基于智能家居环境中ZigBee固件升级的镜像文件轻便解压算法的制作方法
本发明涉及在智能家居环境中的zigbee节点固件升级过程实现一种对镜像文件轻便的解压缩算法,具体涉及一种对于已经被哈夫曼编码压缩的zigbee固件升级镜像文件,在zigbee智能节点对其进行解压缩处理,属于智能物联网领域。
背景技术:
现代科学技术使个人的生活环境更加方便,舒适,自动和安全。智能家居逐渐走进了人们的生活。文献1:handm,limjh.smarthomeenergymanagementsystemusingieee802.15.4andzigbee[j].consumerelectronics,ieeetransactionson,2010,56[3]:1403-1410.提出智能家居是一个家庭监控系统具有安装简单、操作方便的特点。在智能家居环境中有许多技术都在被广泛应用,例如蓝牙,wifi,6lowpan,zigbee等。zigbee技术的特点是近距离,低复杂性,自组织,低功耗和低的数据速率因而被广泛用于自动控制,远程控制和各种嵌入式设备。因此本文选择zigbee技术作为支持技术来搭建智能家居环境。由于zigbee终端节点的资源有限,如存储器大小,通信带宽和处理能力等方面因素,如何能够完成资源节约型的固件更新成为一种挑战。通常使用的方法是将升级所需的镜像文件在发送传输之前进行压缩,在智能zigbee端点进行固件镜像的解压缩并用它来升级芯片当前的应用程序。镜像发送者通常是资源相对丰富的家庭网关。相比之下的接收机端,即zigbee的端点却是资源有限的嵌入式芯片。如图1.所示,基于zigbee技术的智能家居环境包含一个智能家居网关,一是zigbee网络加密狗节点与网关通过有线连接,同时与其它zigbee端点无线连接。固件映像将在家庭网关压缩并通过zigbee加密狗传输至需要升级的zigbee端点。zigbee的端点解压缩新固件并且替换原来的程序代码来完成整个更新过程。
因此zigbee的固件更新中的一个挑战就是如何使解压过程中使用尽可能少的资源成为可能。本文的目的是设计一个灵活轻便的解压缩算法,以满足有限的资源固件升级情况。文献2:d.huffman,“amethodfortheconstructionofminimumredundancycode”,proc.ire,vol.40,pp.1098-1101,1952.提出huffman编码是一个非常典型的压缩编码技术,本发明决定先使用哈夫曼编码来对压缩固件映像,然后zigbee加密狗将其广播到zigbee网络,随后zigbee终端使用灵活的算法来解压huffman编码压缩的固件镜像。主要工作集中在端点如何有效地解压镜像。
文献3:linyk,huangsc,yangch.afastalgorithmforhuffmandecodingbasedonarecursionhuffmantree[j].journalofsystemsandsoftware,2012,85(4):974-980.专注于huffman解码的时间效率,它利用了数值解析加快解码处理。文献4:aggarwalm,narayana.efficienthuffmandecoding[c]//imageprocessing,2000.proceedings.2000internationalconferenceon.ieee,2000,1:936-939.提出了一种memoryefficient数组来表示的哈夫曼树,以便减少内存大小和加速搜索中的哈夫曼树符号的过程。它们都集中于解码处理。此外,也有关于编码处理的设计,以提升解码效率的工作。文献5:faller,n.1973.anadaptivesystemfordatacompression.recordofthe7thasilomarconf.oncircuits,systemsandcomputers(pacificgrove,ca.nov.),593-597.提出了一种自适应哈夫曼编码以使得哈夫曼编码树的存储空间减少到零。在某种特定的条件约束情况下,解码器可动态地重建与编码器同步哈夫曼编码树,而无需任何附加数据。