一种仿操作性条件反射的神经网络非线性控制方法与流程
本发明涉及非线性系统控制领域和神经网络控制领域,特别涉及一种用于处理复杂不确定系统的未知非线性项的方法。
背景技术:
人工神经网络(ann)因其能够逼近任意范数上的非线性函数这一特征,常作为一种倍受青睐的数学工具在非线性系统控制领域广泛应用。在诸多成果中,神经网络控制器可分为三种类型:离线训练权值的i型控制器,基于固定网络结构的在线权值学习ii型控制器,以及网络结构可调节的在线权值学习iii型控制器。
截至目前,绝大多数研究工作集中在以i型和ii型控制器为主的设计与开发中。然而i型控制器缺乏离线权值训练网络的自适应能力,ii型控制器在初始化时要求预置大量神经元,导致控制性能在很大程度上取决于人工选取的神经元个数与相应的结构参数,因此通常会消耗巨大的系统运算资源并产生过拟合的现象。为突破ii型控制器的使用局限性,基于权值与网络结构均能自动调整的iii型控制器相继出现。以自动确定网络节点数为设计目标,iii型控制器旨在避免通过人工方式引入过多神经元而造成的运算负担和过度参数化问题。但iii型控制器出现的时间比较短,其理论体系尚不健全,存在很多值得深入讨论和不可预见的问题。例如,如何在系统运行期间自动生成合适数目神经元的神经网络,如何简化控制器结构和繁琐的稳定性分析过程,如何避免会消耗过多运算资源的参数估计算法,如何优化网络拓扑结构进一步以提升神经网络控制的有效性、灵活性与自适应性等等。这些都需要以iii型神经控制器为雏形,对具有自构造能力的神经网络控制方法进行优化与改进。
技术实现要素:
有鉴于此,本发明的目的是提供一种仿操作性条件反射的神经网络非线性控制方法,以实现在非线性系统控制中减少了人工调参工作,不依赖精确的漂移非线性信息,无需离线训练与停机再编程过程,具有更加宽泛的系统运行条件,并且能够在确保控制精度的同时消耗较少的系统运算资源。
本发明仿操作性条件反射的神经网络非线性控制方法,包括以下步骤:
步骤一、建立操作性条件反射仿生模型:
将网络中的神经元按神经活动的不同进行分类,具有相同神经活动的神经元构成一个神经自适应单元,总体网络由m个神经自适应单元组成,则第i个神经自适应单元的神经活动:
其中,μi∈rq,σi∈r为第i个神经元簇的参数,z=[z1,z2,...,zq]t为神经网络输入;根据奖励行为最大化神经活动原理,μi由下式获得:
其中,ri表示第i个奖励事件发生的时刻。
步骤二、建立基于操作性条件反射仿生模型的一类非仿射系统:
其中,系统状态向量x=[x1,...,xn]t∈rn,系统输入/控制器信号u∈r,系统输出为y∈r;fξ(t)(·)表示结构随时间漂移的未知非线性模型,具体形式如下:
fξ(t)(·)={fi(·)|i=ξ(t)∈n+,0≤ti≤t<ti+1}
且fξ(t)(·)满足
定义系统状态误差向量e(t)和滤波误差s(t)分别为
e(t)=x-xr=[e1,e2,...,en]t∈rn
s(t)=[kt1]e
其中,xr=[x1r,x2r,...,xnr]t为期望状态向量,k=[k1,k2,...,kn-1]t为hurwitz多项式系数,取
步骤三:利用ocbm仿生网络设计控制器u:
针对如上所述非仿射受控系统,设计控制器u为:
控制器u由监督控制器us,仿生网络渐近器ubio,以及补偿器uc(s,e)组成;其具体表达为:
uc(s,e)=-kps-ηsat(s/β0)-λ
其中
其中m为神经自适应单元个数,gi(z)为高斯函数,
其中,ρ为权值学习速率,i为(q+1)阶单位矩阵,χ>0为设计常量。
步骤四:将控制器u作用到步骤二建立的非仿射系统,使输出y(t)按给定精度β0跟踪期望轨迹xd(t),同时确保系统跟踪误差e(t)在t≥0有界。
