一种告警关联规则挖掘方法和装置与流程
本发明涉及通信
技术领域:
,具体涉及告警关联规则挖掘技术。
背景技术:
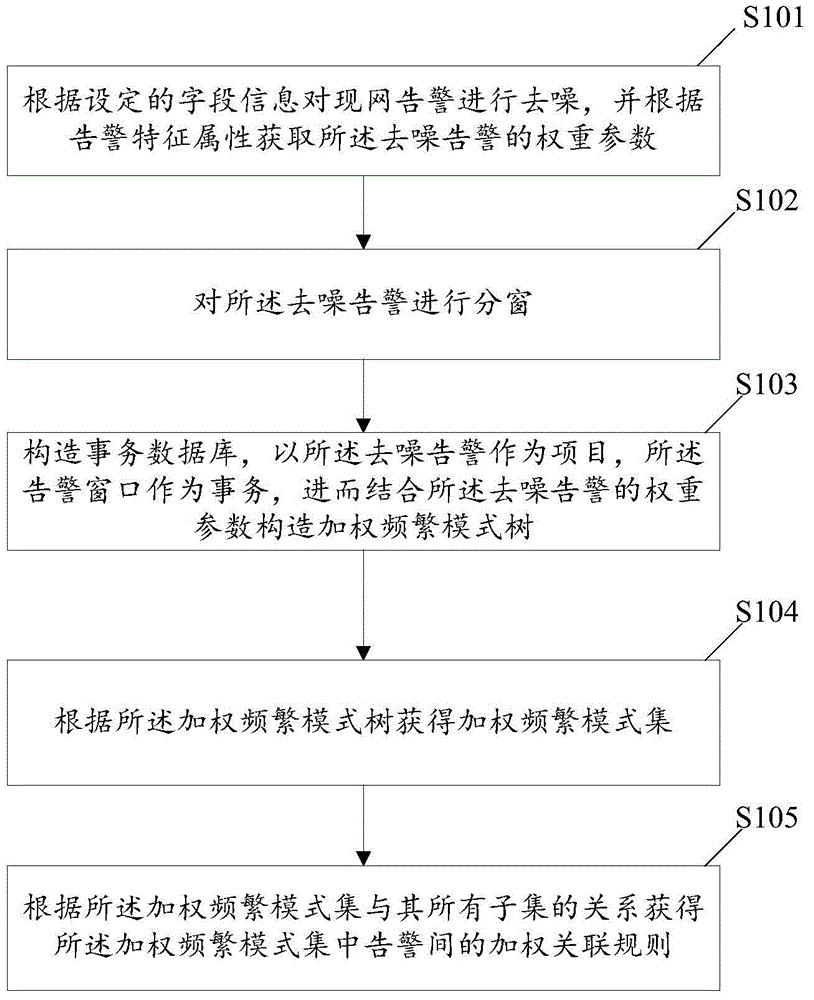
:电信运营商在经过了多年的网管系统建设、不断完善,在告警管理方面已经有了较为成熟的监控管理模式和告警数据的分析处理流程。电信网管系统的告警监控和管理模块,在日常运维工作中起到了重要的作用,成为运营商告警监控、管理和业务分析的必备工具。近来年数据挖掘技术在各行业都取得了令人瞩目的应用效果,通信行业中也是如此,尤其是在业务支撑领域已经有比较多的应用案例。在告警应用方面,运营商积累了大量的告警历史数据,其中可能包含大量的业务规则或逻辑,对告警相关的业务运营会有积极的帮助。以往由于没有较好的技术手段支持来处理体积巨大的告警历史数据,因此对告警数据中业务知识的挖掘也少有人尝试。目前电信网络中的告警关联规则一般是通过业务专家、运维专家基于积累的相关经验,进行总结提炼,先形成备选规则,经过专家团队讨论确定后,部分规则作为优选规则,实施现网验证,得到验证的规则最终进入告警关联规则库,在现网正式推广使用。这种人工方式获取现网有效关联规则的方法,本身存在效率不高,且依赖特定专家经验,使得有效告警关联规则的获取成本高,难以适应不断出现的新业务场景。由于新的业务网络基于多种新技术,且网络结构更加复杂,同时存在网络结构变化越来越频繁的趋势,原来依靠专家经验的方式越来越难以奏效,新的有效规则的获取变得越来越困难。不同类型网元、不同级别告警,或者其他因素可能导致告警数量分布存在差异,这种差异到使得告警规则挖掘的结果不能完全达到预期。因此,通过搭建系统依赖现网数据进行有效规则挖掘和获取的方法是很有实用价值的,也是电信运营商运维、监控用户急切需要的。综上所述一种基于现网数据实现自动分析并准确挖掘电信网络告警关联规则的技术亟待出现。技术实现要素:本发明提供一种告警关联规则挖掘方法,所述方法包括:根据设定的字段信息对现网告警进行去噪,并根据告警特征属性获取所述去噪告警的权重参数;对所述去噪告警进行分窗;构造事务数据库,以所述去噪告警作为项目,所述告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树;根据所述加权频繁模式树获得加权频繁模式集;根据所述加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。优选的,所述方法还包括:根据网元资源信息,获取所述去噪告警间的网元关系;根据所述去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤;根据过滤后的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。详细的,根据所述去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤的方法具体为:判断所述加权频繁模式集中的任意两个项目是否存在网元关系,如果不存在,则过滤所述加权频繁模式集。详细的,所述根据告警特征属性获取去噪告警的权重参数的方法具体为:根据所述去噪告警的告警级别和告警所属网元的网元类型计算所述去噪告警的权重参数。进一步的,所述构造事务数据库,以所述去噪告警作为项目,所述告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树的方法具体为:获取所述事务数据库中每个项目在事务数据库中的支持数和k支持期望,根据所述每个项目的支持数和k支持期望对所述事务数据库中的项目进行第一次过滤;设定最小建树支持度,计算所述事务数据库中每个项目的支持度与其权重参数的乘积,并结合预设的最小建树支持度对所述事务数据库中的项目进行第二次过滤;将所述经过两次过滤剩余的所述事务数据库中的每个事务按照事务中剩余项目的支持数降序排列;将所述降序排列的事务数据库按照fp-growth方法构造加权频繁模式树。进一步的,所述根据所述加权频繁模式树获得加权频繁模式集的方法具体为:扫描所述加权频繁模式树,计算树中每一个树枝的加权支持度,剪掉所述加权支持度小于预设加权支持度阈值的树枝;将所述剪枝后加权频繁模式树中的每一个树枝转化为一个加权频繁模式集,集合中的元素对应树枝的节点。优选的,所述方法还包括:根据预设规则深度删除所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集。详细的,所述根据所述加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则的方法具体为:获取所述每个加权频繁模式集的所有非空子集;计算所述加权频繁模式集与其各非空子集的置信度;当所述置信度大于预设的最小置信度时,由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。