一种基于中文分词的文本相似性识别方法及装置与流程
技术特征:
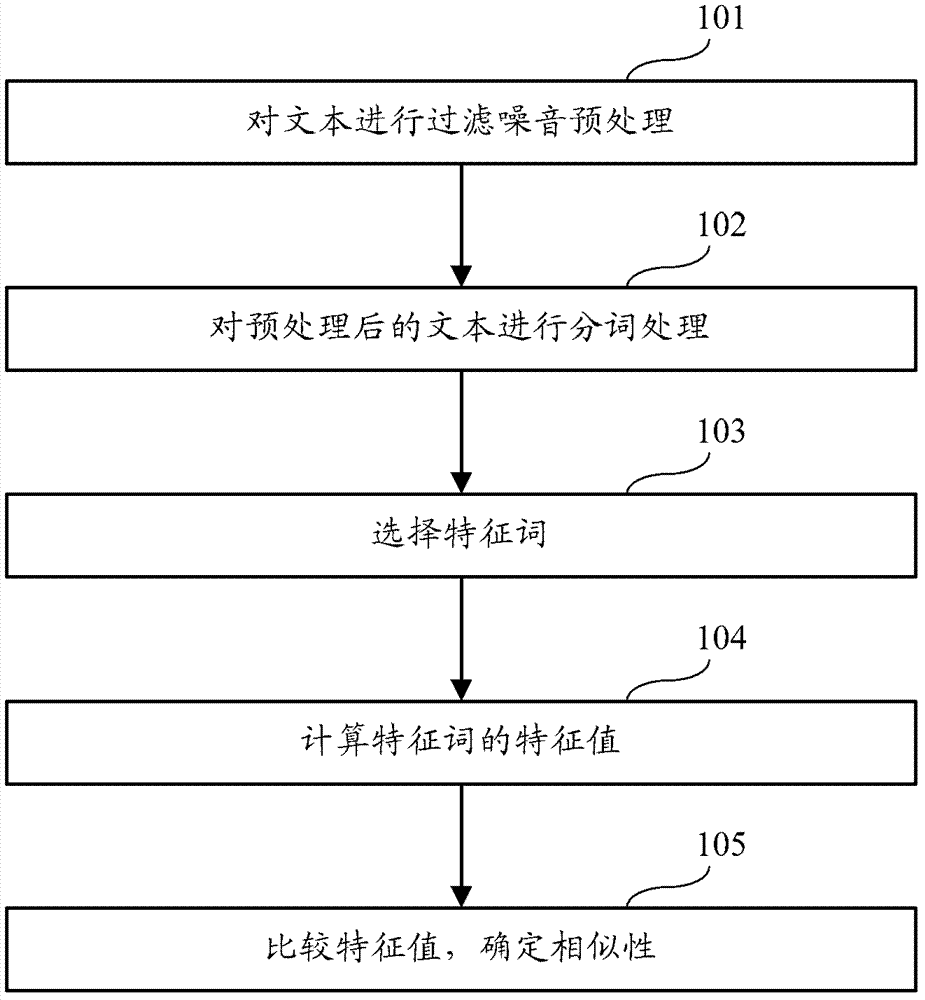
1.一种基于中文分词的文本相似性识别方法,其特征在于,该方法包括:对文本进行分词;根据分词的词性和出现的次数从所有分词中选择预设数量的分词作为特征词;对选择的特征词进行排序得到特征字符串,并计算所述排序得到的特征字符串的特征值;将所述特征值作为整个文本的特征值;所述排序包括:根据特征词的词性和出现的次数作为权重,对特征词进行加权排序,得到排序后的特征词字符串;通过比较文本的特征值,确定文本之间的相似性。2.如权利要求1所述的基于中文分词的文本相似性识别方法,其特征在于,所述对文本进行分词包括:按照大粒度或小粒度模式,结合词频词性选择特定的分词单元对文本以单词为单位进行划分,并标注每个单词的词性。3.如权利要求1所述的基于中文分词的文本相似性识别方法,其特征在于,对文本进行分词之前还包括:对文本中不能识别的字符以及无意义字符进行过滤。4.如权利要求1所述的基于中文分词的文本相似性识别方法,其特征在于,所述特征值为根据所述排序后的特征词字符串计算的MD5值。5.如权利要求1所述的基于中文分词的文本相似性识别方法,其特征在于,该方法进一步包括:预先选取样本文本并计算特征值;根据所述样本文本的特征值建立...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1