本发明的有益效果:
本发明仿操作性条件反射的神经网络非线性控制方法,其从操作性条件反射的生物学原理出发,构建出一种受仿生启发的人工神经网络并将其用于处理复杂不确定系统的未知非线性项,并针对一类不确定非仿射系统设计出基于操作性条件反射模型的控制策略,使得该类不确定非仿射系统控制能减少人工调参工作,不依赖精确的漂移非线性信息,无需离线训练与停机再编程过程,具有更加宽泛的系统运行条件,并且能够在确保控制精度的同时消耗较少的系统运算资源,提高了神经网络控制的有效性、灵活性与自适应性。
附图说明
图1是具有神经自适应单元的仿生神经网络基本组成原理示意图;
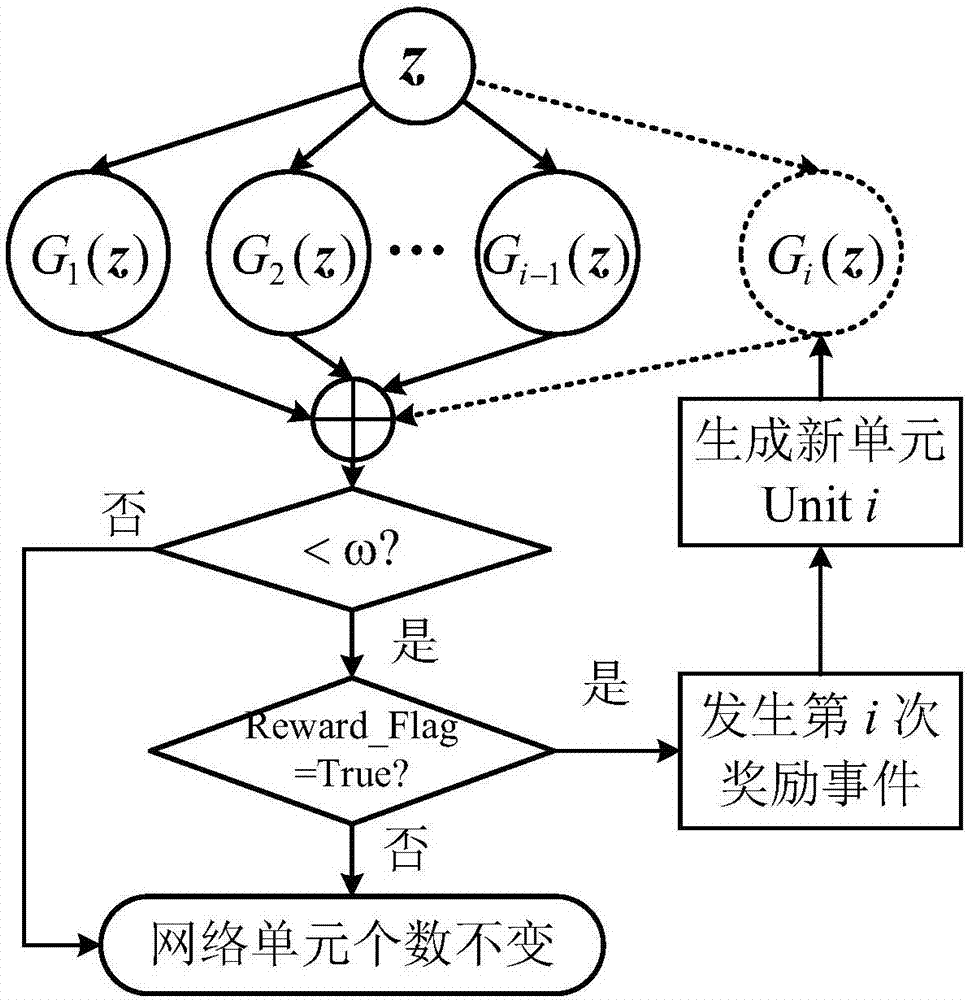
图2是构建第i个神经自适应单元的基本流程示意图;
图3是基于操作性条件反射仿生模型(ocbm)的仿生神经网络结构原理图;
图4是使用ocbm与传统自组织渐近控制(soac)方法所得滤波误差演变情况曲线图;
图5是使用ocbm与soac方法所得控制信号输出演变情况曲线图;
图6是使用ocbm方法所得f0系统状态相位图曲线图
图7是使用soac方法所得f0系统状态相位图曲线图;
图8是神经自适应单元的数目演变情况曲线图。
具体实施方式
下面结合附图和实施例对本发明作进一步描述。
本实施例仿操作性条件反射的神经网络非线性控制方法,包括以下不步骤:
步骤一、建立操作性条件反射仿生模型:
在高等生物的神经系统中,神经元包体在神经中枢区域聚集形成神经核,功能相似的神经核集合形成神经核团。受这一原理启发,本发明将网络中的神经元按神经活动的不同进行分类,使具有相同神经活动的神经元构成一个神经自适应单元,总体网络由有m神经单元组成,则第i个神经单元的神经活动:
其中,μi∈rq,σi∈r为第i个神经元簇的参数,z=[z1,z2,...,zq]t为神经网络输入。可见,神经网络皮质输入z对神经活动具有直接影响。当μi=z时,gi(z)可以取得最大值。根据奖励行为最大化神经活动原理,μi由下式获得:
其中,ri表示第i个奖励事件发生的时刻。换言之,如果个体的某一行为使其神经活动得以最大化,则多巴胺神经元将会自动记录该行为并存入μi中,进而通过gi(z)影响uniti的输出gi。以此类推,当第m个奖励事件发生后,unitm将被激活,并形成gm(z)。如图1所示,随着奖励事件的发生,神经元簇被相继激活,使得神经网络的整体结构呈现基本的自构造能力。
生成新的第i个神经自适应单元的具体过程为:1)根据当前的行为偏差s(t),奖励信号标志位reward_flag被赋为真值;2)在已生成的(i-1)个单元中,所有神经元的神经活动满足0<gsum<ω。图2给出了自动建立uniti的基本流程。可见,通过研究个体的操作性条件学习机制对传统人工神经元结构进行优化具有一定的生物合理性。
图3给出了基于操作性条件反射模型的仿生神经网络结构图。该网络新颖之处在于其能够在一定程度上模拟生物神经系统在学习期间脑内结构的自动更新过程。结合行为心理学与神经生理学的客观事实与发现,通过研究脑在操作性学习期间所发生的一系列变化,探索性地提出了一种仿生学习的人工神经元模型。具体地,(1)整体网络的输出gbio由不同unit的输出加权和求得,而非简单的累加和形式;(2)unit的生成规则基于所设计的奖赏策略、行为偏差和系统当前的神经活动。每生成一个新unit,才会相应引入(q+1)个神经元及(如图3中虚线所示部分),因此不会造成无用/无关神经元的引入,从而节省系统运算资源和学习成本;(3)每个unit的突触权值和基函数结构参数均在系统运行过程中自动更新,进而避免了繁琐的人工选参和调参步骤。综上,相比传统人工神经网络,所提模型具有相对健全的自学习、自适应和自构造能力。
