语音翻译系统的制作方法与工艺
语音翻译系统相关申请本申请是基于申请号201080043645.3、申请日2010年3月3日、发明名称“语音翻译系统、第一终端装置、语音识别服务器装置、翻译服务器装置以及语音合成服务器装置”的中国发明专利申请所做的分案申请。技术领域本发明涉及进行语音翻译的语音翻译系统等。
背景技术:
在现有的语音翻译系统中,存在着用于提高语音识别精度或者翻译处理精度等的提高各部分处理精度的技术(例如,参照专利文献1、专利文献2)。【专利文献1】:日本特开2008-243080号公报(第1页,图1等)【专利文献2】:日本特开2009-140503号公报(第1页,图1等)
技术实现要素:
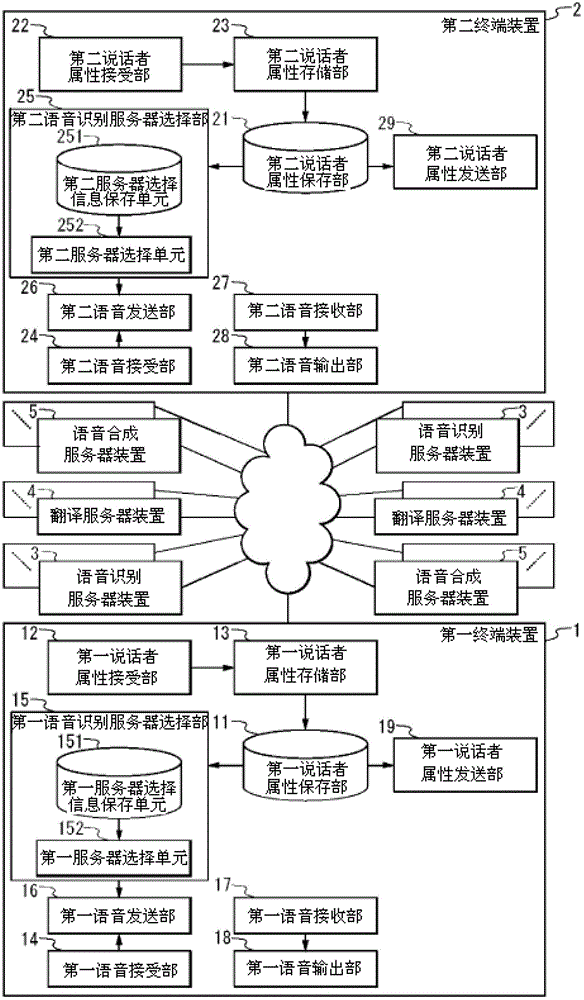
发明所要解决的技术问题但是,在现有的语音翻译系统中,在语音翻译过程中,不能根据说话者的属性来变更进行语音识别、翻译或语音合成的装置或模型,因此,在语音识别、翻译或语音合成的各处理中,精度降低、或者发生不恰当的输出。用于解决技术问题的方案本发明的第一方案的语音翻译系统,具有输入语音的第一终端装置、2个以上语音识别服务器装置、一个以上翻译服务器装置以及一个以上语音合成服务器装置,上述第一终端装置具备:第一说话者属性保存部,可保存一个以上的作为说话者的属性值的说话者属性;第一语音接受部,接受语音;第一语音识别服务器选择部,根据上述一个以上说话者属性,选择上述2个以上语音识别服务器装置中的一个语音识别服务器装置;以及第一语音发送部,向上述第一语音识别服务器选择部选择的语音识别服务器装置,发送由上述第一语音接受部所接受的语音构成的语音信息,上述语音识别服务器装置具备:语音识别模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存语音识别模型;语音信息接收部,接收上述语音信息;语音识别部,利用上述语音识别模型保存部的语音识别模型,对上述语音信息接收部所接收的语音信息进行语音识别,取得语音识别结果;以及语音识别结果发送部,发送上述语音识别结果,上述翻译服务器装置具备:翻译模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存翻译模型;语音识别结果接收部,接收上述语音识别结果;翻译部,利用上述翻译模型保存部的翻译模型,将上述语音识别结果接收部所接收的语音识别结果翻译成目标语言,并取得翻译结果;以及翻译结果发送部,发送上述翻译结果,上述语音合成服务器装置具备:语音合成模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存语音合成模型;翻译结果接收部,接收上述翻译结果;语音合成部,利用上述语音合成模型保存部的语音合成模型,对上述翻译结果接收部所接收的翻译结果进行语音合成,并取得语音合成结果;以及语音合成结果发送部,向第二终端装置发送上述语音合成结果。根据该结构,在语音翻译过程中,能够根据说话者的属性来变更进行语音识别的装置,在语音识别处理中,提高精度。此外,本发明的第二方案的语音翻译系统,具有输入语音的第一终端装置、一个以上语音识别服务器装置、一个以上翻译服务器装置以及一个以上语音合成服务器装置,上述第一终端装置具备:第一语音接受部,接受语音;以及第一语音发送部,向上述语音识别服务器装置发送由上述第一语音接受部接受的语音构成的语音信息,上述语音识别服务器装置具备:第三说话者属性保存部,能够保存一个以上作为说话者的属性值的说话者属性;语音识别模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存2个以上语音识别模型;语音信息接收部,接收上述语音信息;语音识别模型选择部,根据上述一个以上说话者属性,从上述2个以上语音识别模型中选择一个语音识别模型;语音识别部,利用上述语音识别模型选择部选择的语音识别模型,对上述语音信息接收部所接收的语音信息进行语音识别,取得语音识别结果;以及语音识别结果发送部,发送上述语音识别结果,上述翻译服务器装置具备:翻译模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存翻译模型;语音识别结果接收部,接收上述语音识别结果;翻译部,利用上述翻译模型保存部的翻译模型,将上述语音识别结果接收部所接收的语音识别结果翻译成目标语言,并取得翻译结果;以及翻译结果发送部,发送上述翻译结果,上述语音合成服务器装置具备:语音合成模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存语音合成模型;翻译结果接收部,接收上述翻译结果;语音合成部,利用上述语音合成模型保存部的语音合成模型,对上述翻译结果接收部所接收的翻译结果进行语音合成,并取得语音合成结果;以及语音合成结果发送部,向第二终端装置发送上述语音合成结果;上述说话者属性包含语速或说话者类别。根据该结构,在语音翻译过程中,能够根据说话者的属性来变更进行语音识别的模型,在语音识别处理中,提高精度。此外,本发明的第三方案的语音翻译系统,具有一个以上语音识别服务器装置、一个以上翻译服务器装置以及2个以上语音合成服务器装置,上述语音识别服务器装置具备:语音识别模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存语音识别模型;语音信息接收部,接收语音信息;语音识别部,利用上述语音识别模型保存部的语音识别模型,对上述语音信息接收部所接收的语音信息进行语音识别,并取得语音识别结果;以及语音识别结果发送部,向上述翻译服务器装置发送上述语音识别结果,上述翻译服务器装置具备:翻译模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存翻译模型;第四说话者属性保存部,可保存一个以上说话者属性;语音识别结果接收部,接收上述语音识别结果;翻译部,利用上述翻译模型保存部的翻译模型,将上述语音识别结果接收部所接收的语音识别结果翻译成目标语言,并取得翻译结果;语音合成服务器选择部,根据上述一个以上说话者属性,选择上述2个以上语音合成服务器装置中的一个语音合成服务器装置;以及翻译结果发送部,向上述语音合成服务器选择部选择的语音合成服务器装置发送上述翻译结果,上述语音合成服务器装置具备:语音合成模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存语音合成模型;翻译结果接收部,接收上述翻译结果;语音合成部,利用上述语音合成模型保存部的语音合成模型,对上述翻译结果接收部所接收的翻译结果进行语音合成,并取得语音合成结果;以及语音合成结果发送部,向第二终端装置发送上述语音合成结果。根据该结构,在语音翻译过程中,能够根据说话者的属性来变更进行语音合成的装置,在语音合成处理中,进行恰当的输出。此外,本发明的第四方案的语音翻译系统,具有一个以上语音识别服务器装置、一个以上翻译服务器装置以及一个以上语音合成服务器装置,上述语音识别服务器装置具备:语音识别模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存语音识别模型;语音信息接收部,接收语音信息;语音识别部,利用上述语音识别模型保存部的语音识别模型,对上述语音信息接收部所接收的语音信息进行语音识别,并取得语音识别结果;以及语音识别结果发送部,向上述翻译服务器装置发送上述语音识别结果,上述翻译服务器装置具备:翻译模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存翻译模型;语音识别结果接收部,接收上述语音识别结果;翻译部,利用上述翻译模型保存部的翻译模型,将上述语音识别结果接收部所接收的语音识别结果翻译成目标语言,并取得翻译结果;以及翻译结果发送部,向上述语音合成服务器装置发送上述翻译结果,上述语音合成服务器装置具备:语音合成模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存2个以上语音合成模型;第五说话者属性保存部,可保存一个以上说话者属性;翻译结果接收部,接收上述翻译结果;语音合成模型选择部,根据上述一个以上说话者属性,从上述2个以上语音合成模型中选择一个语音合成模型;语音合成部,利用上述语音合成模型选择部选择的语音合成模型,对上述翻译结果接收部所接收的翻译结果进行语音合成,并取得语音合成结果;以及语音合成结果发送部,向第二终端装置发送上述语音合成结果;上述说话者属性包含语速或说话者类别。根据该结构,在语音翻译过程中,能够根据说话者的属性来变更进行语音合成的模型,在语音合成处理中,进行恰当的输出。此外,本发明的第五方案的语音翻译系统是,在第一方案中,上述第一终端装置具备:第一说话者属性接受部,接受一个以上说话者属性;以及第一说话者属性存储部,在上述第一说话者属性保存部存储上述一个以上说话者属性。根据该结构,由于能够在说话者使用的终端中设定说话者属性,因此能够在语音识别、翻译或语音合成的各处理中利用说话者属性,在语音识别、翻译或语音合成的各处理中,提高精度,进行恰当的输出。此外,本发明的第六方案的语音翻译系统是,在第二方案中,上述语音识别服务器装置还具备:语音说话者属性取得部,根据上述语音信息接收部所接收的语音信息,取得关于语音的一个以上说话者属性;第三说话者属性存储部,将上述语音说话者属性取得部所取得的一个以上说话者属性,存储在第三说话者属性保存部。根据该结构,能够自动地取得与语音有关的说话者属性,所以在语音识别、翻译或语音合成的各处理中能够利用说话者属性,在语音识别、翻译或语音合成的各处理中,提高精度,进行恰当的输出。此外,本发明的第七方案的语音翻译系统是,在第三方案中,上述翻译服务器装置还具备:语言说话者属性取得部,根据上述语音识别结果接收部所接收的语音识别结果,取得关于语言的一个以上说话者属性;以及第四说话者属性存储部,将上述语言说话者属性取得部所取得的一个以上说话者属性,存储在上述第四说话者属性保存部。根据该结构,能够自动地取得与语言有关的说话者属性,因此,能够在语音识别、翻译或语音合成的各处理中利用说话者属性,在语音识别、翻译或语音合成的各处理中,提高精度,进行恰当的输出。此外,本发明的第八方案的语音翻译系统是,在第一方案中,语音翻译控制信息从上述语音识别服务器装置并经由上述一个以上翻译服务器装置被发送到上述语音合成服务器装置,其中,该语音翻译控制信息包含用于确定上述说话者使用的语言即原语言的原语言标识符、用于确定翻译目标语言即目标语言的目标语言标识符以及一个以上说话者属性;上述语音识别服务器选择部、上述语音识别部、语音识别模型选择部、上述翻译服务器选择部、上述翻译部、翻译模型选择部、上述语音合成服务器选择部、上述语音合成部或者语音合成模型选择部,利用上述语音翻译控制信息进行各自的处理。根据该结构,使包含说话者属性的语音翻译控制信息流通,在语音识别、翻译及语音合成中,进行假设了同一说话者的处理,在语音识别、翻译或语音合成的各处理中,提高精度,进行恰当的输出。此外,本发明的第九方案的第一终端装置,其具备:第一说话者属性保存部,可保存一个以上的作为说话者的属性值的说话者属性;第一语音接受部,接受语音;第一语音识别服务器选择部,根据上述一个以上说话者属性,选择上述2个以上语音识别服务器装置中的一个语音识别服务器装置;以及第一语音发送部,向上述第一语音识别服务器选择部选择的语音识别服务器装置,发送由上述第一语音接受部所接受的语音构成的语音信息。