基于变论域模糊规则迭代学习的玻璃窑炉空燃比调整方法与流程
本发明属于先进制造、自动化和信息领域,具体涉及一种玻璃窑炉空燃比迭代调整方法。
背景技术:
玻璃窑炉的燃烧控制对提高窑炉燃烧效率、降低能耗、较少废气排放、提高玻璃产品质量具有重要作用,其是实现玻璃窑炉温度、压力等高效控制的基础,而空燃比优化设定是燃烧控制的核心内容。在我国实际玻璃生产过程中,窑炉空燃比常被设定为固定值,但由于天然气热值、助燃风温度等生产工况常发生变化,基于定值空燃比进行燃烧控制会对燃烧效率、能耗、废气排放量、玻璃产品质量等指标产生不利影响。
技术实现要素:
本发明提出一种基于变论域模糊规则迭代学习的玻璃窑炉空燃比调整方法,其特征在于,所述方法是在计算机上依次按以下步骤实现的:
步骤(1):初始化,设定如下基本变量
设定问题变量:
x1(t):t时刻的天然气流量
x2(t):t时刻的助燃风流量
y(t):t时刻的烟气含氧量
[ymin,ymax]:烟气含氧量设定值区间
△C:空燃比调整量
C:实际空燃比
CT:理论空燃比
CGas:天然气热值
步骤(2):数据采集
采集一个或多个生产班次的包括上述天然气流量x1(t)、助燃风流量x2(t)、烟气含氧量y(t)信息存储至建模数据库中,并形成训练数据对;
步骤(3):指标预报数据模型建模
根据采样数据建立如下开环Narx回归神经网络的模型为:
y(t)=f2(x1(t),x1(t-1),…,x1(t-9),x1(t-10),x2(t),x2(t-1),…,x2(t-9),x1(t-10),y(t
-1),y(t-2),…,y(t-10))
其中,t为时间,x1(t)为t时刻的天然气流量,x2(t)为t时刻的助燃风流量,y(t)为t时刻的烟气含氧量,f2()为闭环Narx回归神经网络,神经网络隐层为20个神经元。
步骤(4):机理模型建模
根据经验每4186.8Kj发热量的燃料燃烧时,约需1m3的空气量,从而,若热值CGas的单位为Kj/m3,则空燃比的理论模型可建模为:
CT=CGas/4186.8
进而本发明以[CT*0.95,CT*1.05]为空燃比的限定区间。
步骤(5):建立变论域模糊规则
以烟气含氧量实际偏差Eo及其与指标预报模型的预测偏差的变化率ΔEo作为模糊规则的输入,空燃比调整量△C作为模糊规则的输出。模糊决策表设定如下
表1模糊决策表
其实际论域根据Eo和ΔEo自适应调整,即误差较大时,采用大的模糊论域,误差较小时采用较小的模糊论域。
模糊论域划分方法如附图所示。其论域归一化后的每个模糊集的峰点值a1、a2、a3和a4采用步骤(7)给出的基于约束满足的和声搜索算法进行离线搜索,搜索过程按步骤(6)给出的方法建立对象模型。
步骤(6):对象模型建立
采用闭环Narx回归神经网络进行建模
y(t)=f2(x1(t),x1(t-1),…,x1(t-9),x1(t-10),x2(t),x2(t-1),…,x2(t-9),x1(t-10),y(t
-1),y(t-2),…,y(t-10))
其中,t为时间,x1(t)为t时刻的天然气流量,x2(t)为t时刻的助燃风流量,y(t)为t时刻的烟气含氧量,f2()为闭环Narx回归神经网络,神经网络隐层为40个神经元。
步骤(7):设计基于约束满足的和声搜索算法搜索
步骤(7.1):目标函数
在采用变论域模糊规则对空燃比进行调整时,需保证烟气中含氧量在一定的区间范围内,从而和声向量的目标函数定义如下:
f(Xi)=∑|Eo|
其中,Eo是烟气中含氧量的偏差。
步骤(7.2):和声向量
考虑到论域Eo、ΔEo和△C的每个论域均需优化相应的a1、a2、a3和a4。从而,每一个和声向量包含d=4×3=12个和声变量值。令每个和声向量是服从正态分布的属于区间[0,1]的随机数。
