一种移动机器人端到端导航方法、系统和设备与流程
1.本发明涉及机器人技术领域,尤其涉及一种移动机器人端到端导航方 法、系统和设备。
背景技术:
2.在人机共融场景下,传统机器人需要具备处理突发事件的能力以适应非 结构化感知和动态化避障的场景,即智能化是机器人日常中的任务中的关键 技术。随着深度学习的热潮来临,谷歌的deepmind团队也提出了深度强化 学习的概念,基于深度强化学习的移动机器人的导航的研究再次成为了一个 新的研究热点。
3.目前基于深度强化学习的移动机器人的导航研究仍然处于一个尝试阶 段,国内外研究者采用了不同感知环境的方法进行研究,并取得一定的效果。 其中tail等人提出采用深度相机的图像作为输入,由于深度相机可以获取 物体间的距离信息,机器人可以实现一定的避障功能,但对于导航的成功率 较低。jaderberg等人提出预测值的概念,结合纹理控制和非监督学习的方 式,但是该方法适用范围存在一定的局限性,需要提前知道纹理信息。zhelo 等人也是引入预测值比较机制,预测值与实际值之间的差值赋予奖惩值,可 以很好解决稀松值问题,但是个方法需要一个合适的预测值,依旧存在局限 性。马如龙等人在摄像头的rgb图像上做出尝试,rgb图像虽然信息较多, 但是没有距离信息,这将对避障功能带来很大的挑战,实现的效果不是很理 想。王大方等人则采用dqn算法进行训练模型,其中的策略是机器人的运 动控制,实现机器人完成避障操作,没有对导航进行深入研究。zhu等人提 出采用预训练的方式结合孪生网络(siamesenetwork)以及actor-critic网络, 他们成功的解决了小范围视觉导航的问题,但该网络过于复杂,难以实现实 际机器人的迁移。
技术实现要素:
4.本发明要解决的技术问题,在于提供一种移动机器人端到端导航方法、 系统和设备,采用了位置,距离以及方向的复合奖励机制实现了对较为精确 的机器人导航。
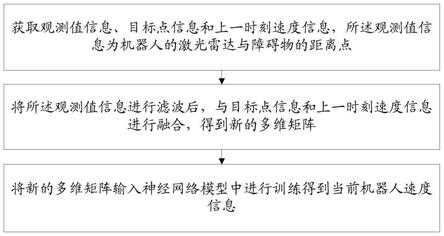
5.第一方面,本发明提供了一种移动机器人端到端导航方法,包括如下步 骤:
6.步骤1、获取观测值信息、目标点信息和上一时刻速度信息,所述观测 值信息为机器人的激光雷达与障碍物的距离点;
7.步骤2、将所述观测值信息进行滤波后,与目标点信息和上一时刻速度 信息进行融合,得到新的多维矩阵;
8.步骤3、将新的多维矩阵输入神经网络模型中进行训练得到当前机器人 速度信息。
9.进一步的,所述步骤2具体为:将多维观测值信息矩阵(...)进行滤波 后,与二维的速度信息矩阵(x,y)以及二维的目标点信息矩阵(z,w) 进行融合,组合成一个新的多维矩阵(x,y,z,w,...)作为神经网络模型 的输入。
10.进一步的,所述神经网络模型是基于tensorflow框架搭建的,所述神 经网络模型中采用的强化学习算法为近端策略优化算法(proximalpolicyoptimization,ppo),所述神经网络模型包括两个稠密层,每一稠密层的维 度均为512。
11.进一步的,所述近端策略优化算法的奖赏函数设置为:
[0012][0013]
其中,当移动机器人的激光检测到与障碍物的距离laserr(t)小于0.2m的 时,此时判定为碰撞到障碍物,回馈为一个负的奖励值rc,进行对移动机 器人的惩罚,结束这一回合,重置机器人与环境的位置,重新开始新一类的 训练;当机器人与指定目标点的距离d(t)小于目标点圆心距离阈值cd时,则 判定机器人抵达目标点。其中,cr(d(t-1)-d(t))-c
p
为时刻前后距离差的奖 赏值计算公式,cr为奖赏倍率,c
p
为时间惩罚因子。
[0014]
进一步的,所述方法还包括,对所述机器人限制其最大线速度v
max
为 0.5m/s,以及最大角速度w
max
为1.2rad/s。
[0015]
第二方面,本发明提供了一种移动机器人端到端导航系统,包括:
[0016]
数据采集模块,用于获取观测值信息、目标点信息和上一时刻速度信息, 所述观测值信息为机器人的激光雷达与障碍物的距离点,所述速度信息包括 线速度和角速度;
[0017]
融合模块,用于将所述观测值信息进行滤波后,与目标点信息和上一时 刻速度信息进行融合,得到新的多维矩阵;以及
[0018]
训练与输出模块,用于将新的多维矩阵输入神经网络模型中进行训练得 到当前机器人速度信息。
[0019]
进一步的,所述融合模块具体为:用于将多维观测值信息矩阵(...)进 行滤波后,与二维的速度信息矩阵(x,y)以及二维的目标点信息矩阵(z, w)进行融合,组合成一个新的多维矩阵(x,y,z,w,...)作为神经网络 模型的输入。
[0020]
进一步的,所述神经网络模型是基于tensorflow框架搭建的,所述神 经网络模型中采用的强化学习算法为近端策略优化算法(proximal policyoptimization,ppo),所述神经网络模型包括两个稠密层,每一稠密层的维 度均为512。