详细的,所述根据设定的字段信息对现网告警进行去噪的方法具体为:根据设定的字段信息删除字段数据不完整的告警、去除工程告警、去除非通信设备类告警、去除关联告警、去除轻微告警、去除重复告警。本发明还公开一种告警关联规则挖掘装置,所述装置包括:告警预处理单元,用于根据设定的字段信息对现网告警进行去噪,并根据所述告警特征属性获取所述去噪告警的权重参数;告警分窗单元,用于对所述告警预处理单元处理后的去噪告警进行分窗;加权频繁模式树构造单元,用于构造事务数据库,以所述告警预处理单元处理后的去噪告警作为项目,所述告警分窗单元确定的每个告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树;加权频繁模式集获取单元,用于根据所述加权频繁模式树构造单元构造的加权频繁模式树获得加权频繁模式集;关联规则获取单元,用于根据所述加权频繁模式集获取单元获取的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。优选的,所述装置还包括加权频繁模式集过滤单元:所述告警预处理单元,还用于根据所述设定的字段信息,获取所述去噪告警间的网元关系;所述加权频繁模式集过滤单元,用于根据所述告警预处理单元获取的去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤;和,根据预设规则深度过滤所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集;关联规则获取单元根据所述加权频繁模式集获取过滤单元过滤后的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。详细的,所述告警预处理单元进一步包括:告警去噪模块,用于根据设定的字段信息删除字段数据不完整的告警、去除工程告警、去除非通信设备类告警、去除关联告警、去除轻微告警、去除重复告警;告警权重计算模块,用于根据所述去噪告警的告警级别和告警所属网元的网元类型计算所述去噪告警的权重参数;网元关系获取模块,用于根据网元资源信息,获取所述去噪告警间的网元关系。详细的,所述加权频繁模式树构造单元进一步包括:项目过滤模块,用于获取所述事务数据库中每个项目在事务数据库中的支持数和k支持期望,根据所述每个项目的支持数和k支持期望对所述事务数据库中的项目进行第一次过滤;设定最小建树支持度,计算所述事务数据库中每个项目的支持度与其权重参数的乘积,并结合预设的最小建树支持度对所述事务数据库中的项目进行第二次过滤;事务排序模块,用于将经过所述项目过滤模块过滤剩余的所述事务数据库中的每个事务按照事务中剩余项目的支持数降序排列;加权频繁模式树构造模块,用于将经过所述事务排序模块排序的事务按照fp-growth方法构造加权频繁模式树。详细的,所述加权频繁模式集获取单元进一步包括:剪枝模块,用于扫描所述加权频繁模式树构造模块加权频繁模式树,计算树中每一个树枝的加权支持度,剪掉所述加权支持度小于预设加权支持度阈值的树枝;加权频繁模式集获取模块,用于将经过所述剪枝模块剪枝后的加权频繁模式树中的每一个树枝转化为一个加权频繁模式集,集合中的元素对应树枝的节点。详细的,所述关联规则获取单元进一步包括:子集获取模块,用于获取所述加权频繁模式集获取模块获取的每个加权频繁模式集的所有非空子集;置信度计算模块,用于计算所述加权频繁模式集与其各非空子集的置信度;规则成立判定模块,用于当所述置信度计算模块计算的置信度大于预设的最小置信度时,判定由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。基于不同类型网元、不同级别告警,或者其他因素可能导致告警规则挖掘的结果不准确,本发明首先对现网告警进行去噪和权重计算,去噪是排除了现网数据中不适合做规则挖掘的告警,如工程告警、轻微告警等,权重计算即考虑了类似于高级别的告警比低级别的告警影响程度更大的因素,能够获取更加准确的告警关联规则;进一步的,通过构建加权频繁模式树对告警规则进行挖掘,挖掘时考虑了权重和网元的资源关系,避免了“垃圾规则”的输出,提高了规则挖掘的准确定;另一方面建立树结构的好处是把事务数据库中的项都压缩到一棵树上,在找频繁项集时,不必重复扫描原始数据库,避免了大量的i/o开销,因此本发明实现了一种基于现网数据自动分析并准确挖掘电信网络告警关联规则的技术。