一种基于改进随机森林的电弧炉建模方法
1.本发明涉及电气工程领域领域,具体的是一种基于改进随机森林的电弧炉建模方法。
背景技术:
2.随着国家经济、科技的快速发展,电动汽车、储能等新型负荷不断涌现,对电力系统的供需平衡提出了巨大的挑战。面对新的发展问题,传统的“源随荷动”调节模式已不能满足形式多变且日益增长的新型用电形式。针对该问题,国家强调要增强需求侧管理,提升负荷的调控能力。而在众多电力负荷中,工业负荷容量大且分布集中,具有较大的调控潜力。由于对不同类型的工业负荷尚缺乏定量分析模型,现有的批量负荷控制方法简单粗暴,容易对生产社会造成严重影响。同时,还导致工业负荷参与电网互动的规划手段缺乏,调控潜力难以被充分挖掘。
3.随着人工智能的发展,机器学习、深度学习被广泛结合到各个领域,尤其是电气领域,和电气领域传统的技术方法相结合,使一些以往难以解决的问题得到妥善处理。本发明结合机器学习中的集成学习方法,提出一种基于改进随机森林的电弧炉建模方法来反映电弧炉生产应用中的电量特征以及非电量生产因素俞电弧炉能耗之间的关系。该建模方法具有良好的泛化能力,可为其他类型工业负荷建模提供一个良好的参考。
技术实现要素:
4.为解决上述背景技术中提到的不足,本发明的目的在于提供一种基于改进随机森林的电弧炉建模方法
5.本发明的目的可以通过以下技术方案实现:
6.一种基于改进随机森林的电弧炉建模方法,所述方法包括如下步骤:
7.步骤1:研究电弧炉的电气和非电气影响因素,并采集这些因素数据;
8.步骤2:对采集到的原始数据进行清洗划分;
9.步骤3:基于改进随机森林的电弧炉模型搭建。
10.进一步的,所述步骤1中电弧炉的电气和非电气影响因素包括:电弧炉负载的电压电流、电炉变压器容量、吹氧量、能源回收率和原料结构。
11.进一步的,所述对采集到的原始数据进行清洗划分的方法包括如下步骤:
12.步骤2.1:采用pandas中的dropna进行缺失值过滤;
13.步骤2.2:针对数据中的异常值,采用局部离群因子检测法(local outlier factor,lof)对收集到的原始数据进行预处理
14.进一步的,所述lof方法是一种基于密度的高精度离群点检测方法,通过给每个数据分配一个依赖于邻域密度的离群因子lof,若lof》》1,则该数据点是异常点,若lof接近于1,则为正常数据点。
15.进一步的,所述基于改进随机森林的电弧炉模型搭建步骤如下:
16.步骤3.1:将初始训练集d随机划为大小相同的k个集合d1、d2、.....dk,令dj为第j个测试集,为相应的训练集;
17.步骤3.2:利用训练t个初级学习器;
18.步骤3.3:利用第j个测试集进行测试,对于测试集dj中的每个样本xi,t个初级学习器的输出结果组成的向量(z
i1
,z
i2
,...,z
it
)构成了次级学习器输入的一部分;
19.步骤3.4:重复步骤3.2和步骤3.3,生成次级训练集;
20.步骤3.5:利用次级训练集训练次级学习器;
21.步骤3.6:模型测试。
22.进一步的,所述模型测试的方法包括如下步骤:
23.步骤3.6.1:将训练所得的模型在测试集上进行测试,所述测试集涵盖120组数据,内容包括电弧炉负载的电压电流、电炉变压器容量、吹氧量、能源回收率和原料结构;
24.步骤3.6.2:将测试集作为训练所得模型的输入得出电弧炉的能耗估计值为输出结构;
25.步骤3.6.3:采用均方根误差衡量模型输出与实际值之间的差异度,并与决策树、随机森林、极端随机森林测试结果相对比。
26.本发明的有益效果:
27.1、本发明以决策树作为初级学习器,在初级学习器的训练中引入了数据样本扰动和输入属性扰动,大大提高了初级学习器的多样性,提高了模型的集成效果。且由于随机性的引入,模型不易过拟合、具有良好的抗噪声能力。
28.2、本发明采用集成学习的方法,提出的模型相比于单个决策树构成的模型具有更高的准确率。
29.3、本发明的结合模块为一次级学习器,其学习算法为多响应线性回归,同时为了防止过拟合,在初级学习器训练阶段采用了交叉验证的方式,该设计使得模型的鲁棒性得到提高。
30.4、本发明提供的基于改进随机森林的电弧炉建模方法,具有优秀的泛化能力,可为其他类型工业负荷建模提供一个良好的参考。
附图说明
31.下面结合附图对本发明作进一步的说明。
32.图1为本发明所提基于改进随机森林的电弧炉模型学习示意图;
33.图2为本发明所提基于改进随机森林的电弧炉建模方法流程图;
