基于维度裁剪的PPO算法的四旋翼姿态轨迹控制方法
基于维度裁剪的ppo算法的四旋翼姿态轨迹控制方法
技术领域
1.本发明属于四旋翼无人机的智能控制技术领域,尤其涉及一种基于维度裁剪的近端策略优化算法的无人机姿态轨迹控制方法。
背景技术:
2.近年来,无人机被广泛应用于农业植保、公安、军事、消防应急等领域。四旋翼是典型的欠驱动非线性强耦合系统,其姿态控制和轨迹控制一直是研究的热点之一。但是,影响四旋翼飞行器的因素很多,如环境干扰、飞行时电机快速旋转产生的陀螺扭矩、空气阻力干扰、旋翼质量分布不均等。这种不确定性使得对四旋翼飞行器进行精确建模非常困难。因此,依赖精确建模的传统控制算法难以满足控制要求,探索一种能够将环境与可变动态适应性相结合的方法是非常必要的。在四旋翼控制方法研究中,根据预设的性能范围,传统控制方法难以快速收敛控制系统的跟踪误差。强化学习作为一种有效的无模型方法并应用于四旋翼飞行器以实现四旋翼飞行器系统的优化控制。利用神经网络开发智能飞行控制系统已逐渐成为一个非常热门的研究领域。
3.强化学习算法可以在接近现实世界复杂性的情况下取得成功。专利号cn 111460650 a的专利采用了一种基于深度强化学习的无人机端到端控制方法,来完成无人机的自主着陆任务,该发明用到的actor
‑
critic算法虽然在应对不同阶段中导航的高端控制策略上优于dqn等值函数强化学习算法,但在训练控制策略时,actor网络的策略更新还是过于依赖critic网络给出的优势值,样本采样率较低。专利号cn 108319286 a的专利采用一体化控制器来取代传统的内外环控制器,提供了一种基于近端策略优化算法的无人机目标跟踪控制方法,其仿真环境仅考虑在室内无干扰的情况下进行,这并不足以验证ppo算法能否有效的应用于真实情况下的无人机飞行。专利号cn 112650058 a的专利提出了一种基于强化学习四旋翼无人机轨迹控制方法,其设置的控制器回报函数过于简单,不利于四旋翼控制策略的探索。专利号cn 110488872 a的专利一种基于深度强化学习的无人机实时路径规划方法,利用双重q网络完成无人机的实施路径规划,但其设置的无人机动作空间集太少,仅8个方向(前进,左转45
°
,左转90
°
,左转135
°
,后退,右转135
°
,右转90
°
,右转45
°
),这使得在未知的干扰环境下(如随机风场、磁场等)四旋翼不能够快速收敛到稳定状态。
4.近端策略优化算法使用裁剪目标函数绑定当前策略的策略更新,实现稳定学习。当迭代从第i次开始时,策略π
θi
生成当前样本批次b
i
={(s
i,0
,a
i,0
,r
i,0
),
…
,(s
i,n
‑1,a
i,n
‑1,r
i,n
‑1)},长度为n。然后策略π
θ
根据在b
i
中采样的多个小批量完成更新。由于生成bi的策略π
θi
与策略更新的目标策略π
θ
之间存在差异,ppo算法根据重要性采样(is)权重r
i
校准策略π
θi
与目标策略π
θ
之间的统计差异。
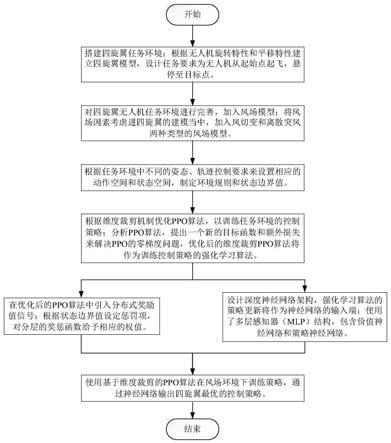
5.此外,在“schulman,j.,levine,s.,abbeel,p.,jordan,m.,and moritz,p.trust region policy optimization.in proceedings of the 32nd international conference on machine learning(icml
‑
15),pp.1889
–
1897,2015a.”中,为了限制策略更新量以保证学习的稳定性,ppo降低了is权重。因此,ppo的目标函数由下式给出:
[0006][0007]
其中其中是的估计值,b
i
在每个小批量中随机采样m个样本。
[0008]