附图说明图1为本发明实施例一提供的一种告警关联规则挖掘方法的流程示意图;图2为本发明实施例二提供的方法优选流程示意图;图3为本发明实施例三提供的办发明构建加权频繁模式树方法流程示意图;图4为本发明实施例四提供的本发明中获得加权频繁模式集的方法流程示意图;图5为本发明实施例五提供的方法流程示意图;图6为本发明实施例五提供的方法中构造加权频繁模式树示意图;图7为本发明实施例六提供的一种告警关联规则挖掘装置结构示意图;图8为本发明实施例七提供的装置结构示意图。具体实施方式以下将配合图式及实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。关联规则是表示数据库中一组对象之间某种关联关系的规则。数据项之间的关联,即一个事务中某些数据项的出现可以导出另一些数据项在同一事务中的出现。关联规则是形如的蕴含式,其中且下面如图1所示,给出本发明的实施例一阐述一种告警关联规则挖掘方法,所述方法包括:步骤s101:根据设定的字段信息对现网告警进行去噪,并根据告警特征属性获取所述去噪告警的权重参数。计算告警的权重参数是结合告警的一些属性来确定告警的重要性,如不同告警级别,业务和网元的影响程度不同,需要区别对待;不同的网元,由于管理业务的范围不同,重要性也不同;因此可结合告警级别和网元类型计算告警权重。也可根据实际需求选择其他告警属性来计算告警的权重,可令灵活选择。根据挖掘分析的需要和预处理的结果,待挖掘分析的告警其告警级别分为三个,1级(严重,critical);2级(重要,major);3级(次要,minor)网元类型也分为三类(每类给出了部分网元类型样例,其他未在本文描述的网元类型或者新增的网元类型,可同样方法处理),一类:msc/gmsc(101)/mscserver(130)/mgw(131)、hlr(102),hstp/lstp(108);二类:bsc(200)/rnc(9200)、bts(201)/nodeb(9201)、stp(108);三类:cell(300)/utracell(9300)。步骤s102:对所述去噪告警进行分窗。电信网络中不同设备厂家的告警会集中到网管系统中进行统一管理,对网管系统来说,告警数据就是时间上“无头无尾”的连续、流式数据,必须经过特殊处理后,才能挖掘告警间的关联关系。在此采用滑动窗口机制对告警数据进行“交易化”处理,也就是人为的从时间维度上对告警进行“分箱”处理,但不是简单的按照不同的时间点,把告警划入不同的窗口中,而是采用滑动窗口的方法,解决非滑动窗口方法存在的窗口边界告警关联关系可能丢失的问题。步骤s103:构造事务数据库,以所述去噪告警作为项目,所述告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树。步骤s104:根据所述加权频繁模式树获得加权频繁模式集。步骤s105:根据所述加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。为了更好的阐述本发明,下面给出本发明的实施例二,如图2所示:步骤s201:根据设定的字段信息对现网告警进行去噪,并根据告警特征属性获取所述去噪告警的权重参数。告警去噪,是指对告警数据进行清洗和过滤,告警原始数据中有一部分告警对于告警挖掘分析来说是噪声数据或者不需要的,需要将这些数据剔除。根据设定的字段信息删除字段数据不完整的告警、去除工程告警、去除非通信设备类告警、去除关联告警、去除轻微告警、去除重复告警。具体处理内容如下:a)对全量告警数据按照挖掘的需要过滤出必要的字段内容。如表1所示:表1告警必要字段示意字段名称字段缩写能否为空网元idint_id否网元类型object_class否告警标题idalarm_title否告警标题alarm_title_text否告警产生时间event_time否原始告警级别org_severity否厂家告警级别vendor_severity否告警类别org_type否告警清除时间cancel_time是告警活动状态active_status否omc_idomc_id否告警号omc_alarm_id否重定义级别redefine_severity否重定义类别redefine_type否集团告警级别group_severity否地市告警级别region_severity否告警子类型sub_alarm_type否资源状态resource_status否归属网元idparent_int_id否归属网元类型parent_object_class否厂家idvendor_id否厂家名称vendor_name否网元名称ne_lable否城市名称city_name否城市idcity_id否地区idregion_id否地区名称region_name否网络类型network_type否告警工程状态alarm_resource_status否专业类型professional_type否工单状态sheet_status否工单号sheet_no否逻辑告警分类logic_alarm_type是逻辑告警子类logic_sub_alarm_type是标准告警idstandard_alarm_id否告警对设备的影响effect_ne是告警对业务的影响effect_service是设备对象类型eqp_object_class否标准化标志standart_flag否网元名称ne_label否网元中文名称zh_label是b)去除不完整的告警数据,针对前面的告警挖掘分析字段列表,检查告警数据是否完整。