控制和/或分析工业的过程的系统和设备外部的计算单元的制作方法
本发明公开了一种用于借助于设备外部的计算单元和设备外部的计算单元之中的用于系统操作者的审核模块来控制和/或分析工业的过程的系统和方法。
背景技术:
进行过程控制的多个设备通常满足自动化和控制技术的任务。这些任务通常由自动化单元执行,其在现场并且因此在要自动化的过程的附近安装。这样的自动化单元由于其受限的计算能力在之前不能够映射复杂的调节结构或调节和/或模拟策略,如其在更高等级的自动化设备中能够实现的那样。这样能够需要巨大的计算容量的、复杂的调节策略能够例如是所谓的模型预测控制(Model Predictive Control,MPC),如其优选地在工艺的过程中采用的那样。常常也存在设置复杂的调节的期望,其在大量的历史数据的基础上建立并且其例如在所谓的支持向量机(SVM)中使用,以便在其基础上能够进行过程上的优化。因此,这样的计算密集的工艺的过程或者数据分析模型通常在设备的上级的控制和监视系统中进行自动化。
当前经历的是外部计算单元中的在中心的数据分析的方向上的趋势(所谓的基于云的分析)。利用该外部的计算单元能够基于云地执行用于工业的设备的过程控制,通过由设备收集过程数据的方式,以便将其随后提供给用于分析的外部的计算单元。分析结果为了改善过程控制和过程优化而被发回到设备处。由于其大量的分析方法和主要自我学习的技术,基于云的分析允许过程控制的主要的改善。此外经过长时间收集的历史数据为了分析而存储在外部的计算单元中。然而,外部的计算单元也能够包括MES(Manufacturing Execution Systems,制造执行系统)或ERP系统(Enterprise resource planning,企业资源规划)的数据。这样的MES或ERP系统具有另外的功能范围,其中,其功能同样基于最不同的过程数据和过程参量计算。也位于该系统中的、经受另外的处理的缓存数据能够对于过程控制来说是意义重大的。在自动化单元的过程参量计算通常直接作用于工业的过程(例如通过用于调节器的额定值预设)期间,MES或ERP系统的过程参量计算之前间接地作用于工业的过程,通过MES为了结束生产过程例如通过确定由收集指令的生产计划负责任地示出的方式,或者通过MES实施资源的检查和管理的方式,以便准备生产或利用必要的材料资源来执行生产预定和/或经由生产过程的进展来告知其它的系统。或者对过程的作用间接地通过交换过程数据、运行装置物品的状态分析、材料消耗信息或者历史或当前的生产数据来实现。
过程的前述数据是系统操作者的敏感数据,尽管如此仍应当将其多次存储在外部的计算单元中,其代表了公开的或所谓混合的云。因此从系统操作者的直接的负责和访问区域中获得这些数据,这被看作是有问题的。此外,这样的公开的或混合的云也存储和处理不同的系统操作者和企业的数据。此外,公司机构在其数据处理方面经受其独特的不同的安全规定,其能够被上级的安全规定影响,其能够由于法规而在各国之间不同。一旦数据离开了企业的限制,对于企业来说执行规则的维持就会是困难的。
基于云的应用的或类似这样的云的提供者认识到的问题是,客户抱怨无法获得如下的透明度,其数据中的哪些存储在哪种范围中并且其如何通过提供者进行使用。这导致的是,客户很难同意和接受基于云的服务提供。
对于位于企业限制中的数据来说能够轻易地执行对企业的数据的审核,对于位于云中的-再加上其它的提供者的-数据来说这会是很大的问题。