ppo通过裁剪目标函数而不是使用kl散度约束来限制策略更新次数稳定更新。好处是这种裁剪机制可以防止r
t
变得过小或过大,尤其是对于很多复杂的环境,稳定的更新范围更有利于更快更高效的训练。当简化裁剪后的目标函数时,可以得到:
[0009]
当且r
t
<1
–
ε时,
[0010]
当且r
t
>1+ε时,
[0011]
在上述情况下,是常数并且梯度消失。这种零梯度的问题,尤其是在高动作维度的任务中,是非常严重的。所以正是因为ppo直接裁剪损失函数,ppo生成的零梯度样本极大地影响了样本效率,从而也影响了复杂四旋翼系统中的学习效率和跟踪精度。本发明提出的基于维度裁剪的ppo强化学习算法,在复杂的高维度环境下能够有效增加样本效率,在风切变和离散突风的风场环境下进行测试,也有效的验证了控制策略的抗干扰能力。
技术实现要素:
[0012]
本发明的目的是提出一种基于维度裁剪的ppo算法的四旋翼姿态轨迹控制方法,用于四旋翼飞行器的姿态轨迹控制。不仅有效解决了ppo算法的零梯度问题,可以在保持良好采样效率的同时快速收敛,而且在控制精度上也有更好的表现。
[0013]
本发明解决其技术问题所采用的技术方案如下。
[0014]
一种基于维度裁剪的ppo算法的四旋翼姿态轨迹控制方法,包括以下步骤:
[0015]
s1:搭建四旋翼任务环境;
[0016]
无人机控制系统为欠驱动系统,四输入六输出。建立固定在四旋翼上的惯性坐标系和体坐标系来描述四旋翼的姿态和位置。两个坐标系有如下转换关系:
[0017][0018]
其中φ,θ,ψ为四旋翼的三个欧拉角,s{
·
}和c{
·
}表示为sin(
·
)and cos(
·
)。
[0019]
四旋翼的非线性动力学方程如下:
[0020]
设定任务要求为控制四旋翼从[0,0,0]的
起始点起飞至[5,5,5]的目标点并稳定的悬停在目标点。
[0021]
s2:对四旋翼无人机任务环境进行完善,加入风切变和离散突风两种风场模型;其中风切变的模型为其中,v
pw
为产生的风切变风速值,v
w0
为摩擦速度,由空气密度ρ和地面剪应力τ0决定,表达式为:k为karman常数,h为四旋翼的飞行高度,一般取0.4,h0为粗糙度高度,一般取为0.05。离散突风的模型为其中v
wm
为突风的峰值,d
m
为突风尺度范围,x为离突风中心的距离。
[0022]
s3:根据任务环境中不同的姿态、轨迹控制要求来设置相应的动作空间和状态空间,制定环境规则和状态边界值;
[0023]
s4:根据维度裁剪机制优化ppo算法,以训练任务环境的控制策略;将现有ppo算法的各个维度的重要性采样权重分别裁剪,更改为一个新的目标函数,如下所示:
[0024][0025]
其中π
θ
(
·
|s
t
)=n(μ,σ2i)为目标策略,μ=(μ0,μ1,
…
,μ
d
‑1)是均值向量,d是动作维度,σ是方差,i是单位矩阵。当策略π
θ
被分解为策略维度时,π
θ,d
(
·
|s
t
)~n(μ
d
,σ2),假设a
t,d
是a
t
的第d个元素,则
[0026]
本发明还新增了一个额外的损失以防止is权重离太远。最后的目标函数如下:
[0027][0028]
其中α
is
是权重因子,类似于ppo的kl散度约束。它通过自适应方式改变其价值:
[0029][0030]
s5:在优化后的ppo算法中引入分布式奖励值信号;设置了一个结合多种奖励策略的奖励函数来替代单一简单的奖励函数。
[0031]
s6:设计深度神经网络架构,强化学习算法的策略更新将作为神经网络的输入端;训练使用了两种神经网络,一个是critic神经网络,另一个是actor神经网络θ。四个策略子网络θ
i
(i=1,2,3,4)组成了actor神经网络。
[0032]
s7:使用基于维度裁剪的ppo算法在风场环境下训练策略,通过神经网络输出四旋翼的控制策略;训练过程中强化学习算法对控制策略进行更新,设定训练周期为n,四旋翼