根据表中能否为空的标识,判定告警数据是否完整,若能够为空的标识为“否”,则表示该字段不能为空,而告警的该字段为空,则表明该告警为不完整告警,需要去除。c)去除工程告警。工程告警对挖掘来说属于噪声数据,需要滤掉,根据上述表1中的“告警工程状态”字段判断该告警是否为工程告警。d)去除非通信设备类告警。比如:性能告警、网管采集层告警及其他网管模块自身产生的告警等,这些告警并非真正的设备告警,也需要过滤掉,根据上述表1中的“告警类型”字段进行判断。e)去除系统中生成的“关联告警”(非网元设备产生的告警)f)去掉“轻微”告警一般来说轻微告警不需要进行监控运维部门处理,不必要进行告警关联规则的挖掘分析,直接过滤掉该类告警,根据告警级别进行判断。g)剔除重复告警数据(对挖掘分析来说,属于重复的告警数据)重复的告警对告警关联规则的挖掘没有益处,但会增加处理的复杂性,也影响系统处理的效率,重复的告警只保留一条即可。告警的权重计算可以有很多种方式,再次本发明给出一种计算权重的方法,基于告警级别和网元类型进行权重计算。表1、表2、表3分别列出权重比:表1告警级别和网元类型的权重比项目\项目告警级别网元类型告警级别13网元类型1:31对比矩阵中的取值,表示列名称和行名称的重要性比值,比如:1:3(0.333333)表示网元类型比告警级别重要性低,取值关系为1/3。表2告警级别之间权重比项目\项目一级二级三级一级139二级1:313三级1:91:31表3网元类型之间权重比项目\项目一类二类三类一类139二类1:313三类1:91:31通过计算可获得不同种类告警权重(一共有9种):以告警类1为例进行说明进行计算:1、最底层的每一种告警,都有两条线获取权重:告警级别和网元类型,根据对比矩阵设计,告警级别权重0.75,网元类型权重为0.25(总权重取值加和为1)2、告警级别细分为三级,根据对比矩阵设计,计算得出三中基本告警权重分别为:一级告警(0.5192),二级告警(0.1731),三级告警(0.0577)。网元类型类似。举例:一级告警权重=0.75*(9/(9+3+1))≈0.5192。3、最终告警类1的权重计算过程如下:权重取值=(0.75*(9/(9+3+1))+0.25*(9/(9+3+1)))/3≈0.2308步骤s202:对所述去噪告警进行分窗。采用滑动窗口机制,主要涉及两个参数:窗口长度和滑动步长。窗口长度:属于经验数据,确定原则一般是窗口中告警数量不太多,且经过挖掘算法的处理得到规则数量适中,可现场试验确定。滑动步长:可取窗口长度的五分之一到十分之一左右。步骤s203:根据网元资源信息,获取所述去噪告警间的网元关系。根据网元业务关系提取资源数据中的“网元关系”,提取网元关系的依据如下:)网元之间存在传输链路连接;a)网元之间存在业务管理关系;b)网元之间存在供电关系;c)网元之间存在同址关系,比如:“位于相同机房”或“处于相同机楼”关系;形成网元关系集合,作为后续挖掘算法过滤的基础数据。对资源数据处理后网元关系集合,进行整理,可以形成网元关系库。如表4所示:表4网元关系库表示意步骤s204:构造事务数据库,以所述去噪告警作为项目,所述告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树。设i={i1,i2,,in}是n个不同项目的一个集合,ik,k=1,2,,n称为项目,d是事务数据库,d={t1,t2,,tk},其中tp,p=1,2,,k为集合i的子集,tp称为事务,d中任意的事务tp∈d,满足任一事务tp都有唯一的事务标识,记作tid。一般情况下,事务数据库d中包含多个事务,对告警执行分窗操作后,每个窗口被视为一个事务,位于每个窗口中的告警,被视为项目。因此事务数据库包含多个事务,每个事务包含多个项目,经过去噪和分窗操作后的告警即为事务数据库中的项目。结合告警的权重参数构造加权频繁模式树在一定程度上把事务数据库中的项目都压缩到了一颗树上,在下一步寻找频繁项集时,不需要重复扫描数据库,避免了大量的i/o开销。步骤s205:根据所述加权频繁模式树获得加权频繁模式集。加权频繁模式树上的每一个树枝即可视为一个加权频繁模式集。