基于强化学习的机器人时间最优轨迹规划方法及控制器与流程
本发明涉及机器人控制器及方法,尤其是基于强化学习的机器人时间最优轨迹规划方法及控制器。
背景技术:
在利用机器人进行搬运,装配,机加工等场合时,为了提高机器人的工作效率,应该使机器人始终处于允许的最大速度下工作,这种为了减少机器人执行任务的时间,使机器人在临界条件下运动的轨迹规划方法称为时间最优轨迹规划方法。
在使用机器人进行时间最优轨迹规划时,通常需要利用机器人的动力学模型通过求解力矩约束不等式方程组进行求解,如文献(bobrowj,dubowskys,gibisionj.time-optimalcontrolofroboticmanipulatorsalongspecifiedpaths[j].theinternationaljournalofroboticsresearch.1985,4(3):3-17.)(王陈琪.高速高精度平面并联机器人时间最优控制系统的研究[d].哈尔滨:哈尔滨工业大学,2006.)(steinhausera,sweversj.anefficientiterativelearningapproachtotime-optimalpathtrackingforindustrialrobots[j].ieeetransactionsonindustrialinformatics.2018,14(11):5200-5207.)。但是由于文献提到的不可避免的模型——对象不匹配现象(model-plantmismatch),模型并不能完全反映真实情况,这导致了有些情况下运行基于动力学模型规划得到的时间最优轨迹之后会出现测量力矩超出约束限制的情况,导致规划结果不可行。或由于动力学模型的不准确导致规划得到的时间最优轨迹是次优的。
技术实现要素:
为了解决上述问题,本发明的目的是提供一种基于强化学习的机器人时间最优轨迹规划方法及控制器,通过强化学习方法不需要知道模型便能进行学习的特点,消除模型对象不匹配问题,最终获得使实际测量力矩满足约束条件限制,并使轨迹规划结果更加接近最优解。
本发明至少通过如下技术方案之一实现。
基于强化学习的机器人时间最优轨迹规划方法,包括以下步骤:
s1将任务路径的各关节参数输入到路径参数化模块转化为关于末端路径的标量参数;
s2将参数化后的路径输入到路径离散化模块进行路径离散化;
s3将离散化后的路径输入到强化学习模块中构建强化学习环境;
s4使用强化学习模块学习最优的策略轨迹;
s5运行策略轨迹获得反馈的关节力矩;
s6将反馈的关节力矩输入到强化学习模块从而对强化学习环境进行修正;
s7在更新后的强化学习环境中,使用强化学习模块学习新的最优策略轨迹;
s8重复步骤s5-步骤s7,直到强化学习环境不再更新。
优选的,步骤s1的将任务路径的各关节参数输入到路径参数化模块转化为关于末端路径的标量参数,具体包括以下步骤:
s11获取任务路径的时间序列的各关节角位移;
s12将各关节角度代入机器人正运动学方程获得时间序列的笛卡尔空间位移;
其中,上述机器人正运动学方程为采用如下的矩阵表达式