设和声库规模为HMS,那么和声库中的第i(i=1,2,…,HMS)个和声向量可表示如下:
其中,代表第一个输入论域模糊划分中模糊数的峰点,需满足
代表第二个输入论域模糊划分中模糊数的峰点,需满足
代表输出论域模糊划分中模糊数的峰点,需满足
步骤(7.3):和声改进机制
对和声库采用记忆考虑、音节调整、随机选择等和声改进机制,能获得一个新的和声向量其中,对于每个和声变量值若随机生成的均匀随机数小于预先给定的和声库考虑概率HMCR,根据按下式给出的记忆考虑方法生成:
其中,a是属于区间[1,HMS]的随机整数。
否则,若上述随机生成的均匀随机数大于或等于HMCR,通过如下的随机选择方法生成:
其中,Randn是服从正态分布的属于区间[0,1]或[-1,0]的随机数,若和声变量对应模糊数的峰点需要小于0,则在[-1,0]取值,否则在[0,1]取值。
进一步,若通过记忆考虑获得,则以微调扰动概率PAR通过如下音节调整方法进行扰动:
其中,是迄今获得的最好和声向量中第j个和声变量值。
步骤(7.4):约束处理
若采用上述方法新生成的不满足和声变量的约束,需交换相邻奇数位和偶数位的和声变量。
步骤(7.5):和声库更新机制
经过和声改进机制,新的和声向量Xnew能被构造,然后,和声库按如下方法进行更新:若Xnew优于和声库中的最差和声XWorst,则将Xnew替换XWorst。
步骤(7.6):迭代搜索机制
迭代步骤7.3-步骤7.5到最大迭代次数,获得优化的和声向量。
根据上述基于指标预报数据和机理相结合的玻璃窑炉空燃比在线调整方法,本发明做了大量的仿真实验,从仿真结果可看出,本发明对玻璃窑炉烟气含氧量的降低有显著的效果。
附图说明
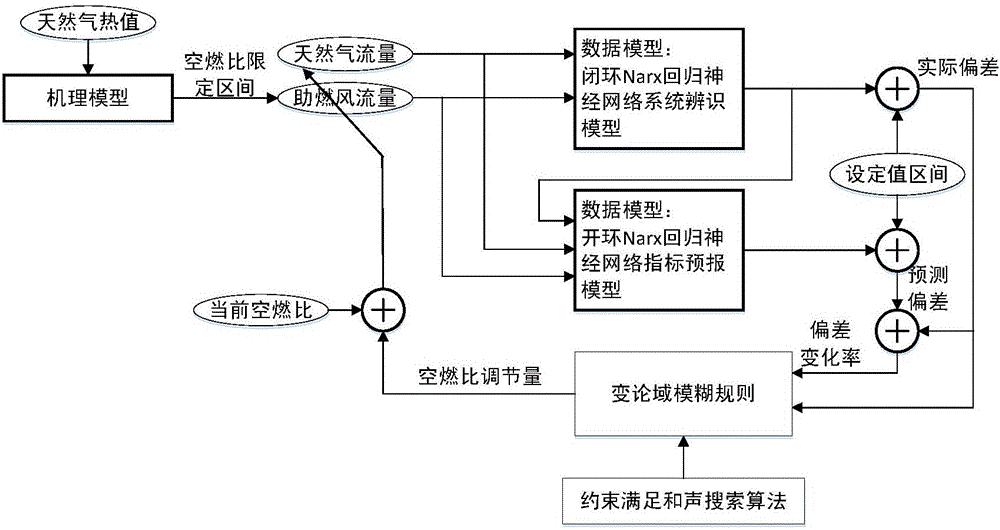
图1:基于指标预报数据和机理相结合的玻璃窑炉空燃比在线调整方法硬件系统结构示意图。图2:基于指标预报数据和机理相结合的玻璃窑炉空燃比在线调整方法流程示意图。
图3:变论域模糊规则论域划分示意图。
图4:烟气含氧量对象模型拟合曲线。
图5:烟气含氧量指标预报模型拟合曲线。
图6:烟气含氧量变化曲线。
具体实施方式
本发明调度方法依赖于相关数据采集系统,有建模客户端和建模服务器实现。在实际玻璃窑炉中应用本发明的软硬件架构示意图如图1所示,本发明的实施方式如下。
步骤(1):初始化,设定如下基本变量
设定问题变量:
x1(t):t时刻的天然气流量
x2(t):t时刻的助燃风流量
y(t):t时刻的烟气含氧量
[ymin,ymax]:烟气含氧量设定值区间
△C:空燃比调整量
C:实际空燃比
CT:理论空燃比
CGas:天然气热值
步骤(2):数据采集
采集一个或多个生产班次的包括上述天然气流量x1(t)、助燃风流量x2(t)、烟气含氧量y(t)信息存储至建模数据库中,并形成训练数据对;
步骤(3):指标预报数据模型建模
根据采样数据建立如下开环Narx回归神经网络的模型为:
y(t)=f2(x1(t),x1(t-1),…,x1(t-9),x1(t-10),x2(t),x2(t-1),…,x2(t-9),x1(t-10),y(t
-1),y(t-2),…,y(t-10))
其中,t为时间,x1(t)为t时刻的天然气流量,x2(t)为t时刻的助燃风流量,y(t)为t时刻的烟气含氧量,f2()为闭环Narx回归神经网络,神经网络隐层为20个神经元。
步骤(4):机理模型建模
根据经验每4186.8Kj发热量的燃料燃烧时,约需1m3的空气量,从而,若热值CGas的单位为Kj/m3,则空燃比的理论模型可建模为:
CT=CGas/4186.8
