基于JY‑KPLS的复杂工业过程在线质量预测方法与流程
本发明涉及一种基于JY-KPLS的批次过程在线质量预测的方法,属于工业生产过程质量预测领域。
背景技术:
企业产品的质量永远是其在市场竞争中赖以生存的关键。在科学技术飞速发展的今天,能否获得准确的质量预测值比任何时候都更加能引起人们的关注。但是在实际生产过程中,产品最终的实际质量指标往往只能够在生产批次运行结束时离线测量得到,例如生物发酵过程的产品浓度等无法直接在线获得。而离线测量方式通常采样周期较长,几个小时甚至十几小时,测量严重滞后,难以直接用于生产优化。然而这些难以直接测量的参数对于保证产品质量、反映生产过程的运行特征与运行状况以及调整生产策略等都具有极其重要的意义。为了解决这一矛盾,质量预测技术应运而生。
目前质量预测方法主要有两大类,一类是基于机理建模的方法;另一类是基于数据驱动的方法,例如回归分析法和人工神经元网络。基于机理建模的方法建立在事先对工业过程有充分了解的基础上,在面对具有强非线性和模型不确定性的工业过程时,往往难以完成机理建模;而基于数据驱动的方法主要依据过程的可测数据,建模过程并不依赖于过程自身的机理。基于回归分析法的质量预测方法通过对工业生产过程中积累的历史数据进行回归分析,离线的建立质量的预测模型,并进行在线质量预测,其中的偏最小二乘方法(PLS)应用最为广泛。
基于偏最小二乘的质量预测方法使用成分提取的方法建立质量预测模型。在进行主成分提取时,同时考虑输入数据信息和输出数据信息,保证从输入数据和输出数据中所提取出的主成分之间相关性最大,用提取出的主成分进行回归建模。偏最小二乘算法具有对训练数据量要求较少,运算复杂度较低,解释效果较好等优点。
目前,已有相关学者对批次过程质量预测做了一些研究。如赵春晖等,提出了一种基于时段的PLS建模与质量预测方法,适用于解决多段间歇过程的建模与质量预测问题。崔久莉等,提出了一种基于多向核偏最小二乘法的质量预测方法,对当前的一些统计过程监控和质量预测算法进行了改进。曲亚鑫、宋凯等,所提出的方法局限于利用单一过程的数据信息,并且建模过程需要大量的训练数据。董伟威、贾润达、汤健等,所提的建模方法基于核偏最小二乘(KPLS),能够有效的处理系统中的强非线性问题。张曦等,对核函数方法进行了相关研究,并将核方法运用到了青霉素发酵过程的运行监控中。
以上几种方法都是建立在拥有充足数据样本的基础上,对于一个刚投入生产的新批次生产过程,由于生产过程运行的时间较短,通常无法获得充足的过程数据。如果采用类似于上述的建模方法,所建立的预测模型往往预测精度较低无法满足生产需求。而按照传统方法就必须重新设计实验以获取过程数据,这将耗费大量的人力财力,建模效率低下,严重拖慢了新过程实现生产运行优化的速度,不利于企业实时调整生产策略与扩大生产规模。此外,实际生产过程中往往会存在强非线性问题,导致线性的偏最小二乘方法难以适用。
实际的生产过程中,操作条件的改变或者新生产线的建立都将使原先建立的预测模型失效,然而由于新旧过程的内在机理的是一致的,它们之间必然存在一定的相似性。如果能够采用某种策略,利用相似过程中有用的数据信息来帮助新过程建模,将能够避免进行大量的重复试验,提高建模效率。
技术实现要素:
为了克服现有预测方法因新生产过程数据不足而难以建立准确预测模型的不足,本发明提供一种基于JY-KPLS的复杂工业过程在线质量预测方法,利用两个相似过程数据联合建立预测模型,将相似过程中合适的数据迁移应用到新的生产过程中,能够有效克服新的生产过程数据少而无法建立预测模型的问题,能够加快建模速度,可以提高模型预测精度,实现模型更新。
本发明解决其技术问题采用的技术方案是:
一种基于JY-KPLS的复杂工业过程在线质量预测方法,其采用两套完全相同的生产设备,各自的内部参数设置不同,分别进行a过程和b过程两个生产过程,其中,a过程是全新的生产过程且数据少,而b过程的生产时间且长数据丰富;预设过程数据矩阵为X∈RN×J,N为样本数,J为过程变量数;预设输出数据矩阵为Y∈RN,包含输出过程变量;质量预测方法具体步骤如下:
步骤一、将a过程、b过程的三维输入数据按照批次方向展开成二维矩阵,分别为Xa、Xb;
步骤二、对a过程、b过程输入数据矩阵Xa,Xb的各列进行零均值和单位方差处理;同理,对输出数据矩阵Ya,Yb也进行标准化处理,且输出数据Ya与Yb中质量变量的数目相同;
步骤三、将输入数据矩阵Xa、Xb经非线性映射Φ:xi∈RN→Φ(xi)∈F投影到高维特征空间F,并在F空间中计算核矩阵Ka、Kb:Ka=ΦTΦ,Kb=ΦTΦ;
步骤四、对核矩阵Ka、Kb进行标准化处理;
步骤五、对输入核矩阵K和输出矩阵Y运行JY-KPLS算法:
此时输入数据矩阵变为Ka、Kb,输出数据矩阵变为Ya,Yb,从输出矩阵Y中提取收敛的ui,令i=1,KWi=KW,YWi=YW;
a1、令YWi中的任意一列等于ui;
b1、计算Ka的得分向量,t1i=KWiu1i,t1i←t1i/||t1i||;
c1、Kb的得分向量t2i=KWiu2i,t2i←t2i/||t2i||;
d1、计算Y1Wi的得分向量u1i=Y1*qi,u1i←u1i/||u1i||;f1、计算Y2Wi的得分向量u2i=Y2*qi,u2i←u2i/||u2i||;
e1、判断u1i与u2i是否收敛,若收敛则转入步骤六,否则返回a1;
步骤六、计算KWi的负载矩阵:
步骤七、提取出全部主元,计算输入数据矩阵KW的得分矩阵T、输入数据矩阵KW的负载矩阵P、输出数据矩阵YW的得分矩阵U以及输出数据矩阵YW的负载矩阵Q,具体如下:
a2、令
b2、令i=i+1,重复步骤五、六直到提取出A个主元,主元个数A可由交叉验证法确定;
c2、T1=[t1,...,tA],T2=[t1,...,tA],P=[p1,...,pA],U2=[u1,...,uA],Q=[q1,...,qA];若输出数据矩阵Y为单输出变量,则JY-KPLS模型的表达式如下:
y=K*U2(T2*Knx*U2)-1*Tj'*Yj+F,
是a过程输出变量和b过程输出变量的联合,是a过程潜变量和b过程潜变量的联合,即建立质量预测模型所需要得出的最关键变量,可用于运行状态离线质量预测模型的建立;
当引入新的样本knew,其得分矩阵将由下式得出:
其中,knew是新样本xnew的核函数,可由下式计算得到:
knew=Φ(X)Φ(xnew)=[k(x1,xnew),...k(xn,xnew)]T,
对knew进行均值化可得:
其中,1t=1/n·[11...1]T∈Rn;
步骤八、在线获得输入数据数据xnew,无法获得的部分输入数据用均值补齐,利用xnew进行在线质量预测获得预测值并依据预测结果指导生产过程;
步骤九、如果该生产批次结束,则获得最新的输出数据ynew,并计算最新批次的预测误差δn,其中否则返回步骤八;
步骤十、模型预测精度检验,绘制误差曲线;当过程批次大于2J次时(J为过程输入变量总数),获取除最新批次外所有的预测误差δn-1;样本δn-1服从正态分布,求出当显著性α=0.95时的置信区间当最新批次预测误差δn落在置信区间内时,则进入步骤十一;当δn落在置信区间外时,则进入步骤十二;
步骤十一、剔除b过程中与a过程相似程度最小的数据旧过程与新过程的相似程度用相似性s(xi)表示,用公式(10)与(11)可求得s(xi),公式如下:
其中,||||为欧式距离,为新过程数据的均值,s(xi)的取值范围为0到1;
