使用标志子集内的线性关系进行面部表情识别的方法和系统与流程
面部表情识别是用于使人们与彼此恰当地通信的非常重要的非口头方式。已经研发了自动面部表情识别使得计算机和其它设备可以使用该工具与人们有效地交互以便预计人的期望或需要以及辅助人们通过某些介质与彼此交互。这些系统使用在诸如以下各项的应用中:感知用户接口、车辆驾驶安全设备、访问控制系统、用于游戏或化身通信的面部动画、远程护理或远程医疗照看、在线学习和教育节目等。
动态面部表情识别的目标是连续地标识在所捕获或实况的视频序列中不由自主地展现的面部表情。然而,常规面部表情识别方法既不足以检测面部特征中的细小差异也在计算上是昂贵的。因而,期望更高效、准确的面部表情识别。
附图说明
作为示例而非限制,在附图中图示了本文描述的素材。出于说明的简单性和清楚性,在图中图示的元件未必按照比例绘制。例如,出于清楚性,可能相对于其它元件而夸大一些元件的尺寸。另外,在考虑适当的情况下,已经在图当中重复参考标记以指示对应或类似的元件。在图中:
图1是执行面部表情识别的图像处理设备的图示;
图2是示出了面部表情识别过程的流程图;
图3是面部表情识别过程的详细流程图;
图4是面部表情识别过程的部分的详细流程图;
图5是解释用于面部表情识别的面部形状对准的图;
图6是解释用于面部表情识别的特征提取的图;
图7是表征用于面部表情识别过程中的特征提取的描述符的图;
图8是用于面部表情识别中的特征提取的描述符的图表的集合;
图9是用于面部表情识别的区别性模型的图;
图10是用于示出面部表情识别的结果的CK+数据集上的混淆矩阵;
图11是用于示出面部表情识别的结果的MMI数据集上的混淆矩阵;
图12是本文描述的示例系统的操作的图;
图13是示例系统的说明性图;
图14是另一个示例性系统的说明性图;以及
图15图示了全部依照本公开的至少一些实现进行布置的另一个示例设备。
具体实施方式
现在参照所包含的附图来描述一种或多种实现。尽管讨论了具体配置和布置,但是应当理解到,这仅出于说明性目的而做出。相关技术领域中的技术人员将认识到,可以采用其它配置和布置而不脱离该描述的精神和范围。相关技术领域中的那些技术人员将清楚的是,本文描述的技术和/或布置还可以在除本文描述内容之外的各种其它系统和应用中采用。
尽管以下描述阐述了可以在诸如例如片上系统(SoC)架构之类的架构中显现的各种实现,但是本文描述的技术和/或布置的实现不限于特定架构和/或计算系统并且可以出于相似目的而由任何架构和/或计算系统所实现。例如,采用例如多个集成电路(IC)芯片和/或封装的各种架构,和/或各种计算设备和/或消费者电子(CE)设备(诸如成像设备、数字相机、智能电话、网络摄像机、视频相机、视频游戏面板或操控台、机顶盒等),可以实现本文描述的技术和/或布置。另外,尽管以下描述可以阐述众多具体细节,诸如系统组件的逻辑实现、类型和相互关系、逻辑分区/整合选择等,但是所要求保护的主题可以在没有这样的具体细节的情况下实践。在其它实例中,可能没有详细示出一些素材,诸如例如控制结构和完整软件指令序列,以便不使本文公开的素材混淆不清。本文公开的素材可以实现在硬件、固件、软件或其任何组合中。
本文公开的素材还可以实现为存储在机器可读介质或存储器上的指令,其可以由一个或多个处理器读取和执行。机器可读介质可以包括用于以由机器(例如,计算设备)可读的形式存储或传送信息的任何介质和/或机构。例如,机器可读介质可以包括只读存储器(ROM);随机存取存储器(RAM);磁盘存储介质;光学存储介质;闪速存储器设备;电气、光学、声学或其它形式的传播信号(例如,载波、红外信号、数字信号等),以及其它机器可读介质。在另一种形式中,非暂时性物品,诸如非暂时性计算机可读介质,可以供以上提及的任何示例或者其它示例(只是它不包括暂时性信号本身)所使用。它包括除信号本身之外的那些元件,那些元件可以以诸如RAM等的“暂时性”方式临时持有数据。
在说明书中对“一种实现”、“实现”、“示例实现”等的引用指示所描述的实现可以包括特定特征、结构或特性,但是每一种实现可能不会必然地包括该特定特征、结构或特性。此外,这样的短语未必指的是相同的实现。另外,当结合实现描述特定特征、结构或特性时,主张的是,结合无论本文明确描述与否的其它实现施行这样的特征、结构或特性在本领域技术人员的知识范畴内。
面部表情识别的系统、物品和方法使用标志子集内的线性关系。
如上文所提及的,对于通过计算机实现的设备进行更好的通信或者关于人的面部表情从自动化设备获得更合适的反应,自动面部表情识别是合期望的。这些系统使用在诸如以下各项的应用中:感知用户接口、车辆驾驶安全设备、访问控制系统、用于游戏或化身通信的面部动画、远程护理或远程医疗照看、在线学习和教育节目等。而且如所提及的,目标在于连续地标识在所捕获或实况的视频中不由自主地展现的面部表情的常规动态面部表情识别系统仍然是不够的。
具体地,用于面部表情识别的常规方法可以分成两个类别:(1)基于局部特征的方法,以及(2)基于动作单元的方法。基于局部特征的方法主要使用局部代表性特征,诸如局部二元图案(LBP)、伽柏和梯度方向直方图(HOG),以描述不同面部表情种类当中外观方面的变化。这些类型的方案通常仅仅很好地适于标识面部上容易可识别的强(或高量值)面部表情。
相比而言,基于动作单元(AU)的方法更流行并且有效用于处置在进行中的视频序列中连续面部表情识别问题。在该类别中,依据固定数目的唯一AU的变化来描述面部肌肉运动。更具体地,每一个AU具有通过数个基准点(诸如,标志)定义明确的面部构成组成的某一间距和布置,因而其与一个或多个面部肌肉有关。在视频序列中由帧到帧的面部肌肉的运动可以依照AU进行描述。例如,在公知的面部动作编码系统(FACS)中,AU 10描绘了上唇的抬起等等。尽管这种类型的方案已经变为用于动态面部表情表示和识别的标准,但是除其高计算成本之外,对于动作单元检测而言还非常难以准确。
为了避免这些问题,已经研发了强有力的动态模型,其包括条件随机场(CRF)和贝叶斯网络的改进不变量,尤其是用于对面部形状的临时变化(即,固定数目的语义学上重要的面部标志)进行建模。然而,这些动态模型的能力部分地受面部形状数据作为用于模型的特征输入的直接使用所约束,而同时忽略了面部形状一般既不密集也不是区别性的事实。因而,在常规形式中,直接用于限定面部形状的面部标志的数据,诸如作为一个示例的68个标志,没有以高准确度提供用于描述复杂面部表情变化的充足数量的数据,因为来自小数目的标志或点位置的数据在略微或轻微不同的面部表情当中不是充分不同的。
