
然后,当导出经过spark分布式计算框架迭代后的计量数据成功时,经过airflow向下进行数据计算调度计算,同时将计算过的数据存储到hdfs分布式文件系统中,并且从hdfs系统获取数据,当导出原始计量数据失败时,定时任务失败,同时任务日志记录存储进入源数据库中;
由上可见,本发明基于hdfs分布式文件系统,设计了计量数据的存储方法,改善对现有海量的计量数据存储不足的问题和基于分布式计算方法,利用分布式计算框架spark的计量数据抽取快速模式,加强对计量数据管理,提高计量档案信息的完整性、保证数据在传输过程中的同步性、准确性、及时性;
在对归档的计量数据进行处理时,现有的方法在处理海量的数据时存在的缺点有无法批量处理数据、访问的归档数据的时间过长等缺点,对海量的智能数据的处理效率低,无法满足现阶段对电力信息化的要求。针对这些问题本发明利用分布式计算框架spark的迭代计算方式,将归档中的计量数据进行转换操作,解决无法对海量计量数据进行批量处理、访问计量数据时间长、效率低的问题。本发明的应用很大程度上可以帮助电力信息化的发展,提高数据的处理能力。
现阶段大量的计量数据采集回来后却无法得到有效的利用,为了充分利用智能电网的计量数据,设计基于airflow的数据计算调度方法,对经过spark迭代计算后的数据进行调度运用起来,在这个过程充分利用airflow的优点,提高对历史数据的处理效率。
- 还没有人留言评论。精彩留言会获得点赞!