步骤十二、将新测得数据添加到a过程原始数据中组成新的Xa,Ya,并返回步骤一,公式如下:
相比现有技术,本发明的一种基于JY-KPLS的复杂工业过程在线质量预测方法是利用联合Y变量的核偏最小二乘(简称JY-KPLS)技术建立运行状态的离线质量预测模型、批次工业过程的在线质量预测,具体是先利用联合Y的核偏最小二乘法技术离线建立预测模型,即通过步骤一至步骤七完成离线预测模型建立过程,实现JYKPLS模型更新,在线获取决策点所有数据,采用均值填充方式对数据进行补充完整,利用预测模型对产品的质量进行预测。通过将相似过程中已有的历史数据迁移应用到新过程中,解决了新过程难以建立预测模型的问题;与直接利用新过程数据建模的普通偏最小二乘方法相比,该方法能够加快建模速度,使得新的生产过程能够快速投入生产;本方法并不需要两个过程完全相同,对于输入数据的变量数与样本数,该方法不做任何限制,然而由于需要将相似过程的输出数据矩阵联合起来,输出数据的变量数目必须相同。同时,为了解决过程中的非线性问题,本方法引入了核函数方法,核方法通过将获取到的输入数据映射到高维特征空间中,使原本非线性不可分的原始数据变得线性可分,从而降低了数据本身的非线性度,可以在核空间中应用偏最小二乘算法对数据进行分析,引入核方法使本方法能够适用于处理具有高度非线性的实际工业生产过程。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明质量预测方法的流程图。
图2为决策点不同时批次青霉素质量预测相对误差。
图3为青霉素质量预测的浓度相对误差对比。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
基于JY-KPLS(JY-KPLS是联合Y变量的核偏最小二乘的简称)的复杂工业过程在线质量预测方法,其采用两套完全相同的生产设备,各自的内部参数设置不同,分别进行a过程和b过程两个生产过程,其中,a过程是全新的生产过程且数据少,而b过程的生产时间且长数据丰富;预设过程数据矩阵为X∈RN×J,N为样本数,J为过程变量数;预设输出数据矩阵为Y∈RN,包含输出过程变量;质量预测方法具体步骤如下:
步骤一、将a过程、b过程的三维输入数据按照批次方向展开成二维矩阵,分别为Xa、Xb;
步骤二、对a过程、b过程输入数据矩阵Xa,Xb的各列进行零均值和单位方差处理;同理,对输出数据矩阵Ya,Yb也进行标准化处理,且输出数据Ya与Yb中质量变量的数目相同;
步骤三、将输入数据矩阵Xa、Xb经非线性映射Φ:xi∈RN→Φ(xi)∈F投影到高维特征空间F,并在F空间中计算核矩阵Ka、Kb:Ka=ΦTΦ,Kb=ΦTΦ;
步骤四、对核矩阵Ka、Kb进行标准化处理;
步骤五、对输入核矩阵K和输出矩阵Y运行JY-KPLS算法:
此时输入数据矩阵变为Ka、Kb,输出数据矩阵变为Ya,Yb,从输出矩阵Y中提取收敛的ui,令i=1,KWi=KW,YWi=YW;
a1、令YWi中的任意一列等于ui;
b1、计算Ka的得分向量,t1i=KWiu1i,t1i←t1i/||t1i||;
c1、Kb的得分向量t2i=KWiu2i,t2i←t2i/||t2i||;
d1、计算Y1Wi的得分向量u1i=Y1*qi,u1i←u1i/||u1i||;f1、计算Y2Wi的得分向量u2i=Y2*qi,u2i←u2i/||u2i||;
e1、判断u1i与u2i是否收敛,若收敛则转入步骤六,否则返回a1;
步骤六、计算KWi的负载矩阵:
步骤七、提取出全部主元,计算输入数据矩阵KW的得分矩阵T、输入数据矩阵KW的负载矩阵P、输出数据矩阵YW的得分矩阵U以及输出数据矩阵YW的负载矩阵Q,具体如下:
a2、令
b2、令i=i+1,重复步骤五、六直到提取出A个主元,主元个数A可由交叉验证法确定;
c2、T1=[t1,...,tA],T2=[t1,...,tA],P=[p1,...,pA],U2=[u1,...,uA],Q=[q1,...,qA];若输出数据矩阵Y为单输出变量,则JY-KPLS模型的表达式如下:
y=K*U2(T2*Knx*U2)-1*Tj'*Yj+F,
是a过程输出变量和b过程输出变量的联合,是a过程潜变量和b过程潜变量的联合,即建立质量预测模型所需要得出的最关键变量,可用于运行状态离线质量预测模型的建立;
当引入新的样本knew,其得分矩阵将由下式得出:
其中,knew是新样本xnew的核函数,可由下式计算得到:
knew=Φ(X)Φ(xnew)=[k(x1,xnew),...k(xn,xnew)]T,
对knew进行均值化可得:
其中,1t=1/n·[11...1]T∈Rn;
通过步骤一至步骤七完成离线预测模型的建立过程,进而对应实现图1 中的JYKPLS模型更新。
步骤八、新生产批次开始,在线获得输入数据数据xnew,无法获得的部分输入数据用均值补齐,利用xnew进行在线质量预测获得预测值并依据预测结果指导生产过程;
步骤九、如果该生产批次结束,则获得最新的输出数据ynew,并计算最新批次的预测误差δn,其中否则返回步骤八;
步骤十、模型预测精度检验,绘制误差曲线;当过程批次大于2J次时(J为过程输入变量总数),获取除最新批次外所有的预测误差δn-1;样本δn-1服从正态分布,求出当显著性α=0.95时的置信区间当最新批次预测误差δn落在置信区间内时,则进入步骤十一;当δn落在置信区间外时,则进入步骤十二;
步骤十一、剔除b过程中与a过程相似程度最小的数据旧过程与新过程的相似程度用相似性s(xi)表示,用公式(10)与(11)可求得s(xi),公式如下:
其中,||||为欧式距离,为新过程数据的均值,s(xi)的取值范围为0到1;
步骤十二、将新测得数据添加到a过程原始数据中组成新的Xa,Ya,并返回步骤一,公式如下:
下面将提供仿真实例,对本发明的技术方案效果作更加详细的说明。
青霉素是微生物的次级代谢产物,主要通过微生物发酵的途径生产,高成本与高耗能是青霉素发酵过程的特性。因此,优化青霉素发酵生产过程,对于降低青霉素生产成本和提高青霉素产量具有重要意义。为了能够及时掌握产品的质量,实现青霉素发酵过程的实时优化,可将本方法运用于的青霉素质量在线预测中。
当前的青霉素工业生产过程中,补料分批的发酵方式占主导地位。青霉素的生产过程是一个典型的非线性、动态、多阶段间歇生产过程。青霉素的发酵过程PH值和温度采用闭环控制,而补料采用开环值控制,通过控制反应过程中PH值和发酵反应器内的温度,可以使反应在最佳条件下运行。整个生产周期包含了四个生理期:反应滞后期,菌体迅速生长期、青霉素合成期、菌体死亡期;两个物理子时段:细胞培养阶段(对应前两个生理期,大约持续45h)与青霉素补料发酵阶段(对应后两个周期,大约持续355h)。作为二次微生物代谢过程,该发酵过程通常的做法是首先在一定条件下进行微生物的培养,此为初始培养阶段,然后通过不断地补充葡萄糖促进青霉素的合成,此谓青霉素发酵阶段。
通过对青霉素生产过程的深入分析并考虑现场的实际生产过程,可选取6个过程变量和1个输出变量用于青霉素质量的在线预测。这6个过程变量分别是:通风率、底物喂料温度、搅拌功率、培养基体积、CO2的浓度,PH值;1个输出变量是:青霉素浓度。各输入输出变量如表1所示:
表1输入输出变量表
1)浓度预测模型的建立
