一种基于一维线性空间实现Trie树的词典存储管理方法与流程
本发明涉及一种词典存储管理方法,尤其涉及一种基于一维线性空间实现Trie树的词典存储管理方法。
背景技术:
在信息检索和自然语言处理领域,特别是基于词典的技术应用中,词典的规模一般都非常大,拥有成千上万甚至上亿条记录,尤其是搜索引擎中倒排索引词的规模最为庞大。对海量数据词典的存储,当前通常采用索引的数据结构来实现。常用的索引结构包括线性索引表、倒排表、散列(hash)表和搜索树等。当前网络上流行的Trie树的实现版本一般都是基于双数组的,两个数组的名字分别为base[]和check[],数组中的每一个元素下标i相当于Trie树的一个结点编号或在双数组中的存储位置,又称状态编号。base[i]:存放的是当前状态i到所有后继状态最小无冲突的偏移量;check[i]:存放的是当前状态i的直接前驱信息,即存储当前状态是由哪一个状态转移而来;base和check是成对的;base[i]和check[i]代表同一个状态的属性。然而这种基于双数组实现的Trie树的词典数据存储方法存在着这样一个问题:会因为插入新状态而引起的冲突导致要移动大量存在冲突的词典数据,不仅会导致词典数据存储速率慢,也会导致数据移动或存储空间的回溯问题。
技术实现要素:
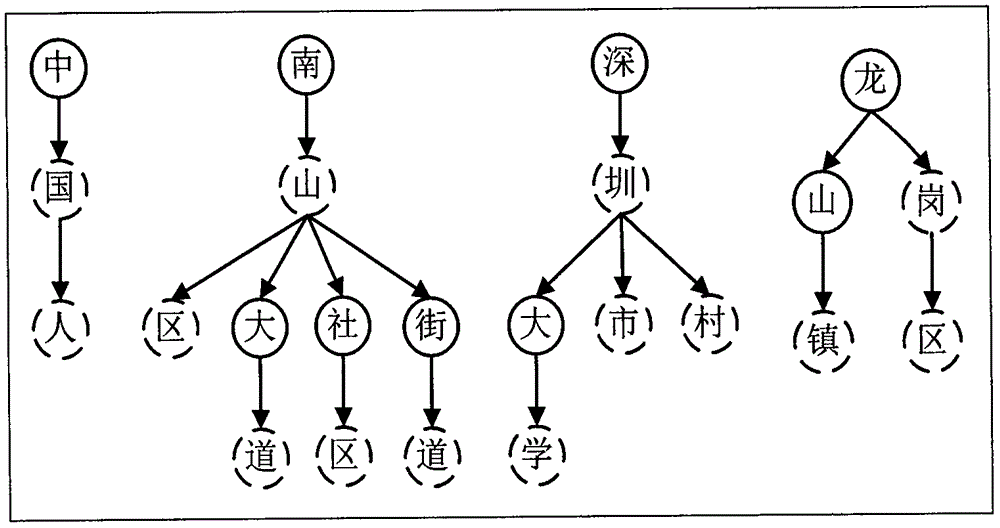
为了解决上述技术的缺陷之一,本发明实施例提供一种基于一维线性空间实现Trie树的词典存储管理方法,本发明采用一维数组代替双数组(base[]和check[]),本方法使得Trie树序列化和反序列化更加便捷,使得词典的加载存储更有效率,同时本发明可以解决双数组实现Trie树的词典数据存储方法中存在的数据移动或存储空间的回溯问题。为此,本发明实施例公开了一种基于一维线性空间实现Trie树的词典存储管理方法。该方法包括以下步骤:获取完整的词典数据;生成有序的词典数据并存放在一维数组中;创建Trie树实现对词典数据的存储。在本发明实施例中,使用一维数组代替双数组(base[]和check[]),此种做法的好处使得Trie树序列化和反序列化更加简单,使得词典的加载更加容易。具体做法可以将base数组放在一维数组的偶数位,check数组放在奇数位,对应关系如下:base[i]->>array[2*i];check[i]->>array[2*i+1].在本发明的一个实施例中,所述生成有序的词典数据包括:将词典数据中所有词条和属性信息以Key为中心按词典顺序排序;合并拥有相同Key值的values。在本发明的一个实施例中,所述的key包括:在每个key后面添加一个虚拟字符代表叶子结点(终端结点),每个叶子结点虚拟字符的存储位置由其直接前驱的base值确定。本发明实施例中,允许让每个key带上自己的属性值values(词性或者其他标注信息)。当前很多Trie树的实现版本,只能存储key,无法将key和key的属性或解释信息(统称为values)直接关联起来。本方法的解决方式是在每个key后面加一个虚拟字符“$”代表叶子结点(终端结点),使得原先的终端结点变为非终端结点,在其后增加一个终端结点“$”作为其直接后继。把每个叶子结点“$”(终端结点)的base值赋上其所处的key按词典顺序序号的相反数-m(m为当前key在所有词条集中的词典顺序序号,m能直接确定相关key对应的values的存储位置),每个叶子结点“$”的存储位置,直接由其直接前驱的base值确定,同时叶子结点的直接前驱定义为自己,即叶子结点的check值等于其状态编号即逻辑存储位置。在本发明的一个实施例中,所述词典顺序排序还包括:拥有公共前缀的keys相邻。在本发明的一个实施例中,所述状态的信息包括:用一个数据机构Node存储每个状态的信息;每个状态的信息包含:当前输入字符、状态的深度、第一个拥有当前状态key的编号、最后一个拥有当前状态key的下一个编号、拥有当前状态key的数量。