对所述难题的明白的解决方案目前是不存在的,基于云的服务提供者配置其数据收集器,以使得其仅收集重要的和符合合同的数据。尽管如此,客户期望有更多透明度的是哪些数据存储在云中,并且其期望的是对如何使用数据并且如何在云应用中处理数据进行更多地控制。
然而,这样的控制由于其它的原因仍然是有问题的。数据的基于云的存储是不均等的。公开的或混合的云系统借助于数据收集器或数据发送器(基于代理或无代理地)在云之中存储不同企业的数据。在此,企业数据能够在云中存储在不同的数据存储器中。数据存储器能够是数据库(SQL、甲骨文、微软Access等)、文件系统(各种类型的文件)、数据文档、大型数据存储器(Hadoop簇、NoSQL、MongoDB、Rabbit等)、缓存器等等。一方面,各种企业的数据能够在有关机构方面以分开的模型进行存储(所谓的理想多租户模型)。根据这种模型,严格地按照企业进行组合和封装。数据存储器是分开的,每个机构都具有其特有的SQL数据库和其特有的文件系统。另一方面,数据能够在有关数据存储器方面以分开的模型进行存安排,即SQL数据库和/或文件系统包括各种企业的数据(所谓的混合多租户模型)。
除了前述有关云中的数据的透明度问题之外还想要知道的是,其数据中的哪些在哪个时间点以哪种详细说明度存在于云中,系统操作者对于该问题认为不知道的是,如何应用其在云中的数据。
然而云中的数据常常被复制。数据的副本由使用这些数据的应用写入临时的缓冲器、存储区域或文件中。数据的副本还保存在备份中。随后也在应当利用“大数据”技术手段完成进一步分析的地方完成数据的副本。因此该问题更致命的是,云也正好通过各种应用处理过程数据,例如状态监视或进一步的大数据分析。
还能够得出的问题是,工业设备的机构或系统操作者变更服务提供者以及云基础设施。在数据多次并且在可能的情况下在各种存储介质上复制之后,几乎不能够为数据所有者保证将其数据完全地删除。复制能够位于临时存储器、备份文档或Hadoop簇中。
技术实现要素:
从前述问题出发,因此本发明的目的在于借助于设备外部的计算单元给出用于控制和/或分析工业的过程的系统,其相对于数据提供者改善了透明度和控制。特别地,该目的建立如何使用和管理数据的透明度。
该目的通过本发明的系统和本发明的装置实现。
由此,用于控制工业的过程的系统在设备侧具有系统操作者的至少一个自动化或计算单元。自动化的设备能够是在工业的环境中具有生产或制造过程的每个设备。设备侧指的是,自动化或计算单元是原始的自动化系统的组成部分并且通常在过程附近布置。自动化单元执行多个第一过程参量计算。对此,自动化单元借助于传感器和执行机构连接到过程中。过程输入变量是传感器和执行机构,其对于控制过程来说通常由自动化单元的输入模块循环地读入并缓存,并且因此通过自动化部件的处理器来提供给另外的软件技术的处理。自动化单元之中的具体的软件技术的处理根据过程控制算法来实现。该处理的输出参量、即设备侧的自动化单元的过程控制算法的结果通常经由自动化单元的输出模块同样循环地变成对过程有效。然而,设备侧的计算单元也能够是MES(Manufacturing Execution Systems)或ERP系统(Enterprise resource planning)。位于该系统中的、经受另外的处理的缓存数据也应该归入在此应用的第一过程参量计算的概念。在自动化单元的过程参量计算通常直接作用于工业的过程(例如通过用于调节器的额定值预设)期间,MES或ERP系统的过程参量计算之前间接地作用于工业的过程,通过MES为了结束生产过程例如通过确定由收集指令的生产计划负责任地示出的方式,或者通过MES实施资源的检查和管理的方式,以便准备生产或利用必要的材料资源来执行生产预定和/或经由生产过程的进展来告知其它的系统。或者对过程的作用间接地通过交换过程数据、运行装置物品的状态分析、材料消耗信息或者历史或当前的生产数据来实现。