伊利诺伊科技学院的Cinar教授开发了青霉素发酵过程的仿真软件Pensim2.0,方便了青霉素数据的获取。该软件能够对不同操作条件下青霉素生产过程的微生物浓度、浓度、CO2值、PH值、青霉素浓度、碳浓度、氧浓度以及产生的热量等进行仿真。所需设定的初始化参数包括:反应时间、采样时间、生物量、发酵环境、温度控制参数、pH控制参数。利用此软件获得了a生产过程获取46个批次的数据,其中5个批次的数据用于建模,41个批次的数据用于检验。b生产过程获取40个批次的数据,用于青霉素浓度预测模型的建立。利用a生产过程的5个批次和b过程的40个批次数据按照上述的方法进行建模,然后利用a过程剩余的41个批次数据进行检测。
2)预测时间的确定
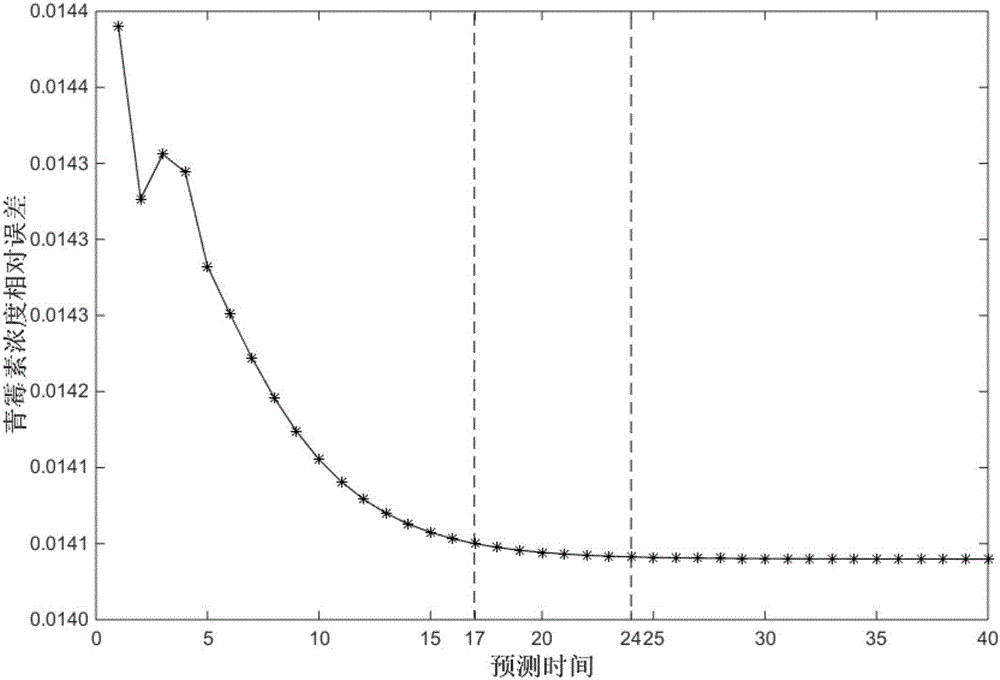
在线预测过程中,需要足够的输入数据才能获得较为满意的预测结果,未知的输入数据可以用均值代替。因此预测时间的选取非常重要,预测时间太早会使得青霉素浓度的预测误差太大,时间太晚又会影响在线预测的有效性。为了求得最佳预测时间点,这里选择第一个批次的数据进行测试,每隔10h分别进行一次质量预测,得到的数据绘制在图2中。由图2可以看出,当预测时间大于17(170h)时,预测误差已经非常接近最小值,因此可以将预测时间的定在170到240h之间,本次仿真将预测时间定在200h处。
3)基于JY-KPLS的青霉素质量在线预测
为了对所提供的基于JY-KPLS的质量预测方法进行检验,这里使用相同的批次数据与基于KPLS的质量预测方法进行比较,结果如图3所示。从图3的前12批次中可以看出,在生产过程的初期,利用JY-KPLS的预测误差明显小于KPLS,因此JY-KPLS的预测模型能够有效地加快预测模型的建立,获得了令人满意的控制性能。需要强调的是,新过程数据越少对JY-KPLS越有利,对KPLS越不利,因此这里选择新过程运行初期的数据进行对比,以体现本方法的优势。
4)旧数据的数据剔除
随着生产批次数的增加,新过程数据样本不断的扩充,KPLS方法的预测精度也因此不断提高。JY-KPLS方法的预测精度同样随批次数的增加而提高,但由于其中相似过程数据的存在,其提高速度明显不如KPLS方法。因此为了进一步提高预测精度,有必要用新获得的生产数据对旧数据进行剔除。
根据说明书中的方法可以求得剔除点为第18个批次,因此按照上述方法从第18个批次开始对旧数据进行剔除,结果如图3所示。从图3中可以看出,当每次都剔除掉相似性s(xi)最低的旧数据时,整体的预测精度得到了进一步的提高,基于JY-KPLS的预测方法再一次拉大了与KPLS方法之间的差距。
通过以上仿真实例可以看出,本发明利用两个相似过程数据联合建立预测模型,将相似过程中合适的数据迁移应用到新的生产过程中,能够有效克服新的青霉素生产过程数据少而无法建立预测模型这一问题。核函数方法非常适合处理具有高度的非线性、时变性以及模型的不确定性的青霉素发酵过程。利用基于潜变量迁移的批次工业过程质量预测方法(JY-KPLS)离线建立质量预测模型,能够加快建模速度,对青霉素的最终浓度进行预测具有重要实际意义的。本方法利用每一批次结束后产生的新数据对模型进行更新,能够不够提高模型预测精度,实现模型自适应。在获得足够的新过程数据后,对旧过程中相似性较低的数据进行剔除,以消除旧数据自身偏差所产生的影响。借助于预测的结果,现场操作人员就可以及时调整和改进生产策略,提高生产效率。
以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质,对以上实施例所作出任何简单修改和同等变化,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!