一种基于相关冗余变换与增强学习的多维度协同控制方法与流程
本发明属于物联网领域,涉及一种基于相关冗余变换与增强学习的多维度协同控制方法。
背景技术:
智能房车作为智能网联汽车与智能家居深度融合的产物,利用多传感器数据采集与车载网关通信技术,对车载设备进行智能化控制,满足人们对于房车的空间体验与智能生活的需求。作为智能房车核心之一的智能控制技术,其控制策略执行的实时性与准确性直接决定着智能房车的优劣,但就目前市场现有的智能房车而言,存在着控制方式单一、控制策略生成智能性欠缺、执行代价过高等问题。为此,本专利采用多源异构信息特征统一与融合,使多源传感器数据进行整合,为多模态复杂环境下的控制奠定基础,并使用pomdp模型下的控制状态引导策略方法与深度增强学习的控制状态引导策略优化两者结合,使控制决策更加准确与智能,同时采用基于总线的底层控制,大幅降低传感器接入成本,改善整个感知平台的可靠性,节省大量运算资源。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于相关冗余变换与增强学习的多维度协同控制方法,
为达到上述目的,本发明提供如下技术方案:
一种基于相关冗余变换与增强学习的多维度协同控制方法,包括以下步骤:
s1:多源异构信息特征统一与融合;
s2:采用基于pomdp模型的控制状态策略引导;
s3:采用基于深度增强学习的控制状态引导策略优化;
s4:采用基于总线的分布式底层控制。
进一步,所述步骤s1具体为:对多传感器网络环境下,多传感器异构信息通过经典相关分析算法cca和同构相关冗余变换(isomorphicrelevantredundanttransformation,irrt)算法分析,将多个异构信息映射到一个统一的、量纲可计算的空间,对特征信息进行统一表示后对信息进行融合。
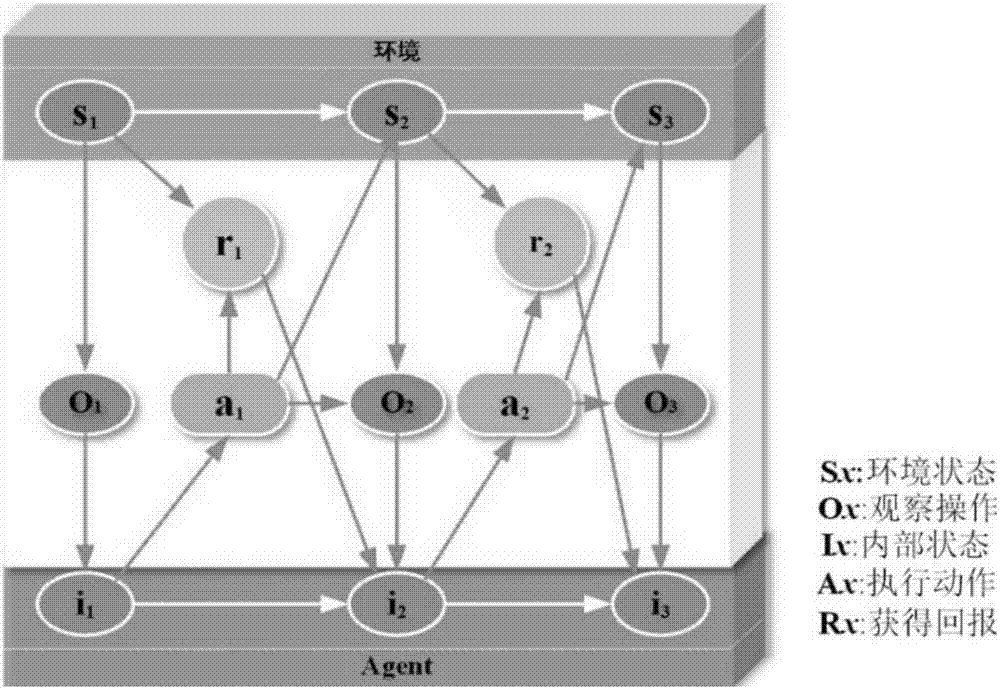
进一步,所述步骤s2具体为:采用多源异构融合技术获得的商务旅居房车各类设备的控制状态,建立pomdp模型以感知、适应、追踪设备控制状态的变化;通过pomdp模型的内部作用器给设备控制状态施加动作,以引起设备控制状态发生变化,并获得一定回报;根据获得的累计回报来衡量所执行一系列策略的可能性,进而将商务旅居房车的设备控制问题转换成策略选择问题;具体地,pomdp模型描述为<s,a,t,o,q,β>,综合环境状态在pomdp模型概率分布中的置信状态表示为b={bt},其t时刻的概率分布为bt={bt(s1),...,bt(sm)};其中,bt(si)表示t时刻环境状态为si的概率;通过对当前时刻控制环境的观察与动作的选择,pomdp模型推导出下一时刻控制状态的置信值;假设起始时刻的置信状态为b0,执行动作a与观察σ,获得下一时刻置信状态b1;当处于控制状态s1,模型获得的观察为o1,模型内部状态为i1;通过计算,根据控制状态引导策略选择相应的动作a1,导致环境状态从s1转移到s2,模型获得回报r1与观察o2,此时模型内部状态从i1(b1)转移到i2(b2),然后模型依此继续运行;
具体地,构建问题的引导策略估计函数实现对话状态跟踪,该函数为
进一步,所述步骤s3具体为:根据pomdp模型得到商务旅居房车设备控制状态的引导策略,采用基于深度增强学习dqn的策略优化方法来选择最佳行动策略;具体地,采用q-网络(q(s,a,θ))定义行为策略,利用目标q-网络(q(s,a;θ-))生成dqn丢失项的目标q值,以及重新记忆pomdp模型用于训练q网络的随机采样状态值;通过增强学习定义pomdp模型的预期总回报