[0021]
进一步的,所述近端策略优化算法的奖赏函数设置为:
[0022][0023]
其中,当移动机器人的激光检测到与障碍物的距离laserr(t)小于0.2m的 时,此时判定为碰撞到障碍物,回馈为一个负的奖励值rc,进行对移动机 器人的惩罚,结束这一回合,重置机器人与环境的位置,重新开始新一类的 训练;当机器人与指定目标点的距离d(t)小于目标点圆心距离阈值cd时,则 判定机器人抵达目标点。其中,cr(d(t-1)-d(t))-c
p
为时刻前后距离差的奖 赏值计算公式,cr为奖赏倍率,c
p
为时间惩罚因子。
[0024]
第三方面,本发明提供了一种电子设备,包括存储器、处理器及存储在 存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实 现第一方面所述的方法。
[0025]
本发明实施例中提供的一个或多个技术方案,至少具有如下技术效果或 优点:
[0026]
本发明采用了位置,距离以及方向的复合奖励机制,智能体在每个时刻 都将得到一个奖励值,这样可以避免稀松问题,提高机器人导航准确度。本 发明中深度强化学习网络采用雷达点作为观测值输入,可以降低仿真场景与 实际场景可以差异性,便于策略迁移,本发明可在仿真环境训练策略模型, 构建多个复杂场景,使得仿真环境下的移动机器人具备导航避障能力,再将 训练好的模型移植到实际机器人,使得实际的机器人具有导航避障能力,实 际机器人无需在实际场景中进行训练,提高训练效率。
[0027]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技 术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它 目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
[0028]
下面参照附图结合实施例对本发明作进一步的说明。
[0029]
图1为本发明实施例一中一种移动机器人端到端导航方法的方法流程 图。
[0030]
图2为本发明实施例二中系统框架示意图。
[0031]
图3为本发明实施例三中设备的结构示意图。
[0032]
图4为本发明一具体实施例中导航任务示意图。
[0033]
图5为本发明一具体实施例中ppo强化学习网络结构。
[0034]
图6为本发明一具体实施例导航策略训练的仿真环境。
[0035]
图7为本发明实验训练得到的两种算法的平均悬赏值曲线图。
[0036]
图8为本发明实验训练得到的两种算法的训练成功率曲线图。
[0037]
图9为本发明实验中避障实验场景布局示意图。
[0038]
图10为本发明实验中两种算法下的二维运动轨迹。
[0039]
图11为本发明实验中两种算法下的三维运动轨迹。
[0040]
图12为本发明的导航实验的实际地图场景。
[0041]
图13为本发明的导航实验的导航示意图。
[0042]
图14为本发明导航实验中成功导航的奖赏值曲线图。
具体实施方式
[0043]
为使得本发明更明显易懂,现以一优选实施例,并配合附图作详细说明 如下。
[0044]
本技术实施例中的技术方案,总体思路如下:
[0045]
采用了位置,距离以及方向的复合奖励机制,智能体在每个时刻都将得 到一个奖励值,这样可以避免稀松问题。首先在仿真环境训练策略模型,构 建多个复杂场景,使得仿真环境下的移动机器人具备导航避障能力,再将训 练好的模型移植到实际机器人,使得实际的机器人具有导航避障能力,实际 机器人无需在实际场景中进行训练。本发明的深度强化学习网络采用雷达点 作为观测值输入,降低仿真场景与实际场景的差异性,便于策略迁移。
[0046]
实施例一
[0047]
本实施例提供一种移动机器人端到端导航方法,如图1、图4和图5所 示,包括如下
步骤:
[0048]
步骤1、获取观测值信息、目标点信息和上一时刻速度信息,所述观测 值信息为机器人的激光雷达与障碍物的距离点;
[0049]
步骤2、将所述观测值信息进行滤波后,与目标点信息和上一时刻速度 信息进行融合,得到新的多维矩阵;
[0050]
步骤3、将新的多维矩阵输入神经网络模型中进行训练得到当前机器人 速度信息。可用公式表示为:v
t
=f(laser
t
,p
t
,v
t-1
),其中,v
t
表示机器人速度 信息,laser
t
为观测值信息,p
t
为目标点信息,f为映射函数,v
t-1
为上一时刻 速度信息。
[0051]
较佳的,所述步骤2具体为:将多维观测值信息矩阵(...)进行滤波后, 与二维的速度信息矩阵(x,y)以及二维的目标点信息矩阵(z,w)进行 融合,组合成一个新的多维矩阵(x,y,z,w,...)作为神经网络模型的输 入。
[0052]
