去除DNA解链分析中的荧光背景的量子方法与流程
本申请要求2013年8月30日提交的题为“去除dna解链分析中的荧光背景的量子方法”的美国临时申请第61/872,173号的优先权及权益,该临时申请以全文并入本文。
发明背景
螺旋度是对双链形式的核酸部分的量度。利用260nm测量值的增色效应的经典吸光度测量法使用了简单的基线外推和归一化来生成与螺旋度预测紧密相配的解链曲线。吸光度解链曲线是dna螺旋度的“金标准”,但它们需要相对大量的dna(μg级)以及0.1-1.0℃/min的解链速率。用于dna解链的荧光方法近来变得流行,部分原因是它们可以使用显著更少量的核酸,并且可以经常在pcr混合物上实施,通常是在同一实时pcr仪器中。由荧光监控生成的解链曲线的优点还包括它们的生成速率比吸光度测量法快60倍。虽然吸光度方法被认为是金标准,但荧光解链曲线已经获得广泛使用。然而,使用荧光方法生成的解链曲线受存在的染料的影响。
用于分析dna序列变异的方法可以分成两个大体的类别:1)对已知序列变异体进行基因分型,和2)扫描未知变异体。用于对已知序列变异体进行基因分型的方法有许多,可以使用利用荧光探针的单步、均相、闭管方法(laymj等人,clin.chem1997;43:2262-7)。相比之下,大多数用于未知变异体的扫描技术都需要在pcr之后凝胶电泳或柱分离。这些包括单链构象多态性(oritao等人,procnatlacadsciusa1989;86:2766-70)、杂双链体迁移(natarajaj等人,electrophoresis1999;20:1177-85)、变性梯度凝胶电泳(abramses等人,genomics1990;7:463-75)、温度梯度凝胶电泳(wartellrm等人,jchromatogra1998;806:169-85)、酶或化学切割方法(taylorgr等人,genetanal1999;14:181-6)以及dna测序。通过测序识别新突变也需要在pcr之后的多个步骤,即循环测序和凝胶电泳。变性高性能液相色谱(xiaow等人,hummutat2001;17:439-74)包括将pcr产物注入柱中。大量平行测序需要多个步骤和昂贵的仪器装备,并且与在pcr之后无任何额外处理的一或二分钟的解链曲线相比运转周期很长。
单核苷酸多态性(snp)是目前在人类及其他物种中观察到的最常见的遗传变异。在这些多态性中,在个体之间仅单个碱基变化。该改变可以引起蛋白质中氨基酸变化,改变转录的速率,影响mrna剪接,或者对细胞过程无明显作用。有时候,当变化是沉默的(例如当它编码的氨基酸不变时),如果所述改变与另一遗传改变所引起的独特的表型有关联(有关),则snp基因分型可能仍是有价值的。
用于snp基因分型的方法有许多,大多数使用pcr或其他扩增技术以扩增所感兴趣关心的模板。可以使用同时发生或随后的分析技术,包括凝胶电泳、质谱和荧光。有吸引力的荧光技术是均相并且在开始扩增后不需要添加试剂或为了分析对反应物进行物理取样。示例性均相技术使用寡核苷酸引物以定位感兴趣区域和用于生成信号的荧光标记或染料。各种基于pcr方法都是完全闭管的,使用对dna变性温度稳定的热稳定酶,以使得加热开始之后不需要添加物。
数个闭管、均相、荧光pcr方法可适用于对snp进行基因分型。这些包括使用具有两个互相作用的生色团的fret寡核苷酸探针(相邻杂交探针、taqmantm探针、分子信标、scorpions)、具有仅一个荧光团的单寡核苷酸探针(g-猝灭探针,crockett,a.o.和c.t.wittwer,anal.biochem.2001;290:89-97和simpleprobes,biofirediagnostics)的系统,以及使用dsdna染料而不是共价的、荧光标记的寡核苷酸探针的技术。
用dsdna荧光染料监控dna解链的pcr方法连同实时pcr已经普及。因为pcr产生足够用于荧光解链分析的dna,且扩增和分析二者可以在同一试管中实施,从而提供不需要加工或分离步骤的均相、闭管系统。dsdna染料一般用于通过它们的解链温度或tm来识别产物。
dna解链分析的效力取决于其分辨率。用于基因扫描的高分辨率解链分析主要依靠pcr产物的解链过渡(meltingtransition)的形状。在很多情况下,解链过渡的高分辨率分析还可以无探针的基因分型。通过使用标记或未标记的探针,能够获得在较小区域针对变异体区分的实际更高的特异性。特定基因分型是通过使探针下的序列改变与探针tm的变化相关联来推断。随着染料和仪器装备方面新近的进步,可同时在一个反应中任选地实施使用未标记探针的高分辨率基因扫描和基因分型(美国专利第7,582,429号,全文以引用方式并入本文)。可以在饱和dna染料存在下观察到pcr产物和探针解链过渡二者。除筛选pcr产物中引物之间的任何序列变异之外,常见的多态性和突变也可以被基因分型。此外,无偏、分层聚类可以准确地将解链曲线分组成基因型(美国专利第8,296,074号,全文以引用方式并入本文)。一个、两个或甚至更多未标记探针可用在单个pcr中。
在同步基因分型和扫描中,产物解链分析检测两个引物之间任何位置的序列变异,而探针解链分析识别探针下的变异。如果序列变异在引物之间并且在探针下,可获得变异的存在和其基因型二者。如果产物解链显示变异但探针没有,则变异可能发生在引物之间而不是在探针下,并且可能需要用于基因分型的进一步分析。探针可以置于共有序列变异的位点以使得在大多数情况下,如果产物扫描是阳性,则探针将识别序列变异,从而大幅降低对测序的需求。用一个探针,可以通过pcr产物和探针解链二者确立snp的基因型。用两个探针,可以探究序列的两个单独区域的基因分型,并且针对pcr产物的其余扫描稀有序列变异。如果探针的解链温度不同并且如果各等位基因存在独特的探针和/或产物解链图谱,可以使用多个探针。