其中px、py、pz表示机器人末端坐标相对于基坐标的位置在极坐标x、y、z轴方向的分量,通过计算相邻时间间隔px、py、pz的变化得到笛卡尔空间位移;nx、ny、nz表示末端姿态的x轴方向在极坐标x、y、z方向的分量;ox、oy、oz表示末端姿态的y轴方向在极坐标x、y、z方向的分量;ax、ay、az表示末端姿态的z轴方向在极坐标x、y、z方向的分量;
矩阵γ由各轴的相邻坐标系的变换矩阵相乘得到,即
其中表示机器人任一关节,
s13根据笛卡尔空间位移计算机器人的路径弧长,并取位移在总弧长的占比作为机器人在任一时刻的标量位移s;
s14使用分段最小二乘方法拟合关节角位移q关于标量位移s的函数q(s);
s15对函数q(s)进行求导,获得路径曲率q′(s)和路径曲率变化率q″(s)。
优选的,步骤s2的将参数化后的路径输入到路径离散化模块进行路径离散化;具体包括以下步骤:
s21设定路径曲率之差的阈值σ以及路径曲率变化率之差的阈值
s22设定m=1,κ=n=时间序列数,将各时间序列的路径标量位移按时间顺序构成集合
s23当m<n时,如果
s24重复步骤s23直到m≥n,则集合n就是离散化后的路径标量位移的集合。
优选的,步骤s3的将离散化后的路径输入到强化学习模块中构建强化学习环境,具体包括以下步骤:
s31将相平面
s311设定机器人运行时允许的各关节最大允许速度
s312根据不等式组
求得每个离散点允许的最大路径标量速度,式中
s313设定在相平面
s314以各离散点中最大的路径标量速度作为速度上限
s315将相平面
s32设定强化学习的状态值函数,所述状态值函数为:
q(sk,ak)←q(sk,ak)+α[rk+1+γq(sk+1,ak+1)-q(sk,ak)]
式中sk表示相平面上的第k个状态,ak表示在第k个状态时选择的动作,q()表示在状态sk时选择动作ak对应的q值表上的值,α表示学习系数,γ表示折扣因子,rk+1表示在状态sk时执行动作ak获得的奖励或惩罚,箭头←表示箭头右边的值赋值给左边;
s33设定强化学习的搜索策略,所述的搜索策略为贪婪策略,其具体步骤为:
s331设定贪婪因子ε,其取值范围在0到1之间;
s332随机生成一个在0到1之间的数λ;
s333如果λ<ε,则执行探索,在动作范围内随机选取一个动作;如果λ≥ε,则选取动作范围内具体最大路径标量速度的动作;
s34设定强化学习的动作奖励和惩罚,所述动作奖励和惩罚的表达式如下
其中,
当程序选择的动作指向的下一个状态违反约束条件,即违反步骤s312不等式组或当前状态的动作范围内没有动作可选择时,则获得惩罚,否则,当程序选择的动作指向的下一个状态不违反约束条件时,则得到奖励;
s35设定强化学习的动作选择范围,所述动作范围选择设定步骤具体如下:
s351根据式
s352根据匀加速运动方程
优选的,步骤s4的使用强化学习模块学习最优的策略轨迹,具体包括以下步骤:
s41初始化q值表,将q值表上的值都设置为0,设定最大学习次数并初始化学习次数为1;
s42当学习次数<最大学习次数时,转到步骤s44,否则转到步骤s49;
s43令k=1,初始化奖励值rk+1=0,从起始状态(0,0)开始学习过程,计算下一状态动作范围,并使用贪婪策略从动作范围中选取出动作ak;
s44当k≤n并且rk+1≥0时,转到步骤s45;
s45执行动作ak,获得奖励或惩罚rk+1和状态sk+1,并计算下一状态动作范围;
s46如果奖励或惩罚rk+1<0或下一状态动作范围为空,则转到步骤s47,否则转到步骤s48;