较佳的,所述神经网络模型是基于tensorflow框架搭建的,所述神经 网络模型中采用的强化学习算法为近端策略优化算法(proximal policyoptimization,ppo),所述神经网络模型包括两个稠密层,每一稠密层的维 度均为512。稠密层作为输出网络结构设置成两层可以更准确的计算输出, 根据输入的维度对应的可将本发明稠密层维度设置为512。
[0053]
ppo最早是用于游戏领域,其优异的表现被很多研究者推广到其他领 域。近端策略优化适合连续的动作空间,这种控制对于离散的dqn而言动 作会更加顺滑。ppo的强化学习网络将直接输出连续的动作,动作为线速 度与角速度。所以本发明设计近端策略优化的drl网络,其结构如图5所 示,将维度为100
×
1的观测值矩阵数据进行过滤后,和维度为2
×
1的上一 时刻速度v
t-1
矩阵数据以及维度为2
×
1的目标点p
t
矩阵数据进行融合后,输 入到本发明的近端测量优化drl网络,经稠密层输出维度为512的速度信 息。
[0054]
较佳的,所述近端策略优化算法的奖赏函数设置为:
[0055][0056]
其中,当移动机器人的激光检测到与障碍物的距离laserr(t)小于0.2m的 时,此时判定为碰撞到障碍物,回馈为一个负的奖励值rc,进行对移动机 器人的惩罚,结束这一回合,重置机器人与环境的位置,重新开始新一类的 训练;当机器人与指定目标点的距离d(t)小于目标点圆心距离阈值cd时,则 判定机器人抵达目标点。其中,cr(d(t-1)-d(t))-c
p
为时刻前后距离差的奖 赏值计算公式,及除了上述两种情况下的其它情况中,采用该公式计算r值, cr为奖赏倍率,c
p
为时间惩罚因子。
[0057]
较佳的,所述方法还包括,对所述机器人限制其最大线速度v
max
为 0.5m/s,以及最大角速度w
max
为1.2rad/s。
[0058]
基于同一发明构思,本技术还提供了与实施例一中的方法对应的系统, 详见实施例二。
[0059]
实施例二
[0060]
在本实施例中提供了一种移动机器人端到端导航系统,如图2、图4和 图5所示,包括:
[0061]
数据采集模块,用于获取观测值信息、目标点信息和上一时刻速度信息, 所述观测值信息为机器人的激光雷达与障碍物的距离点,所述速度信息包括 线速度和角速度;
[0062]
融合模块,用于将所述观测值信息进行滤波后,与目标点信息和上一时 刻速度信息进行融合,得到新的多维矩阵;以及
[0063]
训练与输出模块,用于将新的多维矩阵输入神经网络模型中进行训练得 到当前机器人速度信息。可用公式表示为:v
t
=f(laser
t
,p
t
,v
t-1
),其中,v
t
表 示机器人速度信息,laser
t
为观测值信息,p
t
为目标点信息,f为映射函数,v
t-1
为上一时刻速度信息。
[0064]
较佳的,所述融合模块具体为:用于将多维观测值信息矩阵(...)进行 滤波后,与二维的速度信息矩阵(x,y)以及二维的目标点信息矩阵(z, w)进行融合,组合成一个新的多维矩阵(x,y,z,w,...)作为神经网络 模型的输入。
[0065]
较佳的,所述神经网络模型是基于tensorflow框架搭建的,所述神经 网络模型中采用的强化学习算法为近端策略优化算法(proximal policyoptimization,ppo),所述神经网络模型包括两个稠密层,每一稠密层的维 度均为512。稠密层作为输出网络结构设置成两层可以更准确的计算输出, 根据输入的维度对应的可将本发明稠密层维度设置为512。
[0066]
ppo最早是用于游戏领域,其优异的表现被很多研究者推广到其他领 域。近端策略优化适合连续的动作空间,这种控制对于离散的dqn而言动 作会更加顺滑。ppo的强化学习网络将直接输出连续的动作,动作为线速 度与角速度。所以本发明设计近端策略优化的drl网络,其结构如图5所 示,将维度为100
×
1的观测值矩阵数据进行过滤后,和维度为2
×
1的上一 时刻速度v
t-1
矩阵数据以及维度为2
×
1的目标点p
t
矩阵数据进行融合后,输 入到本发明的近端测量优化drl网络,经稠密层输出维度为512的速度信 息。
[0067]
较佳的,所述近端策略优化算法的奖赏函数设置为:
[0068][0069]
其中,当移动机器人的激光检测到与障碍物的距离laserr(t)小于0.2m的 时,此时判定为碰撞到障碍物,回馈为一个负的奖励值rc,进行对移动机 器人的惩罚,结束这一回合,重置机器人与环境的位置,重新开始新一类的 训练;当机器人与指定目标点的距离d(t)小于目标点圆心距离阈值cd时,则 判定机器人抵达目标点。其中,cr(d(t-1)-d(t))-c
p
为时刻前后距离差的奖 赏值计算公式,及除了上述两种情况下的其它情况中,采用该公式计算r值, cr为奖赏倍率,c
p
为时间惩罚因子。
[0070]