在本发明实施例中,在创建Trie树的过程中为了很好的避免因插入新状态导致冲突而引起的数据移动,要求所有信息按照key有序,才能够获取当前状态的所有直接后继状态的信息(如当前输入的字符c,该状态在Trie树的深度,直接后继状态包含的词条位置范围等)。为了方便,本发明定义一个数据结构Node存储每个状态的信息。在本发明的一个实施例中,创建Trie树包括以下步骤:定义起始状态,编号为0;将起始状态放入双数组第0位置;以起始状态为当前状态;获取当前状态的所有直接后继状态的信息;为当前结点寻找一个合适的base值,插入其所有直接后继结点。本发明实施例提供的一种基于一维线性空间实现Trie树的词典存储管理方法能够使Trie树序列化和反序列化更加便捷,提高了词典的数据加载存储效率,同时本发明克服了双数组实现Trie树的词典数据存储方法中存在的数据移动或存储空间的回溯问题。应当理解,以上总体说明和以下详细说明都是说明性和实例性的,旨在提供对所要求的本发明的进一步说明。附图说明图1是本发明实施例一种基于一维线性空间实现Trie树的词典存储管理方法的流程图。图2是本发明实施例中词典数据前缀树组成的森林的构造图。图3是本发明实施例中实现Trie树的词典存储的流程的示意图。图4是本发明实施例中实现Trie树创建时结点的插入顺序流程的示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。本发明实施例提供的一种基于一维线性空间实现Trie树的词典存储管理方法,该方法包括以下步骤:获取完整的词典数据;生成有序的词典数据并存放在一维数组中;创建Trie树实现对词典数据的存储。如图1所示,是本发明实施例一种一维线性空间实现Trie树的词典存储管理方法的流程图,包括以下步骤:步骤S110,获取完整的词典数据。例如,词典中要存放如下表1中的这些词条(key)数据:中国深圳中国人深圳大学南山深圳市南山区深圳村南山大道龙山镇南山社区龙岗南山街道龙岗区表1步骤S120,生成有序的词典数据并存放在一维数组中。将词典数据中所有词条和属性信息以Key为中心按词典顺序排序;合并拥有相同Key值的values。同时,让拥有公共前缀的keys相邻。根据上述获取的词典数据,那些词之间存在着一些共同的前缀,按照这些前缀树可以组成一个森林,如图2所示,各棵树的结点做如下说明:虚线圆代表树的终端结点;实线圆代表数的非终端结点;从树的根部结点到当前终端结点构成的词是词典中的一条完整词条;从树的根部结点到某一非终端结点构成的词是词典中某些词条的公共前缀。由此可以看出在构造Trie树中,一定要存储当前状态的直接前驱信息。当前网络上流行的Trie树的实现版本一般都是基于双数组的,两个数组的名字分别为base[]和check[],数组中的每一个元素下标i相当于Trie树的一个结点编号或在双数组中的存储位置,又称状态编号。base[i]:存放的是当前状态i到所有后继状态最小无冲突的偏移量。check[i]:存放的是当前状态i的直接前驱信息,即存储当前状态是由哪一个状态转移而来base和check是成对的,base[i]和check[i]代表同一个状态的属性假如当前状态为s,输入的字符为c,下一状态为t,则查询过程的约束条件为:check[base[s]+c]=s;base[s]+c=t。在本发明的一个实施例中,在每个key后面添加一个虚拟字符代表叶子结点(终端结点),每个叶子结点虚拟字符的存储位置由其直接前驱的base值确定。允许让每个key带上自己的属性值values(词性或者其他标注信息)。当前很多Trie树的实现版本,只能存储key,无法将key和key的属性或解释信息(统称为values)直接关联起来。本方法的解决方式是在每个key后面加一个虚拟字符“$”代表叶子结点(终端结点),使得原先的终端结点变为非终端结点,在其后增加一个终端结点“$”作为其直接后继。把每个叶子结点“$”(终端结点)的base值赋上其所处的key按词典顺序序号的相反数-m(m为当前key在所有词条集中的词典顺序序号,m能直接确定相关key对应的values的存储位置),每个叶子结点“$”的存储位置,直接由其直接前驱的base值确定,同时叶子结点的直接前驱定义为自己,即叶子结点的check值等于其状态编号即逻辑存储位置。