同步基因分型和扫描以及使用解链分析的其他基因分型技术是有前景的研究领域。然而,在高分辨率能力前的解链曲线分析缺乏特异性和准确性。随着高分辨率解链曲线分析的出现,背景荧光噪音可妨碍使用解链曲线准确地对snp进行基因分型、检测序列变异和检测突变。与扩增子有关,先前的背景荧光去除技术已经导致一些错误的调用(call)。例如,基线技术使用线性外推作为用于归一化解链曲线和去除背景荧光的方法。这种技术适用于标记的探针。然而,这种技术及其他先前归一化技术不如使用未标记的探针(zhoul,myersan,vandersteenjg,wangl,wittwerct.closed-tubegenotypingwithunlabeledoligonucleotideprobesandasaturatingdnadye.clinchem.2004;50:1328-35),多重小扩增子解链(liewm,nelsonl,margrafr,mitchells,eralim,maor,lyone,wittwerct.genotypingofhumanplateletantigens1-6and15byhigh-resolutionampliconmeltingandconventionalhybridizationprobes.jmoldiag,2006;8:97-104),以及组合的扩增子和未标记探针解链(zhoul,wangl,palaisr,pryorr,wittwerct.)high-resolutionmeltinganalysisforsimultaneousmutationscanningandgenotypinginsolution.clinchem2005;51:1770-7,据此以引用方式并入),它们也不如用于小扩增子。这是至少部分是因为未标记探针和小扩增子解链方法经常需要在比通常对于在80-95℃下的标准扩增子解链更低的温度(40-80℃)下的背景扣除。在这些较低温度下,低温基线不是线性的,反而是在低温快速增加荧光的曲线。当使用线性外推时,所述线可在解链过渡完成之前相交,并且当这发生时,现有技术部分由于它们对绝对荧光值的数学依赖,而无法提供最准确方式的解链曲线分析。
指数方法已经提供与基线方法相比显著的优点(美国专利第8,068,992号,以引用方式并入本文)。然而,指数方法经常引起低温畸变,该低温畸变可导致错误的调用。需要更准确地反映螺旋度的系统和方法。此系统和方法的优势有通过使用高分辨率解链谱图技术在双链核酸以高准确度对snp进行基因分型、检测序列变异和/或检测突变。如果背景荧光可以自动并且准确地从双链核酸样品解链谱图分离,则将更具优势。如果系统和方法利用未标记探针并且针对小扩增子和大扩增子实施准确的解链曲线分析,则其更具优势。
技术实现要素:
本公开涉及一种从使用荧光染料生成的解链曲线去除背景的新颖的方法。在一个实施方案中,提供了一种用于分析核酸样品的解链谱图(profile)的方法,该方法包括:作为温度的函数测量核酸样品的荧光以产生具有解链过渡的原始解链曲线,该核酸样品包含核酸和结合核酸以形成通过荧光可检测的络合物的分子,该原始解链曲线包括背景荧光信号和核酸样品信号;和使用量子算法将背景信号从核酸样品信号中分离以生成校正的解链曲线,所述校正解链曲线包括核酸样品信号。
示例性地,量子方法可以包括分离步骤,该分离步骤包括将来自所述原始解链曲线的初始x轴和初始y轴重新标度至:
x=(1/t-1/t参考)(°k)和
y=ln(i/i参考)
其中
t参考是参考温度,并且
i参考是分子在参考温度下参考荧光的强度。可以理解,分离步骤还可以包括计算第一条线h(t)(在解链过渡之前计算)和第二条线l(t)(在解链过渡之后计算)。分离步骤还可以包括重新标度回初始x轴和初始y轴。任选地,该方法可以包括按比例计算解链曲线的步骤。
在另一示例性实施方案中,提供了一种用于分析核酸样品的系统,该系统包括:加热系统,该加热系统加热通过荧光可检测的络合物同时监控其荧光,该络合物包含核酸和指示双链核酸的荧光分子,该系统经调试以测量并记录样品温度和样品荧光以作为样品温度函数而测定样品荧光以产生解链谱图,该解链谱图包括背景荧光信号和样品荧光信号;中央处理单元(cpu),该cpu用于执行计算机可实施的指令;和记忆存储装置(memorystoragedevice),该记忆存储装置用于存储计算机可执行的指令,当cpu执行该计算机可执行指令时,引起cpu实施分析核酸的程序,其中该程序包括:借助于量子算法将背景荧光信号从解链谱图中分离以生成校正的解链曲线,该校正的解链曲线包括样品信号。
当考虑以下关于例示目前认知的实施本发明的最佳方式的优选实施方案的详细说明时,本发明的额外特征对于本领域技术人员将变得明显。
附图说明
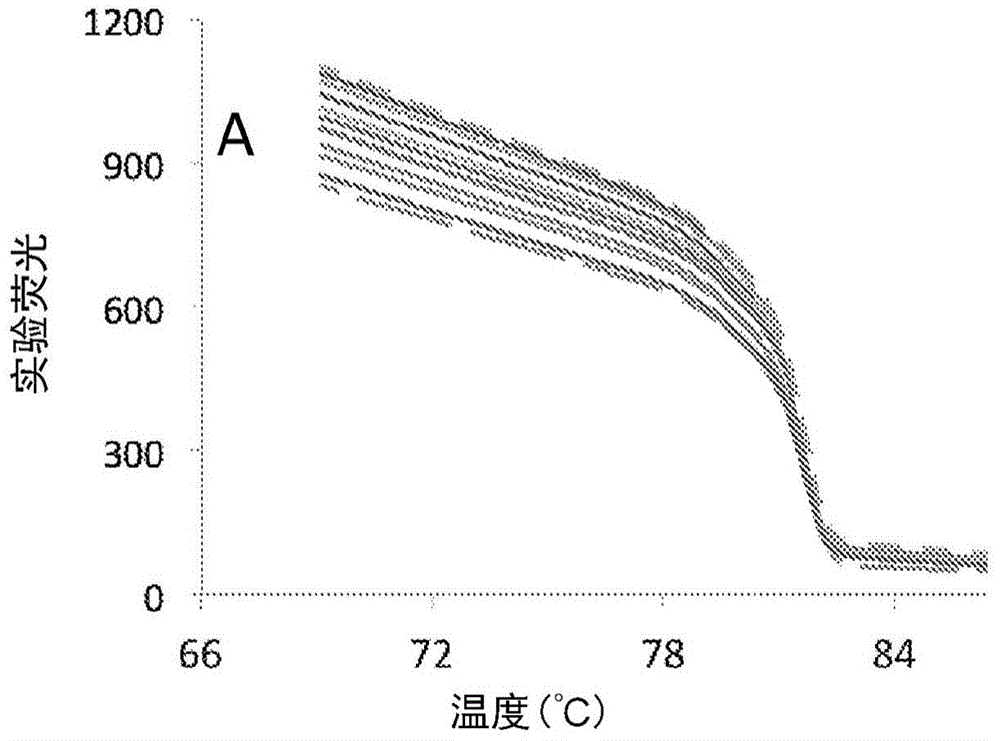
图1a-图1b示出归一化和背景去除的不同状态,包括(图1a)实验数据和(图1b)在0-100%之间归一化的实验数据(短虚线/长虚线)和所预期的解链过渡(黑色)。预期的解链曲线与归一化实验数据叠加,以更好地显示形状差异。
图2a-图2d示出量子方法的图示。图2a示出原始实验数据(黑色),而图2b以°k示出用y轴=ln(i/i参考)和x轴=1/t参考–1/t转换的相同数据(黑色)。当计算并且扣除温度倒数值时,产生数量级为10-5的十进制值,因此相应地标度图2b。上部(深灰色)和下部(浅灰色)线性拟合对应于起始(100%螺旋度)状态和最终(0%螺旋度)状态。h(t)的公式是y=-4422.7x+0.0004,并且l(t)的公式是y=-3272.6x–1.475。然后将数据重绘制在图2c中的初始荧光和温度(℃)轴上。使用公式m(t)=f(t)–l(t)/h(t)–l(t)由图2c计算最终解链曲线(图2d),以在0-100%之间归一化。
图3a-图3c示出荧光解链分析中使用的背景去除算法的比较。示出基线(图3a)方法、量子(图3b)方法和指数(图3c)方法。各行中的左图以黑色示出原始实验解链数据f(t),以及以灰色示出计算的背景信号(l(t)、h(t)和b(t)(视情况而定)。在去除背景之后,示出各方法的归一化的解链曲线(中图)和负导数图(右图)。使用公式m(t)=f(t)–l(t)/h(t)–l(t)计算基线和量子方法的解链曲线。指数方法使用公式m(t)=f(t)-b(t),用于解链曲线计算。背景去除方法之间的差异在较低温度下最明显。
图4a-图4b示出使用合成发夹结构和未标记探针的不同的背景去除方法的比较。图4a示出8bp茎发夹结构的结果,而图4b示出具有1:10链比率的13碱基未标记探针的结果。基线方法用于吸光度数据(黑色)的背景去除。使用量子(浅灰色)方法或指数(深灰色)方法分析荧光解链曲线数据。
图5a-图5c示出由吸光度或荧光监测的合成dna发夹结构解链曲线的比较。示出三种茎长的结果:图5a示出4bp茎的结果,图5b示出6bp茎的结果,图5c示出12bp茎的结果,8bp茎的结果在图4a中示出。在使用量子(浅灰色)或指数(深灰色)荧光方法分析之后的荧光数据作为负导数图显示,并且与用基线方法分析的吸光度数据(黑色)比较。
图6a-图6b示出以改变的比率与较小的序列匹配的未标记探针(13bp)组合的互补合成dna链(各44bp)的负导数解链图。正向链和反向链比率为1:5(图6a)和1:8(图6b),以模拟非对称pcr。1:10链比率在图4b中示出。探针的浓度与最高丰度的链相等,以模拟未标记的探针解链分析。在各图中,杂交的未标记探针区域在左边(较低温度),并且全长双链扩增子在右边(较高温度)。基线方法用于吸光度解链曲线(黑色)的背景扣除。使用量子(浅灰色)方法或指数(深灰色)方法分析荧光解链曲线。