为了克服这些缺点,本文公开的快速、准确且动态的面部表情识别方法使用基于密集几何关系的特征描述符(DGRBFD),并且在一些示例中,使用区别性动态分类模型,诸如基于区别性潜在动态条件随机场(LDCRF)的动态模型,其使用DGRBFD描述符来标识用于面部的面部表情分类。而且,所公开的动态面部表情方法最初获得面部标志处的稀疏几何特征,并且然后通过确定面部形状上的主标志和其它标志的子集当中的几何关系(并且在一种情况下,对线性关系进行递归)而使它们提升为更密集且更有区别的。作为一种形式,子集至少包括相对于主标志的附近邻居面部标志。所提取的关系用于形成针对每一个面部图像的DGRBFD描述符。提供训练面部表情序列(或临时帧或时间实例)之上的DGRBFD描述符以学习基于区别性LDCRF的动态模型,其可以联合地编码每一个面部表情类别中的固有子结构以及不同面部表情类别之间的外在转变。所学习的LDCRF模型利用相应DGRBFD描述符来估计用于当前帧中的每一个面部的面部表情分类标记。所公开的方法还能够不仅在多个帧之上而且在单个帧之上执行面部表情识别。其可以以非常快的速度(>50fps)在常规计算机上运行而大多数情况下不管视频帧的分辨率如何。动态面部表情模型的大小可以小于5KB。
更加详细地,在面部检测和面部表情识别系统中,通过标志的固定集合来限定面部形状,其中每一个单个标志是涉及面部组成的部分的语义学上重要的数据点,面部组成诸如为嘴巴、鼻子、眼睛、下颚线、下巴等。标志处的数据可以包括与分析有关的不管什么数据,包括几何(或像素)坐标、亮度、颜色和/或运动信息,其指示在一个或多个面部的视频序列中由表情到表情(或由帧到帧)的改变。面部表情中的改变通常引起位于主要面部组成周围的标志处的面部的物理几何特征中的可察觉或非常微小或细微的变化。更重要地,已经发现,一个特定面部标志处的面部特征的这种几何变化至少紧密涉及协作地限定相同面部组成和/或靠近的面部组成的一个或多个部分的附近邻居面部标志。在一些情况下,面部上的所有或者几乎所有的标志可以在几何学上涉及用于特定面部表情的单个标志。在本文中,术语“涉及”是指可以处在相对于用于特定面部表情的其它标志的某一距离(或范围)处的标志。因而,提取多个或者每一个面部标志以及包括附近邻居标志的相应子集之间的密集几何特征关系,可以是描述面部表情变化的更准确且高效的方式,由此避免复杂的动作单元检测技术。因此,在该过程中,每一个主标志处的数据可以通过标志的那些分组或子集而不是单个标志来表示。而且,该概念可以扩展成使得针对主标志所形成的每一个子集包括限定面部的所有(排除主标志本身)或者大多数其它标志。
作为一种方案,通过使用主面部标志和子集中的标志处的数据制定和求解线性递归类型的问题来在主标志及其子集当中形成几何关系。线性递归可以用于捕获以下各项的几何特征之间的密集且区别性的关系:(1)至少一个或多个面部标志(称为每当将标志的子集分配给主标志时的主或锚定标志),并且可选地,面部上的每一个标志可以是主标志,以及(2)形成用于主标志的标志的子集的其它标志,诸如附近邻居标志,或者相同面部上的所有其它标志。换句话说,过程或系统使用每一个面部标志和具有其它标志的相应子集的几何特征之间的线性1对K单独几何关系值。因而,出于一致性和清楚性,通过执行例如线性递归而协作地形成线性组合的主标志和子集的首要概念将在本文中称为几何关系,而具有子集中的每一个单独标志的描述符-向量中的单独关系将称为几何关系值。
形成线性模型,其将多个或所有主面部标志处的几何特征表示为那些标志的相应子集的线性组合。作为一个示例,该线性问题的解利用最小平方公式求解,并且用于形成DGRBFD描述符。可以捕获由于面部肌肉的运动所致的形形色色面部表情变化的DGRBFD描述符通过堆叠和级联关于多个或每一个面部标志及其子集的解(几何关系)来构造。几何关系在相同序列(1到N)中级联为在向主标志分配其子集时所建立的主标志的索引,并且级联为用于建立几何关系解。作为一个示例方案,用于每一个主标志的子集标志的几何关系值(1到K)还通过标志的(1到N)索引数字顺序保持。因而例如,如果主标志1、2、21和26也处于用于主标志5的子集中,则当形成用于该面部形状的描述符时,并且如下文利用图7更详细地解释的,标志以该数值顺序级联在用于主标志5的级联空间内。
通过使用DGRBFD描述符表示临时面部表情样本,支持向量机(SVM)或多层感知(MLP)等的常规单独分类器可以被训练用于识别任务。更高级的分类使用区别性动态标记模型,并且在一个示例中,进一步呈现基于LDCRF的动态模型以便联合地编码临时面部表情变化,包括每一个面部表情类别中的固有子结构以及不同面部表情类别之间的外在转变。利用该过程,DGRBFD描述符可以用于以密集且区别性的方式来可靠地描绘源自于面部肌肉运动的可察觉或微小或细微的面部表情变化。
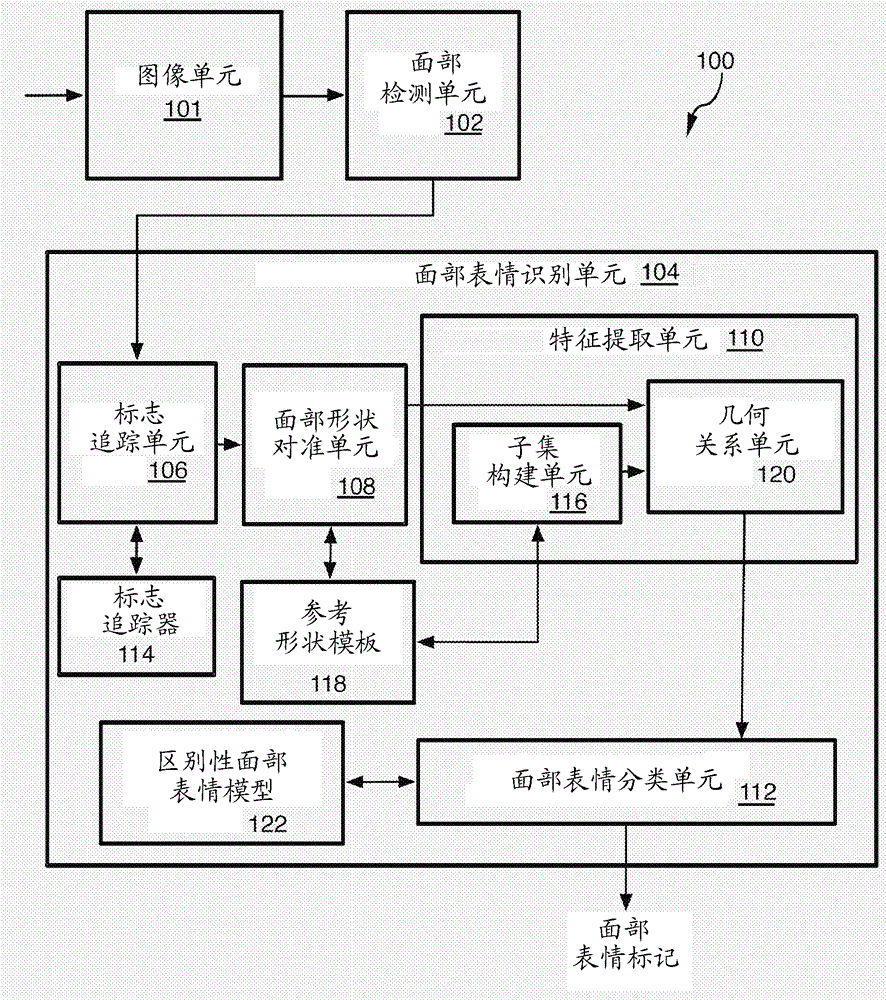
参照图1,用于执行面部表情识别的图像处理设备100可以具有图像单元101或者可以与图像单元101通信,图像单元101接收或者形成单个图像,诸如用于静止照片或者包括数个序列帧的视频序列。关于此,视频序列可以具有图像,图像带有包括一个或多个面部的内容,并且具有随时间或者在视频逐帧前进时改变的面部表情。图像单元101可以接收或者形成来自图像捕获设备(诸如相机或者例如相机模块)的原始图像数据,或者可以接收来自存储器的图像数据。图像单元101可以输出原始图像数据、预处理的图像数据、或者其它方式的图像数据,所述其它方式的图像数据已经部分或完全处理(诸如通过编码器)并且可以就绪用于显示或存储。图像数据可以具有用于帧中的像素的亮度和/或颜色值以及可以用于面部检测的其它统计数据的形式。图像数据然后可以提供给面部检测单元或者面部分类器102,其检测图像数据的图片或帧中的任何面部实例。所使用的一些面部检测技术可以包括具有Haar类、LBP或HOG特征的Viola & Jones级联的Adaboost方案。输出可以是帧坐标,其限定每一个面部实例周围的矩形定界框。