34.图3为本发明所提模型的集成学习算法;
35.图4为本发明所提改进随机森林模型在测试集上的测试结果,实线部分为实际值,虚线部分为模型结果;
36.图5为决策树在测试集上的测试结果。
37.图6为随机森林在测试集上的测试结果。
38.图7为极端随机森林在测试集上的测试结果。
具体实施方式
39.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
40.如图1~3所示,一种基于改进随机森林的电弧炉建模方法,所述方法包括如下步骤:
41.步骤1:研究电弧炉的电气和非电气影响因素,并采集这些因素数据;
42.电弧炉主要应用于钢铁冶炼生产中,利用电极电弧产生的高温熔化矿石和金属,冶炼出各种成分的钢和合金。其耗电量巨大,一般占企业总用电量50%以上。在钢铁冶炼中,影响电弧炉能耗的因素有很多,在不考虑人为因素以及生产方案的前提下,主要的电气和非电气影响因素包括电弧炉负载的电压电流、电炉变压器容量、吹氧量、能源回收率、原料结构。电弧炉炼钢以废钢为主要原料,辅以生铁、直接还原铁以及铁水,不同原料的占比对耗电量有不同影响。其中,铁水和生铁的占比与能耗成负相关,而直接还原铁的比例增大会导致电弧炉能耗的增加。
43.步骤2:对采集到的原始数据进行清洗划分;
44.由于初始数据属性众多且样本量大,包含有相当数量的缺失值和异常值,在建立模型前需要进行数据清洗。针对缺失值,由于样本量大,本发明直接采用dropna进行缺失值过滤,数据集中的异常点则通过局部离群因子检测方法加以剔除。最终训练集d包含1300组数据,测试集t包含120组数据。
45.步骤3:基于改进随机森林的电弧炉模型搭建。
46.所述步骤1中电弧炉的电气和非电气影响因素包括:电弧炉负载的电压电流、电炉变压器容量、吹氧量、能源回收率和原料结构。
47.所述对采集到的原始数据进行清洗划分的方法包括如下步骤:
48.步骤2.1:采用pandas中的dropna进行缺失值过滤;
49.步骤2.2:针对数据中的异常值,采用局部离群因子检测法(local outlier factor,lof)对收集到的原始数据进行预处理
50.所述lof方法是一种基于密度的高精度离群点检测方法,通过给每个数据分配一个依赖于邻域密度的离群因子lof,若lof》》1,则该数据点是异常点,若lof接近于1,则为正常数据点。
51.本发明在普通随机森林的基础上加以改进构建电弧炉模型,为了增强初级学习器的多样性,各节点选取划分属性时,采用随机选取的方法,相比传统的随机森林,获得的初级学习器多样性更强,最终的集成效果更好。在模型的结合策略上,本发明学习了stacking算法,将初级学习器的输出构成次级训练集,利用次级学习器进行结合,次级学习器采用多响应线性回归作为学习算法。因此,模型的搭建流程如下:
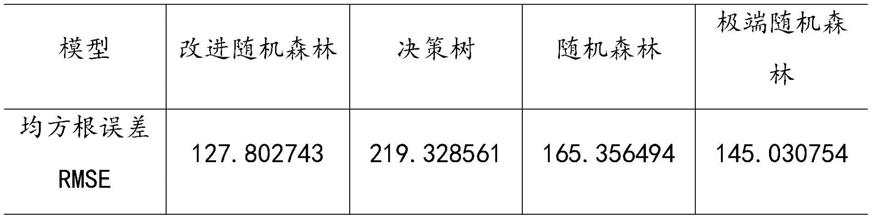
52.步骤3.1:将初始训练集d随机划为大小相同的k个集合d1、d2、.....dk,令dj为第j个测试集,为相应的训练集;
53.步骤3.2:利用训练t个初级学习器;
54.步骤3.3:利用第j个测试集进行测试,对于测试集dj中的每个样本xi,t个初级学习器的输出结果组成的向量(z
i1
,z
i2
,...,z
it
)构成了次级学习器输入的一部分;
55.步骤3.4:重复步骤3.2和步骤3.3,生成次级训练集;
56.步骤3.5:利用次级训练集训练次级学习器;
57.步骤3.6:模型测试。
58.所述模型测试的方法包括如下步骤:
59.步骤3.6.1:将训练所得的模型在测试集上进行测试,所述测试集涵盖120组数据,内容包括电弧炉负载的电压电流、电炉变压器容量、吹氧量、能源回收率和原料结构;
60.步骤3.6.2:将测试集作为训练所得模型的输入得出电弧炉的能耗估计值为输出结构;
61.步骤3.6.3:采用均方根误差衡量模型输出与实际值之间的差异度,并与决策树、随机森林、极端随机森林测试结果相对比。
62.测试结果如图4~7所示,其中实线部分为实际值,虚线部分为模型结果。下表为各模型测试结果的均方根误差,经比对,本发明所提模型精确性最高,优于单个决策树、传统的随机森林以及极端随机森林。
[0063][0064]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1