进而本发明以[CT*0.95,CT*1.05]为空燃比的限定区间。
步骤(5):建立变论域模糊规则
以烟气含氧量实际偏差Eo及其与指标预报模型的预测偏差的变化率ΔEo作为模糊规则的输入,空燃比调整量△C作为模糊规则的输出。模糊决策表设定如下
表1模糊决策表
其实际论域根据Eo和ΔEo自适应调整,即误差较大时,采用大的模糊论域,误差较小时采用较小的模糊论域。
模糊论域划分方法如附图所示。其论域归一化后的每个模糊集的峰点值a1、a2、a3和a4采用步骤(7)给出的基于约束满足的和声搜索算法进行离线搜索,搜索过程按步骤(6)给出的方法建立对象模型。
步骤(6):对象模型建立
采用闭环Narx回归神经网络进行建模
y(t)=f2(x1(t),x1(t-1),…,x1(t-9),x1(t-10),x2(t),x2(t-1),…,x2(t-9),x1(t-10),y(t
-1),y(t-2),…,y(t-10))
其中,t为时间,x1(t)为t时刻的天然气流量,x2(t)为t时刻的助燃风流量,y(t)为t时刻的烟气含氧量,f2()为闭环Narx回归神经网络,神经网络隐层为40个神经元。
步骤(7):设计基于约束满足的和声搜索算法搜索
步骤(7.1):目标函数
在采用变论域模糊规则对空燃比进行调整时,需保证烟气中含氧量在一定的区间范围内,从而和声向量的目标函数定义如下:
f(Xi)=∑|Eo|
其中,Eo是烟气中含氧量的偏差。
步骤(7.2):和声向量
考虑到论域Eo、ΔEo和△C的每个论域均需优化相应的a1、a2、a3和a4。从而,每一个和声向量包含d=4×3=12个和声变量值。令每个和声向量是服从正态分布的属于区间[0,1]的随机数。
设和声库规模为HMS,那么和声库中的第i(i=1,2,…,HMS)个和声向量可表示如下:
其中,代表第一个输入论域模糊划分中模糊数的峰点,需满足
代表第二个输入论域模糊划分中模糊数的峰点,需满足
代表输出论域模糊划分中模糊数的峰点,需满足
步骤(7.3):和声改进机制
对和声库采用记忆考虑、音节调整、随机选择等和声改进机制,能获得一个新的和声向量其中,对于每个和声变量值若随机生成的均匀随机数小于预先给定的和声库考虑概率HMCR,根据按下式给出的记忆考虑方法生成:
其中,a是属于区间[1,HMS]的随机整数。
否则,若上述随机生成的均匀随机数大于或等于HMCR,通过如下的随机选择方法生成:
其中,Randn是服从正态分布的属于区间[0,1]或[-1,0]的随机数,若和声变量对应模糊数的峰点需要小于0,则在[-1,0]取值,否则在[0,1]取值。
进一步,若通过记忆考虑获得,则以微调扰动概率PAR通过如下音节调整方法进行扰动:
其中,是迄今获得的最好和声向量中第j个和声变量值。
步骤(7.4):约束处理
若采用上述方法新生成的不满足和声变量的约束,需交换相邻奇数位和偶数位的和声变量。
步骤(7.5):和声库更新机制
经过和声改进机制,新的和声向量Xnew能被构造,然后,和声库按如下方法进行更新:若Xnew优于和声库中的最差和声XWorst,则将Xnew替换XWorst。
步骤(7.6):迭代搜索机制
迭代步骤7.3-步骤7.5到最大迭代次数,获得优化的和声向量。
基于指标预报数据和机理相结合的玻璃窑炉空燃比在线调整方法的参数选择如下:
●用于指标预报模型建模的数据的采样频率为3秒采;
●烟气含氧量设定范围为[3.05,3.15]
●和声库规模为HMS=50;
●迭代次数为100;
根据上述所提出的基于指标预测和在线学习的微电子生产线调度方法,本发明做了大量的仿真试验,运行的硬件环境为:P4 2.8GHz CPU,1024M RAM,操作系统为Windows、UNIX。
- 还没有人留言评论。精彩留言会获得点赞!