此外,本发明的第十方案的语音识别服务器装置,其具备:第三说话者属性保存部,能够保存一个以上作为说话者的属性值的包括语速或说话者类别的说话者属性;语音识别模型保存部,关于上述2个以上语言中的所有语言或2个以上的一部分语言,可保存2个以上语音识别模型;语音识别模型选择部,根据上述一个以上说话者属性,从上述2个以上语音识别模型中选择一个语音识别模型;以及语音识别部,利用上述语音识别模型选择部选择的语音识别模型,对语音信息进行语音识别,取得语音识别结果。此外,本发明的第十一方案的翻译服务器装置,其具备:翻译模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存翻译模型;第四说话者属性保存部,可保存一个以上说话者属性;翻译部,利用上述翻译模型保存部的翻译模型,将原语言的字符串翻译成目标语言,并取得翻译结果;语音合成服务器选择部,根据上述一个以上说话者属性,选择上述2个以上语音合成服务器装置中的一个语音合成服务器装置;以及翻译结果发送部,向上述语音合成服务器选择部选择的语音合成服务器装置发送上述翻译结果。此外,本发明的第十二方案的语音合成服务器装置,其具备:语音合成模型保存部,关于2个以上语言中的所有语言或2个以上的一部分语言,可保存2个以上语音合成模型;第五说话者属性保存部,可保存一个以上的作为说话者的属性值的包括语速或说话者类别的说话者属性;语音合成模型选择部,根据上述一个以上说话者属性,从上述2个以上语音合成模型中选择一个语音合成模型;以及语音合成部,利用上述语音合成模型选择部选择的语音合成模型,对输入字符串进行语音合成,并取得语音合成结果。发明效果根据本发明涉及的语音翻译系统,在语音翻译过程的语音识别、翻译或语音合成的各处理中,提高精度,进行恰当的输出。附图说明图1是实施方式1的语音翻译系统的概念图。图2是语音翻译系统的框图。图3是语音识别服务器装置的框图。图4是翻译服务器装置的框图。图5是语音合成服务器装置的框图。图6是用于说明该语音翻译系统的动作的流程图。图7是用于说明该语音识别服务器装置的动作的流程图。图8是用于说明说话者属性取得处理的动作的流程图。图9是用于说明该翻译服务器装置的动作的流程图。图10是用于说明该语音翻译系统的动作的流程图。图11是表示第一说话者属性管理表的图。图12是表示第二说话者属性管理表的图。图13是表示语音识别服务器选择信息管理表的图。图14是表示语音识别模型选择信息管理表的图。图15是表示翻译服务器选择信息管理表的图。图16是表示翻译模型选择信息管理表的图。图17是表示语音合成服务器选择信息管理表的图。图18是表示语音合成模型选择信息管理表的图。图19是表示第一终端装置的说话者属性等的输入画面的图。图20是表示语音翻译控制信息的示例的图。图21是表示更新后的语音翻译控制信息的示例的图。图22是表示更新后的语音翻译控制信息的示例的图。图23是表示更新后的语音翻译控制信息的示例的图。图24是表示更新后的语音翻译控制信息的示例的图。图25是其他语音翻译系统的概念图。图26是其他语音翻译系统的框图。图27是控制装置的框图。图28是语音识别服务器装置的框图。图29是翻译服务器装置的框图。图30是表示作为语音翻译控制信息的示例的STML例的图。图31是计算机系统的概念图。图32是计算机系统的框图。图33是语音翻译系统的其他框图。具体实施方式下面,参照附图说明语音翻译系统等的实施方式。在实施方式中赋予了相同标记的构成要素进行同样的动作,因此,有时省略重复说明。(实施方式1)在本实施方式中,说明如下的网络型语音翻译系统,即,在网络型语音翻译系统中,根据说话者属性来适当变更用于进行语音识别的服务器装置或语音识别模型,或者适当变更用于进行翻译的服务器装置或翻译模型,或者适当变更用于进行语音合成的服务器装置或语音合成模型,由此进行高精度的语音翻译。图1是本实施方式的语音翻译系统的概念图。语音翻译系统具备一个以上的第一终端装置1、一个以上的第二终端装置2、一个以上的语音识别服务器装置3、一个以上的翻译服务器装置4、以及一个以上的语音合成服务器装置5。在语音翻译系统中,例如,在作为第一终端装置1的用户(用户A)的日本人用日本语说出“おはようございます”时,语音识别服务器装置3对日本语“おはようございます”进行语音识别。然后,翻译服务器装置4将语音识别结果例如翻译成英语“Goodmorning”。接着,语音合成服务器装置5根据英文“Goodmorning”制作“Goodmorning”的语音信息。之后,从英语为母语的用户B的第二终端装置2输出语音“Goodmorning”。第一终端装置1及第二终端装置2例如是进行通话的终端(电话机,包括便携式电话)。在此,主要说明了第一终端装置1作为发话一侧的终端、第二终端装置2作为被发话一侧的终端,但是,两者当然可以互换。此外,通常是一边将第一终端装置1和第二终端装置2依次连续互换为发话一侧的终端和被发话一侧的终端、一边进行第一终端装置1的用户A和第二终端装置2的用户B的会话。此外,说明了第一终端装置1及第二终端装置2具有相同的功能(下述的构成要素),但是,当然也可以具有部分不相同的功能。此外,下面的说明中设第一终端装置1的用户(说话者)为用户A,第二终端装置2的用户(说话者)为用户B。图2是本实施方式的语音翻译系统的框图。此外,图3是语音识别服务器装置3的框图。图4是翻译服务器装置4的框图。图5是语音合成服务器装置5的框图。语音翻译系统具备一个以上的第一终端装置1、一个以上的第二终端装置2、一个以上的语音识别服务器装置3、一个以上的翻译服务器装置4和一个以上的语音合成服务器装置5。第一终端装置1具备第一说话者属性保存部11、第一说话者属性接受部12、第一说话者属性存储部13、第一语音接受部14、第一语音识别服务器选择部15、第一语音发送部16、第一语音接收部17、第一语音输出部18和第一说话者属性发送部19。第一语音识别服务器选择部15具备第一服务器选择信息保存单元151和第一服务器选择单元152。第二终端装置2具备第二说话者属性保存部21、第二说话者属性接受部22、第二说话者属性存储部23、第二语音接受部24、第二语音识别服务器选择部25、第二语音发送部26、第二语音接收部27、第二语音输出部28、以及第二说话者属性发送部29。第二语音识别服务器选择部25具备第二服务器选择信息保存单元251和第二服务器选择单元252。语音识别服务器装置3具备第三说话者属性保存部301、语音识别模型保存部302、第三说话者属性接收部303、语音说话者属性取得部304、第三说话者属性存储部305、语音信息接收部306、语音识别模型选择部307、语音识别部308、翻译服务器选择部309、语音识别结果发送部310、以及第三说话者属性发送部311。语音识别模型选择部307具备第三模型选择信息保存单元3071以及第三模型选择单元3072。此外,翻译服务器选择部309具备第三服务器选择信息保存单元3091以及第三服务器选择单元3092。翻译服务器装置4具备第四说话者属性保存部401、翻译模型保存部402、第四说话者属性接收部403、语言说话者属性取得部404、第四说话者属性存储部405、语音识别结果接收部406、翻译模型选择部407、翻译部408、语音合成服务器选择部409、翻译结果发送部410、以及第四说话者属性发送部411。翻译模型选择部407具备第四模型选择信息保存单元4071、第四模型选择单元4072。语音合成服务器选择部409具备第四服务器选择信息保存单元4091、第四服务器选择单元4092。语音合成服务器装置5具备第五说话者属性保存部501、语音合成模型保存部502、第五说话者属性接收部503、第五说话者属性存储部504、翻译结果接收部505、语音合成模型选择部506、语音合成部507、语音合成结果发送部508。语音合成模型选择部506具备第五模型选择信息保存单元5061和第五模型选择单元5062。下面,对各构成要素的功能、实现手段等进行说明。其中,第一终端装置1的构成要素的功能和对应的第二终端装置2的构成要素的功能相同(例如,第一说话者属性接受部12和第二说话者属性接受部22的功能相同),因此,只对第一终端装置1的构成要素进行说明。构成第一终端装置1的第一说话者属性保存部11,能够保存一个以上的说话者属性。所谓说话者属性是说话者的属性值。所谓说话者属性,例如是说话者的性别、年龄、语速、说话者类别(有关说话者所使用的语言,考虑了所使用单词的难易度、语法的正确度等的熟练度)等。说话者类别是表示所使用单词的困难程度的信息、表示所使用的用语的谦逊程度的信息、表示语法的正确程度的信息、以及表示这些信息的综合程度的信息、表示是否为母语的信息等。此外,在说话者属性中,还可以包含说话者的感情(高兴、悲伤等)等。此外,毋庸置疑,不考虑说话者属性的内容。此外,若能够确定说话者,在说话者属性中就会包含作为暂时没有变化的属性的静态说话者属性信息和作为实时可变化的属性的动态说话者属性信息。在静态说话者属性信息中,例如包含上述的说话者的性别、年龄、说话者类别等。此外,在动态说话者属性信息中,包含语速或感情等。保存在第一说话者属性保存部11的说话者属性,通常是第一终端装置1的用户输入的信息。此外,保存在第一说话者属性保存部11的说话者属性,通常是静态说话者属性信息。第一说话者属性保存部11也可以保存包含一个以上说话者属性的语音翻译控制信息。这种情况下,第一说话者属性保存部11也可以称作第一语音翻译控制信息保存部11。第一说话者属性接受部12从第一终端装置1的用户接受一个以上的说话者属性。在此,所谓接受是包含如下接受方式的概念,即从键盘、鼠标、触摸面板等输入设备输入的信息接受,通过有线或无线的通信线路发送的信息的接收,从光盘或磁盘、半导体存储器等存储介质读取的信息的接受等。说话者属性的输入机构可以是十个数字键、键盘、鼠标或者利用菜单画面的机构等,可以是任意一种。第一说话者属性存储部13将由第一说话者属性接受部12接受的一个以上说话者属性存储到第一说话者属性保存部11。第一语音接受部14从第一终端装置1的用户(称作用户A)接受语音。第一语音识别服务器选择部15根据一个以上说话者属性,选择2个以上语音识别服务器装置3中的一个语音识别服务器装置3。例如,第一语音识别服务器选择部15使用语音识别服务器选择信息管理表进行选择。第一语音识别服务器选择部15也可以位于未图示的服务器装置(后述的控制装置256)。在这种情况下,第一语音发送部16也可以存在于未图示的服务器装置中。在此,所谓语音识别服务器装置3的选择,例如是取得用于与一个语音识别服务器装置3进行通信的信息(例如一个语音识别服务器装置3的IP地址)等的处理。此外,第一语音识别服务器选择部15优选使用包含一个以上说话者属性的语音翻译控制信息,来选择2个以上语音识别服务器装置3中的一个语音识别服务器装置3。所谓语音翻译控制信息,具有用于语音识别服务器装置3、翻译服务器装置4及语音合成服务器装置5分别进行语音识别、翻译及语音合成或者发送处理结果的信息。语音翻译控制信息,例如具有用于确定发送处理结果的目的地的信息(IP地址或电话号码等)、用于确定原语言或目标语言的信息(日本语、英语、德语等)等。第一终端装置1(第二终端装置2也同样)的未图示的接受部(也可以是第一说话者属性接受部12),例如从用户接受原语言和目标语言。此外,第一语音识别服务器选择部15例如根据第二终端装置2的电话号码或IP地址等,自动地确定原语言和目标语言。