获得加权频繁模式树上的所有树枝,即获得了树上的所有加权频繁模式集,但考虑到实际的应用场景,在某些时候需要根据实际情况对获得的加权频繁模式集进行过滤。步骤s206:根据所述去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤。结合全网资源时,会发现告警所在的网元会存在各种关系,如表1中所述的4种关系,因此通过网元关系过滤出告警关联规则,应具有一定的准确性。判断所述加权频繁模式集中的任意两个项目是否存在网元关系,如果不存在,则过滤所述加权频繁模式集。经过上述判断,如果加权频繁模式集中有两个项目没有存在网元关系,则说明以该加权频繁模式集中的项目生成的告警关联规则有可能不准确,因此将该加权频繁模式集过滤掉。本过滤步骤是优选步骤,在通过网元关系过滤告警关联规则的基础上,还可以通过限定加权频繁模式集的长度进行过滤。结合具体的应用场景,需要得到的加权频繁模式集的长度不能过大,若加权频繁模式集的长度很大,那么由该加权频繁模式集生成的加权关联规则的解释性就很差,因此,在生成加权频繁模式集时,通过限制加权频繁模式集的长度来保证加权关联规则的可解释性。具体实施的方法是,根据预设规则深度删除所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集。步骤s207:根据过滤后的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。通过上述步骤后,可获知加权频繁模式集中各项目之间存在必然存在关联规则,因此可根据加权频繁模式集与其各子集关系获取加权关联规则,即获得了最终的告警关联规则。具体方法为:获取所述每个加权频繁模式集的所有非空子集。计算所述加权频繁模式集与其各非空子集的置信度。当所述置信度大于预设的最小置信度时,由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。为了更好说明本发明构造加权频繁模式树的步骤,下面给出本发明的实施例三,如图3所示:为了更好的解释加权频繁模式树的构造方法,需要对一些术语做出说明:支持度:假定x是一个项目集,d是一个事务数据库,称d中包含x的事务的个数与d中总的事务个数之比为x在d中的支持度(support)。x的支持度记作sup(x),而关联规则的支持度则记作sup(x∪y)。支持数:支持数=支持度*|d|置信度:对形如的关联规则,其中x和y都是项目集,事务集合d中既包含x也包含y的事务个数与d中仅包含x而不包含y的事务个数之比,或者说是项目集x∪y的支持度与x的支持度之比称为规则的置信度(confidence),既sup(x∪y)/sup(x),把规则的置信度记作加权支持度:加权关联规则的加权支持度wsup定义为:加权频繁模式集:给定最小加权支持度阈值wminsup,若k-项集x满足下列公式,则称x为k-加权频繁模式集:若k-项集x为k-加权频繁模式集,则x的支持数(sc)满足:一个包含y的k-项集的最大可能权重为:其中i为所有项目的集合,y为一q-项目集,其中,设在余下的i-y的项目中,权重最大的(k-q)个项目的权重分别为支持期望根据定理1和定理2,包含y的k-加权频繁项集的最小可能支持数为:称为y的k-支持期望。考虑到应取整数,为了保证包含y的k-项目集有可能是加权频繁的,取为大于的最小整数。加权置信度:加权关联规则的置信度的定义为:步骤s301:获取所述事务数据库中每个项目在事务数据库中的支持数和k支持期望,根据所述每个项目的支持数和k支持期望对所述事务数据库中的项目进行第一次过滤。根据上文中记载,支持数=支持度*项目数。如果项目的支持数小于k支持期望,则将该项目从数据库中删除。第一次过滤步骤为构建加权频繁树的常规过滤步骤,由于其过滤的力度较小,因此在步骤s302中结合权重进行更进一步的过滤。步骤s302:设定最小建树支持度,计算所述事务数据库中每个项目的支持度与其权重参数的乘积,并结合预设的最小建树支持度对所述事务数据库中的项目进行第二次过滤。建树支持度为项目的支持度与权重参数的乘积,如果该乘积小于最小建树支持度,则将该项目从数据库中删除。步骤s303:将所述经过两次过滤剩余的所述事务数据库中的每个事务按照事务中剩余项目的支持数降序排列。建树的目的是为了压缩数据库,因此需要将剩余的项目按照其支持数进行降序排列。步骤s304:将所述降序排列的事务数据库按照fp-growth方法构造加权频繁模式树。fp-growth建树算法,是较成熟的建树方法,按照常规的fp-growth建树方法对降序排列的事务数据库进行建树即可。为了更清晰说明本发明根据加权频繁模式树获得加权频繁模式集的方法,给出本发明的实施例四,如图4所示。步骤s401:扫描所述加权频繁模式树,计算树中每一个树枝的加权支持度,剪掉所述加权支持度小于预设加权支持度阈值的树枝。