一种应用于TBM隧道岩爆灾害实时智能预警方法
本发明涉及隧道掘进机施工技术领域,更具体涉及一种应用于tbm隧道岩爆灾害实时智能预警方法。
背景技术:
全断面隧道掘进机是一种高效的隧道开挖机械,特别适用于长距离隧道的施工,它已经在隧道工程中得到越来越广泛的应用。岩爆是地下工程开挖过程中一种常见的动力失稳地质灾害,在时间上具有突发性,在空间上具有随机性,且破坏力极强,特别是在全断面隧道掘进机掘进过程中岩爆的发生往往会造成机毁人亡的巨大损失。然而目前国内外尚无完备的针对全断面隧道掘进机掘进过程岩爆灾害实时智能预警方法,主要存在以下不足:
(1)由于全断面隧道掘进机现场施工条件的限制,在线状狭小的可利用空间中难以搭建高效的微震监测平台。
(2)现有的岩爆灾害智能预警模型难以实现实时预警,受岩体参数(单轴抗压强度、岩石脆性指标、弹性应变能等)快速准确获取技术的限制。
(3)依赖于现场工程师的工程经验,岩爆烈度主要还是由人为确定,主观性强且效率低。
针对上述不足,本发明专利提出了一种应用于tbm隧道基于微震监测的岩爆灾害实时智能预警方法。
技术实现要素:
为解决全断面隧道掘进机安全高效掘进的难题,本发明的目的在于提供了一种应用于tbm隧道岩爆灾害实时智能预警方法。它将人工智能与微震监测相结合,随着微震数据量的不断增加,人工智能为数据处理提供了强有力的有段,进而为岩爆灾害实时智能预警提供了坚实的基础。
为实现上述目的,本发明采用以下技术方案:
一种应用于tbm隧道岩爆灾害实时智能预警方法,包括以下步骤:
步骤1、全断面隧道掘进机掘进过程中进行微震监测平台搭建;
步骤2、对微震监测平台监测获得的微震数据库降维获得降维后的微震数据矩阵x*;
步骤3、利用高斯混合模型进行降维后的微震数据矩阵中的微震事件聚类,为降维后的微震数据矩阵中的微震事件分配聚类标签;
步骤4、根据降维后的微震数据矩阵组建前兆微震序列数据库;
步骤5、建立分类回归树,分类回归树包括根节点、内部节点和叶节点,
根节点用于存储步骤4建立的前兆微震序列数据库中所有的前兆微震序列,内部节点表示属性条件,内部节点将上一层内部节点或根节点中包含的前兆微震序列分割为满足不同属性条件的前兆微震序列子集,叶节点包含岩爆发生与否以及岩爆烈度;
步骤6、训练分类回归树,并通过加权投票法得到自适应增强集成模型的输出;
步骤7、利用贝叶斯优化算法对自适应增强集成模型中的超参数寻优。
如上所述的步骤1包括以下步骤:
步骤1.1、选取监测断,距离开挖掌子面由近到远依次布设有第1组监测断面、第2组监测断面和第3组监测断面,
步骤1.2、每组监测断面在拱肩位置左右对称布置2个传感器;
步骤1.3、全断面隧道掘进机向前掘进设定距离后,将原第3组监测断面前移成为新的第1组监测断面,原第1组监测断面和原第2组监测断面分别作为新的第2组监测断面和新的第3组监测断面。
如上所述的步骤2包括以下步骤:
步骤2.1、构建原始微震数据矩阵x=(xij)m×n,m是微震数据库中微震事件的总数量,n是微震事件的震源参数的总数量,xij是第i个微震事件的第j个震源参数的原始微震数据,
步骤2.2:根据公式1对原始微震数据进行标准化获得标准化微震数据
其中,
步骤2.3:对标准化后的微震数据计算相关系数矩阵r=(rhl)n×n,其中rhl为第h个震源参数和第l个震源参数之间的皮尔逊相关系数,
步骤2.4:计算相关系数矩阵的特征值λ1,λ2,…,λn及其对应的特征向量v1,v2,…,vn,
步骤2.5:将数值大于1且累计贡献率超过80%的特征值对应的特征向量组成矩阵v,特征值的累计贡献率根据公式2计算,
其中,ηg指g个特征值的累计贡献率,
步骤2.6:根据公式3可以得到降维后的微震数据矩阵x*,
x*=x×v公式3
其中,x*指降维后的微震数据矩阵;x指原始微震数据矩阵;v指步骤2.5中由特征向量组成的矩阵。
如上所述的步骤3包括以下步骤:
步骤3.1、按照公式4、公式5和公式6构造高斯混合模型p(y|θ),