在这种情况下,第一语音识别服务器选择部15把电话号码或IP地址等的信息和用于确定语言的信息对应起来保持,或者,以电话号码或IP地址等信息作为关键字,从其他装置取得用于确定语言的信息。此外,第一语音识别服务器选择部15取得用于对应该从原语言或目标语言进行语音识别的语音识别服务器装置3进行确定的信息(IP地址等)、用于确定翻译服务器装置4的信息(IP地址等)、用于确定语音合成服务器装置5的信息(IP地址等)。即,第一语音识别服务器选择部15将原语言或目标语言和用于确定各服务器装置的信息对应起来保持,或者利用原语言或目标语言从其他装置取得用于确定各服务器装置的信息。此外,语音翻译控制信息通常具有一个以上说话者属性,并且,还可以具有表示输入语音的格式的信息、表示输出语音的格式的信息、用于指定输入输出语音的音质的信息、表示输入文本的格式的信息、以及表示输出文本的格式的信息等。第一服务器选择信息保存单元151保存着具有2个以上语音识别服务器选择信息的语音识别服务器选择信息管理表,该语音识别服务器选择信息把用于识别语音识别服务器装置3的语音识别服务器标识符和一个以上说话者属性对应起来保持。语音识别服务器标识符例如是用于与语音识别服务器装置3进行通信的信息(例如,一个语音识别服务器装置3的IP地址)、第一服务器选择单元152从第一服务器选择信息保存单元151中检索与被保存在第一说话者属性保存部11的一个以上说话者属性对应的语音识别服务器标识符。第一语音发送部16发送由第一语音接受部14接受的语音构成的语音信息。语音的发送目的地是一个以上语音识别服务器装置3中的某一个。第一语音发送部16优选向第一语音识别服务器选择部15所选择的语音识别服务器装置3发送由第一语音接受部14接受的语音构成的语音信息。此外,第一语音发送部16也可以向2个以上语音识别服务器装置3发送语音信息。另外,在此优选语音信息是由语音构成的数字信息。再者,第一语音发送部16也可以直接向一个以上语音识别服务器装置3发送语音,也可以经由其他装置(间接地)向一个以上语音识别服务器装置3发送语音。第一语音接收部17接收作为将由第二终端装置2的用户B发出的语音所构成的语音信息进行语音翻译的结果的语音信息。该语音信息通常是翻译成第一终端装置1的用户A能够理解的语言的语音信息。该语音信息通常是从第二终端装置2经由语音识别服务器装置3、翻译服务器装置4及语音合成服务器装置5发送来的信息。第一语音输出部18输出由第一语音接收部17接收的语音信息。在此,所谓输出通常是向扬声器的语音输出。第一说话者属性发送部19向第一语音识别服务器选择部15所选择的语音识别服务器装置3,发送被保存在第一说话者属性保存部11的一个以上说话者属性。第一说话者属性发送部19也可以向第一语音识别服务器选择部15所选择的语音识别服务器装置3,发送包含一个以上说话者属性的语音翻译控制信息。在这种情况下,第一说话者属性发送部19也可以改称为第一语音翻译控制信息发送部19。构成语音识别服务器装置3的第三说话者属性保存部301能够保存一个以上作为说话者的属性值的说话者属性。此处的说话者属性可以是在语音识别服务器装置3取得的说话者属性,也可以是从第一终端装置1或第二终端装置2发送的说话者属性,也可以包含在语音识别服务器装置3取得的说话者属性以及从第一终端装置1或第二终端装置2发送的说话者属性的双方。此外,第三说话者属性保存部301也可以保存包含一个以上说话者属性的语音翻译控制信息。第三说话者属性保存部301也可以称作第三语音翻译控制信息保存部301。语音识别模型保存部302能够保存有关2个以上的语言中的所有语言或2个以上的一部分语言的语音识别模型。语音识别模型保存部302也可以保存2个以上语音识别模型。所谓语音识别模型,例如是隐马尔可夫模型(HMM)的音频模型。其中,语音识别模型不一定为HMM的音频模型。语音识别模型也可以是单一高斯分布模型、概率模型(GMM:高斯混合模型)或统计模型等基于其它模型的音频模型。第三说话者属性接收部303间接或直接从第一终端装置1接收一个以上说话者属性。第三说话者属性接收部303也可以从第一终端装置1接收语音翻译控制信息。在这种情况下,第三说话者属性接收部303也可以称作第三语音翻译控制信息接收部303。语音说话者属性取得部304从由语音信息接收部306接收的语音信息中取得一个以上语音说话者属性。所谓语音说话者属性是有关语音的说话者属性,是能够从语音取得的说话者属性。语音说话者属性取得部304优选取得动态说话者属性信息。此外,语音说话者属性取得部304也可以取得静态说话者属性信息。此外,语音说话者属性取得部304例如对语音信息进行频谱分析,并取得一个以上特征量。此外,语音说话者属性取得部304从一个以上特征量中确定说话者的年龄、性别、语速、感情等说话者属性。语音说话者属性取得部304例如保持用于确定男性或/及女性的特征量的信息(以特征量作为参数的条件),根据所取得的一个以上特征量确定说话者是男性还是女性,取得性别信息(例如,男性为“0”、女性为“1”)。此外,语音说话者属性取得部304例如保持着用于确定特定年龄、或特定年龄层(例如,10多岁,20多岁等)的特征量的信息,并根据所取得的一个以上特征量确定说话者的年龄或年龄层,取得年龄或年龄层的信息(例如,小于9岁为“0”,10多岁为“1”等)。此外,语音说话者属性取得部304解析语音信息,并取得语速(例如,4.5音/秒)。用于取得语速的技术是公知技术,因此省略详细说明。此外,语音说话者属性取得部304例如也可以根据所取得的一个以上特征量取得感情(动态说话者属性信息的一种)。更具体来说,语音说话者属性取得部304例如保持着感情为“普通”时的音调和功率值。并且,语音说话者属性取得部304根据所提取的有声部分的音调和功率值求得平均值、最大值、最小值。此外,语音说话者属性取得部304使用感情为“普通”时的音调和功率值、所提取的有声部分的音调和功率的平均值、最大值、最小值,在平均音调较低、平均功率较高时,取得感情为“怒”。此外,在与感情为“普通”时的音调和功率值相比,最小音调较高、最大功率较低时,语音说话者属性取得部304取得感情为“悲伤”。此外,在与感情为“普通”时的音调和功率值相比,特征量较大时,语音说话者属性取得部304取得感情为“喜”。语音说话者属性取得部304优选使用所取得的一个以上特征量中的功率和韵律来取得感情。关于取得感情的方法,请参照URL“http://www.kansei.soft.iwate-pu.ac.jp/abstract/2007/0312004126.pdf”的论文。此外,不限定语音说话者属性取得部304取得语速等属性的语音信息的单位。即,语音说话者属性取得部304也可以按句子单位取得语速等属性,也可以按单词单位取得语速等属性,也可以按识别结果的单位取得语速等属性,也可以按多个句子单位取得语速等属性。此外,语音说话者属性取得部304也可以根据语音识别部308进行了语音识别的结果、即语音识别结果,确定说话者类别(该说话者类别是语言说话者属性的一种)。例如,语音说话者属性取得部304保持具有难理解度的用语词典(将用语和难理解度对应起来具有的2个以上用语信息的集合),并取得包含在语音识别结果中的一个以上用语的难理解度(n1、n2、···),并根据该一个以上难理解度确定说话者类别(难理解度高为“0”,难理解度中为“1”,难理解度低为“2”等)。此外,语音说话者属性取得部304使用一个以上用语的难理解度(n1、n2、···)及语法错误的有无来确定说话者类别。例如,在存在语法错误的情况下,语音说话者属性取得部304取得在由一个以上难理解度取得的最終难理解度(高为“0”,难理解度中为“1”,难理解度低为“2”)上加了“1”的值,作为说话者类别。此外,关于在句子中是否存在语法错误的检查处理是公知的自然语言处理,所以省略详细说明。此外,语音说话者属性取得部304也可以通过上述方法以外的方法取得说话者属性,也可以取得任意说话者属性。此外,有关语音说话者属性取得部304的技术,例如公开在“基于用于不特定说话者的语音自动识别的性别、年龄差的说话者分类的考察”(中川圣一及其他作者,日本电子通信学会论文志)中(参照http://www.slp.ics.tut.ac.jp/shiryou/number-1/J1980-06.pdf)。此外,语音说话者属性取得部304也可以利用机械学习,确定性别或年龄等说话者属性。即,语音说话者属性取得部304也可以保存多组具有性别(男性或女性)和一个以上特征量的信息组,对于根据语音信息接收部306所接收的语音信息得到的一个以上特征量,并利用SVM或决定树等机械学习的算法,来确定与语音信息接收部306所接收的语音信息相对应的说话者的性别。第三说话者属性存储部305将由语音说话者属性取得部304取得的一个以上说话者属性存储到第三说话者属性保存部301中。此外,此处的存储也可以是暂时性的存储。语音信息接收部306从第一终端装置1直接或间接地接收语音信息。语音识别模型选择部307根据一个以上说话者属性,从2个以上语音识别模型中选择一个语音识别模型。第三模型选择信息保存单元3071保存语音识别模型选择信息管理表。语音识别模型选择信息管理表是包含一个以上记录的表,该记录中具有关于一个以上说话者属性的条件(也可以是一个以上说话者属性)和用于识别语音识别模型的语音识别模型标识符。第三模型选择单元3072根据保存在第三说话者属性保存部301的一个以上说话者属性,检索语音识别模型选择信息管理表,并取得与一个以上说话者属性对应的语音识别模型标识符。此外,语音识别部308从语音识别模型保存部302读取利用由第三模型选择单元3072取得的语音识别模型标识符来识别的语音识别模型,并利用该语音识别模型进行语音识别处理。语音识别部308利用语音识别模型保存部302的语音识别模型,对语音信息接收部306所接收的语音信息进行语音识别,并取得语音识别结果。此外,语音识别部308优选利用语音识别模型选择部307所选择的语音识别模型,对语音信息接收部306所接收的语音信息进行语音识别,并取得语音识别结果。语音识别部308也可以是任意的语音识别方法。语音识别部308是公知技术。此外,语音识别的对象语言(原语言)的信息,例如包含在语音翻译控制信息中。例如,语音翻译控制信息在第一终端装置、语音识别服务器装置、翻译服务器装置、语音合成服务器装置及第二终端装置2之间被传送。语音识别结果通常是原语言(第一终端装置1的用户A发出的语音的语言)的字符串。翻译服务器选择部309根据一个以上说话者属性,选择2个以上翻译服务器装置4中的一个翻译服务器装置4。此外,翻译服务器选择部309也可以是未图示的服务器装置。在这种情况下,通常语音识别结果发送部310也位于未图示的服务器装置中。此外,在这种情况下,也可以从未图示的服务器装置发送应选择的翻译服务器装置4的信息。第三服务器选择信息保存单元3091保存着翻译服务器选择信息管理表。翻译服务器选择信息管理表是包含一个以上记录的表,该记录中具有关于一个以上说话者属性的条件(也可以是一个以上说话者属性)和用于识别翻译服务器装置4的翻译服务器装置标识符。第三服务器选择单元3092根据被保存在第三说话者属性保存部301的一个以上说话者属性,检索翻译服务器选择信息管理表,并取得与一个以上说话者属性对应的翻译服务器装置标识符。此外,语音识别结果发送部310向与第三服务器选择单元3092所取得的翻译服务器装置标识符对应的翻译服务器装置4,发送语音识别结果。语音识别结果发送部310向翻译服务器装置4直接或间接地发送语音识别结果。