与环境在每个周期内进行交互,经验池中将存储所得到的信息,存储到一定批次后,数据将进入神经网络,用于算法对策略的更新迭代,直到n个周期全部训练完毕,所得到的策略网络结构将作为四旋翼无人机的控制策略来使用。
[0033]
与现有的技术相比,本发明有如下优点:
[0034]
1.本发明在近端策略优化算法的基础上训练控制策略,这是一种随即策略梯度算法,与如今相对成熟的确定性策略梯度的强化学习算法相比,确定性策略梯度的优势都建立在有良好的探索策略的基础上。而随机策略梯度可以提供更好的样本效率,这也直接影响控制策略收敛所需的时间步长,使训练相对更快更有效。
[0035]
2.本发明通过在四旋翼的环境模型中加入了风切变和离散突风两种风场模型,极大程度的模拟真实环境,不仅为强化学习运用到实际环境提供了良好基础,也更能验证强化学习算法在复杂环境下的抗干扰能力很强。
[0036]
3.现有的强化学习奖励函数设置都较为简单,本发明探索稀疏奖励、形式化奖励和分布奖励等多种奖励相结合的方法,可以共同促进强化学习算法有效的收敛,有效减少四旋翼控制策略的无效探索。
[0037]
4.本发明的动作集为四旋翼四个转子的转速,在训练时面对未知的复杂环境时,四个转子转速作为控制器的四个输出通道能够更精准的控制无人机。
[0038]
5.本发明在近端策略优化算法上增加了维度裁剪机制,加快了ppo算法的样本学习效率,有效的解决了ppo算法的零梯度问题。
附图说明
[0039]
图1是本发明的方法流程图;
[0040]
图2(a)是本发明的无人机轨迹观测模型示意图;
[0041]
图2(b)是本发明的无人机姿态观测3d模型示意图;
[0042]
图3是本发明的风场模型风切变示意图;
[0043]
图4是本发明的风场模型半波长离散突风示意图;
[0044]
图5是本发明无人机起飞悬停任务流程图;
[0045]
图6是无人机强化学习控制系统结构图;
[0046]
图7(a)是本发明的策略子网络结构图;
[0047]
图7(b)是本发明的价值函数估计器网络结构图;
[0048]
图8是本发明的系统网络框架结构图;
[0049]
图9是控制器与环境交互流程图;
[0050]
图10(a)是本发明实施例的算法优化前后的稳态误差对比图;
[0051]
图10(b)是本发明实施例的算法优化前后的平均累计奖励对比图;
[0052]
图11是本发明实施例两种算法在无人机悬停时姿态的仿真对比图。
具体实施方式
[0053]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实
施例,都属于本发明保护的范围。
[0054]
如图1所示,一种基于维度裁剪的ppo算法的四旋翼姿态轨迹控制方法,包括以下步骤:
[0055]
s1:搭建四旋翼任务环境;
[0056]
本发明的无人机轨迹观测模型示意图和姿态观测3d模型示意图如图2所示。建立了两个坐标系来描述四旋翼的姿态和位置:第一个是惯性坐标系,固定在地球上,第二个是惯性坐标系,它是固定在四旋翼飞行器上的身体固定坐标系,其原点是四旋翼飞行器的质心。一开始两个坐标系是重合的,但在飞行过程中,机身固定坐标系会旋转移动,而惯性坐标系始终保持不变。
[0057]
在本发明中,使用三个欧拉角φ,θ,ψ,来描述绕x轴、y轴和z轴的旋转过程。四旋翼飞行器质心的位置在惯性坐标系中定义为p=[x,y,z]
t
,并且可以表示为四旋翼飞行器的速度和加速度。
[0058]
分布在十字形框架末端的四个旋翼用于驱动四旋翼。质心到每个转子的距离为l。电子调速器(esc)通过脉宽调制信号控制转子的转速。通过电调,转子产生的推力可以与发送到转子的pwm信号近似成正比,即
[0059]
t
i
=ku
i
,i=1,2,3,4.