其中,φk(y|θk)指高斯混合模型中的第k个高斯密度函数;αk(αk≥0)指第k个高斯密度函数的权重系数;
步骤3.2:采用期望最大化算法迭代反演高斯混合模型中的参数α={α1,α2,...,αk}和
期望最大化算法的流程如下:
步骤3.2.1、参数α={α1,α2,...,αk}和
步骤3.2.2、根据公式7计算高斯混合模型中的第k个高斯密度函数φk(y|θk)对降维后的微震数据矩阵中第i个微震事件yi的响应γik,
其中,γik指高斯混合模型中的第k个高斯密度函数对降维后的微震数据矩阵中第i个微震事件的响应,m是微震数据库中微震事件的总数量,yi为第i个微震事件,
步骤3.2.3、根据公式8、公式9和公式10更新参数α={α1,α2,...,αk}和
步骤3.2.4、重复步骤3.2.2~3.2.3,直到参数α={α1,α2,...,αk}和
步骤3.3、迭代反演得到高斯混合模型中的参数α={α1,α2,...,αk}和
如上所述的步骤4包括以下步骤:
为降维后的微震数据矩阵中的微震事件分配聚类标签后,将每5个微震事件对应的聚类标签按照微震事件捕捉时间的先后顺序排列即构造1个前兆微震序列,进而建立由前兆微震序列组成的前兆微震序列数据库。
如上所述的步骤5中,采用属性条件a的基尼指数作为分割判据,属性条件a的基尼指数gini_index(d,a)如公式11所示:
其中,d指由待分割节点所包含的前兆微震序列组成的前兆微震序列数据集,待分割节点包括内部节点或者根节点;dv指由属性条件a分割前兆微震序列数据集得到的前兆微震序列数据子集,v指前兆微震序列数据集d中样本的类数,
基尼值gini(dv)定义为:
其中,pk指前兆微震序列数据子集dv中第k类样本所占的比例。
如上所述的步骤6包括以下步骤:
步骤6.1、初始化前兆微震序列数据库中前兆微震序列的权重,
步骤6.2、根据步骤5利用前兆微震序列数据库建立的分类回归树,
步骤6.3、计算分类回归树的预测误差,
步骤6.4、计算分类回归树在自适应增强集成模型中的权重,
步骤6.5、根据分类回归树预测结果更新前兆微震序列数据库中前兆微震序列的权重,
步骤6.6、如果已建立的分类回归树数量达到预先设定值,则停止训练分类回归树,并通过加权投票法得到自适应增强集成模型的输出;如果已建立的分类回归树数量未达到预先设定值,则重复步骤6.2~6.5。
如上所述的步骤7包括以下步骤:
步骤7.1、初始化自适应增强集成模型中的超参数,建立超参数数据库,
步骤7.2、根据建立的超参数数据库训练如公式13所示高斯过程代理模型:
f(b)~gp(0,κ(xp,xq))公式13
其中,κ(xp,xq)是关于超参数的协方差函数矩阵;xp是超参数数据库中的第p个超参数;xq是超参数数据库中的第q个超参数;f(b)是自适应增强集成模型在不同超参数组合下的精度,gp为高斯过程函数,
步骤7.3、通过公式14所示的最大化概率提升获取函数pi(b)确定下一组待评价超参数,并补充到超参数数据库中,
其中,φ指标准正态分布的累积分布函数;μ(b)和σ(b)分别指根据步骤7.2建立的高斯过程代理模型得到的自适应增强集成模型在不同超参数组合下的精度的平均值和标准差;f(b*)指当前超参数数据库下自适应增强集成模型在不同超参数组合下的精度的最优值,
步骤7.4、若达到设定的最大迭代次数则终止迭代,否则重复步骤7.2~7.3,迭代结束后,将超参数数据库中实现最高自适应增强集成模型精度的一组超参数作为最优超参数。
本发明与现有技术相比,具有以下优点和效果:
(1)根据全断面隧道掘进机现场施工条件,设计和优化了微震监测传感器的布设方式,满足随掘进随监测的要求,同时还能有效地捕捉掘进过程中产生的岩体微破裂信号。
(2)微震监测是一种原位三维空间实时监测技术,利用微震数据开展岩爆预警研究相比传统利用岩性参数开展岩爆预警研究更具有实时性,能及时防控岩爆灾害。
(3)本发明提供自动化智能预警系统,具有高效性,同时可以最大限度减少人为因素的干扰。它由知识驱动而非简单由现场施工人员的工程经验主导,在准确性上可以得到保证。