该系统还具有至少一个设备外部的计算单元(云计算单元),其利用在其上运行的应用执行第二过程参量计算,并且对此经由数据连接从设备侧的自动化或计算单元获得本地的数据。该本地的数据是系统操作者的数据。数据连接经由已知的通信机构和标准化的接口实现。属于通信机构的例如有通信标准OPC(OPC DA,OPC UA)或TCP/IP(Profinet),其允许独立的计算单元联合为分布的系统。属于标准的有接口RPC、OLEDDB或SQL。计算单元应当看作为是设备外部的,其在空间和/或功能上安放在原始的自动化系统之外并且在服务提供者的负责范围之中,并且因此已经离开了系统操作者的负责范围。
设备外部的计算单元具有至少一个应用并且并行于或附加于计算设备侧的自动化或计算装置的第一过程参量计算地执行第二过程参量计算。在此,复杂的第二过程参量计算也能够基于大量的数据。只要这些数据能够由过程自我提供(例如通过附加的和到那时未使用的传感器和执行机构),那么其同样经由设备侧的自动化单元被读入并提供。然而,这样的本地的数据也能够包括历史数据或缓存数据,例如其自身位于设备侧的自动化或计算单元之中。在设备外部的计算单元中执行的计算通常远比能够在设备侧的自动化单元中执行的计算更加复杂和计算密集。因此,外部的计算单元承担大量的控制技术上的功能,例如其由MPC调节器已知。由于更多数量的数据、特别是历史数据,过程控制算法例如也能够包括基于所谓的支持向量机(SVM)的模型预测控制(MPC)算法。经由第二过程参量计算,外部的计算单元能够直接作用于过程,第二过程参量计算能够直接在过程中成为有效的。此外,能够在设备外部的计算单元上运行应用,映射状态监视系统、模拟系统或历史系统,并且在该设备外部的计算单元之中执行附加的评估和分析,并且出于该目的也调用自动化或计算单元中的本地的数据。就此来说,所谓的第二过程参量计算应当包括在本地的数据上的计算,其不是直接调节或控制地反作用于过程,而是应当出于其它的目的、例如评估目的而由应用提供给系统操作者,并且就此而言间接作用于过程,通过应用能够更安全和更有效地完成这些数据的方式。本地的数据利用到设备外部的计算单元中的输入端来存储在初级存储器中,应用为了实施其程序而访问该初级存储器。这样的初级存储器能够构造为理想或混合的多租户模型。
现在,设备外部的计算单元具有审核模块,其中,该审核模块通过应用记录对初级存储器的另外的访问。在这点上,记录理解为直接录入事件(读、写)并且进一步处理、使用每个储存在初级存储器中的数据。访问通过应用、即在设备外部的计算单元之中运行的各个程序来触发。
根据一个变体方案,审核模块不仅记录对初级存储器的数据的访问,还附加地记录对次级存储器的访问。次级存储器在此理解为由应用已使用的临时存储器。其能够例如是Hadoop存储、临时数据和缓存器以及备份系统。在此,不同的应用交替地又或者累加地访问次级存储器。