图7a-7b示出在温度叠加之前(图7a)和之后(图7b)在合成的50bp双链上对不同背景去除方法的比较。量子(中度灰色)方法和指数(深灰色)方法用于从以0.3℃/s获得的荧光数据去除背景。基线方法用于归一化以1℃/min获得的吸光度数据(黑色)。使用web应用umelt生成预测的解链过渡(浅灰色)。
图8a-图8b示出利用未标记探针的fv基因分型试验,该试验使用量子(图8a)和指数(图8b)背景去除方法分析。示出野生型(中度灰色)解链曲线、杂合子(深灰色)解链曲线和变异体(浅灰色)解链曲线。
图9a-图9b示出使用量子(图9a)方法和指数(图9b)方法分析的使用回转引物(snapbackprimer)的基因分型数据。基因分型包括野生型(中度灰色)、杂合子(深灰色)和纯合子变异体(浅灰色)。
图10a-图10b示出多重解链曲线,该多重解链曲线示出hfe基因的p.c282y、p.h63d、p.s65c和c.t189c变异基因座的同步检测。扩增子和探针区域用粗体表示,箭头标记了不同基因型的特征峰。插图示出与h63d、s65c和t189c变异有关的利用h63d探针(点虚线)的全长扩增子(虚线)。使用量子(图10a)方法和指数(图10b)方法分析数据。
图11a-图11b示出f5、f2和mthfr在五重基因分型试验中的解链曲线。四种变异为f5(c.1601g>a,legacy1691g>a,rs6025)、mthfr(c.1286a>c,legacy1298a>c,rs1801131)、mthfr(c.665c>t,legacy677c>t,rs1801133)和f2(c.*97g>a,legacy20210g>a,rs1799963)。使用量子(图11a)方法或指数(图11b)方法分析数据。基因座和温度控制(temperaturecontrol)以粗体示出。
图12例示根据本公开的方面的热循环系统的示例性实施方案的方框图。
图13a-图13f示出其中在转换轴上观察到基线相交的稀有情况的校正。图13a、图13c和图13e示出根据公式3的解链数据曲线,为了便于观看而逆用参考值,而图13b、图13d和图13f示出校正的解链曲线。图13c-图13d示出添加至初始数据的500荧光单位的偏移,而图13e-图13f示出添加至初始数据的750荧光单位。
发明详述
如本文使用,术语“a”、“an”和“the”定义为指一个或多个,并且包括复数,除非上下文不合适。范围在本文可以如下表述:从“约”一个具体值,和/或至“约”另一具体值。本文使用术语“约”表示大概、左右、粗略或大约。当术语“约”用于数值范围时,它通过扩张界限高于或低于所述数值来修饰该范围。一般而言,本文使用术语“约”修饰高于及低于所述值5%偏差的数值。当表述此范围时,另一实施方案包括从一个具体值和/或至另一具体值。类似地,当通过使用先行词“约”将数值表述为近似值时,将理解该具体值形成另一实施方案。还可理解的是,每一个范围的端点均相对于另一终点是显著的,并且独立于另一终点。
如本文使用的词语“或”指具体列表中的任何一员,并且还包括该列表中成员的任意组合。
“样品”指如本文所述被试验的动物;来自动物的组织或器官;细胞(受试者内、直接取自受试者或者保持在培养基中的细胞或来自培养细胞系的细胞);细胞裂解物(或裂解物级分)或细胞提取物;含有来源于细胞、细胞物质或病毒物质的一种或多种分子(例如多肽或核酸)的溶液;或含有非天然存在核酸的溶液。样品还可以为含有细胞、细胞成分或核酸的任何体液或排泄物(例如但不限于,血液、尿、粪便、唾液、眼泪、胆汁)。
如本文使用的短语“核酸”是指能够通过沃森-克里克碱基配对与互补核酸杂交的天然存在或合成的寡核苷酸或多核苷酸,无论是dna或rna或dna-rna杂交体、单链或双链、正义或反义。本发明的核酸还可以包括核苷酸类似物(例如brdu)和非磷酸二酯核苷间连接(例如肽核酸(pna)或硫代二酯连接)。特别地,核酸可以包括而不限于dna、rna、cdna、gdna、ssdna、dsdna或它们的任意组合。
“探针”、“引物”或“寡核苷酸”指可以与含有互补序列(“靶”)的第二dna或rna分子碱基配对的定义序列的单链dna或rna分子。所得杂交体的稳定性取决于长度、gc含量和发生碱基配对的程度。碱基配对的程度受以下参数的影响,诸如探针与靶分子之间互补的程度以及杂交条件的严谨性程度。杂交严谨性的程度受以下参数的影响,诸如温度、盐浓度和诸如甲酰胺的有机分子的浓度,并且通过本领域技术人员已知的方法测定。探针、引物和寡核苷酸可以通过本领域技术人员熟知的方法而被可检测地标记(放射性、荧光或非放射性)。dsdna结合染料(结合至dsdna时的荧光强于结合至单链dna或游离在溶液中时的强度染料)可用于检测dsdna。可以理解的是,“引物”被特异性配置以通过聚合酶延伸,然而“探针”或“寡核苷酸”可以被或不被如此配置。
“特异性杂交”指探针、引物或寡核苷酸在高严谨条件下识别基本互补的核酸(例如样品核酸)并且与之物理互相作用(即碱基配对),并且基本不与其他核酸碱基配对。
“高严谨条件”指可以产生与以下条件产生的杂交相当的杂交的条件:使用长度至少40个核苷酸的dna探针,在含有0.5mnahpo4、ph7.2、7%sds、1mmedta和1%bsa(级分v)的缓冲剂中,在65℃的温度下,或者在含有48%甲酰胺、4.8xssc、0.2mtris-cl、ph7.6、1xdenhardt’s溶液、10%葡聚糖硫酸酯和0.1%sds的缓冲剂中,在42℃的温度下。用于高严谨杂交(诸如pcr、northern杂交、southern杂交或原位杂交、dna测序等等)的其他条件为分子生物学领域技术人员所熟知。
“螺旋度”指双链形式的dna的部分(fraction)。因此,通过冷却核酸样品从而允许杂交增加了螺旋度,而加热核酸样品从而使双链核酸中的一些或全部解链成单链核酸降低了螺旋度。
“荧光染料”、“荧光物”、“指示双链核酸的荧光分子”或“结合核酸以形成通过荧光可检测的络合物的分子”和类似术语是指能够证明、表示或者显露反应混合物中的双链核酸的近似量的任何分子、组分、化学品、化合物、染料、试剂和/或其他荧光材料。一个示意性实例为dsdna结合染料。此种指示物还可以示意性地包括具有一种或多种结合、受约束(tethered)、共轭和/或缔合的双链核酸荧光指示物(诸如染料、分子、部分、单元等)的核酸、蛋白质、探针和/或其他分子。
虽然pcr是本文实施例中使用的扩增方法,但可以理解的是任何扩增方法都可以是合适的。此类合适的方法包括聚合酶链反应(pcr);链置换扩增(sda);基于核酸序列的扩增(nasba);级联滚环扩增(crca)、环介导恒温dna扩增(lamp);恒温和嵌合引物引起的核酸扩增(ican);基于靶的解旋酶依赖性扩增(hda);转录介导的扩增(tma)等。因此,当使用术语pcr时,可以理解包括其他替代扩增方法。对于无离散周期的扩增方法,可以使用额外反应时间,其中额外pcr周期添加至本文描述的实施方案。可以理解的是,可能需要相应地调整方案。还可以理解,本文描述的方法可以使用得自其他来源的核酸,包括天然存在的和合成的核酸。