由于本发明实施例二所介绍的系统,为实施本发明实施例一的方法所采 用的系统,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了 解该系统的具体结构及变形,故而在此不再赘述。凡是本发明实施例一的方 法所采用的装置都属于本发明所欲保护的范围。
[0071]
基于同一发明构思,本技术提供了实施例一对应的存储介质,详见实施 例三。
[0072]
实施例三
[0073]
本实施例提供了一种电子设备,如图3所示,包括存储器、处理器及存 储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序 时,可以实现实施例一中任
一实施方式。
[0074]
本发明采用ppo算法进行强化学习,因为近端策略优化是一种改进型 策略梯度(policy gradient,pg),pg属于同策略法(on policy),智能体收集数 据来更新目前策略π
θ
的θ,这是一个循环的过程,θ更新重新收集数据。相反 的异策略法(off policy),它是通过π
θ
′
收集数据训练,即使用π
θ
′
采样数据可以 不受限制,深度q学习可借助于该方法的经验回放完成训练。ppo的提出 解决了同策略的效率问题。因为ppo算法是重要性采样运用在策略梯度的 目标函数j的导数的推导得到的,其式子如下所示,为了简化该式子,令 a(s
t
,a
t
;θ)为t,π
′
(a
t
,a
t
;θ
′
)为p,π(ai|si;θ)为r:
[0075][0076]
式子式依赖π'采集的样本来训练π,所以j在优化方面可以重复使用样 本,进行多步更新,这存在一个前提条件,π和π
′
需要接近,不能相差太远, 所以在此过程中更新的停止时间要提前确定,否则会出现表现性不佳的现 象。为解决此问题,提出了信赖域策略优化(trust region policy optimization, trpo),它的做法是添加约束。trpo的求解式子如下所示,令 分别化简为π
θ
:
[0077][0078][0079]
trpo的一阶近似得到ppo算法,其式子如下所示,令r
t
(θ)a(s
t
,a
t
)为 r
t
a,a(s
t
,a
t
)为a:
[0080]jclip
(θ)=e
t
[min(r
t
a,clipa)]
[0081][0082]
上式中clip函数可以将r
t
(θ)限制在[1-ε,1+ε],若值低于1-ε则取1
‑ꢀ
ε,若值高于1+ε则取1+ε。可见,使用这种带有约束的ppo算法来训 练本发明的数据,能够提高本发明模型精准度,最终提升本发明机器人导航 成功率。
[0083]
为了验证本发明的上述技术方案的效果,做了以下实验:
[0084]
1、gazebo仿真环境下的导航策略模型训练
[0085]
采用ubuntu下的gazebo搭建用于执行导航任务的训练环境。gazebo 可以在避障导航的环境中设置时间变量来加速训练时间,最为关键的是它可 以很好的兼容ros系统。本实验中的训练平台为华硕笔记本zx50v,内存 12g,显卡gtx960。
[0086]
在进行训练前需要设定好奖赏函数的参数。其数值如表1所示:
[0087]
表1仿真参数表
[0088][0089]
用于导航策略训练的仿真环境如图6所示。该环境中存在固定目标点, 固定障碍
物,以及动态障碍物,移动机器人将在该环境中执行导航任务。本 发明选择的深度强化学习的算法为ppo算法,为了对ppo算法的训练效果 做出评估,实验中还选择了基准算法dqn进行对比。训练结果如图7和图 8所示。
[0090]
由图7可以看到,ppo算法的平均奖赏值高于dqn,并且在1000episode 左右就已经处于稳定的300,这说明本发明所采用的算法能够更好的适应该 训练环境。图8是两个算法抵达目标点的成功率曲线,本发明选择的算法的 成功率在结束训练前已经到达了90%左右并且1800episode达到了收敛,而 基准算法dqn到最后3500episode仅仅达到65%左右,所以由上面的结果 可以得到ppo算法相对dqn更适于动态障碍环境。
[0091]
为了验证实际机器人是否能继承仿真环境中训练好的策略模型,设置了 两个实验,两个实验均采用两轮差速移动机器人roboster进行实验。避障 实验场景如图9所示。避障实验采用vicon光学捕捉系统采集机器人与行人 的位置信息。vicon可以与ros系统进行通信,可以保存机器人与行人轨迹 的数据包,通过matlab可以绘制路径的曲线。图9的场景里包含了7个vicon 传感器,光学标记物,两轮差速移动机器人,行人。在实验中的移动机器人 和行人身上都带有一定数量的反光球,vicon传感器会发射红外光,它将根 据反光球反射的红外光线进行精确的定位。
[0092]
完成避障实验后,通过保存的数据包解析得到的2维和3维轨迹图如图 10,图11所示。
[0093]