[0060]
其中t
i
(i=1,2,3,4)代表产生的推力。k代表推力增益。u
i
(i=1,2,3,4)代表归一化为[0,1]的pwm信号;u
i
=1时,表示系统将获得最大推力,u
i
=0表示系统将获得零推力。
[0061]
接着利用扭矩驱动的旋转运动和力驱动的平移运动的动力学特性来建立动力学模型。
[0062]
对于旋转运动特性,欧拉旋转方程将应用于固定的四旋翼框架:
[0063][0064]
其中i=diag(i
x
,i
y
,i
z
)是四旋翼的对角惯性矩阵,是四旋翼三轴的角速度,m是施加到四旋翼上的扭矩之和。m
τ
=[τ
φ
,τ
θ
,τ
ψ
]
t
是四旋翼的控制力矩,是不同升力和推力的结果:
[0065][0066]
控制力矩τ
φ
和τ
θ
围绕车身固定框架的x轴和y轴。控制力矩τ
ψ
的方向为z轴方向,即四个转子产生的反作用力矩之和。反作用力矩的值与推力成正比,系数为k
ψ
。陀螺效应由四个微调器产生,其中每个转子的转动惯量为i
p
,ω是每个转子的扰动效应。是四旋翼飞行的阻力力矩,其中d
φ
,d
θ
和d
ψ
是三个轴的旋转阻力系数。
[0067]
对于平移运动,根据牛顿第二定律在惯性坐标系中得到:
[0068][0069]
其中f
e
表示作用在四旋翼机身上的合力,f
l
=[0,0,t
z
]表示升力矢量,其中
是产生的升力之和,t
i
是每个螺旋桨产生的升力。为空气阻力,其中d
x
、d
y
、d
z
为绕三个轴方向的阻力系数。g=[0,0,
‑
mg]
t
是重力,其中g是重力加速度。m是四旋翼飞行器的质量。
[0070]
当固定坐标系中的升力转换为惯性坐标系时,需要用到变换矩阵r来实现坐标系的统一:
[0071][0072]
其中φ,θ,ψ为四旋翼的三个欧拉角,s{
·
}和c{
·
}表示为sin(
·
)and cos(
·
)。
[0073]
最后,四旋翼的非线性动力学方程如下:
[0074][0075]
模型中所使用的参数及意义如下表1所示:
[0076][0077]
s2:对四旋翼无人机任务环境进行完善,加入风场模型;
[0078]
对风场进行工程化建模,模型主要反映了风场现象最本质的机理和形成过程,可以利用此模型产生风速,为模拟飞行器飞行时较真实的外界风场环境提供了技术手段。以下为本发明中用到的风场模型:
[0079]
s2.1:风切变
[0080]
本发明主要研究地面边界层风切变,是考虑到在实际飞行中,四旋翼飞行器的飞行高度有限。风切变模型示意图如图3所示,该模型的风速值在水平方向上为定值,竖直方向上与飞行器飞行高度有关。其对数模型可表达为:
[0081][0082]
式中,v
pw
为产生的风切变风速值,v
w0
为摩擦速度,由空气密度ρ和地面剪应力τ0决定,表达式为:k为karman常数,h为四旋翼的飞行高度,一般取0.4,h0为粗糙度高度,一般取为0.05。
[0083]
s2.2:离散突风
[0084]
离散突风的风速在各个方向上会产生突然剧烈的变化,又称为阵风,通常在应用研究中采用半波长离散突风。离散突风模型示意图如图4所示,其模型可表示为:
[0085][0086]
其中v
wm
为突风的峰值,d
m
为突风尺度范围,x为离突风中心的距离。
[0087]
s3:根据任务环境中不同的姿态、轨迹控制要求来设置相应的动作空间和状态空间,制定环境规则和状态边界值。
[0088]
s3.1:姿态控制是四旋翼无人机控制系统中最基础也是最重要的部分,在机体与环境交互的过程中,设定转子转速为四旋翼控制策略需要选择的动作,三个欧拉角和其角速度为四旋翼的状态,这样就得到了三维的动作空间和六维的状态空间。为了满足四旋翼飞行器实际飞行的安全要求,在保证物理可行性的条件下对其进行约束,设置动作空间的大小为[0,500],姿态角速度的状态空间大小设置为[
‑
4.5,4.5],也满足陀螺仪传感器的限制,姿态角的状态空间大小设置为[
‑
45
°
,45
°
]。
[0089]
s3.2:无人机的轨迹控制,设定转子转速为四旋翼控制策略需要选择的动作,其位置为四旋翼的状态,这样就得到了三维的动作空间和三维的状态空间。设置动作空间的大小为[0,500],状态空间大小为[
‑
10,10]。
[0090]
s3.3:无人机的姿态和轨迹同时控制的起飞悬停任务,任务流程图如图5所示。控制四旋翼从[0,0,0]的起始点起飞至[5,5,5]的目标点并稳定的悬停在目标点。设定转子转速为四旋翼控制策略需要选择的动作,三个欧拉角速度、滚转角、俯仰角以及四旋翼的位置作为四旋翼的观测状态,偏航角不作限制,这样就得到了三维的动作空间和八维的状态空间。设置动作空间的大小为[0,500],位置的状态空间大小为[