高分辨率dna解链分析的受欢迎度自其在2003年被引入后已经逐渐趋稳。由于强大、简单并且在封闭环境中进行以限制污染,高分辨率dna解链分析被用在研究和临床应用,用于基因分型(参见,例如liew,m.;pryor,r.;palais,r.;meadows,c.;erali,m.;lyon,e.;wittwer,c.clin.chem.2004,50,lyon,e.;wittwer,c.clin.chem.2004,50,1156-1164,和erali,m.;palais,r.;wittwer,c.methodsmolbiol.2008,429,199-206),变异体扫描(参见,例如gundry,c.;vandersteen,j;reed,g.;pryor,j.;chen,j.;wittwer,c.clin.chem.2003,49,396-406和erali,m.;wittwer,c.methods.2010,50,250-261),以及同步基因分型和突变扫描(参见,例如zhou,l.;wang,l.;palais,r.;pryor,r.;wittwer,c.clin.chem.2005,51,1770-1777和montgomery,j.;wittwer,c.;palais,r.;zhou,l.natureprotocols.2007,2,59-66)。获得优质的高分辨率解链曲线取决于许多因素,包括pcr特异性、荧光染料、仪器装备和用于去除背景的算法。从实验解链数据获取相关信息的能力尤其重要,因为解链曲线形状的小差异可能表示变异体。先前报道的去除背景的方法包括线性基线的外推(常用于由吸光度测量的解链曲线)和指数方法。参见美国专利第8,068,992号,全文以引用方式并入本文。虽然这些方法通常成功用于分析解链曲线,但在一些高分辨率的应用中,其变得难以从背景去除算法的人为信号(artifact)中分离相关信号。这最经常存在于低温应用中,特别是那些使用未标记探针、回转引物或多个小扩增子的应用。
通过跟踪荧光随温度的变化生成示例性荧光dna解链曲线。在一个示例性实施方案中,将“饱和”染料(允许杂双链体检测的那些染料,参见美国专利第7,582,429号和第7,456,281号,它们的全文以引用方式并入本文)添加至pcr混合物,并且在dsdna参与下强烈地发出荧光。当混合物被加热,双链解离,引起荧光下降。通过连续地监控荧光随温度的变化,获得荧光解链曲线。解链温度(tm)是dna双链的一半已经解离的点,并且是gc含量、长度和序列的表征。当解链曲线数据显示在负导数图上时,dna双链的tm是明显的。为了准确的tm计算,需要从实验解链数据中去除背景信号,例如在归一化前。此外,整个解链过渡的形状对于序列匹配、基因分型和突变扫描至关重要,特别是在存在杂双链体时(参见montgomery,j.;sanford,l.;wittwer,c.expertrevmoldiagn.2010,10,219-240)。背景去除差可能导致解链曲线畸变,并且甚至引入可能被解释为独特的等位基因的人为信号,其可能导致不正确的分类。虽然本文实施例中使用了饱和染料,应理解的是其他dsdna结合染料可是合适的,并且可以使用如本领域已知的其他荧光检测系统,诸如共价荧光标记核酸。
近来描述了一种通过荧光监控测定pcr中的溶液温度的方法(参见wo2014/058919,全文以引用方式并入本文)。基于始于beer定律的第一原理,这种方法通过计算使荧光与温度关联的校准常数来由荧光测定平均溶液温度。这种方法(此处称为量子方法)已经延伸至计算解链数据中的背景荧光,目标为更好地表示螺旋度并且降低或消除由其他背景去除算法产生的人为低温域。
在示例性方法中,背景信号在测定螺旋度前从实验解链数据中去除。图1a-图1b证明了当分析荧光解链曲线时的示例性背景去除方法。原始解链数据(图1a)显示出差的曲线聚类,具有在低温的陡的斜率并且在高温具有非零斜率的末端。应用简单的归一化(数据从0-100%标度)与预期的螺旋度相比的结果在图1b中示出(更多归一化的信息可以在美国专利第7,582,429号发现,已经以引用方式并入)。使用归一化,在高温的信号水平强制归零,并且改善了曲线聚类。然而,当针对使用umeltsm(基于万维网的软件应用,被设计用于预期pcr产物的高分辨率dna解链曲线,参见dwight,z.;palais,r.;wittwer,c.bioinformatics.2011,27,1019-1020)生成的预期解链过渡叠加时,归一化和预期的解链曲线之间的差异是明显的。使用umeltsm的预期的解链曲线在低温显示出零斜率,信号水平在高温达到零(当dna完全变性时)。这些比较证明,简单的归一化似乎并没有完全去除荧光解链曲线中的背景信号,并且它们证明,如果需要使实验数据与螺旋度预测匹配,则需要强大的背景去除算法。
量子方法
描述一种示例性方法以消除温度对荧光的作用,并且去除发生在其他背景去除方法中的人工解链域区。这种“量子方法”来源于beer定律(参见lemoine,f.;wolff,m.;lebouche,m.exp.fluids.1996,20,319-327和lemoine,f.;antoine,y.;wolff,m.,lebouche,m.exp.fluids.1999,26,315-323,以引用方式并入本文),其中关于温度依赖的荧光强度的等式可以写为:
i=i0cφε[式1],
其中:
i=所发射的(发射)荧光强度
i0=激发强度
c=荧光染料的浓度
φ=荧光染料的量子效率
ε=荧光染料的吸收系数
当染料的浓度足够小时,发射的强度将与浓度成比例,而温度敏感性的大部分将在于荧光量子产率。式1可以使用基本原则进一步扩展以作为温度的函数表示发射强度:
i=i0cec/t[式2],
其中:
c=校准常数
t=平均溶液温度
虽然浓度可以保持恒定,激发强度的改变可能更难以控制,并且可显著地影响温度测量的准确性。除以参考强度和参考温度允许对激发强度和染料浓度的依赖性大大地消除,从而产生以下式:
ln(i/i参考)=c(1/t-1/t参考)[式3],
其中:
t参考是参考温度,
i参考是荧光染料在参考温度下的参考荧光强度。
在转换成°k而不是℃之后,校准常数c通过在以(1/t-1/t参考)(°k)为横坐标以ln(i/i参考)为纵坐标作图形成的线性线的斜率而确定。当实时获得荧光时,可以使用c以及参考温度和参考强度来计算溶液温度(参见wo2014/058919,已经以引用方式并入)。在量子方法中,计算两个校准常数,一个用于在解链过渡之前计算的h(t),并且一个用于在解链过渡之后计算的l(t)。荧光数据可以根据式3绘制,示例性地,x轴为(1/t-1/t参考)并且y轴为ln(i/i参照)。可以理解,该式可以以其他方式绘制,示例性地,分子中的参考值在y轴上,并且1/t参照–1/t为x轴。此数据呈现形式的变化在本公开的范围内。