图像处理设备100还可以具有面部表情识别系统或单元104以确定用于每一个检测到的面部以及单个帧处或者帧序列上的面部表情分类。为了达成此,面部表情识别单元104可以具有自动化标志追踪单元106,其接收图像数据并且提供用于在位置随图像数据的检测到的面部上的视频序列的帧而改变时检测和追踪面部标志位置的快速且准确的算法。这可以包括面部标志检测(还称为初始化)、由表情到表情以及改变的面部姿态之间的面部标志的追踪、以及验证(即,失败标识和追踪重置)。可以提供标志追踪器114以存储用于检测面部上的标志的离线学习的面部形状检测器以及追踪算法。一个这样的标志追踪方法使用如由美国专利申请No. 14/106,134所公开的联机形状递归。其它自动化标志检测或追踪方法包括主动外观模型(AAM)、强制局部模型(CLM)、明确形状递归(ESR)、监管下降法(SDM)等。标志追踪单元106的输出是用于连续帧中的每一个面部的标志的坐标,并且在联机形状递归方法的情况下,可以针对每一个面部提供68个标志,尽管取决于所使用的系统,许多不同数目的标志可以在面部上可获得。
面部形状对准单元(还称为相似性变换单元)108接收包含标志坐标的所追踪的面部形状以通过使用参考面部形状对当前面部形状进行归一化,参考面部形状本身通过训练样本而形成并且作为参考形状模板118存储以用于形成经对准(归一化)的面部形状。参考面部形状还由特征提取单元110使用,并且特别地由子集构建单元116使用,以建立要为哪些标志(称为主标志)分配其它标志(并且在一些情况下,附近邻居标志)的子集,以及在每一个子集中包括哪些标志。子集布置可以对于使用相同参考面部形状的所有面部保持相同。
特征提取单元110还可以具有几何关系单元120,其接收来自子集构建单元116的子集布置以及来自面部形状对准单元108的经对准的面部形状二者。针对每一个主标志,几何关系单元120确定主标志及其标志的子集当中的关系,并且作为一个示例,使用线性递归问题来进行确定,所述线性递归问题将每一个标志的坐标计入为因素,并且使用如在下文详细提供的最小平方方法求解该问题以确定用于每一个标志与子集的几何关系。几何关系然后如下文解释的那样组合以发展用于面部的DGRBFD描述符,DGRBFD描述符包括当前帧上对比开头帧上的几何关系之间的差异,并且DGRBFD描述符表征面部的当前面部表情。
将包括组合的几何关系的描述符提供给面部表情分类单元112。该分类单元112可以使用区别性面部表情模型122,诸如CRF模型,以及作为一种形式的以下描述的基于区别性LDCRF的动态模型。将如分组到描述符中的几何关系中的改变(或差异)输入到模型中。模型可以编码每一个面部表情类别中的固有子结构以及不同面部表情类别之间的外在转变以用于执行识别。模型的输出是用于每一个面部以及在所分析的每一个时间处(或者换言之,用于每一个帧或描述符)的面部表情分类标记。针对图像处理设备100的许多其它细节在下文解释。
现在参照图2,作为一个方案,示例过程200是一种使用标志子集的面部表情识别的计算机实现的方法。在所图示的实现中,过程200可以包括一个或多个操作、功能或动作,如通过偶数编号的操作202到208中的一个或多个所图示。作为非限制性示例,过程200可以在本文中分别参照图1和13的示例图像处理设备100和1300并且在相关的情况下来描述。
过程200可以包括“获取至少一个图像的图像数据,所述至少一个图像包括具有至少一个人的面部的内容”202。如本文中所提及的,这可以是具有面部的单个图像,或者沿帧的视频序列的多个图像,该视频序列示出随时间逝去的一个或多个相同面部上的面部表情中的改变。
过程200可以包括“确定用于至少一个主标志的标志的至少一个子集,其中每一个标志具有指示关于面部的面部特征的信息的数据”204。该操作可以包括使用在一个或多个面部上检测到的并且指示面部上的面部特征的位置(或几何形状)的标志,以及形成与主标志相关联的标志的子集。如下文更详细地解释,所有或者少于所有的标志可以是具有子集的主标志,并且子集可以包括附近邻居标志、所有其它标志和/或某一数目的最接近(以距离而言)的标志。子集可以针对多个或所有帧而设置成相同的,如下文所解释的。
过程200可以包括“确定至少一个主标志和标志的子集当中的关系”206。作为一个方案,这指的是几何关系,诸如由线性递归确定。尽管该操作覆盖其中仅形成一个子集的情况,但是通常将形成多个子集。因而,当多个子集被设置用于多个相应的主标志时,每一个主标志和对应子集具有几何关系。几何关系可以是几何关系值的向量,每一个几何关系值对应于子集中的标志之一。作为一个示例,可以通过顺序地堆叠和级联成描述符来组合几何关系,所述描述符包括随时间(从具有面部的开始或开头帧到当前帧)的几何关系中的改变。描述符中的几何关系的数目(以及进而,几何关系值)然后可以通过主要组成分析(PCA)而减少。在下文解释细节。
过程200可以包括“通过使用关系来使用区别性模型标记用于面部的面部表情分类”208。再次,尽管操作覆盖单个关系的情况,但是通常将形成多个关系(例如,具有针对每一个子集一个这样的关系的多个几何关系),并且将使用一个或多个关系来形成用于面部的单个描述符。此处,可以将描述符以及继而几何关系的时间差异输入到条件随机场模型中,并且作为一个示例,潜在(例如,具有隐藏值)的动态条件随机场(LDCRF)模型。如本文中所提及的,模型既通过使中间隐藏状态的集合与每一个面部表情类别关联并且通过使用子集而考虑到固有子机构,又通过使用描述符的时间序列对面部表情的连续流进行建模而考虑到外在转变。模型然后提供每一个面部表情样本以及所估计的分类标记。在下文提供多得多的细节。
现在参照图3,作为一个方案,示例过程300是一种使用标志子集的面部表情识别的计算机实现的方法。在所图示的实现中,过程300可以包括一个或多个操作、功能或动作,如由偶数编号的操作302到312中的一个或多个所图示。作为非限制性示例,过程300可以在本文中分别参照图1和13的示例图像处理设备100和1300并且在相关的情况下来描述。
过程300可以包括在帧的视频序列或图像具有包含至少一个面部的内容时“设置时间t=0”302。首先分析t=0处的初始或开头帧,如在下文详细地描述的。将理解到,本文中呈现的过程300可以逐帧执行使得每一个帧或图像限定特定时刻或时间t。