s47令q(sk+1,ak+1)=0,并根据步骤s32的状态值函数更新动作q值,同时为了加速惩罚,对这段探索过程中的所有动作都添加一个惩罚项进行惩罚,具体做法为对于从1逐渐增大到k的整数j,有q(sj,aj)=q(sj,aj)+ρk-jrk+1,其中ρ为惩罚因子,其取值范围为0<ρ<1,之后令学习次数+1并转到步骤s42;
s48在状态sk+1计算动作范围,并通过贪婪策略从动作范围中选取动作ak+1,之后根据步骤s32的状态值函数更新动作q值,令sk←sk+1,ak←ak+1,k←k+1,并转到步骤s45;
s49当学习次数到达最大学习次数时,令贪婪因子ε=0重新进行学习过程,即在从状态(0,0)开始学习时,不会再进行探索,而会直接选取当前动作范围内具有最大路径标量速度的动作,从而获得在最大学习次数下所能获得的最优策略轨迹,同时将训练后的q值表保存到存储模块中,在下一次训练时调用训练过的q值表,节省学习时间。
优选的,步骤s6的将反馈的关节力矩输入到强化学习模块从而对强化学习环境进行修正,具体做法为:在获得测量力矩之后,如果某一状态点对应的测量力矩超过给定力矩约束的限制,即将相平面上的该状态点设为不可行状态,当在该状态的前一状态通过贪婪策略刚好选择的动作指向该不可行状态时,将之视为违反约束条件的情况并直接对相应动作的q值进行惩罚。
根据所述的一种基于强化学习的机器人时间最优轨迹规划方法的控制器,包括路径参数化模块、路径离散化模块、强化学习模块和存储模块;
所述路径参数化模块,用于将机器人关节参数转化为关于末端路径的标量参数;
所述路径离散化模块,用于将机器人末端的连续任务路径离散化为若干个离散点;
所述强化学习模块,用于构建机器人时间最优轨迹规划的强化学习环境以及在强化学习环境中学习最优策略轨迹;
所述存储模块,用于存储强化学习的学习数据。
与现有的技术相比,本发明的有益效果为:
本发明所提出的方法不需要推导机器人的动力学模型,适用于结构复杂的机器人。本发明避免了模型-对象不匹配问题,所提出的方法能够真正实现使机器人的真实测量力矩限制在限定的约束条件范围内,更接近真实的时间最优规矩规划最优解。
附图说明
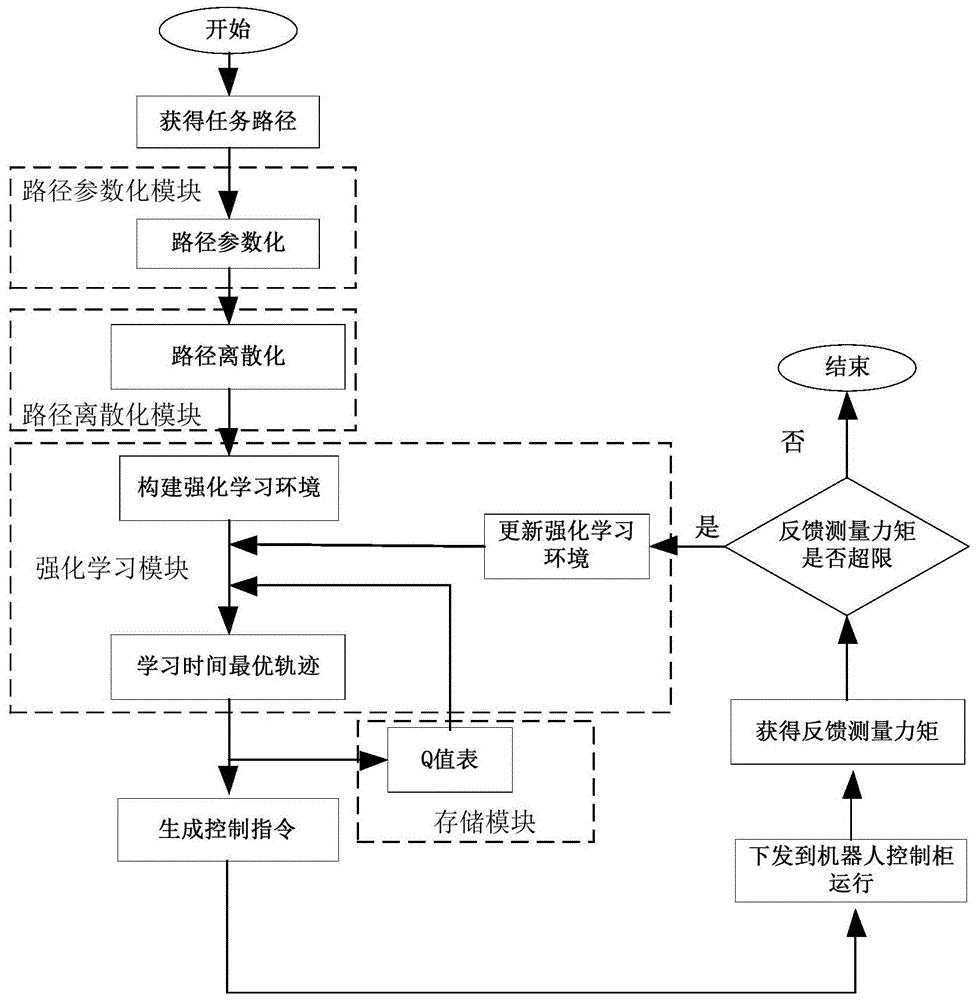
图1为实施例中一种基于强化学习的机器人时间最优轨迹规划方法的流程图。
具体实施方式
下面通过具体实例对本发明的目的作进一步详细地描述,实例不能在此一一赘述,但本发明的实施方式并不因此限定于以下实例。
本实施例的一种基于强化学习的机器人时间最优轨迹规划控制器,所述轨迹规划控制器包括路径参数化模块、路径离散化模块、强化学习模块和存储模块;
路径参数化模块,用于将机器人关节参数转化为关于末端路径的标量参数;
路径离散化模块,用于将机器人末端的连续任务路径离散化为若干个离散点;
强化学习模块,用于构建机器人时间最优轨迹规划的强化学习环境以及在强化学习环境中学习最优策略轨迹;
存储模块用于存储强化学习的学习数据。
如图1所示的一种基于强化学习的时间最优轨迹规划控制器的规划方法,包括以下步骤:
step1.获取任务路径
通过在示教器上规划机器人的任务路径并运行然后进行采样,获得固定采样周期时间序列的机器人各关节脉冲序列,并转化为相应的角度。