因此,如图2b所示,量子方法使用参考温度(t参考)和荧光(i参考)来将实验解链曲线数据(图2a)转换成新标度,该新标度使温度对荧光的作用线性化至解链过渡的外部(图2b)。参考值选自解链过渡的外部。在转换成°k之后,计算上界(h(t))和下界(l(t))的背景荧光作为最佳拟合线性公式。一旦计算了用于h(t)和l(t)的公式,将数值转换回初始荧光和温度(以℃)(参见图2c)。h(t)和l(t)在转换回初始荧光和温度之后的非线性有助于防止l(t)与h(t)的过早相交,该过早相交可能产生基线方法中的算法失败(如以下讨论)。
如图2d所示,然后可以按比例计算解链曲线,例如使用式4,按0-100%荧光的尺度。
m(t)=f(t)–l(t)/h(t)–l(t)[式4],
其中:
m(t)=解链曲线
f(t)=荧光
h(t)=上界
l(t)=下界。
或者,可以使用其他方法从荧光解链数据去除背景。示例性的替代方法包括基线方法和指数方法。这些算法的描述之前已报告,在此简要涵盖。
基线方法
示例性基线方法假定解链过渡外部的区域(h(t)和l(t))可以用线性拟合来估算(参见图3a,左图)。然后使用式4由实验荧光数据f(t)估计解链曲线m(t)。
指数方法
示例性的指数方法模拟实验荧光f(t)作为解链曲线m(t)和指数衰减背景信号b(t)的复合。示例性地,b(t)可以由下式计算:
y=401849e-0.126x[式5]
这种方法涉及选择解链过渡外部的区域,在此区域认为荧光单由背景信号组成。背景信号然后拟合至指数模型,以及通过从实验荧光数据扣除所得的背景计算的m(t)(图3c,左图和中图),并且任选地在0与100%之间归一化(图3c,右图)。然而,可以理解,式5仅为示例性的,其他式也可以用于指数方法(参见palais,r.;wittwer,c.methodsenzymol.2009,454,323-343和美国专利第8,068,992号,已经以引用方式并入)。
在以下讨论的实例中,使用写入labview(nationalinstruments)的习用软件分析吸光度和荧光解链曲线,进行修饰以允许基线算法、量子算法和指数算法之间的比较。如mergny,j.;lacroix,l.oligonucleotides.2003,13,515-537中推荐,基线方法用于从吸光度解链曲线去除背景信号,而全部三种方法均用于荧光解链曲线(图3a-3c)。在去除背景之后,对全部解链曲线针对荧光强度归一化,并且由savitsky-golay多项式计算导数图以助于使解链域和基因型可视化。使用联机软件(umeltsm,https://www.dna.utah.edu/umelt/umelt.html)来基于可以识别多域的递归最近邻算法(recursivenearestneighboralgorithm)来预期解链曲线。
使用uv分光光度计在260nm测量的吸光度解链曲线用作判断从荧光解链曲线去除背景的不同方法的金标准。线性基线去除用于吸光度,而利用荧光使用基线方法、指数方法和量子方法。线性基线方法经常引入随温度而增加的荧光的人为信号(图3a),或者如果顶部基线与底部基线在解链过渡之前相交(数据未示出),则完全失败。因此,在大多数图中仅示出指数方法和量子方法。由于利用pcr产物时来自dntp的干扰吸光度,吸光度解链曲线仅可以由合成寡核苷酸得到。
实施例1-合成的发夹dna的解链
研究了三种不同类型的核酸靶的解链。首先,检验具有6bp环和4、6、8或12bp茎的短的合成发夹结构。示例性单链序列为:4bp(5’-gcag
在260nm下使用uv分光光度计测量吸光度。在示例性实施例中,使用ultrospec2000(pharmaciabiotech)以1℃/min的速率监控dna螺旋度随温度的变化。
还使用在双链dna存在下选择性发荧光的染料来测量发夹环靶的荧光。除非另作说明,所有荧光解链均在hr-1(biofirediagnostics)上实施,以0.3℃/s的速率加热10μl样品。短发夹结构(15μm)的解链曲线在由1x
得自形成发夹结构的合成寡核苷酸的吸光度和荧光解链曲线示于图4a和图5a-图5c,相对tm和峰高数据在下表1中示出。在全部茎长时,量子方法而不是指数方法更好地匹配吸光度数据。指数方法似乎降低tms。在全部茎长中,指数方法还产生低温突出人为信号(bulgeartifact)。在一些情况下,此人为信号可能被误认为额外的解链域。与吸光度标准相比,量子方法将tms升高了0.7+/-0.4℃,而指数方法降低tms1.5+/-1.2℃(p=0.01)。量子方法的峰高对吸光度数据进行平均(101+/-14%),而指数方法倾向于较低的峰高(88+/-20%)。因为所有解链曲线在取导数之前归一化,此值反映了解链曲线的形状。
表1
a来自吸光度的δtm是荧光方法(量子或指数)的tm减去吸光度数据的tm。
b峰高表示为相对于吸光度数据的百分比。
cp=0.01(同方差配对t-检验)。
实施例2-使用未标记线性探针的合成dna的解链
还检验了未标记线性探针的解链(参见美国专利第7,387,887号,已经以引用方式并入)。合成dna用于模拟非对称pcr,其中正向和反向链处于1:5、1:8和1:10的比率。对于1:10的链比率,正向链(5’-tggcaagaggtaactcaatcactagcttaaagcactctatccaa-3’(seqidno:5))具有0.25μm的最终浓度,而反向链(5’-ttggatagagtgctttaagctagtgattgagttacctcttgcca-3’(seqidno:6))的最终浓度为2.5μm。下划线的基因座表示2.5μm的最终浓度探针(5’-caatcactagctt-3’(seqidno:7))的结合位点。对于1:8和1:5的链比率,反向链和探针的浓度为为2.0μm,正向链为0.25μm(1:8)和0.4μm(1:5)。最终的200μl样品还包括2mmmgcl2和50mmtris-hcl(ph8.3)。
第三靶为50%gc含量的50bp合成dna双链(integrateddnatechnologies,inc.),具有5’-tctgctctgcggctttctgtttcaggaatccaagagcttttactgcttcg-3’(seqidno:8)序列和其完美匹配的互补)。最终的100μl样品包括2μm合成dna、1.2mmmgcl2和50mmtris-hcl(ph8.3)。