步骤s402:将所述剪枝后加权频繁模式树中的每一个树枝转化为一个加权频繁模式集,集合中的元素对应树枝的节点。根据这个步骤得到了加权频繁模式树中的所有树枝,为了使得获得的告警关联规则更加准确,可通过下面两个过滤步骤筛选出最终的加权频繁模式集。步骤s403:根据预设规则深度删除所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集。规则深度约定了加权频繁模式集中包含项目的个数,如果加权频繁模式集中包含的项目个数大于规则深度,会造成加权频繁模式集长度很大,生成的加权关联规则解释性差。规则深度根据经验和实际情况进行设定。步骤s404:判断所述加权频繁模式集中的任意两个项目是否存在网元关系,如果不存在,则过滤所述加权频繁模式集。经过上述4个步骤剩余的集合即为所求的加权频繁模式集。为了详细说明本发明公开的挖掘告警关联规则的方法,下面结合实例给出本发明的实施例五,如图5所示。首先给出一个告警事务数据库,在前面提到过,一条告警包含多个字段(如时间窗、网元类型、网元级别、告警级别等等),为避免描述困难,在描述挖掘加权关联规则时把一条告警抽项成一个带下标的i(如i1、i2、i4、i5,i1表示一条告警)。步骤s501:根据设定的字段信息对现网告警进行去噪,并根据告警特征属性获取所述去噪告警的权重参数,获取告警的网元关系。实例中涉及的告警权重如表5所示:表5告警权重示意告警weightsi10.1i20.3i30.4i40.8i50.9步骤s502:对所述去噪告警进行分窗。下表只列出了告警挖掘需要的部分字段,包括时间窗(这是区分不同事务的标志)、int_id-alarm_id(告警唯一标识)和权重,其他字段省略。)分窗口的告警数据如表6所示。表6原始告警事务数据库分窗示意步骤s503:构造告警事务数据库。将上述告警事务数据库转化成简化的告警事务数据库,如下表7所示:表7简化的告警事务数据库windows-id告警2014-04-3023:56:00-2014-05-0100:00:59i1i2i4i52014-04-3023:57:00-2014-05-0100:01:59i1i4i52014-04-3023:58:00-2014-05-0100:02:59i2i4i52014-04-3023:59:00-2014-05-0100:03:59i1i2i4i52014-05-0100:00:00-2014-05-0100:04:59i1i3i52014-05-0100:01:00-2014-05-0100:05:59i2i4i52014-05-0100:02:00-2014-05-0100:06:59i2i3i4i5其中i1:-109_601-075-00-075002(int_id-alarm_id为告警唯一标识,所以这里用它来代表一条告警)、i2:-109_603-070-00-070011、i3:932827395_ff-1932858163、i4:-109_602-076-00-076010、i5:-155110151_ff-29254771。步骤s504:给定输入阈值。给定输入阈值:最小建树支持度=0.01、最小加权支持度=1、规则深度=4、最小置信度=0.7。步骤s505:扫描简化告警事务数据库d,计算每个项目的支持数和k-支持期望,删除支持数小于k-支持期望的告警。扫描简化告警事务数据库d,|d|=7。计算每个项目的支持数:i1:4/7*|d|=4i2:5/7*|d|=5i3:2/7*|d|=2i4:6/7*|d|=6i5:7/7*|d|=7计算每个项目的k支持期望:对i1:所以,bmin(i1)=4=sc(i1)=4对i2:所以有,bmin(i2)=3<sc(i2)=5所以i2是加权潜在1-模式。对i3:所以,bmin(i3)=3>sc(i3)=2删除i3。对i4,i5做同样的计算,均不用删除。获得i1,i2,i4,i5。步骤s506:计算每条告警的支持度与对应权重的乘积并与最小建树支持度比较,删除低于最小建树支持度的告警。support(i1)*weight(i1)=4/7*0.1=0.0285support(i2)*weight(i2)=0.2142同理,计算i4、i5对应的值,都高于最小建树支持度,不删除告警。这步过滤条件是后来在第一步过滤条件的基础上加的,由于告警权重的设计方法,所有的告警权重只有9种,这影响到k-支持期望的过滤效果不明显,在实际应用中,k-支持期望几乎不能起到过滤的作用,但k-支持期望的过滤在理论上又是必须的,所以在其过滤后在进行这步过滤,目的是真正起到过滤告警的作用,这步过滤既考虑到告警的支持度又考虑到告警的权重,因此,这步过滤是有效而且具有实际意义。