文献6:moffata.andturpina.,"ontheimplementationofminimumredundancyprefixcodes",ieeetransactionsoncommunications,vol.45,no.10,1200-1207.的优点是不需要受位操作的限制,可以一次性多位读取比特流,在一定程度上提高了解码效率。对于该算法,文献7:nekrichy.,"onefficientdecodingofhuffmancodes",technicalreportno.85190-cs,departmentofcomputerscience,bonnuniversity,april1998.提出了所确定的编码长度上进行改进即可以将最小码长做成一个二叉树,通过使用这个二叉树可以更快地确定出编码长度。虽然这样的改进是优化了逐位操作的问题,但仍需要计算编码的长度,文献8:shmuelt.klein,"space-andtime-efficientdecodingwithcanonicalhuffmantrees",8thannualsymposiumoncombinatorialpatternmatching,aarhus,denmark,30june-2july1997,lecturenotesincomputerscience,vol.1264,65-75.讨论了基于并不需要计算固定码长的查表算法。该解码算法虽然是高效的,但是当最大码长较大时,表的初始化会花费更多的时间和空间代价,这是不适合小规模数据解码和存储空间紧张的场景。鉴于此,文献9:sieminskia.,"fastdecodingofthehuffmancodes",informationprocessingletters,vol.26,1988,237-241.提出了一种优化查找表的算法。该算法提出先使用一个固定码长解码,则该码长可以直接解码或是其他解码前缀,通过继续读取几位比特数据方可解码,这样大大减少了表的空间。虽然在减少表的空间上都做了很多工作,但是在解码端都需要重构哈夫曼树,对于哈夫曼树的存储是无法避免的。本发明提出了一个基于哈夫曼树的汉密尔顿回路构建的解码数组,考虑到zigbee嵌入式资源有限环境,本发明在与传统哈夫曼解压算法对比后的优化目标有两个:
(1)满足最小哈夫曼树的存储空间占用。
(2)最佳解码效率。
本发明的重大贡献在以下几个方面:
(1)针对嵌入式设备,提出了一个有效的zigbee镜像数据解压缩算法:哈夫曼树的汉密尔顿回路解压缩算法(hhd)。
(2)对于hhd解压算法给出了用于解压的解码数组生成算法。
(3)通过对照hhd算法生成的解码数组对镜像文件进行轻便解压。
技术实现要素:
对于哈夫曼树的存储方式一般有两种方法即顺序存储和链表存储。由于顺序存储结构的特征是使用数组来存储二叉树因而占用更少的内存,这个特点很适合于嵌入式方案中。另外由于数组存储结构可以随机读取数据,通过数组下标与逻辑地址的对应关系,顺序存储进行相应解码。然而顺序地存储的缺点是当码长度较长或者是单支结构哈夫曼树时,数组中出现很多空的占位单元,顺序存储空间将会显著地增大。而且在解码时,根据读取的一串比特流对哈夫曼二叉树进行遍历来寻找对应码字,空单元占位较多情况下浪费了大量的查找时间和对比计算时间消耗。然而,链表存储虽然可以精确的根据指针进行解码查询,但是它却花费了大量的存储空间来存储父节点或子节点的指针,这种较大的内存消耗不适合嵌入式环境。因此,本发明根据对比以上两种哈夫曼树的数据结构的优点和缺点,设计发明了一种新的哈夫曼树的数据存储结构。通过使用数组存储哈夫曼树信息,建立特定的数组下标和逻辑地址的映射关系,可以实现如指针一样的精确跳转搜索功能。这种新型数据存储结构既满足了数组存储的占用空间小的特点,同事也满足了指针精准跳转解码的功能。最后,根据这个解码数组可以很轻便地得到解压缩的码字。
本发明的技术方案如下:基于智能家居环境中zigbee固件升级的镜像文件轻便解压算法,其特征在于,包括以下步骤:
步骤一、利用一个二维数组来记录所有非叶子节点的属性,每个行向量单元有四个数值,分别记录该节点的左侧孩子节点的地址和码值,右侧孩子节点的地址和码值;左侧孩子为0右侧孩子是1,设定第一根节点编号为1,左侧孩子是2,右侧孩子是3,右侧孩子节点被标记为寻路开始节点,左侧孩子节点被标记为寻路结束节点并且规定处在越高层的寻路开始节点拥有更高的优先级设置,而处在越高层的寻路结束节点拥有较低的优先级;
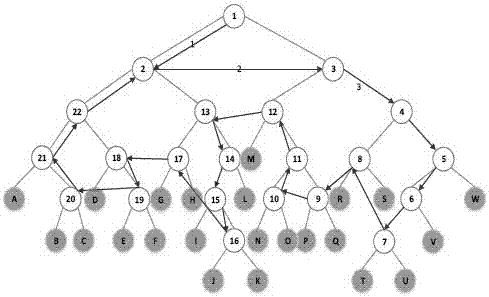
步骤二、对于一个单元的二进制树中的标记制定规则,在标志着所有的节点后,按照寻路规则绘画出一条闭合的汉密尔顿回路,当汉密尔顿回路闭合至2号节点,编号工作完成;
步骤三、使用一个数组来记录节点的信息,采取n[x][y]实例来表示阵列:0<x<n,0<y<5。该二维数组的定义如下:使用单元行向量记录节点属性:n[x][1]存储左子节点值;n[x][2]的存储右侧孩子节点的值;n[x][3]存储左子节点编号;n[x][4]的存储右侧孩子节点编号。如果节点不是叶,其值为null,如果节点是叶,该值是它的解码字且它的编号是零,标志着这段比特流解码的结束。当一段比特流解码结束后,开始从n[x][1]新的比特流进行重新搜索解码;
步骤四、根据hhd阵列生成算法,哈夫曼树将重新生成的解码数组的顺序存储结构,即,所述物理地址和数组下标地址是映射关系且可随机读取的数据。
步骤四的解码解码过程是读取二进制比特流,通过对照新的解码数组。根据该数组中的设定,左边为0,右边是1。输入的二进制比特流,如10110101110000...搜索数组:第一位比特是1,读取n[1][4]并且赋值x=n[1][4]。接着比特为0,读n[x][3]且赋值x=n[x][3],直到当比特是0,x=0时,解码码值等于n[x][1]或者当比特为1,x=0时,解码码值等于n[x][2]的,之后,继续读下一个比特位,从[1][y]重新开始跳转搜索解码,并执行循环操作,直到解码完成。解压缩算法数组中“lv”是左侧孩子节点的码值与“rv”是右侧孩子节点的码值,在“ln”是左侧孩子节点的编号和“rn”是右侧孩子节点的编号。
步骤二的标记的规则如下:左侧孩子节点被标记为二叉树寻路的结束标志,右侧孩子节点为寻路开始标志;当两个子节点中有且只有一个是叶节点,另一个非叶子的节点继承其父节点的信息标志;当两个孩子节点都是叶节点,标记其码值;更高层的寻路开始节点具有较高的优先级而更高层的结束节点具有较低的优先级,在标志着所有的节点后,按照寻路规则绘画出一条闭合的汉密尔顿回路;汉密尔顿回路的寻路规则是:起点出发闭合到终点,终点与下一个最近的起点相连;起始节点分支寻路方向是从顶部到底部,结束节点的方向是从底部到顶部;在最近同一分支,任何开始节点的优先级比任何结束节点大;节点的优先级越高越先被标号并且节点编号顺序依照寻路顺序。
本文通过构建这个数组记录非叶子节点的属性作为一个数据单元。实验结果表明,该算法的优点:
(1)在zigbee镜像压缩文件中,压缩平均码长为约6。因此,只需花费平均六个步骤来获得其解码码字,在解码时间消耗的性能上提高20倍以上。通过减少了解码时间,相应的在嵌入式设备上减少了计算、搜索、跳转步骤,这也将节省一些能量。
(2)哈夫曼树存储方式使用数组来存储,该存储空间比链表存储和顺序存储方式都要小。很明显本发明的算法减少了哈夫曼解码过程的空间成本的消耗。因为有很多空的占位符数据,同时也为未来进一步优化提供了空间。
本发明的算法创新之处在于它将哈夫曼树生成一个特殊约定的解码数组,可以根据该数组下标随机读取被直接解码数据,解码效率大大增加。但是,这种设计的代价是增加了压缩编码端的计算量和编码复杂性。而在智能家居zigbee固件升级场景中,编码过程的工作是在网关处进行,一般家庭网关资源相对比较丰富,这个代价可以接受的,所以该算法正好迎合了这样的应用环境。然而,该数组的构建是能否成功解码的关键。
附图说明
下面结合附图,通过非限定性的举例对本发明的优选实施方式作进一步说明,在附图中:
图1是本发明基于zigbee技术智能家居组成示意图;
图2是哈夫曼二叉树标记图;