图10,图11可以看到两个轨迹,里面或下面的轨迹为机器人的移动轨 迹,外面或上面的轨迹为人的移动轨迹。从轨迹趋势可以看到,机器人轨迹 一直在趋避行人轨迹,该结果表示移动机器人已经拥有较好的动态避障能 力。
[0094]
为了验证机器人是否具备导航能力,还设计了导航实验,其实际场景地 图与示意图如图12和图13所示。实际的地图需要具备起点以及目标点,其 效果如图13所示,图13仅用于显示起点与目标点,实际导航不需要地图。 机器人需要按照目标点的顺序进行分步导航,当到达目标点1之后再进行目 标点2的导航。导航过程中的奖赏值如图14所示。机器人的从起点位置出 发,先进行目标点1的导航,因为目标点1是较近距离,所以机器人很轻松 的完成了导航任务,从图14累计的奖赏值图的第一段就可以看出曲线呈现 稳定的上升趋势,说明机器人始终是沿着正确的方向前进。目标点2相较于 目标点1的距离稍远,机器人需要重新进行寻找方向,所以出现了奖赏值图 的第二段曲线的状态,机器人根据策略进行矫正,最终寻找到目标点2。从 上面奖赏值的曲线可以很好的反映出机器人前进方向是否正确,曲线的结果 证实了移动机器人已经具备良好的导航能力。
[0095]
本发明使用强化学习的方法解决了机器人在无地图环境下的导航,将游 戏领域表现优异的ppo算法运用在移动机器人的导航决策上。在仿真环境 gazebo下添加了间隙地图以及移动的障碍物,增加了移动机器人对于环境 的适应力,本发明选择的算法与基准算法相比,ppo算法在导航成功率和 迭代次数上都优于dqn算法。本发明选择的观测值为雷达点的range数据 作为输入,经过实体机器人多样测试,解决了策略迁移的问题,实体移动机 器人具备良好的动态避障能力以及无地图导航能力,其单目标的导航成功率 和多目标导航成功率均得到了提升。
[0096]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或 计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、 或结合软件和硬件方面的
实施例的形式。而且,本发明可采用在一个或多个 其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘 存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0097]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产 品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图 和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/ 或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌 入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过 计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流 程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的 装置。
[0098]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理 设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储 器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程 或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0099]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上, 使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现 的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程 图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步 骤。
[0100]
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人 员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发 明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的 修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1