参照图5,过程300可以包括“检测和追踪面部标志”304。该操作可以包括已经在帧上检测到的面部上的标志的自动检测。作为本文使用的一个示例,存在用于每一个面部的68个标志。示例图像或帧500示出具有标志504的面部502。如所示出,标志可以指示下颚线、眉毛、眼睛轮廓、鼻子的鼻梁和末端、以及作为一个示例的嘴唇的轮廓,尽管存在许多其它可能性。
如上文所提及的,可以通过由2013年12月13日提交的美国专利申请No. 14/106,134公开的联机形状递归系统来提供用于面部标志检测(初始化)、追踪和验证(即,失败标识和追踪重置)的快速且有效的算法的一个集合。该系统提供在改变的面部表情和面部姿态之下非常准确并且还以极其快的速度(超过500fps)和小存储器使用(小于5MB)运行的追踪性能。所训练的模型能够追踪68个面部标志。以上提及了其它可替换的系统。输出是用于每一个标志的帧坐标,并且当沿帧追踪标志时是在每一个帧处的帧坐标。
过程300还可以包括“生成(多个)经对准的面部形状”306。该操作执行基于相似性变换的对准。具体地,一旦可靠地追踪当前图像中的面部标志位置,就对包括所有面部标志的原始面部形状进行归一化以移除可能已经针对标志检测和追踪执行或者以其它方式疏忽的2D平面中面部变换(平移、缩放和旋转)的影响。归一化还可以移除微小3D平面外面部运动。在保持源自于随时间的面部中的面部表情改变的变化的同时执行这一点。作为结果,可以以几何方式归一化面部特征。在本文中,可以使用基于常规相似性变换的对准,其使每一个所追踪的面部形状506配准到作为所有训练样本的平均所计算的参考面部形状508,以便构建经对准的面部形状(还称为归一化的面部形状)510。作为一个示例,这可以包括后向映射和逐片段仿射包绕。作为结果,参考面部形状上的标志通常可以具有与经对准的面部形状上的不同坐标位置。
过程300然后可以包括“提取面部特征”308。在该操作中,如下文利用过程400(图4)详细解释的,通过形成标志当中的几何关系值的密集区域以及使用数个这些区域(或面部标志子集)来执行这一点以确定用于面部的面部表情。作为几何关系值的向量的几何关系可以针对每一个密集区域确定,并且然后组合在基于密集几何关系的特征描述符(DGRBFD)中。通过级联和堆叠用于每一个几何关系值的时间差异来组合几何关系。然后,可以将用于每一个帧(或者继而,几何关系)的描述符提供给模型以确定每一个描述符建议的是哪个面部表情类别。
过程300可以包括“识别和标记(多个)面部的面部表情”310。还在过程400中更加详细地提供的该操作可以包括将DGRBFD描述符输入到本文提及的LDCRF模型中。特别地,模型可以包括在训练所分析的视频序列之上从所有描述符学习的参数,如下文详细地解释的。作为一个方案,不同面部表情分类可以包括开心、伤心、蔑视、生气、厌恶、害怕和惊喜。其它或不同组合的面部表情是可能的。输出将是用于当前帧上的每一个面部的面部表情分类标记。
过程300然后可以具有测试312以确定在视频序列中是否已经达到最大时间T(或最大帧)以及具有要分析的面部。如果否,则t增加1(314),并且过程再次针对新时间t处的下一帧循环。如果是,并且视频序列分析完成,则过程结束,并且最终使用应用可以使用面部表情识别来执行其它任务。
现在参照图4,作为一个方案,示例过程400是一种使用标志子集内的几何关系(诸如,线性关系)并且特别地涉及特征提取和面部表情分类的面部表情识别的计算机实现的方法。在所图示的实现中,过程400可以包括一个或多个操作、功能或动作,如由偶数编号的操作402到422中的一个或多个图示的。作为非限制性示例,过程400可以在本文中分别参照图1和13的示例图像处理设备100和1300并且在相关的情况下来描述。
提供过程400来提取面部特征,其包括设置用于每一个主标志的子集,并且然后确定用于每一个子集并且要用于形成作为向模型的输入的描述符的几何关系,以确定面部的面部表情分类标记。达成此的一种方式是通过以下操作。
过程400然后可以包括“获取参考面部形状数据”402。由于参考面部形状是标准中性面部形状模板,例如在所有中性面部形状样本之上的平均中性面部形状,所以其用于确定针对每一个主标志的邻居成员。
过程400还可以包括“生成经对准的形状数据”408,并且通过将参考数据应用于原始面部形状数据,如上文利用操作306所解释的。
过程400可以包括“设置标志计数i=1”406。这是用于面部上的标志的索引,其中i=1到N。如果图像具有多个面部,则每一个面部将具有其自身的N个标志的集合。如上文所提及的,作为一个示例,可以存在用于每一个面部的N=68个标志。
因而,过程400然后可以包括“获取用于主标志i的1到K个子集标志”408。作为一种形式,要放置在子集中的标志的数目K可以是比面部上的所有标志的数目少一个的任何数目(1≤K≤N-1)。在实践中,在给定K={5、10、15、20、25、30、35、40、……}的集合的情况下,通过例如在扩展的Cohn-Kanade(CK+)和人机交互(MMI)数据集上执行实验结果的统计分析来确定K,其中根据来自给定K个值的实验结果绘制平均识别准确度曲线。利用这些曲线,确定由于不同K值所致的平均识别准确度变化,并且可以选择最佳K值。
作为一种方案,选择到主标志的最近K个距离以用于包括在每一个子集中,诸如K=10或K=20。距离可以通过欧几里得距离来度量。因而,如本文中所提及的,子集可以包括附近邻居标志,其可以或者可以不指示与子集的主标志相同的面部组成。可替换地,将领会到,子集中的成员关系可以通过诸如设置最大距离或其它阈值之类的其它方法来确定,或者可以受标志指示哪个面部组成所限制。此外,通过使用图像特征(诸如颜色、纹理、梯度等)计算的面部形状上的主标志和其它标志之间的相关性值也可以用于确定主标志的子集。
该操作还可以包括对于以从1到N的某一次序中的主标志和从1到K的子集标志二者编索引。作为一种形式,作为主标志的标志被排序为1到N并且可以是任何逻辑次序,只要从一开始在从与标志标识数字的最初分配相同的参考面部形状生成的所有经对准的面部形状上维持布置即可。因而,作为一个示例,数字可以一般地围绕面部形状顺时针或者逆时针运行,或者可以通过面部组成进行编号,等等。索引数字变成用于标志的永久性标识数字。就子集标志而言,并且如上文所解释的,次序1到K可以在数值上设置为标志的最低或最高索引数字。作为一个示例,用于每一个主标志的所得邻居成员索引是固定的并且在使用相同参考形状并且例如用于当前视频序列的所有经对准的面部形状上使用。
