量化式数据分析方法以及量化式数据分析装置与流程
本发明是有关于一种量化式数据分析方法,且特别是有关于一种与信息安全相关的数据分析方法。
背景技术:
近年来,一些研究机构指出,全球企业因资料外泄所造成的损失,达1兆美元以上,一些研究报告也指出,2011年的资料外泄个案是2010年的五倍多,而企业安全的十大威胁中,“员工不经意中而泄漏重要信息”和“资料被内部成员窃取”等威胁分别位于第二和第五名,由内部成员外泄机密的事件逐年增加,已与外部入侵窃取机密的比例相当。为了保护企业内部的重要数据,许多企业均采用信息安全(informationsecurity)管理系统来监控企业内部的各种信息,避免重要数据外流而造成企业的重大损失。一般而言,这些企业的信息安全政策会对计算机的文档写出权限、光盘烧录权限、文档打印权限、软/硬件使用权限、网页浏览权限、网络传输权限及记录查询...等做出设定与纪录,以对企业内部的计算机信息进行控管。然而,目前企业内部所采用的信息安全控管方法,大多无法十分准确有效地找出需要保密的文件,极有可能将一般员工的私人文件也当成机敏文件处理,造成员工的困扰;或是需要庞大的资源来对企业内部的文件进行管控,消耗了庞大的人力与物力成本。
技术实现要素:
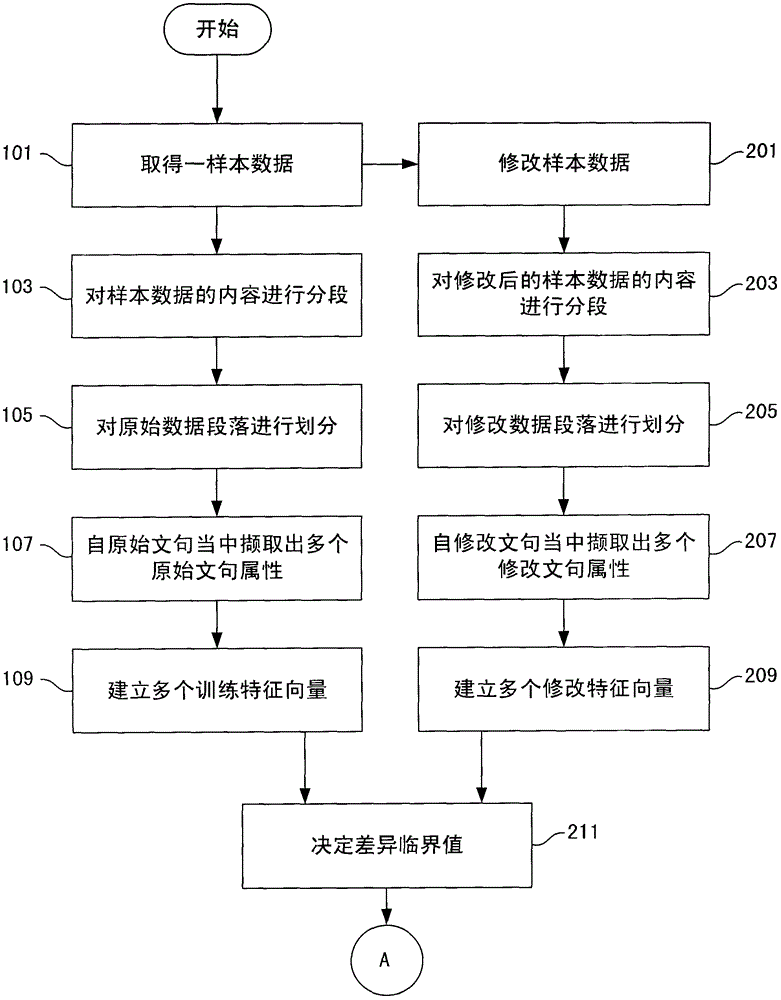
因此,本发明的一方面是在提供一种量化式数据分析方法,能够有效且准确地对企业内部的文件或是应用程序进行管控,降低人力与物力成本。依据本发明一实施例,量化式数据分析方法应用于一计算机系统当中,以判断一待测文件是否具敏感性,此量化式数据分析方法是取得计算机系统当中的一样本数据;对样本数据的内容进行分段,以取得至少一原始数据段落;对 原始数据段落进行划分,以取得多个原始文句;自原始文句当中撷取出多个原始文句属性;以及依据原始文句属性,建立多个训练特征向量。本发明的另一方面是在提供一种量化式数据分析装置,能够有效且准确地对企业内部的文件或是应用程序进行管控,降低人力与物力成本。依据本发明的另一实施例,量化式数据分析装置内建于一电子装置当中,以判断一待测文件或是正在执行的一应用程序是否具敏感性,此量化式数据分析装置内含一文本特征建置器以及一邻似特征搜寻器。文本特征建置器含有一数据撷取器、一数据划分器以及一文句分析器。数据撷取器取得一样本数据或是一待测文件,并分别自样本数据或是待测文件中,抽取出一原始数据或是一待测数据;数据划分器对原始数据或是待测数据的内容进行分段,以取得至少一原始数据段落或是至少一待测数据段落,并对原始数据段落或是待测数据段落进行划分,以取得多个原始文句或是多个待测文句。文句分析器自原始文句或是待测文句当中,撷取出数个原始文句属性或是数个待测文句属性,并依据原始文句属性或是待测文句属性,建立数个训练特征向量或是多个待测特征向量。邻似特征搜寻器依据待测特征向量、训练特征向量,以及差异临界值,决定待测文件是否为具敏感性。以上实施例的量化式数据分析装置以及量化式数据分析方法,是运用量化方式参考前后文的特征,以文件内容为基础进行分析,不因单一关键词而造成误判;对于未知文件或稍作修改的已知文件皆能正确判断,增加了可应用的层面。附图说明为让本发明的上述和其它目的、特征、优点与实施例能更明显易懂,所附附图的说明如下:图1是绘示本发明一实施方式量化式数据分析方法的流程图;图2A、图2B以及图2C是绘示本发明两种实施方式量化式数据分析方法的流程图;图3是绘示本发明一实施方式特征向量说明示意图;图4是绘示本发明一实施方式量化式数据分析装置的方块图;图5A、图5B以及图5C是分别绘示本发明三种实施方式当中电子装置的 应用示意图。