语音识别结果发送部310优选直接或间接地向翻译服务器选择部309所选择的一个翻译服务器装置4,发送语音识别结果。第三说话者属性发送部311直接或间接地向翻译服务器装置4发送被保存在第三说话者属性保存部301的一个以上说话者属性。第三说话者属性发送部311也可以向翻译服务器装置4发送语音翻译控制信息。在这种情况下,第三说话者属性发送部311也可以称作第三语音翻译控制信息发送部311。构成翻译服务器装置4的第四说话者属性保存部401能够保存一个以上说话者属性。第四说话者属性保存部401也可以保存语音翻译控制信息。在这种情况下,第四说话者属性保存部401也可以称作第四语音翻译控制信息保存部401。翻译模型保存部402能够保存有关2个以上语言中的所有语言、或2个以上的一部分语言的翻译用信息。翻译模型保存部402也可以保存2个以上翻译用信息。翻译用信息例如是翻译模型和语言模型。此外,翻译模型保存部402也可以不具有语言模型,而只保存一个以上翻译模型。在这种情况下,翻译模型保存部402能够保存一个以上翻译模型。此外,后述的翻译模型的选择与翻译用信息的选择是相同的意思。第四说话者属性接收部403直接或间接地从语音识别服务器装置3接收一个以上说话者属性。第四说话者属性接收部403也可以从语音识别服务器装置3接收语音翻译控制信息。在这种情况下,第四说话者属性接收部403也可以称作第四语音翻译控制信息接收部403。语言说话者属性取得部404根据语音识别结果接收部406所接收的语音识别结果,取得一个以上语言说话者属性。所谓语言说话者属性是能够通过语言处理而取得的说话者属性。语言说话者属性取得部404例如通过对语音识别结果进行自然语言处理,来确定说话者类别。所谓说话者类别,例如是根据考虑了所使用单词的难度、语法的正确度等的语言熟练度对说话者进行分类的信息。语言说话者属性取得部404例如根据在语音识别结果中使用难理解用语的频度或比例,确定说话者类别。此外,语言说话者属性取得部404例如根据在语音识别结果中是否使用了敬语、使用了敬语的频度或比例,确定说话者类别。此外,语言说话者属性取得部404例如根据在语音识别结果中是否使用了女高中生常用的新单词、使用了新单词的频度或比例,确定说话者类别。语言说话者属性取得部404例如保存有构成难理解的用语或敬语的形态素或女高中生常用的新单词等,对语音识别结果进行形态素解析,并取得构成难理解的用语或敬语的形态素或女高中生常用的新单词等存在的频度或比例,并利用预先决定的条件(等级A:难理解的用语为10%以上,B:难理解的用语为1%以上且小于10%,C:难理解的用语小于1%,等等),确定说话者类别(等级)。语言说话者属性取得部404也可以利用其他算法对语音识别结果进行自然语言处理,并取得一个以上语言说话者属性。此外,语言说话者属性取得部404也可以通过与语音说话者属性取得部304中的语言说话者属性的取得方法同样的方法,取得一个以上语言说话者属性。第四说话者属性存储部405在第四说话者属性保存部401至少暂时存储第四说话者属性接收部403所接收的一个以上说话者属性。第四说话者属性存储部405也可以在第四说话者属性保存部401存储语音翻译控制信息。在这种情况下,第四说话者属性存储部405也可以称作第四语音翻译控制信息存储部405。语音识别结果接收部406直接或间接地从语音识别服务器装置3接收语音识别结果。翻译模型选择部407根据第四说话者属性接收部403所接收的一个以上说话者属性,从2个以上翻译模型中选择一个翻译模型。第四模型选择信息保存单元4071保存着翻译模型选择信息管理表。翻译模型选择信息管理表是包含一个以上记录的表,该记录中具有关于一个以上说话者属性的条件(也可以是一个以上说话者属性)和用于识别翻译模型的翻译模型标识符。第四模型选择单元4072根据被保存在第四说话者属性保存部401的一个以上说话者属性,检索翻译模型选择信息管理表,并取得与一个以上说话者属性对应的翻译模型标识符。此外,翻译部408从翻译模型保存部402取得与由第四模型选择单元4072取得的翻译模型标识符对应的翻译模型,并利用该翻译模型进行翻译处理。翻译部408利用翻译模型保存部402的翻译模型,将语音识别结果接收部406所接收的语音识别结果翻译成目标语言,并取得翻译结果。翻译部408优选利用翻译模型选择部407选择的翻译模型,把语音识别结果接收部406所接收的语音识别结果翻译成目标语言,并取得翻译结果。此外,用于确定原语言和目标语言的信息,例如包含在语音翻译控制信息中。此外,不限定翻译部408中的翻译方法。翻译部408是公知技术。语音合成服务器选择部409根据一个以上说话者属性,选择2个以上语音合成服务器装置5中的一个语音合成服务器装置5。第四服务器选择信息保存单元4091保存着语音合成服务器选择信息管理表。语音合成服务器选择信息管理表是包含一个以上记录的表,该记录中具有关于一个以上说话者属性的条件(也可以是一个以上说话者属性)和用于识别语音合成服务器装置5的语音合成装置标识符。第四服务器选择单元4092根据被保存在第四说话者属性保存部401的一个以上说话者属性,检索语音合成服务器选择信息管理表,并取得与一个以上说话者属性对应的语音合成服务器装置标识符。此外,翻译结果发送部410向与第四服务器选择单元4092所取得的语音合成服务器装置标识符对应的语音合成服务器装置5,发送翻译结果。翻译结果发送部410直接或间接地向语音合成服务器装置5发送由翻译部408进行了翻译处理的结果、即翻译结果。此外,翻译结果发送部410优选直接或间接地向语音合成服务器选择部409所选择的语音合成服务器装置5发送翻译结果。第四说话者属性发送部411直接或间接地向语音合成服务器装置5发送由第四说话者属性接收部403接收的一个以上说话者属性。第四说话者属性发送部411也可以向语音合成服务器装置5发送语音翻译控制信息。在这种情况下,第四说话者属性发送部411也可以称作第四语音翻译控制信息发送部411。构成语音合成服务器装置5的第五说话者属性保存部501,能够保存一个以上说话者属性。第五说话者属性保存部501也可以保存语音翻译控制信息。在这种情况下,第五说话者属性保存部501也可以称作第五语音翻译控制信息保存部501。语音合成模型保存部502能够保存有关2个以上语言中的所有语言或2个以上的一部分语言的语音合成模型。语音合成模型保存部502也可以保存2个以上语音合成模型。第五说话者属性接收部503直接或间接地从语音识别服务器装置3接收一个以上说话者属性。第五说话者属性接收部503也可以从语音识别服务器装置3接收语音翻译控制信息。在这种情况下,第五说话者属性接收部503也可以称作第五语音翻译控制信息接收部503。第五说话者属性存储部504在第五说话者属性保存部501中至少暂时存储第五说话者属性接收部503所接收的一个以上说话者属性。第五说话者属性存储部504也可以在第五说话者属性保存部501存储语音翻译控制信息。在这种情况下,第五说话者属性存储部504也可以称作第五语音翻译控制信息存储部504。翻译结果接收部505直接或间接地从翻译服务器装置4接收翻译结果。语音合成模型选择部506根据第五说话者属性接收部503所接收的一个以上说话者属性,从2个以上语音合成模型中选择一个语音合成模型。第五模型选择信息保存单元5061保存着语音合成模型选择信息管理表。语音合成模型选择信息管理表是包含一个以上记录的表,该记录中具有关于一个以上说话者属性的条件(也可以是一个以上说话者属性)和用于识别语音合成模型的语音合成模型标识符。第五模型选择单元5062根据被保存在第五说话者属性保存部501中的一个以上说话者属性,检索语音合成模型选择信息管理表,并取得与一个以上说话者属性对应的语音合成模型标识符。此外,语音合成部507从语音合成模型保存部502取得与第五模型选择单元5062所取得的语音合成模型标识符对应的语音合成模型,并利用该语音合成模型进行语音合成处理。语音合成部507利用语音合成模型保存部502的语音合成模型,对翻译结果接收部505所接收的翻译结果进行语音合成,并取得语音合成结果。语音合成部507优选利用语音合成模型选择部506选择的语音合成模型,对翻译结果接收部505所接收的翻译结果进行语音合成,并取得语音合成结果。在此,用于确定进行语音合成的目标语言的的信息,例如包含在语音翻译控制信息中。语音合成结果发送部508直接或间接地将语音合成部507所取得的语音合成结果,向第二终端装置2发送。第一说话者属性保存部11、第一服务器选择信息保存单元151、第二说话者属性保存部21、第二服务器选择信息保存单元251、第三说话者属性保存部301、语音识别模型保存部302、第三模型选择信息保存单元3071、第三服务器选择信息保存单元3091、第四说话者属性保存部401、翻译模型保存部402、第四模型选择信息保存单元4071、第四服务器选择信息保存单元4091、第五说话者属性保存部501、语音合成模型保存部502及第五模型选择信息保存单元5061优选使用非易失性存储介质,但是也可以用易失性存储介质实现。不限定在第一说话者属性保存部11等存储上述信息的过程。例如,可以通过存储介质,在第一说话者属性保存部11等存储上述信息,也可以将经由通信线路等发送的上述信息存储在第一说话者属性保存部11等,或者,也可以将借助输入设备输入的上述信息存储到第一说话者属性保存部11等。第一说话者属性接受部12及第二说话者属性接受部22可以通过十个数字键或键盘等输入机构的设备驱动器、或者菜单画面的控制软件等实现。第一语音接受部14及第二语音接受部24例如可以通过鼠标和其设备驱动器等实现。第一语音发送部16、第一语音接收部17、第一说话者属性发送部19、第二语音发送部26、第二语音接收部27、第二说话者属性发送部29、第三说话者属性接收部303、语音信息接收部306、语音识别结果发送部310、第三说话者属性发送部311、第四说话者属性接收部403、语音识别结果接收部406、翻译结果发送部410、第四说话者属性发送部411、第五说话者属性接收部503、翻译结果接收部505及语音合成结果发送部508,通常由无线或有线的通信机构实现,但是也可以由广播机构或广播接收机构实现。第一语音输出部18及第二语音输出部28可以由扬声器及其驱动软件等实现。第一说话者属性存储部13、第一语音识别服务器选择部15、第一服务器选择信息保存单元151、第二说话者属性存储部23、第二语音识别服务器选择部25、第二服务器选择单元252、语音说话者属性取得部304、第三说话者属性存储部305、语音识别模型选择部307、语音识别部308、翻译服务器选择部309、第三模型选择单元3072、第三服务器选择单元3092、语言说话者属性取得部404、第四说话者属性存储部405、翻译模型选择部407、翻译部408、语音合成服务器选择部409、第四模型选择单元4072、第四服务器选择单元4092、第五说话者属性存储部504、语音合成模型选择部506、语音合成部507及第五模型选择单元5062,通常可以由MPU或存储器等实现。第一说话者属性存储部13等的处理步骤通常由软件实现,该软件存储在ROM等存储介质中。但是,也可以由硬件(专用电路)来实现。接着,利用图6~图10的流程图说明语音翻译系统的动作。首先,利用图6的流程图,对第一终端装置1的动作进行说明。(步骤S601)第一说话者属性接受部12等接受部判断是否接受了来自用户A的输入。若接受了输入,则进入步骤S602,若未接受输入,则进入步骤S606。(步骤S602)第一说话者属性接受部12判断在步骤S601接受的输入是不是说话者属性。