在许多情况下,将为面部上的每一个标志分配其自身的其它标志的子集。在一些情景中,少于面部上的所有标志可以用作主标志。主标志可以限于面部的某些区域,或者面部上的某些面部组成。例如,当面部形状包括相对大数目的标志并且下巴也具有一个或多个标志时,可以省略下巴上的标志。具体地,下巴可能容易地受背景群簇所影响或者由于实践中的面部姿态改变而遮挡。而且,相比于诸如眼睛、眉毛、鼻子和嘴巴之类的关键面部组成上的其它标志,下巴上的标志对面部肌肉运动有较少贡献。因而,在一些情况下,下巴上的标志可以不用作主标志,但是仍然可以作为子集内的其它或邻居标志而被包括,或者可替换地可以根本不使用。设想到其它变型。
还将理解到,当存在多于一个子集时,子集可以非常好地重叠使得单个标志可以包括在多个子集中。类似地,如本文中讨论的当前过程仅有一次将标志用作主标志。然而,可以存在以下情景,其中标志可以具有带子集中的不同成员或标志数目的多个子集,或者换言之,标志是用于在单个时间或帧处包含相同面部上的相同或不同数目的标志的数个不同的附加或可替换子集的主标志。这可能发生以向例如某一标志提供额外权重,或者测试潜在可替换子集来确定例如最佳子集。
过程400然后可以包括“计算用于子集的几何关系”410。具体地,使用经对准或归一化的面部形状值(固定的子集成员索引,但是由于面部表情改变所致有不同位置)来确定几何关系并且形成DGRBFD描述符以用于提取并且输入到离线学习的区别性面部表情模型中。
如之前提及的DGRBFD描述符的一个目的是捕获由处在主面部组成(诸如眉毛、眼睛、鼻子、嘴巴和下巴)周围的标志处的几何特征中的变化所引起以及由面部肌肉的运动所引起的可察觉或微小或细微面部表情。还已经发现,在一个特定面部标志处的此类几何变化紧密地涉及至少在其附近邻居标志处的那些几何变化,如果不是相同面部上的所有标志的话。因此,与K个其它标志的所谓的1到K几何关系是用来区分一个特定分类的面部表情样本与其它分类的那些面部表情样本的潜在地有用线索。如下文所解释的,作为示例,过程可以使用线性递归,以明确地计算整个面部形状内的1到K几何关系。
为了计算用于每一个子集和对应主标志的几何关系,可以执行以下操作。在给定包括面部的视频序列的情况下,用于指示面部上的面部特征的标志可以具有坐标,并且其中坐标可以是例如帧(或图像)上的像素位置的坐标。做出以下假设:
(a)令是在对准步骤中使用的参考面部形状,其中N是形成面部形状的标志的数目,但是可以视为要在少于形成面部的所有标志将为主标志时向其分配子集的主标志的数目,
(b)令是时间t处的经对准的面部形状使得t表示例如视频序列中的单个图像或帧,
(c)令是时间t0处的经对准的开头面部形状,使得S0可以是示出所分析的中性面部的视频序列中的第一个帧,
(d)令Pi是位于处并且在本文中称为具有子集的主标志的任意标志,
(e)令是具有到如上文所提及的Pi的最近欧几里得距离的K个邻居的索引的相应子集,并且1≤K≤N-1。使用参考形状来计算Ji,并且维持Ji中的其它或邻居标志的成员关系相同以用于供经对准的两个面部St和S0中的Pi所使用。K中的成员关系如上文所述。
现在,对于经对准的面部形状St,将标志Pi处的几何特征及其K个邻居的几何特征之间的关系的计算公式化为线性递归(或线性表示)问题:
其中
其中f1(i)……fK(i)指的是主标志Pi的K个邻居的索引,并且其中,并且其中
等式(1)的线性系统的解可以通过使用最小平方估计器来求解:
。
使得每一个是具有K维度的向量(具有用于包括在其子集中的每一个邻居标志的元素)。因而,被称为几何关系(或者几何关系向量)并且出于清楚性,其每一个元素被称为几何关系值。
而且,所分析的每一个标志i(1到N)具有其自身的线性系统(或者线性递归)解,在本文中以其它方式称为用于主标志(在pi处)及其子集(其K个邻居)的几何关系。因而,过程400中的下一操作是确定“i=最大值N”是否成立412,并且如果否,则将i设置成i+1(414)以在操作404处重新开始循环,并且生成用于下一主标志及其子集的几何关系。如果达到N,并且已经分析要作为主标志而包括的所有标志,则过程400然后前进到构造用于面部的单个DGRBFD描述符。
参照图6-7,过程400然后可以包括“堆叠和级联几何关系以形成用于面部的DGRBGD描述符”416。对于一个示例,面部形状600被示出有68个标志601,并且其中三个主标志602、604和606各自被示出有其它或邻居标志的相应子集608、610或612。对于该示例,对于每一个子集中的10个标志而言K=10,使得在多个子集中使用许多标志。没有示出存在的其它子集。作为结果,每一个主标志具有维度为10的所提取的特征向量。而且,对于该示例,假设下巴处的68个标志中的17个没有被用作主标志,使得针对所使用的每一个主标志(总共51个)形成几何关系值。在级联中,将每一个所提取的特征向量序列地堆叠到之前堆叠的向量的尾部。此处,序列是指其中对标志编索引(1到N)的数值次序,并且(对于每一个i的1到K)如上文所解释的且最初在参考面部形状处,并且在所图示的示例中,是使用标志生成等式(1)到(4)中的几何关系的相同次序。在相同序列中维持几何关系值(或者每一个几何关系向量的元素)中的差异(等式(5)),使得在不同时间处来自对应标志的几何关系恰当地对准以彼此比较。因此最后,以该示例继续,DGRBFD特征描述符可以具有维度51x10=510。
将理解到,尽管此处示出的堆叠和级联使用几何关系值(等式(5))的差异(T-T0),但是可替换地,所提取的几何关系值可以直接地在时间T处使用以替代地形成描述符。此处,来自时间T0的被减去的值可以用于消除基线关系,使得其余关系值(即,差异)在描述面部表情的变化方面更有区别且鲁棒。
如图6中所示,并且以该示例继续,提供了图表614(1)到614(N),其中每一个主标志一个图表,并且继而每一个几何关系一个图表。x轴表示用于标志i的子集中的标志(k)的索引,而y轴表示来自解向量(几何关系)的每一个子集标志的几何关系值中的差异(等式(5))。基于i和K的索引(如沿x轴所示,并且其中y轴是几何关系值中的差异),级联将所有几何关系组合成用于0到510维度的单个图表700(图7)。