步骤s507:将过滤后的告警事务数据库中的每条事务按支持数降序排列。如表8所示:表8降序排列的告警事务数据库windows-id告警2014-04-3023:56:00-2014-05-0100:00:59i5i4i2i12014-04-3023:57:00-2014-05-0100:01:59i5i4i12014-04-3023:58:00-2014-05-0100:02:59i5i4i22014-04-3023:59:00-2014-05-0100:03:59i5i4i2i12014-05-0100:00:00-2014-05-0100:04:59i5i12014-05-0100:01:00-2014-05-0100:05:59i5i4i22014-05-0100:02:00-2014-05-0100:06:59i5i4i2步骤s508:将所述降序排列的事务数据库按照fp-growth方法构造加权频繁模式树。生成的加权频繁模式树如图6所示。步骤s509:根据最小加权支持度给加权频繁模式树剪枝。计算加权频繁模式树中每一个树枝的加权支持度,并与给定阈值比较,小于给定阈值的树枝剪掉。先算以i1为底端节点的树枝,i1出现在wfp树中的3个分支。这些路径分别是<(i5i4i2:2)>、<(i5:1)>、<(i5i4:1)>。分别计算这些树枝的加权支持度并与最小加权支持度比较所以i1为底端节点的树枝被剪掉。步骤s510:将剪枝后加权频繁模式树中的每一个树枝转化为一个加权频繁模式集。获得集合{i5i4i2}与集合{i5i4}。步骤s511:根据规则深度过滤加权频繁模式集。规则深度为4,两个加权频繁模式集均未超出规则深度。步骤s512:根据网元关系过滤加权频繁模式集。查询上述步骤中获取的网元关系,发现i2,i4,i5两两间均存在网元关系。步骤s513:获取所述每个加权频繁模式集的所有非空子集集合{i5i4i2}的所有非空子集为{i2},{i4},{i5},{i2,i4},{i2,i5},{i4,i5}集合{i5i4}的所有非空子集为{i4},{i5}步骤s514:计算所述加权频繁模式集与其各非空子集的置信度。规则一:规则二:规则三:规则四:规则五:规则六:规则七:规则八:步骤s515:当所述置信度大于预设的最小置信度时,由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。由于最小置信度设定为0.7,因此上述八条规则均符合条件,运用本发明共挖掘出8条告警关联规则。本发明还提供一种告警关联规则挖掘装置用以实现一种告警关联规则挖掘方法,下面给出本发明的实施例六用以说明所述装置的具体结构,如图7所示。一种告警关联规则挖掘装置包括:告警预处理单元1,用于根据设定的字段信息对现网告警进行去噪,并根据所述告警特征属性获取所述去噪告警的权重参数。告警预处理单元根据上文中方法的告警预处理方法,对告警进行去噪,详细过程参见上文描述。告警分窗单元2,用于对所述告警预处理单元1处理后的去噪告警进行分窗。告警分窗单元根据上文中方法的告警分装方法,对告警进行分窗,详细过程参见上文描述。加权频繁模式树构造单元3,用于构造事务数据库,以所述告警预处理单元1处理后的去噪告警作为项目,所述告警分窗单元2确定的每个告警窗口作为事务,进而结合所述去噪告警的权重参数构造加权频繁模式树。一般情况下,事务数据库d中包含多个事务,对告警执行分窗操作后,每个窗口被视为一个事务,位于每个窗口中的告警,被视为项目。因此事务数据库包含多个事务,每个事务包含多个项目,经过去噪和分窗操作后的告警即为事务数据库中的项目。通过将告警作为项目,告警窗口作为事务构造的事务数据库,构建加权模式树,将这些项目都压缩到一棵树上,避免了多余的开销,能够提高效率。加权频繁模式集获取单元4,用于根据所述加权频繁模式树3构造单元构造的加权频繁模式树获得加权频繁模式集。加权模式树上的每一个树枝即可为一个加权模式集。获得加权频繁模式树上的所有树枝,即获得了树上的所有加权频繁模式集,但考虑到实际的应用场景,在某些时候需要根据实际情况对获得的加权频繁模式集进行过滤。可以根据告警所属的网元关系进行过滤,也可以根据规则深度进行过滤。具体实现方法请参见上文中的方法描述,在此不再赘述。关联规则获取单元5,用于根据所述加权频繁模式集获取单元4获取的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。根据加权频繁模式集获取加权关联规则的方法为:获取所述每个加权频繁模式集的所有非空子集。计算所述加权频繁模式集与其各非空子集的置信度。当所述置信度大于预设的最小置信度时,由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。