如上所述测量吸光度。对于全部未标记探针实验,在吸光度测量和稀释1:10之后从测试比色皿中去除样品溶液,以使得最终的10μl体积包括如上所述的1xlcgreenplus(biofirediagnostics),55mmtris-hcl(ph8.3),2.2mmmgcl2,200μm的各脱氧核苷三磷酸、0.5μg/μlbsa和1.6nl/μl的klentaqtm存储缓冲剂。50bp双链(2μm)的解链曲线在由1xlcgreenplus、50mmtris-hcl(ph8.3)、200μm的各脱氧核苷三磷酸、0.5μg/μlbsa和1.6nl/μl的klentaqtm存储缓冲剂组成的缓冲剂中获得。用于50bp双链的mgcl2浓度为2mm。
模拟未标记探针分析的结果在图4b和图6a-图6b中示出。用人工寡核苷酸以1:5至1:10的链比率模拟未标记探针基因型,相对tm和峰高数据在下表2中。探针解链过渡(在较低温度下)清楚地与扩增子解链过渡分离(在较高温度下)。与吸光度数据的最佳匹配仍为量子方法。除发夹结构所见的低温突出之外,使用吸光度作为金标准,与量子方法相比,指数方法严重地降低了扩增子峰高(p=0.03)。用任一方法未观察到tm漂移的或探针区域中峰高的重大差异。总之,当解链曲线导数图中存在两个峰时,指数方法似乎降低了高温峰并且提高了低温峰,而量子方法更好地匹配了吸光度曲线的峰高。
表2
a来自吸光度的δtm是荧光方法(量子或指数)的tm减去吸光度数据的tm。
b峰高表示为相对于吸光度数据的百分比。
cp=0.03(同方差配对t-检验)。
图7a-图7b比较有曲线叠加和没有曲线叠加(叠加沿着温度轴)的50bp合成dna双链的荧光、吸光度和预期的解链曲线。如图7a所示,所有解链曲线的tms在彼此的1.5℃的范围内。荧光曲线具有比吸光度曲线更高的tms,这可能反映50bp双链的染料稳定性。当叠加时(图7b),量子分析的荧光曲线的形状几乎与吸光曲线相同,这是量子方法准确地表示了螺旋度的强力证据。相比之下,指数分析之后的曲线形状更宽并且更短,而预期的解链曲线更高并且更窄。
实施例3-使用荧光的pcr产物的解链
使用利用未标记探针、回转引物、多重短扩增子和以上的组合的基因分型试验在pcr之后生成的荧光解链数据比较指数方法和量子方法。如前所述,使用未标记的探针实现因子vleiden突变的基因分型(参见zhou,l.;wang,l.;palais,r.;pryor,r.;wittwer,c.clin.chem.2005,51,1770-1777)。如上所述生成荧光解链曲线,但为解链速率0.1℃/s,在
还使用在pcr之后稀释的对称回转引物比较指数方法与量子方法(参见专利第8,399,189号,全文以引用方式并入本文)。在含有以下物质的10μl体积中实施pcr:1xlcgreenplus、50mmtris-hcl(ph8.3)、2mmmgcl2、200μm的各脱氧核苷三磷酸、0.4u/μl具有抗体的klentaq、5μg/μlbsa、每反应50ngdna和0.5μm的各引物。正向引物为5’-cctagtgatggcaagaggtaactcaatc-3’(seqidno:9),并且反向引物为5’-ttggatagagtgctttaagct-3’(seqidno:10)。小写字母表示回转探针,下划线大写字母表示5’端上的2-bp错配,该错配防止回转引物从一个发夹结构延长。在s-1000(bio-rad)仪上实施pcr,在95℃下初始变性30s,随后为10周期的逐减方案:使用85℃下5s和73℃-64℃下5s,以30个周期的85℃下5s和63℃下5s结束。反应随后用水稀释10倍,在95℃下变性2分钟并且允许冷却至室温。在lightscanner上以0.1℃/s的解链速率获得解链曲线(37至95℃)。
还使用具有一个未标记探针的双链小扩增子解链试验比较了示例性的背景去除方法,其中该试验同时检测三种错义突变(p.c282y、p.h63d和p.s65c)和一个hfe的多态性(c.t189c)。第一扩增子为hfe的40bp产物,该产物包含用终浓度均为0.025μm的正向引物5’-tggggaagagcagagatatac-3’(seqidno:11)和反向引物5’-tgggtgctccacctg-3’(seqidno:12)扩增的c282y突变。第二扩增子为hfe的78bp产物,该产物含有较低外显率的突变(h63d和s65c及多态性t189),用正向引物5’-tgggctacgtggatga-3’(seqidno:13)(0.1μm)和反向引物5’-aaacccatggagttcgg-3’(seqidno:14)(0.5μm)扩增。此外,未标记探针5’-gctgttcgtgttctatgatcatgaggc-p-3’(seqidno:15)(0.4μm)用于对h63d和t189c变异体进行基因分型,由全扩增子解链检测到s65c。下划线表示探针的3’端上的2-bp错配。此双链pcr在含有以下物质的10μl体积中实施:1xlcgreenplus、50mmtris(ph8.3)、500μg/mlbsa、3mmmgcl2、200μm的各脱氧核苷三磷酸、0.4uklentaq聚合酶(abpeptides)、64ng的taqstart抗体(eenzyme)和5ng/μl的人类基因组dna。在毛细管热循环仪(lightcycler2.0,roche)上实施热循环。在94℃下15s的起始的变性步骤之后为50周期的94℃下0s、60℃下1s和75℃下2s。还进行94℃下0s和45℃下15s的最终周期。程序化缓变率对于从变性至退火为20℃/s,从退火至延长为2℃/s,和从延长至变性为20℃/s。
作为含有多个小扩增子的高分辨率解链的实例,还分析了四重基因分型试验的结果。四种变异体(f51601g>a、mthfr1286a>c、mthfr665c>t和f2*97g>a)同时在单个试验中基因分型。有关引物序列、温度-校正控制和pcr条件的信息先前已经详细描述(参见seipp,m.;pattison,d.;durtschi,j.;jama,m.;voelkerding,k.;wittwer,c.clin.chem.2008,54,108-115,以引用方式并入本文)。荧光解链曲线以0.1℃/s的解链速率使用10μl反应体积生成。
图8a-图8b示出由量子(图8a)算法和指数(图8b)算法二者分析的fv未标记探针基因分型试验。用量子分析,未标记探针与扩增子之间的区域是平的,这表明温度对荧光的作用被充分消除,而在指数分析之后,此区域保留高斜率。
图9a-图9b示出使用量子(图9a)算法和指数(图9b)算法二者的回转引物单碱基基因分型。低温下的发夹结构峰由量子分析更对称。此外,指数分析在野生型中产生明显低温峰,除非基因型对照同时运行并且进过仔细分析,否则该峰可能被误解为杂合体。