【主要组件符号说明】具体实施方式以下实施例的量化式数据分析装置以及量化式数据分析方法,是运用量化方式参考前后文的特征,对文件内容为基础进行分析,未知文件或稍作修改的已知文件皆能正确判断;此外,使用者可自订相似度门槛值,作为分类的依据,增加了比对的弹性。请参见图1,其是绘示本发明一实施方式量化式数据分析方法的流程图。量化式数据分析方法应用于一计算机系统当中,此计算机系统可为区域计算机系统、网际计算机系统,或是电话计算机系统,以判断一待测文件是否具敏感性。量化式数据分析方法首先取得计算机系统当中的一样本数据(步骤101),例如,至计算机系统的数据库当中,取得企业、公司的教育训练文件、营业秘密或商业秘密文件、企划文书、规格说明书、企业宣传文件等,公司或是企业不希望外流的数据,作为样本数据,以这些样本数据的内容为基础,来判断其它文件的内容是否具敏感性。在取得样本数据之后,对样本数据的内容进行分段(步骤103),目地在取得至少一原始数据段落。接着,量化式数据分析方法会对所取得的原始数据段落进行划分(步骤105),以取得数个原始文句。一般而言,可以使用句号来对原始数据段落进行划分,每出现一个句号,代表一个句子的开始以及另一个句 子的结束,借此得到数个原始文句。在步骤105取得数个原始文句之后,接着自这些原始文句当中撷取出数个原始文句属性(步骤107),其中,这些文句属性可以是字数、空白数目、逗号数目、引号数目、冒号数目、分号数目,以及英文与数字数目。也就是说,可以对一个原始文句内所含有的字数、空白数目、逗号数目、引号数目、冒号数目、分号数目,以及英文与数字数目进行累计加总,以得到加总数目。最后再依据原始文句属性,建立数个训练特征向量(步骤109),其中,这些训练特征向量是用来判断待测文件是否具敏感性的基础。举例来说,在取得待测文件的某一些特征向量之后,可以将待测文件的特征向量与所建立的训练特征向量进行比对,以两向量之间的差距为基础,判断待测文件是否为机敏文件。最后再将这些训练特征向量储存至计算机系统的一数据库(步骤111),以在数据库当中累积训练特征向量。请同时参照图2A、图2B以及图2C,其是绘示本发明两种实施方式量化式数据分析方法的流程图。在此两实施方式当中,步骤101~步骤109是与图1的实施方式相同,都是对企业或公司的样本数据建立训练特征向量。除了步骤101至步骤109以外,本实施方式当中的步骤201至步骤211则是用来决定差异临界值T,这个差异临界值T是用来判断文件敏感性的参数之一。量化式数据分析方法首先修改样本数据(步骤201)。详细来说,如果公司或是企业对资料敏感性的认定抱持较为严谨的态度,也就是说,即使待测文件与样本数据之间存在不少的差异,此待测文件仍然可能被判断为具敏感性,那么在修改样本数据时,就可以对样本数据进行较大幅度的修改,以取得容忍度较大的差异临界值T。在步骤201之后,量化式数据分析方法会对修改后的样本数据的内容进行分段(步骤203),以取得至少一修改数据段落,然后再对修改数据段落进行划分(步骤205),以取得数个修改文句;接着,量化式数据分析方法会自修改文句当中撷取出数个修改文句属性(步骤207),依据修改文句属性,建立数个修改特征向量(步骤209)。在此需要特别说明的是,修改特征向量与训练特征向量的建立方法大致相同。最后再依据训练特征向量以及修改特征向量之间的差异大小,决定差异临界值T(步骤211),这个差异临界值T是用来判断待测特征向量是否具相似性。 详细来说,可以先将修改特征向量减去训练特征向量得到一个原始差异矩阵,然后将原始差异矩阵乘以一个加权矩阵,来得到一个量化矩阵,再依据这个量化矩阵的数值,决定出差异临界值T。在差异临界值T取得之后,量化式数据分析方法会继续对需要检验的待测文件进行分析,待测文件的分析主要分成两种方法,分别绘示于图2B以及图2C。