若是说话者属性,则进入步骤S603,若不是说话者属性,则进入步骤S604。(步骤S603)第一说话者属性存储部13将所接受的一个以上说话者属性存储到第一说话者属性保存部11。返回步骤S601。(步骤S604)未图示的接受部判断在步骤S601接受的输入是不是呼叫请求。若是呼叫请求,则进入步骤S605,若不是呼叫请求,则返回步骤S601。此外,呼叫请求是对第二终端装置2的用户B的通话委托,通常包含第二终端装置2的第二终端装置标识符(电话号码等)。(步骤S605)未图示的呼叫部呼叫第二终端装置2。并且,呼叫的结果,开始通话。返回步骤S601。(步骤S606)第一语音接受部14判断是否接受了用户A的语音。若接受了语音,则进入步骤S607,若未接受语音,则返回步骤S601。(步骤S607)第一服务器选择单元152从第一说话者属性保存部11读取一个以上说话者属性。(步骤S608)第一服务器选择单元152把在步骤S607读取的一个以上说话者属性应用于第一服务器选择信息保存单元151的第一服务器选择信息(语音识别服务器选择信息管理表),选择语音识别服务器装置3。在此,所谓语音识别服务器装置3的选择,例如是取得一个语音识别服务器装置标识符。(步骤S609)第一说话者属性发送部19利用被保存在第一说话者属性保存部11的一个以上说话者属性,构成语音翻译控制信息。第一说话者属性发送部19例如取得根据输入的第二终端装置2的电话号码确定的目标语言的标识符。此外,第一说话者属性发送部19取得根据被保存的第一终端装置1的电话号码确定的原语言的标识符。例如,电话号码包含国别代码,因此,第一说话者属性发送部19根据上述国家代码确定目标语言。第一说话者属性发送部19保持着国家代码和目标语言标识符的对应表(例如,具有“81:日本语”、“82:韩国语”等记录的表)。然后,第一说话者属性发送部19利用被保存在第一说话者属性保存部11的一个以上说话者属性、原语言的标识符和目标语言的标识符等,构成语音翻译控制信息。(步骤S610)第一语音发送部16将在步骤S606接受的语音进行数字化,取得语音信息。然后,第一语音发送部16把该语音信息发送到在步骤S608选择的语音识别服务器装置3。(步骤S611)第一说话者属性发送部19把在步骤S609构成的语音翻译控制信息发送到在步骤S608选择的语音识别服务器装置3。此外,在此,第一说话者属性发送部19也可以只把一个以上说话者属性发送到在步骤S608选择的语音识别服务器装置3。返回步骤S601。此外,在图6的流程图中,优选在通话过程中不再执行步骤S607、步骤S608、步骤S609及步骤S611的处理。即,在一次通话中,优选执行步骤S607、步骤S608、步骤S609及步骤S611的处理的次数为一次或比语音信息的发送少的次数。再者,在图6的流程图中,通过电源关断或处理结束的中断,使处理结束。此外,第二终端装置2的动作与第一终端装置1的动作相同,因此省略说明。接着,利用图7的流程图,对语音识别服务器装置3的动作进行说明。(步骤S701)语音信息接收部306判断是否接收了语音信息。若接收了语音信息,则进入步骤S702,若没有接收语音信息,则返回步骤S701。(步骤S702)第三说话者属性接收部303判断是否接收了语音翻译控制信息。若接收了语音翻译控制信息,则进入步骤S703,若没有接收,则进入步骤S710。(步骤S703)语音说话者属性取得部304从在步骤S701接收的语音信息中,取得一个以上说话者属性。将上述处理称为说话者属性取得处理,利用图8的流程图进行说明。(步骤S704)第三说话者属性存储部305在由步骤S702接收的语音翻译控制信息中追加由步骤S703取得的一个以上说话者属性,构成新的语音翻译控制信息,并将该语音翻译控制信息至少暂时存储到第三说话者属性保存部301。此外,第三说话者属性存储部305没必要将在步骤S703取得的所有说话者属性追加到由步骤S702接收的语音翻译控制信息中。此外,也可以是,第三说话者属性存储部305以在步骤S703取得的所有说话者属性为优先,修改在步骤S702接收的语音翻译控制信息的一部分说话者属性。使在步骤S703取得的所有说话者属性优先时,具有例如对带女性生音的男性的语音也容易进行语音识别等优点。(步骤S705)第三模型选择单元3072利用被保存在第三说话者属性保存部301的语音翻译控制信息所具有的一个以上说话者属性,检索语音识别模型选择信息管理表,取得语音识别模型标识符。即,第三模型选择单元3072选择语音识别模型。此外,第三模型选择单元3072从语音识别模型保存部302读取所选择的语音识别模型。(步骤S706)语音识别部308利用所读取的语音识别模型,对在步骤S701接收的语音信息进行语音识别处理。然后,语音识别部308得到语音识别结果。(步骤S707)第三服务器选择单元3092利用被保存在第三说话者属性保存部301中的语音翻译控制信息所具有的一个以上说话者属性,检索翻译服务器选择信息管理表,取得与一个以上说话者属性对应的翻译服务器装置标识符。(步骤S708)语音识别结果发送部310向与在步骤S707取得的翻译服务器装置标识符对应的翻译服务器装置4,发送在步骤S706得到的语音识别结果。(步骤S709)第三说话者属性发送部311向与在步骤S707取得的翻译服务器装置标识符对应的翻译服务器装置4,发送被保存在第三说话者属性保存部301的语音翻译控制信息,并返回步骤S701。(步骤S710)第三模型选择单元3072判断在第三说话者属性保存部301是否保存有语音翻译控制信息。若保存有语音翻译控制信息,则进入步骤S711,若没保存,则进入步骤S712。(步骤S711)第三模型选择单元3072读取被保存在第三说话者属性保存部301的语音翻译控制信息,并进入步骤S705。(步骤S712)第三模型选择单元3072读取被保存在语音识别模型保存部302的任意的语音识别模型,并进入步骤S706。此外,在图7的流程图中,在说话者属性取得处理中进行了语音识别的情况下,也可以不再进行语音识别处理。其中,即使在说话者属性取得处理中进行了语音识别的情况下,也优选选择语音识别模型,进行高精度的语音识别处理。此外,在图7的流程图中,也可以对进行了语音识别处理的结果实施步骤S703的说话者属性取得处理。再者,在图7的流程图中,通过电源关断或处理结束的中断,使处理结束。利用图8的流程图,对步骤S703的说话者属性取得处理进行说明。(步骤S801)语音说话者属性取得部304从语音信息中取得一个以上特征量(进行语音分析)。作为由语音说话者属性取得部304取得的一个以上特征量构成的向量的特征向量数据,例如是对使用了三角型滤波器的信道数为24的滤波器组输出进行了离散余弦变换的MFCC,其具有将静态参数、δ参数(deltaparameter)及δδ参数(deltadeltaparameter)分别进行12维以及进一步归一化的功率、δ功率(deltapower)以及δδ功率(deltadeltapower)(39维)。(步骤S802)语音说话者属性取得部304利用在步骤S801取得的一个以上特征量,确定说话者的性别。(步骤S803)语音说话者属性取得部304利用在步骤S801取得的一个以上特征量,确定说话者的年龄层。(步骤S804)语音说话者属性取得部304根据语音信息,取得语速。取得语速的处理是公知技术。(步骤S805)语音说话者属性取得部304对语音识别部308委托语音识别处理,得到语音识别结果。(步骤S806)语音说话者属性取得部304对在步骤S805得到的语音识别结果进行自然语言处理,并确定说话者类别。返回上位处理。此外,在图8的流程图中,对包含在所接收的语音翻译控制信息(说话者属性)中的说话者属性(例如,性别),也可以不进行取得处理(例如,步骤S802)。从而实现处理的高速化。此外,优选只取得一次在会话中不变化的说话者属性(性别、年龄层等),在会话中变化的说话者属性(语速等)则每次取得,或者还利用累积的信息使其发生变化。接着,利用图9的流程图,对翻译服务器装置4的动作进行说明。(步骤S901)语音识别结果接收部406判断是否接收了语音识别结果。若接收了语音识别结果,则进入步骤S902,若没接收语音识别结果,则返回步骤S901。(步骤S902)第四说话者属性接收部403判断是否接收了语音翻译控制信息。若接收了语音翻译控制信息,则进入步骤S903,若没接收,则进入步骤S909。(步骤S903)语言说话者属性取得部404对在步骤S901接收的语音识别结果进行自然语言处理,并取得一个以上语言说话者属性。语言说话者属性取得部404例如从语音识别结果,取得说话者类别。(步骤S904)第四说话者属性存储部405在由步骤S902接收的语音翻译控制信息中追加由步骤S903取得的一个以上语言说话者属性,构成语音翻译控制信息,并且,将该语音翻译控制信息至少暂时存储在第四说话者属性保存部401。(步骤S905)第四模型选择单元4072利用在步骤S902接收的语音翻译控制信息所具有的一个以上说话者属性、或者被保存在第四说话者属性保存部401的语音翻译控制信息所具有的一个以上说话者属性,检索翻译模型选择信息管理表,取得翻译模型标识符。即,第四模型选择单元4072选择翻译模型。此外,第四模型选择单元4072从翻译模型保存部402读取所选择的翻译模型。(步骤S906)翻译部408利用所读取的翻译模型,对在步骤S901接收的语音识别结果进行翻译处理。然后,翻译部408得到翻译结果。(步骤S907)第四服务器选择单元4092利用被保存在第四说话者属性保存部401中的语音翻译控制信息所具有的一个以上说话者属性,检索语音合成服务器选择信息管理表,取得与一个以上说话者属性对应的语音合成服务器装置标识符。(步骤S908)翻译结果发送部410向与在步骤S907取得的语音合成服务器装置标识符对应的语音合成服务器装置5,发送在步骤S906得到的翻译结果。(步骤S909)第四说话者属性发送部411向与在步骤S907取得的语音合成服务器装置标识符对应的语音合成服务器装置5,发送被保存在第四说话者属性保存部401的语音翻译控制信息。返回步骤S901。(步骤S910)第四模型选择单元4072判断在第四说话者属性保存部401中是否保存有语音翻译控制信息。若保存有语音翻译控制信息,则进入步骤S911,若未保存,则进入步骤S912。(步骤S911)第四模型选择单元4072读取被保存在第四说话者属性保存部401的语音翻译控制信息。进入步骤S905。(步骤S912)第四模型选择单元4072读取被保存在翻译模型保存部402的任意的翻译模型。进入步骤S906。此外,在图9的流程图中,通过电源关断或处理结束的中断,使处理结束。接着,利用图10的流程图,对语音合成服务器装置5的动作进行说明。(步骤S1001)翻译结果接收部505判断是否接收了翻译结果。若接收翻译结果,则进入步骤S1002,若不接收翻译结果,则返回步骤S1001。(步骤S1002)第五说话者属性接收部503判断是否接收了语音翻译控制信息。若接收语音翻译控制信息,则进入步骤S1003,若不接收,则进入步骤S1007。(步骤S1003)第五说话者属性存储部504将在步骤S1002接收的语音翻译控制信息至少暂时存储在第五说话者属性保存部501。(步骤S1004)第五模型选择单元5062利用被保存在第五说话者属性保存部501的语音翻译控制信息所具有的一个以上说话者属性,检索语音合成模型选择信息管理表,取得语音合成模型标识符。即,第五模型选择单元5062选择语音合成模型。然后,第五模型选择单元5062从语音合成模型保存部502取得所选择的语音合成模型。