步骤二、建立基于操作性条件反射仿生模型的一类非仿射系统:
其中,系统状态向量x=[x1,...,xn]t∈rn,系统输入/控制器信号u∈r,系统输出为y∈r;fξ(t)(·)表示结构随时间漂移的未知非线性模型,具体形式如下:
fξ(t)(·)={fi(·)|i=ξ(t)∈n+,0≤ti≤t<ti+1}
且fξ(t)(·)满足
定义系统状态误差向量e(t)和滤波误差s(t)分别为
e(t)=x-xr=[e1,e2,...,en]t∈rn
s(t)=[kt1]e
其中,xr=[x1r,x2r,...,xnr]t为期望状态向量,k=[k1,k2,...,kn-1]t为hurwitz多项式系数,取
步骤三:利用ocbm仿生网络设计控制器u:
针对如上所述非仿射受控系统,设计控制器u为:
控制器u由监督控制器us,仿生网络渐近器ubio,以及补偿器uc(s,e)组成;其具体表达为:
uc(s,e)=α
其中
其中m为神经自适应单元个数,gi(z)为高斯函数,
其中,ρ为权值学习速率,i为(q+1)阶单位矩阵,χ>0为设计常量,则有如下闭环控制系统特性成立:
(1)存在常数tf>0,使得|s(t)|<β1,
(2)在系统运行期间,|s(t)|>β0的总时间ta有限;
(3)当t→∞,有|s(t)|≤β0且|ek(t)|≤2k-1λk-nβ0,k=1,…,n;
步骤四:将控制器u作用到如上非仿射系统,使输出y(t)按给定精度β0跟踪期望轨迹xd(t),同时确保系统跟踪误差e(t)在t≥0有界。
下面对本实施例仿操作性条件反射的神经网络非线性控制方法的有效性进行仿真验证:
考虑如下的二阶非仿射系统:
其中,x=[x1,x2]t,fξ(t)(x,u)为未知漂移非线性模型。本实施例采用不随时间漂移的固定结构系统模型,与传统自组织渐近控制(soac)方法进行对比,验证ocbm方法的有效性。
给定理想轨迹xd(t)=3sin(0.1πt),期望状态向量
令fξ(t)(x,u)=f0(x,u)对t≥0成立,且
f0(x,u)=3u+2sin(u)+0.5cos(x1+x2)
式us(s,λ)中取c=1,可知满足|f0(x,0)|≤c(x)<c。
图4与图5分别描绘了使用ocbm和soac方法所得滤波误差和控制信号输出的演变情况,其内的两幅子图分别为t∈[5,10]和t∈[58,60]的放大结果。由图可见,两种控制方法均可使滤波误差随时间收敛。在整个系统运行期间,传统自组织型控制器会使滤波误差产生较多抖动,而在实施例所提ocbm控制器作用下,滤波误差与控制动作的变化则相对光滑。这也表明基于ocbm的仿生控制具有更好的内部调节能力,其可以避免激起系统的高频振荡,从而延长设备的使用寿命。
图6、图7先后给出了基于ocbm与soac两种方法的系统状态相位图。“×”表示第i次奖励行为对应的系统状态信息。以“×”为圆心绘制的实线圆域表示ann训练输入的紧集区域,且每个紧集对应唯一神经自适应单元(图中由unit标记并区分)。此外,仿生网络渐近器ubio对实线圆域内的系统状态有效,在实线圆域外的状态使用监督器us及补偿器uc进行控制。可以看出,两种方法的系统实际运行轨迹均能跟踪给定理想轨迹,而采用ocbm方法可以产生数量相对较少且区域大小能够实时自动调节的神经自适应单元。
图8体现了神经自适应单元数目随时间的变化情况。注意到大约25秒后,两种控制方法的unit均达到稳定值并不再继续增加。然而,采用soac方法最终生成23个unit,而ocbm方法仅生成9个。可见,在执行同一控制任务时,基于ocbm的控制器可大幅减少系统产生的神经元总数,从而节省系统运算资源。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!