附图说明
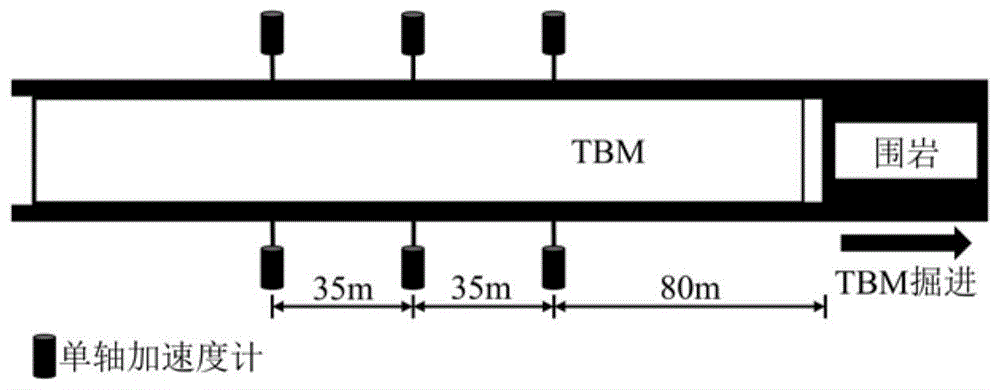
图1为全断面隧道掘进机掘进过程中微震监测平台搭建示意图。
图2为本发明的整体流程示意图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
本发明依次进行微震监测平台搭建、微震数据降维、微震数据聚类、前兆微震序列构造和智能识别。
一种应用于tbm隧道岩爆灾害实时智能预警方法,包括以下步骤:
步骤1、全断面隧道掘进机掘进过程中微震监测平台搭建,详见图1。
步骤1.1:选取监测断面。距离开挖掌子面由近到远依次布设有第1组监测断面、第2组监测断面和第3组监测断面,第1组监测断面距离开挖掌子面80m,这是为了保证工作人员和设备的安全。第2组监测断面和第1组监测断面之间的间距、第3组监测断面和第2组监测断面之间的间距均为35m。
步骤1.2:传感器钻孔安装。传感器选用单轴加速度计,其频率响应范围为50hz-5khz,灵敏度为30v/g,钻孔深度约为1.5m,每组监测断面在拱肩位置左右对称布置2个传感器。
步骤1.3:全断面隧道掘进机每掘进35m时,将原第3组监测断面前移成为新的第1组监测断面,原第1组监测断面和原第2组监测断面分别作为新的第2组监测断面和新的第3组监测断面。
步骤2、对微震监测平台监测获得的微震数据库降维获得降维后的微震数据矩阵x*,详见图2。
步骤2.1:构建原始微震数据矩阵x=(xij)m×n,m是微震数据库中微震事件的总数量,n是微震事件的震源参数的总数量,xij是第i个微震事件的第j个震源参数的原始微震数据。
步骤2.2:为了消除震源参数的量纲影响,使得不同震源参数之间具有可比性,根据公式1对原始微震数据进行标准化获得标准化微震数据
其中,
步骤2.3:对标准化后的微震数据计算相关系数矩阵r=(rhl)n×n,其中rhl为第h个震源参数和第l个震源参数之间的皮尔逊相关系数。
步骤2.4:计算相关系数矩阵的特征值λ1,λ2,…,λn及其对应的特征向量v1,v2,…,vn。
步骤2.5:将数值大于1且累计贡献率超过80%的特征值对应的特征向量组成矩阵v。特征值的累计贡献率根据公式2计算。
其中,ηg指g个特征值的累计贡献率。
步骤2.6:根据公式3可以得到降维后的微震数据矩阵x*。
x*=x×v公式3
其中,x*指降维后的微震数据矩阵;x指原始微震数据矩阵;v指步骤2.5中由特征向量组成的矩阵。
步骤3、利用高斯混合模型进行降维后的微震数据矩阵中的微震事件聚类,为降维后的微震数据矩阵中的微震事件分配聚类标签。
步骤3.1:高斯混合模型是多个高斯密度函数的加权和,构造高斯混合模型p(y|θ),如公式4、公式5和公式6。
其中,φk(y|θk)指高斯混合模型中的第k个高斯密度函数;αk(αk≥0)指第k个高斯密度函数的权重系数;
步骤3.2:采用期望最大化算法迭代反演高斯混合模型中的参数α={α1,α2,...,αk}和
期望最大化算法的流程如下:
步骤3.2.1、参数α={α1,α2,...,αk}和
步骤3.2.2、根据公式7计算高斯混合模型中的第k个高斯密度函数φk(y|θk)对降维后的微震数据矩阵中第i个微震事件yi的响应γik。
其中,γik指高斯混合模型中的第k个高斯密度函数对降维后的微震数据矩阵中第i个微震事件的响应,m是微震数据库中微震事件的总数量,yi为第i个微震事件。
步骤3.2.3、根据式(8)、式(9)和式(10)更新参数α={α1,α2,...,αk}和
步骤3.2.4、重复步骤3.2.2~3.2.3,直到参数α={α1,α2,...,αk}和
步骤3.3、迭代反演得到高斯混合模型中的参数α={α1,α2,...,αk}和
步骤4、根据降维后的微震数据矩阵组建前兆微震序列数据库。
为降维后的微震数据矩阵中的微震事件分配聚类标签后,将每5个微震事件对应的聚类标签按照微震事件捕捉时间的先后顺序排列即可构造1个前兆微震序列,进而建立由前兆微震序列组成的前兆微震序列数据库。