(步骤S1005)语音合成部507利用所读取的语音合成模型,对在步骤S1001接收的翻译结果进行语音合成处理。然后,语音合成部507得到语音合成后的语音信息(语音合成结果)。(步骤S1006)语音合成结果发送部508向第二终端装置2发送在步骤S1005得到的语音合成结果。此外,例如识别第二终端装置2的第二终端装置标识符(例如,第二终端装置2的电话号码或IP地址等)包含在语音翻译控制信息中。返回步骤S1001。(步骤S1007)第五模型选择单元5062判断在第五说话者属性保存部501是否保存有语音翻译控制信息。若保存有语音翻译控制信息,则进入步骤S1008,若没保存,则进入步骤S1009。(步骤S1010)第五模型选择单元5062读取被保存在第五说话者属性保存部501的语音翻译控制信息。进入步骤S1004。(步骤S1011)第五模型选择单元5062读取被保存在语音合成模型保存部502的任意的语音合成模型。进入步骤S1005。此外,在图10的流程图中,通过电源关断或处理结束的中断,使处理结束。下面,对本实施方式的语音翻译系统的具体动作进行说明。语音翻译系统的概念图为图1。在此,第一终端装置1的用户A是说日本语的37岁的女性,日本语是其母语。此外,第二终端装置2的用户B是说英语的38岁的男性,英语为其母语。此外,在第一终端装置1的第一说话者属性保存部11保存有图11所示的第一说话者属性管理表。第一说话者属性管理表中保存有性别“女性”、年龄“37岁”、使用语言“日本语”、及母语“是”。此外,在第二终端装置2的第二说话者属性保存部21中,保存有图12所示的第二说话者属性管理表。此外,在第一终端装置1的第一服务器选择信息保存单元151及第二终端装置2的第二服务器选择信息保存单元251中,保存有图13所示的语音识别服务器选择信息管理表。语音识别服务器选择信息管理表保存着具有“ID”、“语言”、“说话者属性”、“语音识别服务器装置标识符”这样的属性值的一个以上记录。“语言”是语音识别的对象的语言。“说话者属性”是“性别”、“年龄(在此是年龄的类别)”等。“语音识别服务器装置标识符”是用于与语音识别服务器装置3进行通信的信息,在此是IP地址。此外,在第一服务器选择信息保存单元151,只要存在与语音识别服务器选择信息管理表中的语言“日本语”对应的记录就可以。此外,在第二服务器选择信息保存单元251中,只要存在与语音识别服务器选择信息管理表中的语言「英语」对应的记录就可以。此外,在语音识别服务器装置3的第三模型选择信息保存单元3071中,保存有图14所示的语音识别模型选择信息管理表。语音识别模型选择信息管理表保存着具有“语言”、“说话者属性”、“语音识别模型标识符”这样的属性值的一个以上记录。“语音识别模型标识符”是识别语音识别模型的信息,例如利用在语音识别模型的读取。在此,例如,“语音识别模型标识符”是保存有语音识别模型的文件名等。此外,在语音识别服务器装置3的第三服务器选择信息保存单元3091中,保存有图15所示的翻译服务器选择信息管理表。翻译服务器选择信息管理表保存着具有“ID”、“原语言”、“目标语言”、“说话者属性”、“翻译服务器装置标识符”这样的属性值的一个以上记录。“原语言”是作为翻译源的语言。“目标语言”是翻译结果的目标语言。在此,“说话者属性”具有“性别”、“年龄”、“第一说话者类别”等。“第一说话者类别”是根据所使用单词的难度确定的、估计了说话者的知识水平的信息。在“第一说话者类别”为“A”的情况下,设定为说话者的知识水平较高。在“第一说话者类别”为“B”或“C”的情况下,设定为说话者的知识水平为中等或低。关于知识水平的估计方法例子,将在后面说明。“翻译服务器装置标识符”是用于与翻译服务器装置4进行通信的信息,在此是IP地址。此外,翻译服务器装置4的第四模型选择信息保存单元4071保持着图16所示的翻译模型选择信息管理表。翻译模型选择信息管理表保存着一个以上记录,该记录中具有“ID”、“原语言”、“说话者属性”、“翻译模型标识符”的属性值。在此,“说话者属性”具有“性别”、“年龄”、“第二说话者类别”等。“第二说话者类别”表示使用语言是否为母语。是母语的情况下成为“Y”、不是母语的情况下成为“N”的属性值。“翻译模型标识符”是用于识别翻译模型的信息,例如利用在翻译模型的读取。在此,例如“翻译模型标识符”是保存有翻译模型的文件名等。此外,翻译服务器装置4的第四服务器选择信息保存单元4091保存着图17所示的语音合成服务器选择信息管理表。语音合成服务器选择信息管理表保存着一个以上记录,该记录中具有“ID”、“目标语言”、“说话者属性”、“语音合成服务器装置标识符”的属性值。在此,“说话者属性”具有“性别”、“年龄”、“语速”、“第一说话者类别”、“第二说话者类别”等。“语速”是说话速度,在此,可以取“快”、“中”、“慢”这3个值中的任一值。“快”例如是说话速度为“5音节/秒”以上的情况,“中”例如是说话速度小于“5音节/秒”且“3音节/秒”以上的情况,“慢”例如是说话速度小于“3音节/秒”的情况。其中,不限定“语速”的分类种类、分类方法、算法等。“语音合成服务器装置标识符”是用于与语音合成服务器装置5进行通信的信息,在此是IP地址。再者,语音合成服务器装置5的第五模型选择信息保存单元5061保持着图18所示的语音合成模型选择信息管理表。语音合成模型选择信息管理表保存着一个以上记录,该记录中具有“ID”、”目标语言”、“说话者属性”、“语音合成模型标识符”的属性值。在此,“说话者属性”具有“性别”、“年龄”、“第二说话者类别”等。作为“说话者属性”,更优选具有“语速”或“第一说话者类别”。“语音合成模型标识符”是用于识别语音合成模型的信息,例如利用在语音合成模型的读取。在此,例如“语音合成模型标识符”是保存有语音合成模型的文件名等。在上述状况中,假设用户A要向用户B拨打电话。并且,用户A从第一终端装置1调用了输入对方(用户B)的电话号码等的画面、即图19的画面。然后,第一终端装置1读取被保存在第一说话者属性保存部11的第一说话者属性管理表(图11),并显示图19的画面。之后,假设用户输入对方的使用语言和对方的电话号码,并按下“呼叫”按钮。此外,在图19中,假设自身的电话号码“080-1111-2256”保存在未图示的存储介质中。接着,第一终端装置1的未图示的呼叫部呼叫第二终端装置2。然后,开始通话。接着,第一终端装置1的第一语音接受部14接受用户A的语音“おはようございます”。接着,第一服务器选择单元152从第一说话者属性保存部11读取图11的说话者属性。接着,第一服务器选择单元152将所读取的一个以上说话者属性“性别:女性,年龄:37歳,使用语言:日本语···”应用于图13的语音识别服务器选择信息管理表,检索“ID=7”的记录,并取得语音识别服务器装置标识符“186.221.1.27”。接着,第一说话者属性发送部19利用一个以上说话者属性,构成语音翻译控制信息。第一说话者属性发送部19例如构成图20所示的语音翻译控制信息。该语音翻译控制信息包含一个以上说话者属性以及用户A从图19的画面输入的信息(对方的使用语言“目标语言”)。再者,语音翻译控制信息包含语音识别服务器装置标识符“186.221.1.27”。接着,第一语音发送部16对接受的语音“おはようございます”进行数字化,取得“おはようございます”的语音信息。然后,第一语音发送部16将该语音信息发送到以“186.221.1.27”识别的语音识别服务器装置3。接着,第一说话者属性发送部19将图20的语音翻译控制信息发送到以“186.221.1.27”识别的语音识别服务器装置3。接着,语音识别服务器装置3的语音信息接收部306接收语音信息“おはようございます”。然后,第三说话者属性接收部303接收图20的语音翻译控制信息。接着,语音说话者属性取得部304根据接收的语音信息“おはようございます”取得一个以上说话者属性。即,第三说话者属性接收部303从语音信息“おはようございます”中取得一个以上特征量。然后,第三说话者属性接收部303利用一个以上特征量,取得预先决定的信息。在此,虽然在图20的语音翻译控制信息中包含性别、年龄等说话者属性,但是,第三说话者属性接收部303也可以取得与语音翻译控制信息重复的说话者属性(性别或年龄等),并且将取得的说话者属性优先利用于语音识别、后面的翻译或语音合成。接着,语音说话者属性取得部304根据语音信息“おはようございます”取得语速。在此,假设语音说话者属性取得部304判断为4音节/秒,取得语速“中”。接着,第三模型选择单元3072利用保存在第三说话者属性保存部301中的语音翻译控制信息所具有的一个以上说话者属性、以及语音说话者属性取得部304所取得的一个以上说话者属性(在此,语速“中”),从语音识别模型选择信息管理表(图14)检索“ID=18”的记录,取得语音识别模型标识符“JR6”。然后,第三模型选择单元3072从语音识别模型保存部302读取所选择的语音识别模型“JR6”。语音识别部308利用所读取的语音识别模型,对接收的语音信息进行语音识别处理,得到语音识别结果“おはようございます”。接着,语音说话者属性取得部304向语音识别部308委托语音识别处理,得到语音识别结果“おはようございます”。语音说话者属性取得部304对得到的语音识别结果进行自然语言处理,由于是敬语,取得第一说话者类别“A”。语音说话者属性取得部304例如也可以保存构成敬语的用语“ございます”、“です”或难易度高的用语“龃龉”、“谬误”等,并根据这些用语的出现频度、出现比例等,确定第一说话者类别。语音说话者属性取得部304对“おはようございます”进行形态素解析,分割为“おはよう”和“ございます”的2个形态素。接着,语音说话者属性取得部304检测“ございます”与所管理的的用语一致的情况。接着,语音说话者属性取得部304计算出是管理用语的比例为“50%”。接着,语音说话者属性取得部304根据所保存的判断条件“A:管理用语的出现比例为5%以上,B:管理用语的出现比例为1%以上且小于5%,C:管理用语的出现比例小于1%”,确定第一说话者类别为“A”。此外,优选每当连续地进行会话时,语音说话者属性取得部304每次都计算管理用语的出现比例,确定并变更第一说话者类别。接着,第三说话者属性存储部305在接收的语音翻译控制信息(图20)上追加作为说话者属性的语速“中”及第一说话者类别“A”。然后,第三说话者属性存储部305将图21的语音翻译控制信息至少临时存储到第三说话者属性保存部301。接着,第三服务器选择单元3092利用被保存在第三说话者属性保存部301的语音翻译控制信息(图21)所具有的一个以上说话者属性,检索翻译服务器选择信息管理表(图15),取得与一个以上说话者属性对应的“ID=25”的记录中的翻译服务器装置标识符“77.128.50.80”。然后,第三说话者属性存储部305把翻译服务器装置标识符“77.128.50.80”追加到语音翻译控制信息中,并且存储在第三说话者属性保存部301。如此更新的语音翻译控制信息示于图22。接着,语音识别结果发送部310向与所取得的翻译服务器装置标识符“77.128.50.80”对应的翻译服务器装置4,发送语音识别结果“おはようございます”。然后,第三说话者属性发送部311向与取得的翻译服务器装置标识符“77.128.50.80”对应的翻译服务器装置4,发送被保存在第三说话者属性保存部301的语音翻译控制信息(图22)。接着,翻译服务器装置4的语音识别结果接收部406接收语音识别结果「おはようございます」。