参照图8,作为另一个示例,DGRBFD在捕获如图表802中所展示的面部肌肉的各式各样运动方面具有有利能力,图表802呈现关于六个流行面部表情分类的经对准的面部形状样本800之上的一些代表性DGRBFD。在图表802上,x轴表示用于特定主标志的邻居标志集合的索引,并且y轴表示所计算的几何关系值中的差异(等式5)(其中K=20)。在当前系统中,51个标志中的每一个(排除位于下巴上的17个标志,如现有技术示例那样)和包括20个最近邻居的相应子集(选自所有67个标志候选者)之间的几何关系i用于构造DGRBFD。因而,对于该示例,用于描述每一个面部表情样本的DGRBFD具有维度51x20=1020。
然而,作为一种形式,几何关系本身不是针对区别性模型所提供的最终值。替代地,为了将时间元素计为因素来捕获随时间的面部表情中的改变,描述符包括如下用于相同子集但是在不同时间(或帧)处的几何关系中的差异。用于使面部表情分类与面部以及因此要放置在区别性标记模型中的输入特征匹配的最终描述符通过以下列向量并且在经对准的面部形状St和S0之上以及通过形成用于描述符的向量而找到:
将理解到,对于开头中性描述符,实际几何关系值使用在零向量中。以其它方式,通过如本文中所解释的那样序列地堆叠和级联关于多个或每一个面部主标志及其K个邻居的等式(1)到(4)的线性系统的解来构造描述符。如等式(5)中所示,描述符最终可以包括用于每一个主标志的当前帧或时间t与初始或开头帧(t=0)中的解之间的差异。
将理解到,设想到用于描述符的可替换方案,其以其它方式并且针对与下文提供的不同类型模型来组合几何关系。
过程400然后可以包括“应用主要组成分析(PCA)以减少描述符的维度”418。根据实验结果,在以上示例中提及的1020维度可以通过使用PCA而减少为15那么低。这形成用于基于区别性LDCRF的动态模型的输入。PCA是用于维度减少的基本且流行的方法。其在许多流行的开源SW中可获得,诸如OpenCV和MATLAB。将理解到,对于大容量系统,可以省略PCA。
过程400可以包括“使用区别性面部表情模型来识别用于面部的面部表情的分类”420。具体地,基于LDCRF的动态模型可以用于针对图像上的密集区域而对面部表情(DGRBFD)描述符的一个或多个图像进行归类。基于区别性LDCRF的动态模型处置连续面部表情识别问题,而同时通过使中间隐藏状态的集合与每一个面部表情类别相关联而编码每一个面部表情类别的固有子结构,以及通过对面部表情样本的数个训练序列进行建模而编码不同面部表情类别之间的外在转变(例如,由帧到帧)。
这种建模操作包括首先训练模型,并且其次使用具有所分析的当前视频序列的模型来生成用于面部的面部表情标记。具体地,可以在分析当前视频序列的帧之前离线地预训练区别性模型来提供最终面部表情分类以供进一步使用。区别性模型通过用于在CK+和MMI数据集上的训练的相同或相似过程来训练。一般地,然后,训练过程可以包括检测样本以及在数个样本面部表情视频之上对准面部形状,数个样本面部表情视频可以具有数个不同主体,可以从中性开始并且然后示出数个不同分类中的面部表情,以及提供用于每一个面部表情的一系列运动,诸如示出从开头到峰值的特定目标面部表情。
训练过程可以包括与本文提供的实际应用过程(过程300和400)相同或相似的过程以便优化参数。一旦通过训练设置参数,则参数固定以用于向当前视频序列的实际应用。
参照图9,示出了模型900的结构,其中表示随时间的基于DGRBFD的观察,表示面部表情分类标记的相关序列,并且表示中间隐藏状态。换言之,当形成描述符时,将它们录入模型中使得模型包括在分析用于面部的当前描述符之前已经到来的多个或全部的之前描述符。换句话说,模型中的每一个x是使得在模型中的DGRBFD的描述符或向量。而且,将隐藏状态变量并入具有明确分区的模型中。因而,面部表情识别可以在用于模型构建的测试视频序列的任意长度的图像帧之上执行。
作为一种形式,针对遍及运行面部图像的每一个帧而提供用于模型的描述符以得到最大的准确度。然而,作为另一个示例,可以在间隔中(诸如用于每第十个或第三十个帧的描述符等等)将描述符提供给模型,以减少面部表情识别的计算负载。
利用以上限定,将模型限定为概率等式(基于概率的链式法则):
其中是模型的参数。为了使训练和推导可追踪,限制与非联合的每一个面部表情分类标记yi相关联的隐藏状态的集合。也就是说,当任一个hi不属于时,则。然后,等式(6)可以表述为:
与传统条件随机场(CRF)的公式化一致地限定,从而提供:
其中
其中可以是状态函数或者状态转移函数。状态函数例如表示当输入特征向量x被分类为隐藏状态hi时的概率。状态转移函数表示在前一特征向量被分类为隐藏状态hi-1的条件之下将输入特征向量x分类为隐藏状态hi时的概率。因此,在给定输入特征向量x的情况下,状态函数仅取决于单个当前隐藏状态,而状态转移函数除当前隐藏状态hi之外还取决于前一隐藏状态hi-1。在训练过程中,通过最大化整个训练数据集之上的等式(6)的对数几率函数,使用梯度上升算法来学习模型的经优化参数值。
一旦学习基于区别性LDCRF的动态模型,就可以使用序列置信传播容易地推得测试视频序列之上的面部表情标记。具体地,根据等式(6)和(7),LDCRF模型的结果是参数值,用于每一个面部表情分类的隐藏状态的相应非联合集合,以及所学习的状态函数或状态转移函数。在给定测试输入向量x的情况下,相应面部表情标记y*可以经由最大化较晚概率模型来确定:
一旦利用面部表情类别标记面部,则可以将标记提供给许多不同应用以供使用,诸如用于与游戏化身通信,诊断由相机监控的人的健康、状态或需要,检测车辆驾驶员睡着等等。
将理解到,模型在视频序列之上连续地运行,使得相同模型在分析视频序列时接收用于具有面部的每一个帧的每一个描述符。如本文中所提及的,这通过将所有描述符收集到模型中而提供了累积性、考虑外在因素的效果。因而,一旦将描述符提供给模型,就针对要生成的下一描述符而对于下一时间帧(t)重复操作并且将其输入到如利用过程300(图3)所解释的模型。
因而,当前方法和系统可以准确地提供面部表情识别。此外,当前方法能够在多个帧之上而且还在单个帧上执行面部表情识别。而且,其基本上可以在常规计算机上以非常快的速度(>50fps)运行,而不管由于以下事实所致的视频帧的分辨率如何:从面部形状直接提取密集且区别性的面部特征。动态面部表情模型的大小小于大约5KB。