步骤5、建立分类回归树。
分类回归树由一系列节点组成,包括根节点、内部节点和叶节点。
根节点用于存储步骤4建立的前兆微震序列数据库中所有的前兆微震序列,在一个分类回归树中只有一个根节点。内部节点表示属性条件,当前层内部节点包含上一层内部节点或根节点中满足当前层内部节点表示的属性条件的前兆微震序列。换句话说,内部节点将上一层内部节点或根节点中包含的前兆微震序列分割为满足不同属性条件的前兆微震序列子集。叶节点包含岩爆发生与否以及岩爆烈度等信息。
基尼指数用于确定哪种属性条件作为分割判据,完成分类回归树的生长过程。基尼指数越小,节点纯度越高,分割效果越好。属性条件a的基尼指数gini_index(d,a)定义为:
其中,d指由待分割节点所包含的前兆微震序列组成的前兆微震序列数据集,待分割节点包括内部节点或者根节点;dv指由属性条件a分割前兆微震序列数据集得到的前兆微震序列数据子集,v指前兆微震序列数据集d中样本的类数,每个前兆微震序列都会对应岩爆发生与否以及岩爆烈度的信息,将对应相同信息的前兆微震序列称为同一类样本,在这里分为五类:无岩爆,轻微岩爆,中等岩爆,强岩爆,极强岩爆,即在这里v=5。
基尼值gini(dv)定义为:
其中,pk指前兆微震序列数据子集dv中第k类样本所占的比例,每个前兆微震序列都会对应一个岩爆发生与否以及岩爆烈度的信息,将对应相同信息的前兆微震序列称为同一类样本,岩爆烈度分为五类:无岩爆,轻微岩爆,中等岩爆,强岩爆,极强岩爆。
步骤6、训练分类回归树,并通过加权投票法得到自适应增强集成模型的输出。
步骤6.1:初始化前兆微震序列数据库中前兆微震序列的权重。
步骤6.2:根据步骤5利用前兆微震序列数据库建立分类回归树。
步骤6.3:计算分类回归树的预测误差。
步骤6.4:计算分类回归树在自适应增强集成模型(adaboost)中的权重。
步骤6.5:根据分类回归树预测结果更新前兆微震序列数据库中前兆微震序列的权重。
步骤6.6:如果已建立的分类回归树数量达到预先设定值,则停止训练分类回归树,并通过加权投票法得到自适应增强集成模型(adaboost)的输出;如果已建立的分类回归树数量未达到预先设定值,则重复步骤6.2~6.5。
步骤7、利用贝叶斯优化算法(bayes)对自适应增强集成模型(adaboost)中的超参数寻优,自适应增强集成模型(adaboost)中的超参数包括分类回归树数目、最大树深和学习率。
步骤7.1:初始化自适应增强集成模型(adaboost)中的超参数。本实施例中,初始化100组自适应增强集成模型(adaboost)中的超参数从而建立超参数数据库。
步骤7.2:根据建立的超参数数据库训练高斯过程代理模型,即公式13。
f(b)~gp(0,κ(xp,xq))公式13
其中,κ(xp,xq)是关于超参数的协方差函数矩阵;xp是超参数数据库中的第p个超参数;xq是超参数数据库中的第q个超参数;f(b)是自适应增强集成模型(adaboost)在不同超参数组合下的精度。gp为高斯过程函数(gaussianprocess)。
步骤7.3:通过公式14所示最大化概率提升获取函数pi(b)(pi,probabilityimprovement)确定下一组待评价超参数,并补充到超参数数据库中。
其中,φ指标准正态分布的累积分布函数;μ(b)和σ(b)分别指根据步骤7.2建立的高斯过程代理模型得到的自适应增强集成模型(adaboost)在不同超参数组合下的精度的平均值和标准差;f(b*)指当前超参数数据库下自适应增强集成模型(adaboost)在不同超参数组合下的精度的最优值。
步骤7.4:若达到设定的最大迭代次数则终止迭代,否则重复步骤7.2~7.3。迭代结束后,将超参数数据库中实现最高自适应增强集成模型(adaboost)精度的一组超参数作为最优超参数。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!