根据一个变体方案,审核模块包括至少一个日志文件,其记录至少利用参数用户(用户组)、数据类别、副本的访问。以该方式生成的档案是关于哪里、哪些数据、如何应用和在可能的情况下在哪个存储器区域中复制。“用户”或“用户组”的条目的合理处在于,设备外部的计算单元中的数据不仅由设备外部的计算单元的服务操作者使用,而且具有部分特有的应用的一系列的其它的用户应当访问数据。因此能考虑的是,用于特定服务和/或分析的服务操作者的伙伴也应当访问系统操作者的数据。伙伴应当在可能的情况下甚至取决于其分析地访问各种服务操作者的数据。其它的情况能考虑的是,在其中例如在极其特殊的应用情况下用户应当接触到这些数据。例如,用户能够被限定为“人力资源”的角色并且获得对特定的人员数据的访问。
通过“数据类别”记录的是,数据的哪些组经过了进一步的处理或复制。以这种方式能够有利地检查,在其角色中的用户是否实际上仅访问允许的数据并且进一步处理。“副本”条目记录的是,是否并且如果是,那么在哪个存储器区域中确认复制。如果复制的日期再次在存储区域上、优选地从次级的存储区域中删除,那么就相应地更新日志文件。经由日志文件,系统操作者或作为数据的所有者的机构保持的概况为,何时由谁处理并且在可能的情况下复制其数据中的哪些。
根据另一种观点,系统操作者或数据的所有者获得从设备侧的自动化和计算单元的外部的访问。设备侧的自动化和计算单元的外部的访问意味着通过系统操作者的独立的访问,在第一线中通过系统操作者进行时间和空间上独立的访问,即在设备外部的计算单元实施控制或分析功能期间或之后。数据所有者现在能够在每个时间得到完整的概况为,将设备外部的计算单元中的哪些数据或者数据的类别通过哪些用户复制到哪里。这对于二者、系统操作者和服务操作者来说是有利的。因此,系统操作者能够为了依从目的而使用过审核模块,服务操作者能够相对于系统操作者证实的是,其仅在可能的情况下进行数据的合同商定的运动。
该目的还通过用于控制和/或分析系统操作者的至少一个工业的过程的、设备外部的计算单元实现。设备外部的计算单元具有一个或多个应用并且在本地的数据的基础上执行用于至少一个工业的过程的过程参量计算。经由数据连接,设备外部的计算单元从设备侧的自动化或计算单元获得本地的数据,其存储在设备外部的计算单元的初级存储器中。设备侧的自动化或计算单元具有审核模块,其记录一个或多个应用对次级存储器的访问。因此,通过录入在有关次级存储器方面记录所有的读取和写入的访问、即应用的所有活动。因此,能够检测每个存储在初级存储器中的日期的进一步处理和使用。
通常,设备外部的计算单元的基础设施除了前述的初级存储器之外也具有另外的存储区域,其由应用在处理其程序时使用。根据本发明的另一个观点,标记为次级存储器的存储器也由审核模块检测并且也记录对该次级存储器的访问。以该方式在存储区域方面保障应用的所有行为的完整记录,并且因此在对于之后评估的行为方面建立广泛的记录。
附图说明
联系附图详细阐述本发明的上述特性、特征和优点以及实现的方式和方法。在此示意性地示出:
图1示出用于具有设备外部的计算单元的工业设备的分布过程控制的系统,
图2示出在设备外部的计算单元中的审核模块的工作原理,
图3示出用于系统操作者的日志文件的可行的区段。
具体实施方式