使用一维数组代替双数组(base[]和check[]),此种方法的好处使得Trie树序列化和反序列化更加简单,使得词典的加载更加容易。具体做法可以将base数组放在一维数组的偶数位,check数组放在奇数位,对应关系如下:base[i]->>array[2*i];check[i]->>array[2*i+1].所述一维数组包括:一维数组的偶数位存放双数组的base值,一维数组的奇数位存放双数组的check值。在创建Trie树的过程中为了很好的避免因插入新状态导致冲突而引起的数据移动,要求所有信息按照key有序,才能够获取当前状态的所有直接后继状态的信息(如当前输入的字符c,该状态在Trie树的深度,直接后继状态包含的词条位置范围等)。为了方便,本发明实施例定义一个数据结构Node存储每个状态的信息,该数据结构用于在创建Trie树时存储新插入的状态信息,主要存储的信息说明包括:code存储的是当前的输入字符c,可以为c的Unicode值或者字节值,为了规避虚拟的终端结点“$”(终端结点的code为0),本方法定义每个code的值取字符c的Unicode值+1;depth当前状态在Trie树中的深度+1,即其直接后继在Trie树的深度(Trie树的根结点即初始结点定义为第0层);start第一个拥有当前状态key的编号;end最后一个拥有当前状态key的下一个编号;end-start为拥有当前状态key的数量,即这些key拥有共同的前缀。步骤S130,创建Trie树实现对词典数据的存储。如图3所示,是实现Trie树词典数据的存储流程,具体包括以下步骤:步骤S131,将所有词条和属性信息以key为中心按词典顺序排序,合并拥有相同key值的values,要保证key不存在重复;步骤S132,定义起始状态,编号为0,其包含的信息值为[code=0,depth=0,start=0,end=N],其中N为词典的规模,即key的数量;步骤S133,将起始状态放入双数组第0位置,将其base[0]=1(array[2*0]=array[0]=1),并标识base为1的值已经被占用(保证所有状态的base值唯一),check[0]=0(array[2*0+1]=array[1]=0);步骤S134,以起始状态作为当前状态;步骤S135,获取当前状态的所有直接后继状态的信息,若直接后继结点列表为空,即当前结点为终端结点“$”,表示从起始结点到当前结点构成的key恰好是词典中的一个完整词条,将当前结点(终端结点)的base值赋上当前key词典顺序序号的相反数,该路径上执行完毕;否则执行步骤S136;步骤S136,为当前结点寻找一个合适的base值,使得base值唯一,且不会导致所有直接后继结点与现有Trie树存储的结点冲突。依次将当前结点的直接后继结点插入Trie树中,并将其check值赋上当前结点的base值,再依次把当前结点的直接后继结点作为当前结点,跳转到步骤S135。如图4所示,Trie树在插入新结点的顺序是依次插入当前结点的直接后继结点,然后依次把当前结点的直接后继结点作为当前结点,递归执行插入操作,若当前结点没有后继结点,即当前结点为终端结点“$”,跳出当前递归,直至所有结点插入完毕,即可完成Trie树的创建操作。若把所有的结点(包括终端结点“$”)按照插入的顺序编号。本发明实施例提供一种基于一维线性空间实现Trie树的词典存储管理方法,该方法包括以下步骤:获取完整的词典数据;生成有序的词典数据并存放在一维数组中;创建Trie树实现对词典数据的存储。本发明采用一维数组代替双数组(base[]和check[]),本方法使得Trie树序列化和反序列化更加便捷,使得词典的加载存储更有效率,同时本发明可以解决双数组实现Trie树的词典数据存储方法中存在的数据移动或存储空间的回溯问题。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1