将领会到,尽管当前过程使用在CK+和/或MMI数据集中寻址的七个或六个面部表情分类,但是可以容易地一般化线性递归过程以直接地处置更多或更少的面部表情分类。扩展的应用场景可以包括子类别面部表情识别(诸如稍微、正常或极度地用于诸如高兴之类的任何基本面部表情分类的子类别)、分类的组合(诸如,作为一个分类的悲伤+蔑视)、以及多得多的面部表情变型(诸如添加左眼张开或闭合、右眼张开或闭合、睡眠等等)。为了处置这种增大数量的面部表情分类,系统收集并且精细地标注相关数据集以用于训练形状模型和动态面部表情模型。当前方法在这些应用中同样将获得领先性能。
为了对照现有技术来测试所公开的面部表情识别方法,将结果与CK+和MMI数据集进行比较,CK+和MMI数据集可以视为最具挑战性的公共可获得的、很好标注的、基准面部表情数据集,并且在建立面部表情样本的困难性以及面部表情分类的数目方面是有挑战的。
CK+数据集包含从30岁前的118个主体18捕获的327个视频序列。标记了所有七个基本面部表情,包括生气(Ang)、蔑视(Con)、厌恶(Dis)、害怕(Fea)、高兴(Hap)、伤心(Sad)和惊喜(Sur)。所标记的MMI数据集包括从年龄由16到52岁的23个主体捕获的205个视频序列。标记了总共六个基本面部表情(排除蔑视)。与CK+数据集不同,MMI数据集中的主体通常示出大头部运动和非姿态式面部表情。
比较性实验和评估量度与Z. Wang等人、Capturing Complex spatio-temporal relations among facial muscles for facial expression recognition、In Proceedings of 27th IEEE Conference on Computer Vision and Pattern Recognition、页码3422-3429、2013年描述的那些相同或相似。当前实验遵循CK+和MMI数据集的所有视频序列上的15重和20重交叉主体验证。由于当前方法可以不仅在多个帧(包括整个视频长度)之上而且还在单个帧上执行面部表情识别,所以最困难的运行方式、单个帧被选择用于比较。总体上,分别在CK+数据集和MMI数据集中存在5876和16633个图像帧。以下表格1总结了所公开的方法和Z. Wang等人所公开的方法的结果。可以看出,所公开的方法分别在两个数据集上将当前现有技术的错误减少了多于63.94%和23.97%。测试证实动态面部表情(LDCRF)模型的模型大小小于5KB,并且方法在常规计算机上以非常快的速度(>50fps)充分地运行而不管视频帧的分辨率如何。
参照图10-11,提供混淆矩阵1000和1100以更好地示出所公开的方法相比于常规方法的改进性能。混淆矩阵是示出方法在多分类识别任务上的性能的标准方式。示出了两个矩阵,矩阵1000用于CK+数据集,并且矩阵1100用于MMI数据集。在混淆矩阵上,y轴表示实际(地面实况)分类,并且x轴包括所有可能的分类。矩阵的每一行提供被识别为每一个可能的分类的相应实际分类的样本的部分。每一行的总和是1,并且矩阵对角线处的空间示出真实识别速率(成功),而矩阵中的其它空间示出错误率(被识别为其它分类的失败部分)。
当前公开的方法在广泛使用的CK+数据集上的七个基本面部表情(包括生气、蔑视、厌恶、害怕、高兴、伤心和惊喜)之上实现了95.06%的平均识别率,从而将当前现有技术的错误减少了多于63.94%。在更具挑战性的MMI数据集上,当前方法在六个基本面部表情(MMI数据集不包含蔑视)之上实现了69.36%的平均识别率,从而将当前现有技术的错误减少了多于23.97%。
参照图12,过程1200图示了依照本公开的至少一些实现的、使用标志子集内的几何关系(诸如,线性关系)执行面部表情识别的样本图像处理系统1300的操作。更详细地,在所图示的形式中,过程1200可以包括一个或多个操作、功能或动作,如由偶数编号的动作1202到1216中的一个或多个图示的。作为非限制性示例,过程1200将在本文中参照图13进行描述。具体地,系统1300包括逻辑单元1304,其具有带有特征提取单元1314的面部表情识别单元1312和面部表情分类单元1316。系统的操作可以如下进行。
过程1200可以包括“接收参考形状数据”1202,并且如上文所解释的,其可以是具有从训练样本的集合平均的参考标志坐标的中性面部形状。
过程1200可以包括“生成经对准的形状数据”1204。如上文所解释的,最初形状数据通过使用参考形状数据而对准。
过程1200还可以包括“设置标志邻居子集”1206,其使用参考标志坐标来选择哪些标志将被视为主标志并且以索引中的某一次序提供它们。该操作还包括确定子集中的其它或邻居标志的成员关系,并且还对它们编索引。如上文所提及的,作为一个示例,这可以是相对于包括在子集中的主标志的最近标志的数目。
过程1200还可以包括“确定用于每一个子集的几何关系”1208。特别地,作为一个示例,可以使用线性递归问题并且通过最小平方方法对其求解以确定用于每一个子集的几何关系。解或几何关系本身可以是几何关系值的向量,每一个子集标志一个值。
过程1200可以以“基于关系生成面部描述符”1210而继续。对于该操作,在单个时间点处用于面部的几何关系可以组合以形成单个描述符。作为一个示例,描述符是几何关系的向量,并且作为另一个示例,是DGRBFD描述符。作为一个示例,几何关系以及进而子集标志的几何关系值通过序列地堆叠和级联而组合。描述符然后可以由几何值形成,或者可替换地,由几何值和开头帧处的对应几何值之间的差异形成。
过程1200可以包括“将描述符放置在区别性模型中”1212,使得在分析具有面部的图像的视频序列时形成描述符,将描述符输入到标记模型使得模型包括按时间顺序放置的描述符的行以在视频序列进展时将面部表情中的外在改变计为因素。将理解到,当图像具有多于一个面部时,针对每一个面部执行分离的分析和模型。
过程1200可以包括“确定用于面部的面部表情分类标记”1214。如之前所述,可以使用区别性模型,诸如CRF模型或LDCRF模型,以便准确地确定用于特定面部的最有可能的面部表情分类。与面部表情分类相关联的中间隐藏状态的集合连同最大化概率等式(10)和(11)可以用于确定特定时间处或者在面部表情沿视频序列的运行而改变时用于面部的有可能的面部表情分类标记。而且如所提及的,该操作可以包括在将模型应用于要分析的当前视频序列的描述符之前,首先在训练集合上训练模型以优化模型的参数。