图3是哈夫曼二叉树的汉密尔顿回路寻路路径标记;
图4是hhd解码算法流程图;
图5是对于zigbee样本镜像,顺序存储、链表存储与hhd算法的存储空间消耗对比;
图6是针对不同的元素数量的链表式存储与hhd算法的空间消耗对比;
图7是针对不同的最长编码码长,顺序存储的最大和最小存储空间对比;
图8是遍历二叉树解码与hhd解码时间消耗对比。
具体实施方式
下面结合附图对本发明作进一步的详细说明。
首先,我们设定既定的哈夫曼树,左侧孩子为0右侧孩子是1,画出哈夫曼树如图中所示。我们的目标是建立一个有序的配置解码表,并要求它的逻辑地址是闭合的。正如上文讨论如何使得数组中节点下标地址与逻辑地址形成映射关系并且是闭合回路是本发明成功设计的关键点。使用汉密尔顿回路来解决这个问题。设定第一根节点编号为1,左侧孩子是2,右侧孩子是3。右侧孩子节点被标记为寻路开始节点,左侧孩子节点被标记为寻路结束节点并且规定处在越高层的寻路开始节点拥有更高的优先级设置,而处在越高层的寻路结束节点拥有较低的优先级。这样,哈夫曼树应被标记成为如图3所示。
对于一个单元的二进制树中的标记的规则如下:左侧孩子节点被标记为二叉树寻路的结束标志,右侧孩子节点为寻路开始标志;
•当两个子节点中有且只有一个是叶节点,另一个非叶子的节点继承其父节点的信息标志;
•当两个孩子节点都是叶节点,标记其码值;
•更高层的寻路开始节点具有较高的优先级而更高层的结束节点具有较低的优先级。
在标志着所有的节点后,按照寻路规则绘画出一条闭合的汉密尔顿回路。汉密尔顿回路的寻路规则是:
•起点出发闭合到终点,终点与下一个最近的起点相连;
•起始节点分支寻路方向是从顶部到底部,结束节点的方向是从底部到顶部;
•在最近同一分支,任何开始节点的优先级比任何结束节点大;
•节点的优先级越高越先被标号并且节点编号顺序依照寻路顺序。
当汉密尔顿回路闭合至2号节点,编号工作完成。这时我们就需要使用一个数组来记录节点的信息,采取n[x][y]实例来表示阵列:0<x<n,0<y<5。该二维数组的定义如下:使用单元行向量记录节点属性:n[x][1]存储左子节点值;n[x][2]的存储右侧孩子节点的值;n[x][3]存储左子节点编号;n[x][4]的存储右侧孩子节点编号。如果节点不是叶,其值为null。如果节点是叶,该值是它的解码字且它的编号是零,标志着这段比特流解码的结束。当一段比特流解码结束后,开始从n[x][1]新的比特流进行重新搜索解码。以上哈夫曼树样本n[x][y]如表所示i.
根据hhd阵列生成算法,哈夫曼树将重新生成的解码数组的顺序存储结构,即,所述物理地址和数组下标地址是映射关系且可随机读取的数据。解码过程是读取二进制比特流,例如对照表,通过对照新的解码数组。
根据该数组中的设定,左边为0,右边是1。输入的二进制比特流,如10110101110000...搜索在表中数组:第一位比特是1,读取n[1][4]并且赋值x=n[1][4]。接着比特为0,读n[x][3]且赋值x=n[x][3]。直到当比特是0,x=0时,解码码值等于n[x][1]或者当比特为1,x=0时,解码码值等于n[x][2]的。之后,继续读下一个比特位,从[1][y]重新开始跳转搜索解码,并执行循环操作,直到解码完成。解压缩算法数组中“lv”是左侧孩子节点的码值与“rv”是右侧孩子节点的码值。在“ln”是左侧孩子节点的编号和“rn”是右侧孩子节点的编号。
构建二维数组的关键是如何根据哈夫曼编码树生成汉密尔顿电路。然后使用译码阵列进行解压缩的数据可以使其更加迅速和方便。因为大部分的计算成本的是在创造减压阵列的过程中,使符合本文贡献目标的解压缩处理是非常灵活。综上所述,hhd算法使用数组存储结构来存储哈夫曼二叉树,实现逻辑地址映射数组索引地址。换句话说,它使用数组存储实现指针跳转功能。以这种方式,zigbee的端点能够灵活地解压缩更新的固件映像,hhd算法流程图如图4所示。
算法的评估流程如下。首先,zigbee的固件更新源文件有256个元素,它已被哈夫曼压缩。最长的编码长度是11和平均编码长度为6。数组中数据占用存储空间是1字节和指针占用存储空间为2字节。