首先,dqn使用记忆重构,在pomdp模型的每个时间步长t内,将记忆元组et=(st,at,rt,st+1)存放到记忆存储器dt={e1,…,et}中;
其次,dqn分别维持两个独立的q网络(q(s,a,θ))和(q(s,a;θ-));当前参数θ在每个时间步长内进行多次更新,并在n次迭代之后被复制到旧参数θ-中;在更新迭代时,为了最小化相对于旧参数θ-的均方bellman误差,通过优化损失函数
最后,在每个时间步长t内,选择相对于当前q-网络(q(s,a;θ))的偏好行为动作;使用中心参数服务器来维护q网络(q(s,a;θ-))的分布式表示;同时,该参数服务器接收强化学习到的渐变信息,并在异步随机梯度下降算法的驱动下,应用这些渐变信息来修改参数向量θ-。
进一步,所述步骤s4具体为:设计基于存储器映射的数据通道的编址方式,综合考虑触发方式、时序和负载能力问题,协同多路开关与采样保持器,实现数据接口通道的共享;设计具有冗余结构的自主控制系统,智能解析融合决策所获得的控制指令,兼顾电源输出波动、电磁辐射和分布式电容电感干扰因素,完成车载设备的自主控制。
本发明的有益效果在于:本发明是一种基于相关冗余变换与增强学习的多维度智能房车协同控制方法。在对设备工况监测、驾乘环境类人感知、人体特征识别、用户意图推理、资源信息交互、车机自主控制等方面,与其它方法相比,本专利围绕智能商务旅居房车统一设备连接协议、共享设备接口、提高系统集成度的自主协同控制需求,利用基于pomdp模型和深度增强学习的自主控制引导策略,采用多维度智能融合得到的控制状态作为计算机控制系统的输入,建立pomdp模型以感知、适应、追踪设备控制状态的变化,采用基于深度增强学习(dqn)的策略优化方法来选择最佳行动策略,实现商务旅居房车的自主协同控制。将pomdp模型与深度增强学习两种方法结合,形成多模态模式下与复杂环境下的智能房车最佳控制决策,不仅有利于最终决策的有效性与实时性,同时提高了交互反馈的准确性与策略的学习优化程度,提升用户体验。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为多源异构特征统一表示与融合图;
图2为于pomdp模型的控制状态引导策略图;
图3为深度增强学习的控制状态策略优化模型。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
如图1、2、3所示,本发明各部分具体实施细节如下:
1、多源异构信息特征统一与融合。该过程包含以下5个步骤:
(1)多模态数据采集;
(2)多模态特征抽取;
(3)特征关联;
(4)多模态特征统一表示;
(5)多源异构信息特征融合。
2、基于pomdp模型的控制状态引导策略设计。该过程包含以下4个步骤:
(1)建立pomdp模型感知、适应、追踪设备控制状态变化;
(2)作用器给设备控制状态施加动作,获得一定回报;
(3)根据获得的累计回报来衡量所执行一系列策略的可能性,
(4)进行所得策略选择;
3、基于深度增强学习的控制状态引导策略优化。该过程包含以下3个步骤:
(1)q-网络定义行为策略;
(2)生成dqn丢失项的目标q值;
(3)重新记忆pomdp模型用于训练q网络的随机采样状态值。
4、基于总线的分布式底层控制。采用基于can总线的智能房车网关集中控制方案,引入智能房车接口单元模块,有效的隔离被控对象的多样性,减小系统的复杂性;通过键盘控制、遥控方式从智能房车网关分离,提高智能房车网关的可靠性;智能房车内部网络选用can总线,降低系统的成本,满足系统的可扩展性,并根据can总线的多主特性,实现被控对象的即插即用功能。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!