然后,第四说话者属性接收部403接收语音翻译控制信息(图22)。接着,第四说话者属性存储部405将接收的语音翻译控制信息(图22)至少暂时存储在第四说话者属性保存部401。接着,第四模型选择单元4072利用图22的语音翻译控制信息所具有的一个以上说话者属性,从翻译模型选择信息管理表(图16)检索“ID=18”的记录,取得翻译模型标识符“JT4”。然后,第四模型选择单元4072从翻译模型保存部402读取“JT4”的翻译模型。接着,翻译部408利用读取的翻译模型“JT4”,对接收的语音识别结果“おはようございます”进行翻译处理。然后,翻译部408得到翻译结果“Goodmorning.”。接着,第四服务器选择单元4092利用图22的语音翻译控制信息所具有的一个以上说话者属性,从语音合成服务器选择信息管理表(图17)检索与一个以上说话者属性对应的“ID=33”的记录,取得语音合成服务器装置标识符“238.3.55.7”。然后,第四说话者属性存储部405构成在图22的语音翻译控制信息中追加了语音合成服务器装置标识符“238.3.55.7”的语音翻译控制信息(图23),将该语音翻译控制信息存储到第四说话者属性保存部401。接着,翻译结果发送部410向与语音合成服务器装置标识符“238.3.55.7”对应的语音合成服务器装置5,发送翻译结果“Goodmorning.”。接着,第四说话者属性发送部411将图23的语音翻译控制信息发送到与语音合成服务器装置标识符“238.3.55.7”对应的语音合成服务器装置5。接着,语音合成服务器装置5的翻译结果接收部505接收翻译结果。此外,第五说话者属性接收部503接收图23的语音翻译控制信息。然后,第五说话者属性存储部504将接收的语音翻译控制信息至少暂时存储在第五说话者属性保存部501。接着,第五模型选择单元5062利用保存在第五说话者属性保存部501的语音翻译控制信息(图23)所具有的一个以上说话者属性,从语音合成模型选择信息管理表检索“ID=18”的记录,取得语音合成模型标识符“JC9”。然后,第五模型选择单元5062从语音合成模型保存部502读取所选择的语音合成模型“JC9”。接着,语音合成部507利用所读取的语音合成模型,对翻译结果“Goodmorning.”进行语音合成处理。然后,语音合成部507得到语音合成后的语音信息(语音合成结果)。接着,语音合成结果发送部508向第二终端装置2发送得到的语音合成结果。接着,第二终端装置2的第二语音接收部27接收语音合成结果“Goodmorning”。然后,第二语音输出部28输出语音“Goodmorning”。通过以上处理,用户A发出的“おはようございます”在到达第二终端装置2之前变换为“Goodmorning”的语音,向第二终端装置2输出“Goodmorning”。此外,第二终端装置2的用户B对“Goodmorning”作出应答而发出“Goodmorning”的语音,通过上述相同的处理变换为“おはよう”,向第一终端装置1输出语音“おはよう”。以上,根据本实施方式,在语音识别、翻译、语音合成的各处理中,能够选择与说话者属性一致的适当的装置或适当的模型。其结果,能够提供精度高、或继承了说话者属性的网络型语音翻译系统。此外,根据本实施方式,在会话过程中,语速或说话者类别等说话者属性发生了变化的情况下,适用与该变化相符的装置(语音识别、翻译、语音合成的各装置)或模型(语音识别、翻译、语音合成的各模型),能够适当地进行语音识别、翻译、语音合成等处理。此外,根据本实施方式,在语音识别、翻译、语音合成的各处理中,能够全部选择与说话者属性相符的适当的装置或适当的模型。但是,也可以只选择进行语音识别的装置或模型,也可以只选择进行翻译的装置或模型,也可以只选择进行语音合成的装置或模型。此外,根据本实施方式,例如用户指定了翻译服务器装置或翻译模型的情况下,优选使用被指定的翻译服务器装置或翻译模型,进行翻译处理。这是由于有时用户想要利用存储了自身想要使用的表现的翻译服务器装置或翻译模型。在这种情况下,例如在第一终端装置1保存了用于识别想要利用的翻译服务器装置的翻译服务器装置标识符或用于识别翻译模型的翻译模型标识符。然后,这样的翻译服务器装置标识符或翻译模型标识符附加在语音翻译控制信息上。然后,这样的语音翻译控制信息经由语音识别服务器装置3发送到翻译服务器装置4。此外,同样地,在本实施方式中优选如下方式:例如用户指定了语音合成服务器装置或语音合成模型的情况下,使用所指定的语音合成服务器装置或语音合成模型进行语音合成处理。这是由于有时用户例如想要利用收集了自身语音的语音合成模型或保存了已收集自身语音的语音合成模型的语音合成服务器装置,进行目标语言的语音合成。在这种情况下,例如在第一终端装置1保存了用于识别想要利用的语音合成服务器装置的语音合成服务器装置标识符、或者用于识别语音合成模型的语音合成模型标识符。然后,这样的语音合成服务器装置标识符或语音合成模型标识符附加在语音翻译控制信息中。然后,这样的语音翻译控制信息经由语音识别服务器装置3及翻译服务器装置4,从第一终端装置1发送到语音合成服务器装置5。附加了用于识别用户指定的翻译服务器装置的信息和用于识别用户指定的语音合成服务器装置的信息的语音翻译控制信息的例子是图24。此外,根据本实施方式,第一终端装置1进行语音识别服务器装置3的选择处理。此外,语音识别服务器装置3进行了语音识别模型的选择处理及翻译服务器装置4的选择处理。此外,翻译服务器装置4进行了翻译模型的选择处理及语音合成服务器装置5的选择处理。而且,语音合成服务器装置5进行了语音合成模型的选择处理。但是,这样的模型或服务器装置的选择处理也可以由其他装置进行。例如,在一个控制装置进行这样的服务器装置的选择处理时的语音翻译系统6的概念图是图25。在图25中,语音翻译系统具备:一个以上第一终端装置251,一个以上第二终端装置252,一个以上语音识别服务器装置253,一个以上翻译服务器装置254,一个以上语音合成服务器装置5以及控制装置256。该语音翻译系统6和上述语音翻译系统之间的差异,是因进行服务器装置的选择处理的装置不同而产生的差异。此外,在图25中,模型的选择是分别由语音识别服务器装置253、翻译服务器装置254及语音合成服务器装置5进行。此外,在图25中,第一终端装置251、第二终端装置252、语音识别服务器装置253、翻译服务器装置254及语音合成服务器装置255分别从控制装置256接收处理前的结果,向控制装置256发送处理后的结果。即,第一终端装置251向控制装置256发送从用户A接受的语音信息。然后,控制装置256确定进行语音识别的语音识别服务器装置253,并向语音识别服务器装置253发送语音信息。接着,语音识别服务器装置253接收语音信息,根据需要选择语音识别模型,进行语音识别处理。然后,语音识别服务器装置253向控制装置256发送语音识别结果。接着,控制装置256从语音识别服务器装置253接收语音识别结果,并选择进行翻译的翻译服务器装置254。然后,控制装置256向选择的翻译服务器装置254发送语音识别结果。接着,翻译服务器装置254接收语音识别结果,并根据需要选择翻译模型,进行翻译处理。然后,翻译服务器装置254向控制装置256发送翻译结果。接着,控制装置256从翻译服务器装置254接收翻译结果,选择进行语音合成的语音合成服务器装置5。之后,控制装置256向所选择的语音合成服务器装置5发送翻译结果。接着,语音合成服务器装置5接收翻译结果,并根据需要选择语音合成模型,进行语音合成处理。之后,语音合成服务器装置5向控制装置256发送语音合成结果。接着,控制装置256从语音合成服务器装置5接收语音合成结果,并发送到第二终端装置252。接着,第二终端装置252接收语音合成结果,并输出。图26是语音翻译系统6的框图。在图26中,由第一终端装置251的第一语音发送部16、第一语音接收部17、第一说话者属性发送部19,第二终端装置252的第二语音发送部26、第二语音接收部27、第二说话者属性发送部29进行信息收发的装置是控制装置256。在图26中,第一终端装置251具备:第一说话者属性保存部11,第一说话者属性接受部12,第一说话者属性存储部13,第一语音接受部14,第一语音发送部16,第一语音接收部17,第一语音输出部18,以及第一说话者属性发送部19。第二终端装置252具备:第二说话者属性保存部21,第二说话者属性接受部22,第二说话者属性存储部23,第二语音接受部24,第二语音发送部26,第二语音接收部27,第二语音输出部28,以及第二说话者属性发送部29。图27是控制装置256的框图。控制装置256具备:说话者属性保存部2561,发送接收部2562,说话者属性存储部2563,第二语音识别服务器选择部25,翻译服务器选择部309,以及语音合成服务器选择部409。说话者属性保存部2561能够保存一个以上的说话者属性。说话者属性保存部2561也可以保存语音翻译控制信息。发送接收部2562与第一终端装置251、第二终端装置252、语音识别服务器装置253、翻译服务器装置254及语音合成服务器装置5之间,收发各种信息。所谓各种信息,是语音信息、语音识别结果、翻译结果、语音合成结果及语音翻译控制信息(也包含一部分说话者属性)等。发送接收部2562通常可以由无线或有线的通信单元实现。说话者属性存储部2563将发送接收部2562接收的一个以上说话者属性(也可以是语音翻译控制信息)存储在说话者属性保存部2561中。此外,图28是语音识别服务器装置253的框图。语音识别服务器装置253具备:第三说话者属性保存部301,语音识别模型保存部302,第三说话者属性接收部303,语音说话者属性取得部304,第三说话者属性存储部305,语音信息接收部306,语音识别模型选择部307,语音识别部308,语音识别结果发送部310,以及第三说话者属性发送部311。此外,图29是翻译服务器装置254的框图。翻译服务器装置254具备:第四说话者属性保存部401,翻译模型保存部402,第四说话者属性接收部403,第四说话者属性存储部405,语音识别结果接收部406,翻译模型选择部407,翻译部408,翻译结果发送部410,以及第四说话者属性发送部411。此外,在本实施方式中,利用图20~图24对语音翻译控制信息的例子进行了说明。其中,不限定语音翻译控制信息的格式。语音翻译控制信息当然可以是图30所示的XML格式。将图30所示的语音翻译控制信息的描述语言称作语音翻译用标记语言STML(SpeechTranslationMarkuplanguage)。在图30中,记载了用户ID(确定说话者的用户的信息“Mike”)、语音识别的输出结果的格式或大小(MaxNBest=“2”)、原语言“英语”(Language=“en”)、确定翻译对象的信息(在此为Task=“Dictation”、会话的范围(在此为“Travel(旅行)”)以及表示输入语音的格式的信息(在此为“ADPCM”)。此外,在图30中,记载着说话者属性中的性别(在此为“male”)、年龄(在此为“30”)及是否为母语(在此为“no”)。此外,在图30中,记载着表示输出文本的格式的信息(在此为“SurfaceForm”)。而且,在语音翻译控制信息中,也可以存在表示输出语音的格式的信息、指定输入输出语音的音质的信息、表示输入文本的格式的信息等信息。此外,上述的(MaxNBest=“2”)表示输出并发送语音识别结果中的上位第2个为止的候補。此外,Nbest表示语音识别结果中的上位第N个为止的候補。