如图2B的实施方式所绘示,量化式数据分析方法会继续取得待测文件的一待测数据(步骤213),然后对待测数据的内容进行分段(步骤215),以取得至少一待测数据段落;接着继续对待测数据段落进行划分(步骤217),以取得数个待测文句,并自待测文句当中撷取出数个待测文句属性(步骤219),然后依据待测文句属性,建立数个待测特征向量(步骤221)。在此需要特别说明的是,待测特征向量群与修改特征向量群、训练特征向量群的建立方法大致相同,各向量除了代表其来源文句,向量之间的顺序也依循来源文句的顺序。当步骤221取得数个待测特征向量之后,再依据待测特征向量、训练特征向量,及差异临界值T,逐一比对以决定待测文件是否具敏感性。详细来说,是将待测特征向量群依序且逐一与训练特征向量群各元素计算差异,如图2C所绘示,首先自待测特征向量群中选取第一个待测特征向量,作为现行待测特征向量(步骤225)。接着以现行待测特征向量为基础,搭配参数矩阵R,筛选训练特征向量子集合(步骤227),参数矩阵R用以初步筛选与待测特征向量数值相似的训练特征向量子集合,参数矩阵R的各元素为对应特征向量各元素之差(距离)。挑选出的训练特征向量各元素与待测特征向量各元素的距离(绝对值)应小于参数矩阵R对应的数值。举例来说,待测特征向量Q[3,4,5,6,7,8,9]搭配参数矩阵R[2,10,10,10,10,10,10],第一个元素(数值为3)适合的范围为1至5,若训练向量P11[1,4,5,6,7,8,9],则符合挑选条件;若为训练向量P12[6,3,3,6,3,3,3],则因第一个元素(数值为6)与待测向量对应元素之差超过2,不符合挑选条件。在此步骤227当中,被选取的训练特征向量于训练特征向量群的原始位置,不得小于先前循环发现具相似性训练特征向量的位置;若先前没有发现具相似性的训练特征向量,则无此限制。之后,逐一计算现行待测特征向量与训练特征向量子集合各元素的差异 (步骤229),然后判断现行待测特征向量是否具有相似性(步骤231),其中,若结果小于差异临界值T,则判定现行待测特征向量有相似性。倘若在步骤231当中,若发现现行待测向量具相似性,则参考邻近边界值A(AdjacencymarginA),检查现行待测特征向量先前的数个待测向量是否也具相似性(步骤235);倘若具相似性,则判定待测文件具敏感性(步骤237),结束检查;其中是依据待测特征向量、训练特征向量子集合当中的训练特征向量,以及一邻近边界值A,决定待测文件是否具敏感性。若发现待测文件中任意两个具相似性的待测特征向量的间隔距离小于或等于A,则代表待测文件具敏感性,此时量化式数据分析方法可回报一肯定值;反之,若所有具相似性的待测特征向量的间隔距离均大于A,则代表待测文件不具敏感性,此时量化式数据分析方法可回报一否定值。倘若待测文件不具敏感性,则选取下一个待测特征向量作为现行待测特征向量,然后重复前述步骤。倘若前述步骤循环无法找到任意距离在A内的具相似性待测特征向量,则判定待测文件不具敏感性(步骤239)。当判断出待测文件具有敏感性之后,量化式数据分析方法可以拒绝传输此一具敏感性的待测文件、直接删除此待测文件,或是作出其它处理。请参见图3,其是绘示本发明一实施方式特征向量说明示意图。如图3所绘示,训练特征向量P1、P2、P3是对样本数据301分析得来。当样本数据301被修改之后,会得到修改后的样本数据303,修改后的样本数据303经过分析后,会得出修改特征向量Q1、Q2、Q3。这些特征向量则内含字数、空白数目、逗号数目、引号数目、冒号数目、分号数目,以及大写字母数目等信息。请参见图4,其是绘示本发明一实施方式量化式数据分析装置的方块图。量化式数据分析装置400,内建于一电子装置当中,以判断一待测文件或是正在执行的一应用程序是否具敏感性,此量化式数据分析装置含有文本特征建置器405、邻似特征搜寻器415、信息标注器417,以及数据库413。