图1示出了用于对工业的过程1进行控制的系统100,该过程能够是加工工业中的任意的生产过程。工业的过程能够是在一个又或者多个地点之中运行的过程。过程1经由非中心的设备侧的自动化单元2控制和调节。其装配有一个或多个在此未示出的处理器,其与必要的中间存储器共同作用地处理以软件代码存储的指令。指令涉及用于控制和调节过程的全部的过程控制算法以及单元之间的数据通信。自动化单元2(PLC)为了控制和调节过程而具有从有效连接3到在图1中未详细示出的一系列的传感器或执行机构。经由该连接,输入模块17读入本地的数据,其之后位于自动化单元的存储区域中。经由有效连接4实现从输出模块18到图1中未详细示出的过程的执行机构的控制命令。示例性地示出两个自动化单元2,在实践中多个自动化单元对过程进行控制、调节和监视。经由数据连接20使得自动化单元2与监视系统5连接,其承担对过程1的控制和监视。监视系统5(SCADA)维持到制造执行系统6的数据连接21,该制造执行系统又维持到企业资源规划系统7的数据连接22。制造执行系统6和企业资源规划系统7也能够经由数据连接20与监视系统5通信。自动化单元2在经由有效连接3生成的本地数据的基础上实施过程控制算法8。这是过程有效的监视分析和调节功能,其通常包含更简单和更小复杂程度的分析和调节任务。该过程控制算法的结果作为过程参量计算19在自动化单元2中用于另外的应用并且大体上不需要在下个循环中被覆盖。然而,过程参量计算19同样通过上级的系统5,6,7之中的计算被影响。因此,例如规划预设在来自MES和ERP系统的客户预定或材料供应的基础上导致的是,特定的制造过程应当更慢、更能量优化或更快地实施。SCADA能够例如由于制造过程(例如包装部门)的其它位置上的干扰而同样影响位于前面的制造过程(例如填裝)。
在该配置中,系统100是有效的并且能够满足其控制、调节和监视任务。
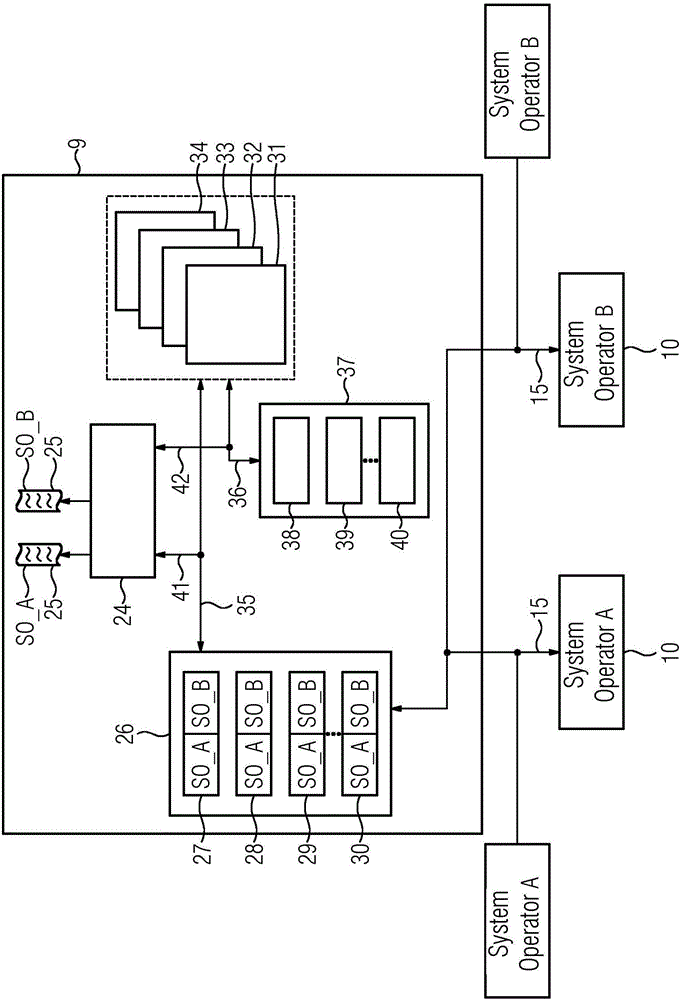
系统100通过设备外部的计算单元9扩展。其装配有一个或多个在此未示出的处理器,其与必要的中间存储器共同作用地处理以软件代码存储的指令。指令涉及用于对过程进行控制、调节和分析的全部的过程控制算法以及单元之间的数据通信。计算单元9经由数据连接15和网关10与设备侧的自动化和计算单元连接。数据连接15优选地经由互联网要么有线地要么无线地实现。网关10能够是数据收集器单元,其从自动化和计算单元2,5,6,7经由数据连接23获得所有的本地的数据,其在计算单元9中对于在该处运行的、用于对过程1进行控制、调节和分析的前述的过程控制算法来说是必要的。所示的数据连接23能够在功能上理解,其在物理上能够是特有的网络,或者其将数据收集器单元10接入到系统100中存在的网络上,如20、21那样。设备外部的计算单元9在由网关10提供的并且基本基于经由有效连接3生成的数据的输入过程变量12的基础上执行过程控制算法13并且给出该计算的结果14。输入过程变量12同样能够基于位于自动化单元2中的历史数据。可替换地或附加地,输入过程变量12能够基于自身位于计算单元9中的历史数据。示例性地,图1示出了作为过程控制算法13的MPC调节结构。然而,更广泛的数据分析也能够是前述算法的内容,并且结果14是这样的分析功能的结果。将结果14传送到自动化和计算单元2,5,6,7处。对此,经由网关10能够使用通讯路径,或者其替换地使用在此未示出的单独的通信路径。如果结果14会直接作用于过程1,那么检查模块16在自动化单元2之中决定的是,结果14是否经由发送模块18变成过程有效的(prozesswirksam)。然而可替换地,结果14也能够是例如状态监视系统的数据分析并且仅传输到计算单元6,7处。在该情况中,当例如分析功能在状态监视的范畴中确定了构件的故障时,分析功能的这样的结果也能够提供给ERP或MES。也能考虑的是,结果仅存储和保留在外部的计算单元9之中并且能提供用于另外的评估。