此外,在本实施方式中,语音识别服务器装置3及翻译服务器装置4也可以不是分别进行语音识别模型的选择或翻译模型的选择。此外,也可以不选择进行语音识别处理的语音识别服务器装置3或者进行翻译处理的翻译服务器装置4。在这种情况下,进行与说话者属性对应的语音合成服务器装置5的选择或语音合成模型的选择。这样的语音合成服务器装置5的选择处理、语音合成模型的选择处理如上所述。此外,语音合成服务器装置5的语音合成部507也可以根据说话者属性(例如,语速、音的高低或音质等),改变语音来构成输出的语音信息。即,语音合成部507也可以利用语音合成模型保存部502的语音合成模型,对翻译结果接收部505所接收的翻译结果进行语音合成,以使其与第五说话者属性接收部503所接收的一个以上说话者属性所表示的属性相符,并取得语音合成结果。此外,语音合成部507也可以利用语音合成模型保存部52的语音合成模型,对翻译结果接收部505所接收的翻译结果进行语音合成,以使其与语音翻译控制信息的说话者属性所示的属性相符,并取得语音合成结果。在这种情况下,也可以称作语音合成模型的选择。再者,也可以由软件实现本实施方式的处理。此外,也可以通过软件下载等来发布该软件。此外,也可以把该软件记录在CD-ROM等存储介质中传布。此外,这在本说明书中的其他实施方式中也同样。此外,用于实现本实施方式的第一终端装置的软件是如下的程序。即,该程序是使计算机执行以下各单元的功能的程序:第一语音接受部,接受语音;第一语音识别服务器选择部,根据存储介质中保存的一个以上说话者属性,选择2个以上语音识别服务器装置中的一个语音识别服务器装置;以及第一语音发送部,向上述第一语音识别服务器选择部选择的语音识别服务器装置,发送由上述第一语音接受部接受的语音构成的语音信息。此外,实现本实施方式中的语音识别服务器装置的软件,是使计算机执行以下各单元的功能的程序:语音信息接收部,接收语音信息;语音识别模型选择部,根据存储介质中保存的一个以上说话者属性,从存储介质中所保存的2个以上语音识别模型中选择一个语音识别模型;语音识别部,利用上述语音识别模型选择部选择的语音识别模型,对上述语音信息接收部所接收的语音信息进行语音识别,并取得语音识别结果;语音识别结果发送部,发送上述语音识别结果。此外,用于实现本实施方式的语音识别服务器装置的软件是使计算机执行以下各单元的功能的程序:语音信息接收部,接收语音信息;语音识别部,利用存储介质中保存的语音识别模型,对上述语音信息接收部接收的语音信息进行语音识别,并取得语音识别结果;翻译服务器选择部,根据存储介质中保存的一个以上说话者属性,选择2个以上翻译服务器装置中的一个翻译服务器装置;以及语音识别结果发送部,向上述翻译服务器选择部选择的翻译服务器装置发送上述语音识别结果。此外,用于实现本实施方式的语音识别服务器装置的软件是使计算机执行以下各单元的功能的程序:语音说话者属性取得部,根据上述语音信息接收部接收的语音信息,取得关于语音的一个以上说话者属性;以及第三说话者属性存储部,将上述语音说话者属性取得部所取得的一个以上说话者属性存储到存储介质中。此外,用于实现本实施方式的翻译服务器装置的软件是使计算机执行以下各单元的功能的程序:第四说话者属性接收部,接收一个以上的说话者属性;语音识别结果接收部,接收语音识别结果;翻译模型选择部,根据上述第四说话者属性接收部所接收的一个以上说话者属性,从存储介质中所保存的2个以上的翻译模型中选择一个翻译模型;翻译部,利用上述翻译模型选择部选择的翻译模型,将上述语音识别结果接收部所接收的语音识别结果翻译成目标语言,并取得翻译结果;翻译结果发送部,发送上述翻译结果。此外,用于实现本实施方式中的翻译服务器装置的软件,是使计算机执行以下各单元的功能的程序:第四说话者属性接收部,接收一个以上说话者属性;语音识别结果接收部,接收语音识别结果;翻译部,利用存储介质中保存的翻译模型,把上述语音识别结果接收部接收的语音识别结果翻译成目标语言,并取得翻译结果;语音合成服务器选择部,根据上述一个以上说话者属性,选择2个以上语音合成服务器装置中的一个语音合成服务器装置;以及翻译结果发送部,向上述语音合成服务器选择部选择的语音合成服务器装置发送上述翻译结果。此外,用于实现本实施方式中的翻译服务器装置的软件是使计算机执行以下各单元的功能的程序:语言说话者属性取得部,根据上述语音识别结果接收部所接收的语音识别结果,取得关于语言的一个以上说话者属性;以及第四说话者属性存储部,将上述语言说话者属性取得部取得的一个以上说话者属性存储到存储介质中。此外,用于实现本实施方式中的语音合成服务器装置的软件是使计算机执行以下各单元的功能的程序:接收一个以上说话者属性的第五说话者属性接收部;接收翻译结果的翻译结果接收部;语音合成模型选择部,根据上述第五说话者属性接收部所接收的一个以上说话者属性,从存储介质中保存的2个以上语音合成模型中选择一个语音合成模型;语音合成部,利用上述语音合成模型选择部选择的语音合成模型,对上述翻译结果接收部所接收的翻译结果进行语音合成,并取得语音合成结果;语音合成结果发送部,将上述语音合成结果发送到第二终端装置。此外,图31示出执行本说明书中描述的程序而实现上述实施方式的语音翻译系统等的计算机的外观。上述的实施方式能够由计算机硬件以及在其上面执行的计算机程序实现。图31是该计算机系统340的概念图,图32是表示计算机系统340的内部结构的图。在图31中,计算机系统340包括:包含FD驱动器3411、CD-ROM驱动器3412的计算机341,键盘342,鼠标343,以及监视器344。在图32中,计算机341除了具有FD驱动器3411、CD-ROM驱动器3412之外,还包括:MPU3413;总线3414,连接到CD-ROM驱动器3412及FD驱动器3411上;RAM3416,连接到用于存储引导程序等程序的ROM3415,暂时存储应用程序的指令,并且提供临时存储空间;以及硬盘3417,用于存储应用程序、系统程序及数据。在此,虽然未图示,但是,计算机341也可以进一步包含用于提供与LAN的连接的网卡。使计算机系统340执行上述实施方式的语音翻译系统等的功能的程序,也可以存储在CD-ROM3501或FD3502中,插入CD-ROM驱动器3412或FD驱动器3411之后,进而转送到硬盘3417。也可以是,经由未图示的网络把程序发送到计算机341,并存储到硬盘3417中。程序在执行时被装载到RAM3416中。程序也可以直接从CD-ROM3501、FD3502或网络装载。在程序中,不必一定包括使计算机341执行上述实施方式的语音翻译系统等的功能的操作系统(OS)或第三方程序等。在程序中,只要包括以被控制的方式调用适当功能(模块)、并得到期望结果的指令的部分就可以。计算机系统340如何工作是公知技术,省略详细说明。此外,在上述程序中,在发送信息的步骤或接收信息的接收步骤等,不包含由硬件进行的处理,例如发送步骤中由调制解调器或接口卡等进行的处理(只能由硬件进行的处理)。此外,执行上述程序的计算机可以是单个,也可以是多个。即,可以进行集中处理,或者也可以进行分散处理。此外,在上述各实施方式中,存在于一个装置中的2个以上通信单元(语音识别结果接收部、第四说话者属性接收部等),当然在物理上可以由一个媒介实现。此外,在上述各实施方式中,也可以通过由单一装置(系统)进行集中处理来实现各处理(各功能),或者,也可以由多个装置进行分散处理来实现各处理(各功能)。此外,在由单一装置(系统)集中处理各处理(各功能)时,语音翻译系统是一个装置,语音识别服务器装置、翻译服务器装置及语音合成服务器装置被包含在一个装置中。在这种情况下,上述信息的发送及接收成为信息的交接。即,上述接收或发送可以较宽地理解。更具体而言,语音翻译系统由单一装置集中处理的情况下,该语音翻译系统例如成为图33所述的结构。即,语音翻译系统具备:语音接受部3301,第三说话者属性保存部301,语音识别模型保存部302,语音说话者属性取得部304,语音识别模型选择部307,语音识别部308,翻译模型保存部402,语言说话者属性取得部404,翻译模型选择部407,翻译部408,语音合成模型保存部502,语音合成模型选择部506,语音合成部507,以及语音合成结果输出部3302。语音接受部3301从用户接受语音。该语音是语音翻译对象的语音。语音接受部3301例如可以由麦克风及其驱动软件等构成。通常,第三说话者属性保存部301保存着从用户接受的说话者属性。此处的说话者属性通常是静态说话者属性信息。语音说话者属性取得部304根据由语音接受部3301接受的语音构成的语音信息,取得一个以上语音说话者属性。在此取得的语音说话者属性主要是动态说话者属性信息,但也可以是静态说话者属性信息。语音识别模型选择部307根据第三说话者属性保存部301的说话者属性或语音说话者属性取得部304所取得的说话者属性中的一个以上说话者属性,从2个以上的语音识别模型中选择一个语音识别模型。语音识别部308利用语音识别模型保存部302的语音识别模型,对由语音接受部3301所接受的语音构成的语音信息进行语音识别,并取得语音识别结果。此外,语音识别部308优选利用语音识别模型选择部307选择的语音识别模型,对语音信息进行语音识别,并取得语音识别结果。语言说话者属性取得部404根据语音识别部308所取得的语音识别结果,取得一个以上语言说话者属性。翻译模型选择部407根据一个以上说话者属性,从2个以上翻译模型中选择一个翻译模型。此处的说话者属性,是第三说话者属性保存部301的说话者属性、或者语音说话者属性取得部304所取得的说话者属性、或者语言说话者属性取得部404所取得的语言说话者属性中的一个以上说话者属性。翻译部408利用翻译模型保存部402的翻译模型,将语音识别结果翻译成目标语言,并取得翻译结果。翻译部408优选利用翻译模型选择部407选择的翻译模型,将语音识别结果翻译成目标语言,并取得翻译结果。语音合成模型选择部506根据一个以上说话者属性,从2个以上语音合成模型中选择一个语音合成模型。此处的说话者属性是第三说话者属性保存部301的说话者属性、或者语音说话者属性取得部304所取得的说话者属性、或者语言说话者属性取得部404所取得的语言说话者属性中的一个以上说话者属性。语音合成部507利用语音合成模型保存部502的语音合成模型,对翻译结果进行语音合成,并取得语音合成结果。语音合成部507优选利用语音合成模型选择部506选择的语音合成模型,对翻译结果进行语音合成,并取得语音合成结果。语音合成结果输出部3302输出由语音合成部507取得的语音合成结果。此处的输出是包含使用了扬声器等的语音输出、向外部装置(通常,语音输出装置)的发送、向存储介质的存储、向其他处理装置或其他程序等的处理结果的传送等概念。语音合成结果输出部3302可以由扬声器及其驱动软件等构成。此外,在语音翻译系统中,第三说话者属性保存部301、语音说话者属性取得部304、语音识别模型选择部307、语言说话者属性取得部404、翻译模型选择部407、语音合成模型选择部506并不是必需的构成要素。本发明不限于以上实施方式,能够进行各种变更,这些变更当然也包含在本发明的范围内。工业实用性如上所述,本发明涉及的语音翻译系统,在语音翻译过程中,能够根据说话者的属性来变更进行语音识别、翻译或语音合成的装置或模型,在语音识别、翻译或语音合成的各处理中,具有提高精度,进行恰当输出的效果,作为语音翻译系统等有用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1