step2.路径参数化,将任务路径的各关节参数输入到路径参数化模块转化为关于末端路径的标量参数;
将机器人各关节的角度输入到机器人正运动学方程得到笛卡尔空间的坐标。用l()表示机器人的路径弧长函数,l(o)表示机器人的第o个脉冲序列时的路径弧长。从而可以计算出机器人末端的路径弧长l(o)为:
式中δx,δy,δy表示相邻时间间隔的末端路径位移,o表示机器人走完这段路径总的采样周期数。从而计算时间序列t的机器人末端路径标量参数位移s(t):
s(t)=l(t)/l(o)
采用分段最小二乘法拟合机器人各关节角度q关于路径标量参数位移s的函数q(s),对q(s)进行求导得到路径曲率q′(s)和路径曲率变化率q″(s)。
step3.将参数化后的路径输入到路径离散化模块进行路径离散化,具体包括以下步骤:
step31设定路径曲率之差的阈值σ以及路径曲率变化率之差的阈值
step32设定m=1,κ=n=时间序列数,将各时间序列的路径标量位移按时间顺序构成集合
step33当m<n时,如果
step34重复步骤step33直到m≥n,则集合n就是离散化后的路径标量位移的集合。
s4.将离散化后的路径输入到强化学习模块中构建强化学习环境,具体包括以下步骤:
step41将相平面
step411设定机器人运行时允许的各关节最大允许速度
step412根据不等式组
求得每个离散点允许的最大路径标量速度,式中
step413设定在相平面
step414以各离散点中最大的路径标量速度作为速度上限
step415将相平面
step42设定强化学习的状态值函数,所述状态值函数为:
q(sk,ak)←q(sk,ak)+α[rk+1+γq(sk+1,ak+1)-q(sk,ak)]
式中sk表示相平面上的第k个状态,ak表示在第k个状态时选择的动作,q()表示在状态sk时选择动作ak对应的q值表上的值,α表示学习系数,γ表示折扣因子,rk+1表示在状态sk时执行动作ak获得的奖励或惩罚,箭头←表示箭头右边的值赋值给左边;
step43设定强化学习的搜索策略,所述的搜索策略为贪婪策略,其具体步骤为:
step431设定贪婪因子ε,其取值范围在0到1之间;
step432随机生成一个在0到1之间的数λ;
step433如果λ<ε,则执行探索,在动作范围内随机选取一个动作;如果λ≥ε,则选取动作范围内具体最大路径标量速度的动作;
step44设定强化学习的动作奖励和惩罚,所述动作奖励和惩罚的表达式如下
其中,
当程序选择的动作指向的下一个状态违反约束条件,即违反步骤step412不等式组或当前状态的动作范围内没有动作可选择时,则获得惩罚,否则,当程序选择的动作指向的下一个状态不违反约束条件时,则得到奖励;
step45设定强化学习的动作选择范围,所述动作范围选择设定步骤具体如下:
step451根据式
step452根据匀加速运动方程
step5使用强化学习模块学习最优的策略轨迹,具体包括以下步骤:
step51如果q值表还没被训练过,则初始化q值表,将q值表上的值都设置为0,设定最大学习次数并初始化学习次数为1;
step52当学习次数<最大学习次数时,转到步骤s54,否则转到步骤s59;