图10a-图11b和图11a-图11b提供更复杂的基因分型的实施例。在图10a-图10b中,通过量子(图10a)方法和指数(图10b)方法分析了两个小扩增子的双重扩增,扩增子中的一个还具有未标记探针。对hfe的四种单碱基变异体进行基因分型(p.c282y、p.h63d、p.s65c和c.t189c)。量子方法和指数方法二者产生准确的基因型,同时用量子方法存在更少的低温人为信号。如同以上的回转引物分析,指数方法产生低温肩,该低温肩可能导致错误的调用。在图11a-图11b中,在两个温度控制存在下通过小扩增子解链对四种单碱基基因座进行基因分型,其可用于归一化。类似于hfe,量子(图11a)方法和指数(图11b)方法二者在该血栓形成倾向四重试验(f5、f2、和2mthfr变异体)中提供准确的基因型,虽然用量子方法观察到更好的基线和降低的低温人为信号。
实施例4–使用量子方法的解链系统
本发明的某些实施方案还可以涉及或包括经配置以使用量子方法生成解链曲线的pcr系统。参照图12,显示根据本公开的示例性方面的示例性系统700的方框图,该系统700包括控制元件702、热循环元件708和光学元件710。
在至少一个实施方案中,系统可以包括至少一种容纳在样品皿714中的pcr反应混合物。在某些实施方案中,样品皿714可以包括pcr反应混合物,该pcr反应混合物经配置以允许和/或实现模板核酸的扩增。某些示例性实施方案还可以包括至少一种样品区段或腔室716,该样品区段或腔室716经配置以容纳至少一个样品皿714。样品皿714可以以单独、条式、板式或者其他形式包括一个或多个单独的样品皿,并且示例性地,其可以作为样品区段或样品腔室716而提供或者容纳在样品区段或样品腔室716中。任选地,根据形式,可以提供有加热盖,以帮助温度控制。
一种或多种实施方案还可以包括至少一种样品温度控制装置718、720,其经配置以操控和/或调节样品的温度。此类样品温度控制装置可以经配置以升高、降低和/或维持样品的温度。在一个实施例中,样品控制装置718是加热系统,样品控制装置720是冷却系统。示例性的样品温度控制装置包括(但不限于)加热和/或冷却区段(block)、元件、交换器、线圈、散热器、制冷器、灯丝、peltier装置、压力鼓风机、处理器、通风口、配电器、压缩机、冷凝器、水浴、冰浴、火焰和/或其他燃烧或者可燃形式的热量、热敷、冷敷、干冰、干冰浴、液氮、微波和/或其他波发射装置、冷却器件、加热器件、操控样品温度的其他器件和/或任何其他合适的经配置以升高、降低和/或维持样品温度的装置。
pcr系统的某些实施方案还包括光学系统710,该光学系统710经配置以检测由样品714(或者其部分或试剂)发射的荧光的量。如本领域已知,此光学系统710可以包括一个或多个荧光通道。
pcr系统的至少一种实施方案还可以包括cpu706,该cpu706经程序设计或配置以操作、控制、执行或者推进加热系统718和冷却系统720,以热循环pcr反应混合物并加热反应混合物,同时光学系统710收集荧光信号。cpu706然后可以生成解链曲线,其可以打印、显示在屏幕上或输出。任选地,原始解链曲线和根据量子方法调整的解链曲线二者都可以被显示,或仅调节的解链曲线和/或其导数被显示。任选地,经调整的解链曲线或其导数可以显示为叠加在来自其他样品的其他经调节的解链曲线或它们的导数上,叠加在与样品一起运行的标准之上,或叠加在吸光度解链曲线或预期的解链曲线上,或其任何组合之上。在另一实施方案中,系统700仅使用另一仪器生成的或从其他来源收集的扩增产物来生成解链曲线。
示例性特征、组分、元件和或示例性pcr系统和/或热循环仪的部件的其他实例是本领域已知的和/或描述在上文或者美国专利申请序列号13/834,056(其全文以引用方式并入本文)中。
应该注意到,本发明的实施方案的pcr系统可以包括、引入或者包含在本文公开的其他系统、方法和/或混合物中描述的性质、试剂、步骤、组分、部件和/或元件。
因此,使用示例性系统700或其他已知pcr或解链装置,合成发夹结构双链的解链曲线(图4a和图5a-图5c)显示出背景去除方法改变了导数曲线的形状、面积和峰高。使用量子方法预期的tms高于吸光度tms,而指数分析产生较低的tms。总曲线形状在方法之间不同,吸光度和量子数据最紧密地对齐。吸光度和量子分析解链曲线显示出清楚的单解链域,而指数方法产生更复杂的解链过渡,在低温下具有肩或次级解链域。回转引物(参见美国专利第8,399,189号,已经以引用方式并入)还在pcr之后产生发夹结构,这增加了背景去除方法的难度(图7)。在指数方法中也发生了相同的低温畸变,这可使得基因分型变难。
利用未标记的探针的基因分型导致扩增子和探针解链过渡(图4b、图6a-图6b和图8a-图8b)。扩增子与探针之间的温度范围与低探针tm组合提供了对背景去除的质量的简便评估。如同发夹结构数据,吸光度方法和量子荧光方法间具有形状相似的导数图。相比之下,利用指数方法,在探针峰左侧具有独特的肩。此外,用指数方法时扩增子的峰高经常被压制,而量子方法更紧跟吸光度数据(表2,p=0.03)。当考虑扩增子与探针之间的峰高比时,也是如此。即,与吸光度相比,指数背景去除扩大了低温信号并且削减了高温信号。指数方法准确去除背景的潜在限制还显示在图8b中,其中荧光在探针和扩增子区域之间持续降低。相比之下,如所预期,量子方法(图8a)在这些区域之间引起的改变小。
对于50bp合成双链体,吸光度和量子方法产生几乎相同的解链曲线形状(图7a-图7b)。相比之下,指数方法产生与较低的峰高相关联的长的低温肩。该肩的严重度低于发夹结构或未标记探针,可能是因为双链较长。如先前讨论,具有染料和/或更高的解链速率的dna的稳定性可以解释利用荧光得到tms比利用吸光度的高(参见zhou,l.;myers,a.;vandersteen,j.;wang,l.;wittwer,c.clin.chem.2004,50,1328-1335和zhou,l.;errigo,r.;lu,h.;poritz,m.;seipp,m.;wittwer,clin.chem.2008,54,1648-1656)。由umelt预测的峰高比吸光度或荧光曲线更窄,这可能是因为50bp尺寸在软件的推荐范围的下端(50–1000bp)。
来自指数背景去除的低温畸变(distortion)和差分扩增还见于更复杂的基因分型试验中。hfe(图10b)和凝结四链(coagulationquadraplex)(图11b)试验均显示了这些人为信号,特别是当与量子分析相比时(图10a和图11b)。当仅指数方法可用时,形成了hfe和四链试验,因此指数方法和量子方法二者都能进行成功的基因分型,这或许也就不奇怪。虽然指数方法是一个强大的方法,但可能期望具有改善的背景去除的量子方法将允许开发甚至更复杂的测试。而且,虽然通常运行标准的同时还运行未知,但因为量子方法更紧密地匹配吸光度值,使得基因分型而不运行标准成为可能。示例性地,可以通过与预期的曲线或存储的吸光度曲线比较,实施基因分型。