文本特征建置器405含有数据撷取器407、数据划分器409,以及文句分析器411。数据撷取器407用以取得样本数据401或是待测文件403,并分别自样本数据401或是待测文件403中,抽取出一原始数据或是一待测数据。数据划分器409对抽取出的原始数据或是待测数据的内容进行分段,以取得至少一原始数据段落或是至少一待测数据段落。数据划分器409并对原始数据段落或是待 测数据段落进行划分,以取得数个原始文句或是数个待测文句。文句分析器411自原始文句或是待测文句当中,撷取出数个原始文句属性或是数个待测文句属性,并依据原始文句属性或是待测文句属性,建立数个训练特征向量或是数个待测特征向量。邻似特征搜寻器415负责依据待测特征向量、训练特征向量,以及差异临界值T,决定待测文件是否为具敏感性。当邻似特征搜寻器415判定待测文件具敏感性时,信息标注器417为待测文件加上标注,例如,可将文件标示为机密文件,以防止外流。除了加注标示之外,信息标注器417还可以对具敏感性的待测文件作进一步的处理,例如,可以通知信息安全系统拒绝传输此一具敏感性的待测文件、直接删除此待测文件,或是作出其它处理。请同时参见图5A、图5B以及图5C,其是分别绘示本发明三种实施方式当中电子装置的应用示意图,前述实施方式当中所提及的量化式数据分析装置,则内建于这些电子装置当中,以判断待测文件或是正在执行的应用程序是否具敏感性。在图5A当中,电子装置为安全网关器(SecurityGateway)505,这个安全网关器505负责管控由个人计算机传递至因特网上的各种待测文件,以判断在网络上传递的待测文件是否具敏感性。举例来说,安全网关器505会监控个人计算机501要往外传递的电子邮件,看看这些电子邮件是否夹带具有敏感性的附加文档,如果电子邮件所夹带的附加文档具有敏感性,则安全网关器505可以拦截这封电子邮件,禁止电子邮件往外传送。在图5B当中,电子装置为网络节点509的一数据探索器(Explorer),数据探索器会探索局域网络的计算机主机515或是服务器所内含的待测文件是否具敏感性。举例来说,数据探索器会检验计算机主机515或是服务器所提供的服务是否违反企业、公司内部的规定,例如,计算机主机515或是服务器是否不当地提供网络邻居或是共享软件(FileTransferProtocol;FTP)来分享数据。另外,在图5C当中,电子装置为端点代理器525,以使用者行为为基础监控并拦截文档存取相关应用程序接口(API),如:开启文档应用程序接口527、打印文档应用程序接口529以及烧录文档应用程序接口523。举例而言,当使用者欲进行上述行为,端点代理器可于受监控的应用程序接口被呼叫的当下,自应用程序接口参数截取欲存取的文档,并进行量化数据分析。若判定预存取 的文档具敏感性,则依既定政策阻挡或进一步处理;若否,则回归原有运作流程。以上实施例的量化式数据分析方法以及量化式数据分析装置,是以文件内容为基础进行分析,参考前后文的特征,对于未知文件或稍作修改的已知文件皆能正确判断,不会因为单一关键词而造成误判;且提供效能选项,让使用者根据硬件性能及系统资源自行调整搜寻范围以及差异容忍度;使用者也可自订相似度门槛值,作为分类的依据;除此之外,量化式数据分析方法以及量化式数据分析装置还可以自机敏数据分段撷取量化特征,每次学习的结果可作为后续调校的依据。虽然本发明已以实施方式揭露如上,然其并非用以限定本发明,任何在本发明所属技术领域当中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰,因此本发明的保护范围当视所附的权利要求书所界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1