‑
10,10],姿态角速度的状态空间大小设置为[
‑
4.5,4.5],滚转、俯仰角的状态空间大小设置为[
‑
45
°
,45
°
]。
[0091]
s4:根据维度裁剪机制优化ppo算法,以训练任务环境的控制策略;
[0092]
强化学习控制系统结构图如图6所示,近端策略优化算法在执行连续动作任务时使用高斯分布作为随机策略,π
θ
(
·
|s
t
)=n(μ,σ2i),即其中μ=(μ0,μ1,
…
,μ
d
‑1)是均值向
量,d是动作维度,σ是方差,i是单位矩阵。当策略πθ被分解为策略维度,π
θ,d
(
·
|s
t
)~n(μ
d
,σ2),假设a
t,d
是a
t
的第d个元素,则
[0093]
在保持裁剪优点的同时,将ppo算法各个维度的重要性采样权重分别裁剪,更改为一个新的目标函数,如下所示:
[0094][0095]
此外,新增一个额外的损失以防止is权重离太远。最后目标函数如下:
[0096][0097]
其中α
is
是权重因子,它通过自适应方式改变其价值:
[0098][0099]
最终算法的伪代码如表2所示。
[0100]
[0101][0102]
s5:在优化后的ppo算法中引入分布式奖励值信号;
[0103]
现有的强化学习奖励函数设置比较简单:
[0104][0105]
其中(φ,θ)是四旋翼的姿态角观测值,是角速度的观测值,(x,y,z)是位置观测值,r是单步奖励值。在初始化阶段,四旋翼可能会出现过大的角度偏差或位置偏转。本发明设置了一个结合多种奖励策略的奖励函数。
[0106]
fig.1.
[0107]
fig.2.r2=
‑
γ*arctan(s)*(x2+y2+z2)
[0108]
fig.3.
[0109]
fig.4.
[0110][0111]
r
new
=r1+r2+r3+r4+r5[0112]
其中α,β和γ是三个误差系数来控制姿态和位置相对于奖惩函数的权重,s是四旋翼当前位置与目标位置间的直线距离。当四旋翼越靠近目标点时,姿态角奖惩值的权值会增大,当四旋翼开始偏离目标点时,位置奖惩值得权值会增大。r
t
是四旋翼稳定状态下的奖励,一般取0.5,r
p1
和r
p2
分别代表姿态角和位置的边界惩罚,一般取
‑
1,目标误差值一般取0.1。
[0113]
s6:设计深度神经网络架构,强化学习算法的策略更新将作为神经网络的输入端;神经网络的结构图如图7所示,训练使用两种神经网络,一个是critic神经网络,另一个是actor神经网θ。四个策略子网络θ
i
(i=1,2,3,4)组成了actor神经网络。它们的权重在训练后将得到优化。
[0114]
由于神经网络良好的泛化能力,本发明使用了多层感知器(mlp)结构。在actor神经网络的结构中,每个策略子网络有两个隐藏层,每个隐藏层有64个tanh节点,状态向量是
一个八维的向量。critic神经网络具有相同的结构,它的唯一输出是估计值函数,用于评估在给定状态下选择给定动作的优势。
[0115]
神经网络参数如表3所示:
[0116][0117]
s7:使用基于维度裁剪的ppo算法在风场环境下训练策略,通过神经网络输出四旋翼的控制策略;
[0118]
如图8所示,进入训练过程时,同一个状态向量进入两个神经网络作为网络输入。四个子网络的输出分别为μ
i
和σ
i
(i=1,2,3,4),分别对应高斯分布的四组均值和标准差。高斯分布随机采样一组动作,并将所选动作归一化为u
i
(i=1,2,3,4)。μ
i
成为四旋翼飞行器的输入,它会变成一个新的状态。
[0119]
当前actor网络收集到一批状态向量后,将四个策略子网络的网络参数复制到老actor网络中。进入老actor网络的参数保持不变。当进入当前批次的状态时,四个子网络继续训练和更新。对于critic神经网络,它产生的优势值将评估为实现这些状态而采取的措施的质量。在使用梯度下降法最小化其参数的更新后,critic神经网络将优势值和参数一起馈送到策略更新环节,从而完成actor神经网络的更新过程,控制器与环境交互流程图如图9所示。
[0120]
在训练过程结束后,如图10所示,基于维度裁剪的ppo算法在学习速率上要优于ppo算法。面对高维度任务的训练环境,盲目探索的ppo算法容易出现零梯度问题,导致“学不会”的情况。如图11所示,基于维度裁剪的ppo算法不仅能有效地学习控制策略,在随机风场的干扰下抗干扰能力也更强,姿态的控制精度也相对更高,侧面说明在结合风场的环境下训练,基于维度裁剪的ppo算法样本采样率更高,学习到的控制策略精度也更高。
[0121]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1