使用温度敏感的荧光染料来测定溶液温度已经在流场(lemoine,f.;antoine,y.;wolff,m.;lebouche,m.exp.fluids.1999,26,315-323)和pcr(sanford,l.;wittwer,c.analbiochem.2013,434,26-33和ross,d.;gaitan,m.;locascio,l.anal.chem.2001,73,41174123)应用中均取得成功。量子方法基于第一原理,该原理描述了通过与电磁辐射相互作用使分子激发成较高能态。从有机染料发射的荧光强度与其溶液浓度有关(walker,d.j.phys.e:sci.instrum.1987,20,217-224)。对于恒定浓度的稀释溶液,通用公式类似于beer’s定律(g.guilbault.practicalfluorescence,2nded.;marceldekker,inc.:newyork,1990),并且发射强度的变化可能与温度变化相关。诸如染料的量子效率、激发强度和摩尔吸收率的因素均可影响发射强度。然而,利用稳定的激发源,显示出对温度的最强敏感性的正是染料的荧光量子产率,术语“量子”用于描述这种背景去除的方法。
一般而言,由于诸如碰撞猝灭的激发态互相作用,荧光随着增加的温度而降低。这种物理现象占荧光解链曲线中背景信号的大多数。然而,在较低温度下认为出现了额外的贡献因素:与高度浓缩的引物结合的dna染料(reed,g.;kent,j.;wittwer,c.pharmacogenomics.2007,8,597-608和zhou,l.;errigo,r.;lu,h.;portiz,m.;seipp,m.;wittwer,c.clin.chem.2008,54,1648-1656),并且可能要求对本文描述的量子方法进行额外修改。因此,扩大量子方法以去除额外的人为信号(如由扩增混合物产生的那些)也在本公开的范围内。
准确地去除背景信号是分析荧光解链曲线的必不可少的重要部分。虽然基线方法经常是成功的,但它在利用多个小扩增子、未标记探针和回转引物的应用中总是失败。当下部线性拟合和上部线性拟合在低于解链过渡的温度相交时,产生这种失败,从而使得分母变为零并且发生不连续。图3a-图3c有助于使用基线方法、量子方法和指数方法计算的背景信号的差异可视化。虽然基线方法在这种情况下并未完全地失败,上部基线降到低于实验解链曲线,引起>100%荧光、解链曲线上的上坡和导数图中的负信号。图3b还示出量子方法经常通过允许非线性基线来避免这种失败。
虽然通过量子方法生成的基线曲线通常在解链区域内不相交(其可能引起随后的算法失败),已经在转换轴上观察到基线相交的少有情况。不必限于理论,这可能来自于与引物荧光有关的低解链信号以及测定基线曲线的区域的选择。如果转换轴上的基线曲线在解链区域相交,则荧光vs温度图上的基线将在解链区域相交。因此,f(t)-l(t)/h(t)-l(t)(来自式4)的分母将通过零并且造成不连续或由于不能除以零。mthfr扩增的回转区域的实施例在图13a-图13f中示出。
图13a-图13b标记的“无偏移”证明了这种少有的问题。当在转换轴上绘制(图13a)时,顶部基线和底部基线在解链区域中相交,实验曲线极接近顶部基线。因为公式4的右边的分母在相交点通过零,解链曲线(图13b)显示了极小的分母和符号改变产生的不连续。此问题的一个解决办法是在轴转换之前将荧光偏移(增加量)加至初始解链曲线上的全部点。图13c-图13f显示出加到初始数据(荧光vs温度)的500和750荧光单元的偏移以及在转换轴上的作图(图13c和图13e)。因为零点和荧光强度两者都不是绝对的,此转换是合理的。当偏移变大时,最终解链曲线(图13d和图13f)中的不连续变小并且最终消失,产生期望的解链曲线形状。加上更大的偏移使得i参考/i更接近1.0,从而使得ln(i参考/i)接近零并且不接近无穷,如果i参考/i接近0.0,i>>i参考,则接近无穷。
已知的背景扣除方法均不能完全解释系统出现的所有效果。初始基线方法在低温下具有不足。指数方法几乎总是起作用,但与吸光度相比使低温过渡畸变,有时引起低温肩。量子方法基于第一原理,并且应该解释温度对用于背景去除的荧光的作用。然而,因为饱和染料尤其在低温下的暂时结合产生的引物的增加的荧光(独特于各引物组),可能需要额外的调整,用于准确地显示解链曲线。不同的方法概括在下表3中:
表3
在一个示例性实施例中,可以在量子方法中实施自动编程以实现最佳的偏移。例如,可以增量修改偏移直到荧光永不超出100%。或者,如果关心的是基线曲线相交,可以逐渐增加偏移直到在解链区域中不发生相交,并且任选地可以通过调节垂直光标(cursors)修改基线区域,以定义用于评估基线曲线的不同上部区域和下部区域。在另一实施例中,加上设定量的荧光作为标准偏移。还考虑了校正量子方法的少有失败的其他方法,非限制实例包括使用总曲线荧光的分数(fraction)作为增量或将各曲线乘以常数(除加上增量之外)以在轴调换之前修饰初始解链曲线。
指数方法(图3c)计算单个指数衰减的背景信号,该背景信号在低温下去除与量子方法相比较少的背景信号。在导数图上,这在低温下产生起始的陡的斜率和更高的信号电平。在一些情况下,这种人为信号基本上是足够的,这样可能难以辨别低温域是否是真实的双链或相反是来自指数背景去除的人为信号。
全部背景去除算法使用了解链过渡之外的区域以计算背景信号。在低温下,该区域必然地必须为约100%螺旋(dna是双链,染料处于最大荧光)。因此,背景信号的主要组分来自于温度对结合至dsdna的染料的荧光的作用,虽然染料分子还可能与存在于溶液中的高浓度的引物互相作用。最终状态显示出约0%螺旋度(由变性单链dna组成)。在这种情况下,来自与dna分子互相作用的荧光染料的背景信号应该最小。然而,荧光染料保持在溶液中,因此在存在变性dna时出现游离染料的一些背景。两个独特的(和独立的)dna状态(解链过渡之前100%螺旋度,在解链过渡之后0%)天然地产生两个独特的背景信号。基线和量子方法的益处是它们将解链曲线模拟为存在于这两种dna状态之间的成比例信号。因此,上部拟合跟踪dsdna的背景荧光变化,而下部拟合跟踪溶液中的游离染料产生的背景。
量子方法产生的解链曲线似乎更好地反映跨解链过渡的吸光度曲线和dna双链的实际百分比。在一些高分辨率解链中,表面上的细微变化可能在诊断上具有重要性。相关的信号不应该丢失在背景噪声中,并且背景信号不可引入可能导致基因分型和扫描误差的人为信号。由于光学和仪器装备的发展不断推进,将生成具有更高分辨率的更详细的解链曲线,并且用于背景去除的算法必须跟上以确保准确的诊断。
本文所述的所有引用通过引用方式并入本文,如同被完整的进行了阐述。
虽然已经参照优选实施方案详细描述了本发明,本发明的范围和精神内存在有多种如以下权利要求所描述及定义的变体和修改。
- 还没有人留言评论。精彩留言会获得点赞!