基于增强学习型智能算法的无人艇航迹跟踪控制方法与流程
本发明涉及的是一种无人艇航迹跟踪控制方法,具体涉及的是一种基于增强学习型智能算法的无人艇航迹跟踪控制方法。
背景技术:
无人艇(USV)是一种集自主规划,自主航行,自主完成环境感知,目标探测等功能为一体的小型水面运动平台。针对诸如水域勘察、海洋资源探测、水文地理研究、海上作业等不同任务,无人艇均需具必备航迹跟踪控制的能力。
增强学习是当今机器学习和人工智能领域研究的热点之一,当外界环境不能提供明确的训练信号,而交互式代理体必须学习最优控制动作时该算法非常有效。
技术实现要素:
本发明的目的在于提供一种用以得到响应迅速且输出平滑的控制效果,同时不依赖于外界环境模型的基于增强学习型智能算法的无人艇航迹跟踪控制方法。
本发明的目的是这样实现的:
(1)用位置参考系统测得无人艇的位置信息、用姿态参考系统测得无人艇的艏向姿态信息;
(2)对获取的位置信息及姿态信息进行滤波及融合,得到无人艇的实际位置及姿态;
(3)将期望的位置及姿态与实际的位置及姿态做比较,并经过解算得到误差信号;
(4)利用Backstepping法不断反演,最终得到无人艇航迹跟踪控制系统的控制律。
本发明还可以包括:
1、还包括利用近似策略迭代增强学习的智能算法进行航迹跟踪学习的过程,具体过程为:
定义五元组(S,LA,LP,R,γ),其中,S为有限或连续状态空间、LA为有限或连续行为空间、R为回报函数、LP为MDP的状态转移概率、γ为决策优化的目标函数,将MDP的状态定义为三维向量,向量元素ex,ey,分别为实际的北向位置、东向位置及艏向角同三者期望值之间的误差,Backstepping控制器采用自学习优化策略,MDP的行为定义为一系列候选的控制器参数{(K11,K21),(K12,K22),…(K1n,K2n)};
其中回报函数和目标函数定义为:
R=m|e|
|e|为路径跟随误差,m为负常数,n为加权因子,
然后,采用近似策略迭代增强学习法,解决连续空间的策略逼近与泛化问题,行为值函数Q(s,a)的逼近形式为:
其中s(x,a)为状态-行为对(x,a)的联合特征,αi为加权系数,(xi,ai)为样本点,同时确定行为值函数逼近误差的上界δ:
整个流程如下:
(1)、随机生成初始策略,确定停止条件、以及马氏决策过程在初始条件下产生的观测数据;
(2)、算法初始化,确定迭代次数;
(3)、迭代循环:
a)对当前数据集合,进行策略值函数的估计;
b)计算策略的优化与改进,并生成下一个策略;
c)生成新的数据样本;
d)返回循环;
满足条件停止。
2、所述利用Backstepping法不断反演的具体过程为:
需要控制的无人艇的控制力和艇本身的关系式为:
其中M为系统的惯量矩阵,D为水动力阻尼系数矩阵,为北东坐标系和船体坐标系间的旋转变换矩阵,τ为艇的控制力,f为风浪流干扰力,为误差变量e的一阶导数,为e的二阶导数,同理为R-1的一阶导数,为ηd的一阶导数,为ηd的二阶导数;
令其中μ为待反演的控制律的输出信号,K1为给定的正定增益矩阵,并定义如下状态变量:
构造Lyapunov函数,
其中,P为正定矩阵,V1与V2为选取的李雅谱诺夫函数,且x1和x2均按指数收敛于0,经过递推得到如下的控制律:
μ=Bx2-AP-1x1-AP-1K2x2
其中K2正定对角阵,带入艇的控制力τ的表达式,得到最终的控制力输出为:
本发明针对无人艇的航迹跟踪控制问题,提出了一种基于增强学习型智能算法的跟踪控制方法,用以得到响应迅速且输出平滑的控制效果,同时不依赖于外界的环境模型。
本发明包括以下有益效果:
1、本发明引入了Backstepping法进行航迹跟踪控制器的设计,针对具有欠驱动特性的无人艇能够满足其航迹跟踪控制的要求。
2、本发明中无人艇位置及姿态的获取采用了集成位姿传感器,其精度满足航迹跟踪控制需求同时体积小巧更换方便,适应无人艇体积空间小的特点。
3、本发明所述的近似策略迭代增强学习的航迹跟踪学习控制,在不依赖于环境模型的基础上实现了Backstepping控制器的学习优化,相较于传统的航迹跟踪控制器其算法更加智能,跟踪控制响应更加迅速,跟踪效果更加平滑,跟踪误差小。