图2示意性地示出了设备外部的计算单元9之中的审核模块24的工作原理。经由相应的系统操作者SO_A、SO_B(System Operator A,System Operator B)的网关10,设备侧的自动化和计算单元2,5,6,7的本地的数据借助于代理经由数据连接15进行传输。系统操作者的数据在设备外部的计算单元9中的初级存储器26中存储。初级存储器在物理上不应当理解为唯一的存储器。更确切地,其能够包括一系列的各种存储介质,例如数据库27、文件系统28、内存中的数据库29、文档30等。初级存储器26能够如在该实施例中那样,设备外部的计算单元与多个操作者的数据源连接。示例性地,图2示出了将数据以混合多租户模型的形式存储在数据库中和数据系统中。可替换地,数据也能够存储在理想多租户模型中,即利用用于相应的系统操作者的数据的、特有的数据库和/或文件系统。应用31,32,33,34读取地并且在可能的情况下也写入地访问初级存储器的数据。应用对初级存储器的数据的读取的和写入的访问通过箭头35示出。基于云的应用31至34访问初级存储器的数据,以便将其进一步处理、分析或经由用户接口可视化。应用31,32,33,34能够是服务操作者或另外的服务伙伴又或者系统操作者自身的应用。例如,应用31能够是用于状态监视31的应用,其从初级存储器中读取用于机器的状态的数据,然后在用于快速傅里叶变换的临时的存储器中处理,并且调入用于预防性的维护的建议的、另外的分析的中间结果。用于收入预测的应用32从初级存储器中读取历史数据并且将其复制到用于另外的大数据分析的Hadoop存储器中。备份应用33交替地完成从初级存储器到次级存储器中的转存。ERP应用34访问初级存储器的数据,以便例如计算用于制造的特定的KPI(key performance indicator,关键绩效指标)。所有的应用都是共用的,即其使用一个次级存储器37,以便在那里存储初级存储器的数据的副本或中间结果。次级存储器37同样不应当在物理上理解为唯一的存储器。其也能够包括一系列的各种存储介质或机构,例如Hadoop存储38、临时存储区域39或备份文件系统40等。应用31-34具有读取和/或写入的访问,其通过箭头36示出。
审核模块24记录了-通过箭头41示出-应用对初级存储器26的所有的访问。审核模块24进一步记录并且通过箭头42示出了应用对次级存储器37的所有的访问。模块24生成日志文件25,在其中写入用于访问的细节和数据的使用的类型。各种日志文件25设置用于各种系统操作者(SO)。示例性地,图2示出了用于系统操作者A(SO_A)和B(SO_B)的日志文件25。
图3示例性地示出了用于系统操作者A的日志文件25的可行的区段。访问的日期43的时间点被记录。在另外的条目中记下了用户/用户组44,由其进行访问。这能够例如是服务操作者、服务操作者的伙伴或系统操作者自身。同样地,经由用户访问数据的应用实现录入。数据对应数据的类别45,在其中数据引入日志文件中。在此示例性地,类别是“机器配置数据”、“振动数据”、“人力资源数据”。附加地,对于每次日志文件的录入来说包括处理的数据的数据量46。条目47提供了关于是否制作副本并且如果是的话在哪个存储器/存储区域中存放副本的信息。
- 还没有人留言评论。精彩留言会获得点赞!