一种基于中文分词的文本相似性识别方法及装置与流程
本发明涉及文本识别技术领域,特别涉及一种基于中文分词的文本相似性识别方法及装置。
背景技术:
随着Web2.0技术及SNS的快速发展,虽然使信息传播更加便利,但重复信息也越来越多,据公开资料统计,网页的重复率平均大约为4。也就是说,当你通过一个连接看到一篇文章信息的时候,平均还有另外3个不同的链接也给出相同或者基本相似的内容。对于相同或相似的信息,现有的一些网站、社区等会对网页或文章中的文本内容进行识别,提取文本中的一些特征信息,并基于这些特征信息判断文本之间的相似程度,并通过聚类、过滤等手段对相似的文本进行处理,减少过多的无效重复信息,以及拦截批量传播的非法内容、垃圾广告等不良信息。对于文本相似性的识别,现有方法一般是基于关键字的提取,即提取文本中的关键字作为特征信息,再根据文本之间特定关键字的共性,如相同关键字的数量、相同关键字出现的次数等,确定文本之间的相似性,之后,即可基于文本相似性进行后续的聚类、过滤、拦截等处理操作。但是,这种基于关键字的文本相似性识别并不能很好的反映文本真实意思表示的相似性,其相似性识别的准确率比较低,很多文本虽然都包含某些相同的关键字,但是其要表达的意思可能完全不同甚至相反,致使很多虽然带有相同关键词,但意思表示与已知文本完全不同的文本被认为相似而被误杀,对网站、社区用户的体验伤害很大,对业务发展带来较大压力。为提高相似性识别的准确性,人们提出了其它改进的方法:向量矩阵算法,该算法将文本转换为一个向量矩阵,通过对向量矩阵进行比较,确定文本之间的相似性。全文分段签名算法,该算法把文本按一定的原则分成N段(如每n行作为一段),然后对每一段进行签名(即计算指纹),于是文本就可以用N个签名后的指纹来表示。对于两个文本,当它们的N个签名中有M个相同时(m是系统定义的阈值),则认为两个文本相似。虽然上述两种算法能够保证较高的识别准确率,降低了关键字提取方法所带来的误杀,但这两种算法所需的计算量相当大,它们在时间上的复杂度(提取特征信息和特征信息比较过程所需时间)和空间的复杂度(提取出的特征信息需要占用的存储空间)都很高,大大降低了文本相似性识别的效率,难以胜任海量文本业务的应用。
技术实现要素:
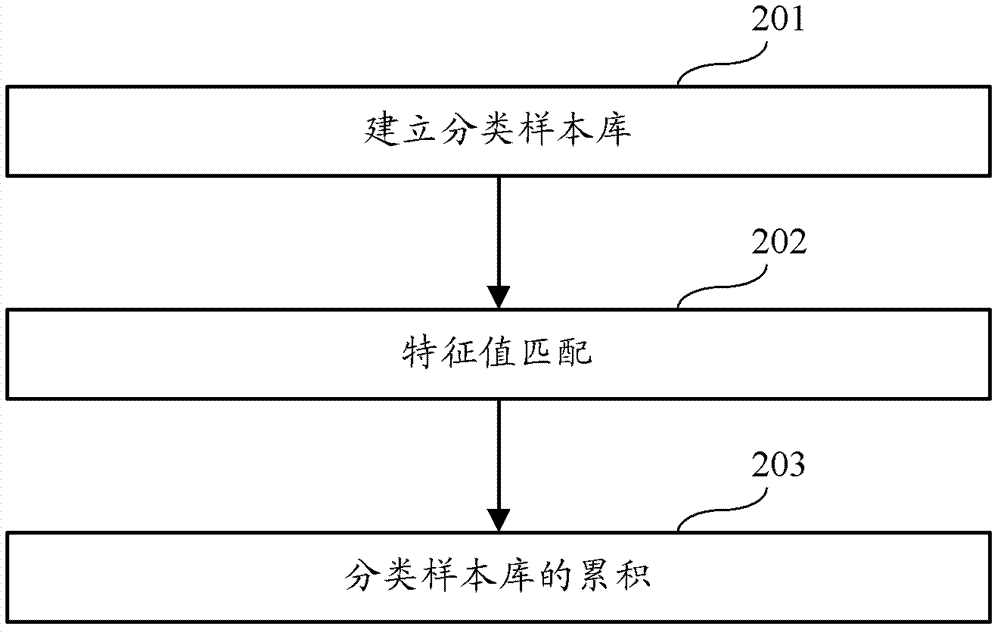
有鉴于此,本发明提供了一种基于中文分词的文本相似性识别方法及装置,可以降低识别复杂度,提高识别效率,同时达到较高的识别正确率。为达上述目的,本发明的技术方案具体是这样实现的:一种基于中文分词的文本相似性识别方法,该方法包括:对文本进行分词;根据分词的词性和出现的次数从所有分词中选择预设数量的分词作为特征词;对选择的特征词进行排序得到特征字符串,并计算所述排序得到的特征字符串的特征值;将所述特征值作为整个文本的特征值;所述排序包括:根据特征词的词性和出现的次数作为权重,对特征词进行加权排序,得到排序后的特征词字符串;通过比较文本的特征值,确定文本之间的相似性。较佳地,对文本进行分词包括:按照大粒度或小粒度模式,结合词频词性选择特定的分词单元对文本以单词为单位进行划分,并标注每个单词的词性。较佳地,对文本进行分词之前还包括:对文本中不能识别的字符以及无意义字符进行过滤。较佳地,所述特征值为根据所述排序后的特征词字符串计算的MD5值。较佳地,该方法进一步包括:预先选取样本文本并计算特征值;根据所述样本文本的特征值建立分类样本库;计算特定文本的特征值并与所述分类样本库中样本文本的特征值进行匹配;若匹配到相同的特征值,则确定该特定文本对应的分类,根据该特定文本的分类,进行对应的处理。较佳地,该方法进一步包括:若没有匹配到相同的特征值,则将该特定文本进行手工分类,并将该特定文本的特征值加入分类样本库。一种基于中文分词的文本相似性识别装置,该装置包括:分词模块,用于按照预设的分词模式对文本进行分词;选择模块,与所述分词模块相连,用于预先设定选取特征词的数量,根据分词的词性和出现的次数从所有分词中选择预设数量的分词作为特征词;特征值计算模块,与所述选择模块相连,用于根据选择的特征词的词性和出现的次数作为权重,对选择的特征词进行加权排序得到特征字符串,并计算所述排序得到的特征字符串的特征值;将所述特征值作为整个文本的特征值;比较模块,与所述特征值计算模块相连,用于通过比较文本的特征值,确定文本之间的相似性。较佳地,所述分词模块包括:模式确定单元,用于确定分词模式,包括大粒度模式或小粒度模式;划分单元,与所述模式确定单元相连,用于根据确定的分词模式,结合词频词性选择特定的分词单元对文本以单词为单位进行划分;标注单元,与所述划分单元相连,用于标注每个单词的词性。较佳地,该装置还包括:预处理模块,与分词模块相连,用于在分词之前对文本中不能识别的字符以及无意义字符进行过滤。较佳地,所述特征值计算模块包括:排序单元,用于根据特征词的词性和出现的次数作为权重,对特征词进行加权排序,得到排序后...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1