附图说明
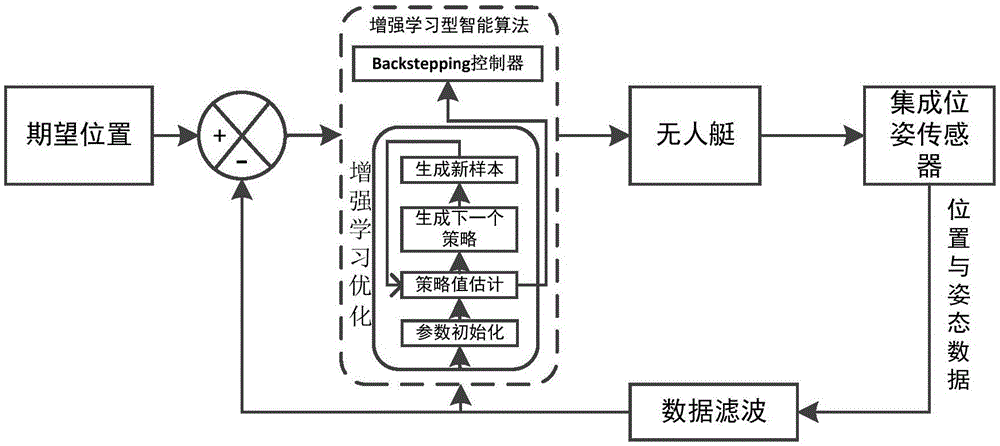
图1为本发明的技术方案的流程图;
图2为船舶北向的滤波值与时间关系曲线图;
图3为船舶东向的滤波值与时间关系曲线图;
图4为艏向角的滤波值与时间关系曲线图。
具体实施方式
下面结合附图举例对本发明作进一步说明。
结合图1,本发明的基于增强学习型智能算法的无人艇航迹跟踪控制,按以下步骤进行:
步骤一、获取船舶的位置和姿态参数:
用位置参考系统测得无人艇的位置信息,用姿态参考系统测得无人艇的艏向姿态信息;对获取的无人艇的姿态及位置信号进行滤波及时空对准,得到无人艇的精确位置及姿态;
步骤二、利用Backstepping法反演控制律:
由期望的位置及姿态与实际的位置及姿态做比较,并经过解算得到误差信号;并利用Backstepping法不断的反演,最终得到使整个无人艇航迹跟踪控制系统稳定的控制律。
步骤三、基于近似策略迭代增强学习的航迹跟踪学习控制:
将控制器优化设计问题建模为Markov决策过程,学习控制成为逼近最优状态行为值函数。由初始化策略产生观测数据集合,进行策略值函数估计后生成新策略,并不断循环此过程直到满足条件学习停止。
步骤一中所述的位置参考系统及姿态参考系统由集成位姿传感器采集数据信息。
步骤一中所述的无人艇姿态及位置信息滤波,采用卡尔曼滤波的方式,以滤除信号中的野值及高频噪声。
步骤一中所述的无人艇姿态及位置信号时空对准的具体内容为,对获取的船舶姿态及位置信号采用曲线拟合的方式进行时间对准,并对不同坐标系下的数据进行空间对准。
利用Backstepping法反演控制律的具体过程为:
对于需要控制的无人艇,其控制力和艇本身存在如下关系式:
式中M为系统的惯量矩阵,Ds为水动力阻尼系数矩阵,为北东坐标系和船体坐标系间的旋转变换矩阵,τ为艇的控制力,f为风浪流干扰力,为误差变量e的一阶导数,为e的二阶导数,同理为R-1的一阶导数,为ηd的一阶导数,为ηd的二阶导数;
令其中μ为待反演的控制律的输出信号,K1为给定的正定增益矩阵,并定义如下状态变量:
构造Lyapunov函数,
上式中,P为正定矩阵,V1,V2为选取的使系统稳定的李雅谱诺夫函数,且x1和x2均按指数收敛于0,经过递推可得到如下的控制律:
μ=Bx2-AP-1x1-AP-1K2x2
其中K2正定对角阵,带入艇的控制力τ的表达式,可得到最终的控制力输出为:
利用近似策略迭代增强学习的智能算法进行航迹跟踪学习控制,具体过程为:
首先,把无人艇的航迹跟踪跟踪器的优化设计问题建模为一个Markov决策问题,以求解Markov决策过程最优值函数和最优策略为目标,通常定义为五元组(S,LA,LP,R,γ)。其中,S为有限或连续状态空间,LA为有限或连续行为空间,R为回报函数,LP为MDP的状态转移概率,γ为决策优化的目标函数。本设计中将MDP的状态定义为三维向量为实际的北东位置及艏向和期望的北东位置及艏向的误差,Backstepping控制器采用自学习优化策略,MDP的行为定义为一系列候选的控制器参数{(K11,K21),(K12,K22),…(K1n,K2n)}。
其中回报函数和目标函数定义为:
R=m|e|
|e|为路径跟随误差,m为负常数,n为加权因子。
然后,采用近似策略迭代增强学习法,解决连续空间的策略逼近与泛化问题,行为值函数Q(s,a)的逼近形式为:
其中s(x,a)为状态-行为对(x,a)的联合特征,αi为加权系数,(xi,ai)为样本点。同时确定行为值函数逼近误差的上界δ:
基于以上的分析,整个算法的流程如下:
1、随机生成初始策略,确定算法停止条件,以及马氏决策过程在初始条件下产生的观测数据。
2、算法初始化,确定迭代次数。
3、迭代循环:
a)对当前数据集合,进行策略值函数的估计。
b)计算策略的优化与改进,并生成下一个策略。
c)生成新的数据样本
d)返回循环
满足条件算法停止。
- 还没有人留言评论。精彩留言会获得点赞!