为了进一步保证挖掘的告警关联规则的准确性,告警预处理单元,还用于根据所述设定的字段信息,获取所述去噪告警间的网元关系。优选的,所述装置还可以包括:加权频繁模式集过滤单元6,用于根据所述告警预处理单元1获取的去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤;和,根据预设规则深度过滤所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集。关联规则获取单元5根据所述加权频繁模式集获取过滤单元过滤后的加权频繁模式集与其所有子集的关系获得所述加权频繁模式集中告警间的加权关联规则。本发明中关于构造加权频繁模式树时使用到的一些定义和公式均参见上文方法描述中的相关部分,在此不再赘述。为了更详细的说明本发明一种告警关联规则挖掘装置各部分的结构,给出本发明的实施例七,如图8所示。告警预处理单元1进一步包括:告警去噪模块11,用于根据设定的字段信息删除字段数据不完整的告警、去除工程告警、去除非通信设备类告警、去除关联告警、去除轻微告警、去除重复告警。设定的字段信息参见上文中表1所示。去噪的方法也参见上文中方法描述的相关部分。告警权重计算模块12,用于根据所述去噪告警的告警级别和告警所属网元的网元类型计算所述去噪告警的权重参数。网元关系获取模块13,用于根据网元资源信息,获取所述去噪告警间的网元关系。告警分窗单元2,用于对所述告警预处理单元1处理后的去噪告警进行分窗。加权频繁模式树构造单元3进一步包括:项目过滤模块31,用于获取所述事务数据库中每个项目在事务数据库中的支持数和k支持期望,根据所述每个项目的支持数和k支持期望对所述事务数据库中的项目进行第一次过滤;设定最小建树支持度,计算所述事务数据库中每个项目的支持度与其权重参数的乘积,并结合预设的最小建树支持度对所述事务数据库中的项目进行第二次过滤;事务排序模块32,用于将经过所述项目过滤模块31过滤剩余的所述事务数据库中的每个事务按照事务中剩余项目的支持数降序排列;加权频繁模式树构造模块33,用于将经过所述事务排序模块32排序的事务按照fp-growth方法构造加权频繁模式树。加权频繁模式集获取单元4进一步包括:剪枝模块41,用于扫描所述加权频繁模式树构造模块加权频繁模式树,计算树中每一个树枝的加权支持度,剪掉所述加权支持度小于预设加权支持度阈值的树枝;加权频繁模式集获取模块42,用于将经过所述剪枝模块剪枝后的加权频繁模式树中的每一个树枝转化为一个加权频繁模式集,集合中的元素对应树枝的节点。关联规则获取单元5进一步包括:子集获取模块51,用于获取所述加权频繁模式集获取模块42获取的每个加权频繁模式集的所有非空子集。置信度计算模块52,用于计算所述加权频繁模式集与其各非空子集的置信度。规则成立判定模块53,用于当所述置信度计算模块52计算的置信度大于预设的最小置信度时,判定由所述加权频繁模式集与其对应的非空子集生成的加权关联规则成立。加权频繁模式集过滤单元6,用于根据所述告警预处理单元1获取的去噪告警间的网元关系,对所述获得的加权频繁模式集进行过滤;和,根据预设规则深度过滤所述加权频繁模式集的长度超过所述规则深度的加权频繁模式集。告警去噪模块11对告警进行清洗和去噪后,告警权重计算模块12获取告警的权重,网元关系获取模块13获取告警间的网元关系;告警分窗单元2对告警进行分窗形成项目,加权频繁模式树构造单元3根据去噪后的告警结合告警的权重,通过项目过滤模块31、事务排序模块32、加权频繁模式树构造模块33完成对项目的过滤、事务的排序以及加权频繁模式树的构造;加权频繁模式集获取单元4通过剪枝模块41、加权频繁模式集获取模块42,对加权频繁模式集进行过滤后获得最终的加权频繁模式集;加权频繁模式集过滤单元6对加权频繁模式集进行进一步过滤;关联规则获取单元5通过自己获取模块51获取加权频繁模式集中的非空子集,置信度计算模块52计算这些子集的置信度,规则成立判定模块53通过将置信度与预设的最小置信度比较来判定最终成立的加权关联规则。通过本装置可以实现加权告警进行运算,且可以根据实际情况设置不同阶段的过滤步骤,基于现网数据实现自动分析并准确挖掘电信网络告警关联规则。本装置用以实现一种告警关联规则挖掘方法,各模块的工作原理在上文方法描述中均有相对应的描述,在此不再赘述。虽然本发明所揭露的实施方式如上,然而所述的内容并非用以直接限定本发明的保护范围。任何本发明所属
技术领域:
中技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作些许的更动。本发明的保护范围,仍须以所附的权利要求书所界定的范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1