(1)序列存储哈夫曼树的大小是根据它的最长的编码长度为k。在本文中,完全哈夫曼二叉树编号顺序是从上到下,从左到右。如果哈夫曼树编码最长长度为单左支,其规模最小:
如果哈夫曼树编码最长长度为单右支,其规模是最大的:
一般来说,最长的编码长度将超过8。在本发明的压缩zigbee的图像文件的条件中,k=11。因此,最小尺寸是:(2^10+2^10+1)*1个字节=2049字节;
(2)如果链表式存储仅仅使用孩子指针而没有父亲指针,一般链表存储结构空间成本为:
我们只需要记录左右孩子的指针无父亲指针数据结构,链表的存储空间成本较小为:(2字节+1字节+2字节)*(256+256-1)=2555字节;
(3)hhd算法只是记录的非叶子节点的信息,其元素数量只有n-1,每个元素需要4个字节存储空间。然后hhd哈夫曼树总存储空间成本为:
所以这个解压缩算法的空间成本大小为:(256-1)*4字节=1020字节,上述三个比较结果如图5所示。使用y1代表链表存储的空间成本,并使用y2表示hhd解压缩算法的空间成本。从图6,它显示了y1比y2更大。hhd解压缩算法的成本比其他算法占用更小的空间。因为顺序的存储空间成本由最长的编码长度确定。一般来说,最长的编码长度几乎都比8大,不同类型的文件有不同的最长编码长度。从图7中我们可以看到它与编码最长长度k的关系。在本发明样本数据中,最长编码长度为11,序列最小的存储空间成本为2049字节,这仍然比hhd的1020个字节要大一倍多。
解压时间成本对比,本发明的解压缩算法,通过读取逻辑地址映射到数组的索引号实现了数组指针的功能。在本发明样本数据中,平均编码长度为6,则表明我们平均需要六个跳转搜索步骤来解码相应编码字。因此,平均时间成本为6*t,对比结果如下所示:
在实验中,zigbee升级镜像文件具有256个元素,并设定解压的跳转搜索单元时间消耗为t。传统的哈夫曼解码是通过遍历二叉树进行解码,效率不高现实应用场景不多。更多的是根据二叉树生成编码表,通过搜索编码表对照解码相应码字。所以,传统解压方式应搜索256个元素和它们对应的码字进行解码。理想情况下,对于一个有256个元素的解码表搜索跳转解码时,按照平均概率计算,传统的编码表存储在搜索哈夫曼树成功解码一个码字的时间成本是:(256/2)*t。如果使用顺序来存储哈夫曼树和遍历树,搜索时间比这个值更大。因为遍历二叉树有三种:前序遍历,中间顺序遍历和后序遍历。他们都需要经历更多步骤来查找解码字。在较好的情况下,平均编码长度为6,我们需要跳六次找到一个解码的字。但是,在遍历解码时我们需要遍历256个单元,平均解码时间成本(256/2)*6t。在hhd的算法,我们只是精确地跳转六个步骤找到解码的码字。所以只是花费6*t时间解码相应编码字。由于遍历哈夫曼树的时间成本比遍历编码表大,本发明只是对比遍历编码表的时间成本和hhd算法时间成本如图8所示。我们可以看到,hhd平均解压消耗时间成本要小于遍历解码表时间消耗大约二十倍。
本文通过构建这个数组记录非叶子节点的属性作为一个数据单元。实验结果表明,该算法的优点:
(1)在zigbee镜像压缩文件中,压缩平均码长为约6。因此,只需花费平均六个步骤来获得其解码码字,在解码时间消耗的性能上提高20倍以上。通过减少了解码时间,相应的在嵌入式设备上减少了计算、搜索、跳转步骤,这也将节省一些能量。
(2)哈夫曼树存储方式使用数组来存储,该存储空间比链表存储和顺序存储方式都要小。很明显本发明的算法减少了哈夫曼解码过程的空间成本的消耗。因为有很多空的占位符数据,同时也为未来进一步优化提供了空间。
本发明的算法创新之处在于它将哈夫曼树生成一个特殊约定的解码数组,可以根据该数组下标随机读取被直接解码数据,解码效率大大增加。但是,这种设计的代价是增加了压缩编码端的计算量和编码复杂性。而在智能家居zigbee固件升级场景中,编码过程的工作是在网关处进行,一般家庭网关资源相对比较丰富,这个代价可以接受的,所以该算法正好迎合了这样的应用环境。然而,该数组的构建是能否成功解码的关键。
- 还没有人留言评论。精彩留言会获得点赞!