step53令k=1,初始化奖励值rk+1=0,从起始状态(0,0)开始学习过程,计算下一状态动作范围,并使用贪婪策略从动作范围中选取出动作ak;
step54当k≤n并且rk+1≥0时,转到步骤s55;
step55执行动作ak,获得奖励或惩罚rk+1和状态sk+1,并计算下一状态动作范围;
step56如果奖励或惩罚rk+1<0或下一状态动作范围为空,则转到步骤step57,否则转到步骤step58;
step57令q(sk+1,ak+1)=0,并根据状态值函数更新动作q值,同时为了加速惩罚,对这段探索过程中的所有动作都添加一个惩罚项进行惩罚,具体做法为对于从1逐渐增大到k的整数j,有q(sj,aj)=q(sj,aj)+ρj-jrk+1,其中ρ为惩罚因子,其取值范围为0<ρ<1,之后令学习次数+1并转到步骤step52;
step58在状态sk+1计算动作范围,并通过贪婪策略从动作范围中选取动作ak+1,之后根据状态值函数更新动作q值,然后令sk←k+1,ak←ak+1,k←k+1,并转到步骤step55;
step59当学习次数到达最大学习次数时,令贪婪因子ε=0重新进行学习过程,即程序在从状态(0,0)开始学习时,不会再进行探索,而会直接选取当前动作范围内具有最大路径标量速度的动作,从而获得在最大学习次数下所能获得的最优策略轨迹,同时将训练后的q值表保存到存储模块中,在下一次训练时调用训练过的q值表,节省学习时间。
step6生成控制指令
首先,求出到达每个路径离散点k所需要的时间t(k)。具体做法为:
由匀加速运动方程,规划完成时间最优轨迹后路径离散点的加速度
其中s(k)表示第k个离散点所对应的路径位移,
由速度加速度方程,可求出到达每个路径离散点k所需要的时间t(k)
求得到达每个路径离散点的时间之后,便可求得每个控制周期的路径标量位移;若要求第n个控制周期的标量位移,到达该控制点的时间即为nt,其中t为控制周期。假设该控制时间与到达路径离散点k所需要的时间t(k)最接近,则这两点的时间间隔为
δt=nt-t(k)
根据匀加速运动方程,该控制点的路径位移即为
从而可以求得每个控制周期的路径标量位移,再代入函数q(s)即可求得每个控制周期的关节角度,最后将关节角度转化为关节脉冲指令传输到机器人控制器运行。
step7下发到机器人控制柜运行
将步骤step7获得的关节脉冲指令通过示教器下发到机器人控制柜以控制关节电机运转。
step8获得反馈测量力矩
通过控制柜反馈回来的信号,可以获得机器人在运行过程中各关节的反馈测量力矩。
step9判断反馈测量力矩是否超限
将反馈回来的测量力矩与机器人电机运行的安全力矩约束条件进行比较,以判断反馈测量力矩是否出现超限情况,如果没有,则转到步骤s11,否则转到步骤step10。
step10更新强化学习环境
在获得测量力矩之后,如果某一状态点对应的测量力矩超过给定力矩约束的限制,即将相平面上的该状态点设为不可行状态,当程序在该状态的前一状态通过贪婪策略刚好选择的动作指向该不可行状态时,将之视为违反约束条件的情况并直接对相应动作的q值进行惩罚。再返回步骤step5。
step11当反馈测量力矩不再超限的时候,结束程序,获得使反馈测量力矩满足约束条件的时间最优轨迹。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!