过程1200然后可以“获取下一帧”并且循环回到执行描述符生成(操作1210)。换言之,模型针对视频序列连续地运行,从而累积如上文所提及的描述符。一旦具有面部的最后帧(或其它指示符)被分析,则过程完成。
将领会到,利用图2-4和12分别解释的过程200、300、400和1200并非必然地必须以所示出的次序执行,也并非必然地必须具有所示出的所有操作。将理解到,可以跳过或者以不同次序执行一些操作。
而且,图2-4和12的操作中的任何一个或多个可以响应于由一个或多个计算机程序产品提供的指令而承担。这样的程序产品可以包括提供指令的信号承载介质,该指令在由例如处理器执行时可以提供本文描述的功能性。计算机程序产品可以以任何形式的一个或多个机器可读介质来提供。因而,例如,包括一个或多个处理器核的处理器可以响应于通过一个或多个计算机或机器可读介质运送给处理器的程序代码和/或指令或指令集而承担本文的示例过程的操作中的一个或多个。一般地,机器可读介质可以以程序代码和/或指令或指令集的形式运送软件,其可以使任何设备和/或系统如本文描述的那样执行。机器或计算机可读介质可以是非暂时性物品或介质,诸如非暂时性计算机可读介质,并且可以供以上提及的任何示例或者其它示例(只是它不包括暂时性信号本身)所使用。它包括除信号本身之外的那些元件,那些元件可以以诸如RAM等的“暂时性”方式临时持有数据。
如在本文描述的任何实现中所使用的,术语“模块”是指配置成提供本文描述的功能性的软件逻辑、固件逻辑和/或硬件逻辑的任何组合。软件可以体现为软件封装、代码和/或指令集或指令,并且如在本文描述的任何实现中使用的“硬件”可以单个地或者以任何组合包括例如硬布线电路、可编程电路、状态机电路和/或存储由可编程电路执行的指令的固件。模块可以联合地或者单独地体现为形成更大系统的部分的电路,例如集成电路(IC)、片上系统等。例如,模块可以体现在逻辑电路中以用于经由本文讨论的编码系统的软件、固件或硬件而实现。
如在本文描述的任何实现中所使用的,术语“逻辑单元”是指配置成提供本文描述的功能性的固件逻辑和/或硬件逻辑的任何组合。如在本文描述的任何实现中使用的“硬件”可以单独地或者以任何组合包括例如硬布线电路、可编程电路、状态机电路、和/或存储由可编程电路执行的指令的固件。逻辑单元可以联合地或者单独地体现为形成更大系统的部分的电路,例如集成电路(IC)、片上系统(SOC)等。例如,逻辑单元可以体现在逻辑电路中以用于经由本文讨论的编码系统的固件或硬件的实现。本领域普通技术人员将领会到,由硬件和/或固件执行的操作可以可替换地经由软件实现,软件可以体现为软件封装、代码和/或指令集或指令,并且还领会到,逻辑单元也可以利用软件的部分来实现其功能性。
如在本文描述的任何实现中所使用的,术语“组件”可以是指模块或者逻辑单元,如以上描述的这些术语。相应地,术语“组件”可以是指配置成提供本文描述的功能性的软件逻辑、固件逻辑和/或硬件逻辑的任何组合。例如,本领域普通技术人员将领会到,由硬件和/或固件执行的操作可以可替换地经由软件模块实现,软件模块可以体现为软件封装、代码和/或指令集,并且还领会到,逻辑单元也可以利用软件的部分来实现其功能性。
参照图13,依照本公开的至少一些实现布置示例图像处理系统1300。在各种实现中,示例图像处理系统1300可以具有形成或者接收所捕获的图像数据的成像设备1302。这可以以各种方式实现。因而,在一种形式中,图像处理系统1300可以是数字相机或其它图像捕获设备,并且成像设备1302在该情况下可以是相机硬件和相机传感器软件、模块或组件。在其它示例中,成像处理系统1300可以具有包括或者可以为相机的成像设备1302,以及可以与成像设备1302远程地通信或者可以以其它方式通信耦合到成像设备1302以用于图像数据的进一步处理的逻辑模块1304。
在任一情况下,这样的技术可以包括相机,诸如数字相机系统、专用相机设备、网络摄像机或者成像电话,而不管是静止图片或视频相机还是二者的某种组合。因而,在一种形式中,成像设备1302可以包括相机硬件和光学器件,包括一个或多个传感器以及自动聚焦、变焦、光圈、ND滤波器、自动曝光、闪光灯和致动器控件。
图像处理系统1300的逻辑模块1304可以包括执行至少部分处理的图像单元1306或者与其通信。因而,图像单元1306可以执行预处理、编码和/或甚至后处理以使图像数据准备用于传送、存储和/或显示。在最低程度上,图像单元1306具有充足数据以执行面部检测和面部表情识别。
在所图示的示例中,逻辑模块1304还可以包括面部检测单元1301、特征提取单元1314和面部表情分类单元1316,它们执行以上描述的许多操作。这些单元可以由(多个)处理器1320操作或者甚至完全地或部分地位于(多个)处理器1320处,并且处理器1320可以包括ISP 1322以执行所述操作。逻辑模块可以通信耦合到成像设备1302的组件以便接收原始图像数据。在这些情况下,假设逻辑模块1304被视为与成像设备分离。并不必需如此,并且逻辑模块也可以非常好地被视为成像设备的部分。
图像处理系统1300可以具有一个或多个处理器1320、存储器存储装置1324、以及天线1308,一个或多个处理器1320可以包括专用图像信号处理器(ISP)1322,诸如Intel Atom,存储器存储装置1324可以或者可以不保持以上提及的面部检测和面部表情识别数据集中的一个或多个。在一种示例实现中,图像处理系统1300可以具有显示器1328、通信耦合到显示器的至少一个处理器1320、以及通信耦合到处理器以执行如上文解释的本文中描述的操作的至少一个存储器1324。可以具有编码器的图像单元1306和天线1308可以提供成压缩图像数据以用于传送给可以显示或存储图像的其它设备。将理解到,图像处理系统1300还可以包括解码器(或图像单元1306可以包括解码器)以接收和解码图像数据以便用于由系统1300处理。以其它方式,经处理的图像1330可以显示在显示器1328上或者存储在存储器1324中。如所图示的,这些组件中的任一个可以能够相互通信和/或与逻辑模块1304和/或成像设备1302的部分通信。因而,处理器1320可以通信耦合到图像设备1302和逻辑模块1304二者以用于操作那些组件。作为一种方案,尽管如在图13中示出的图像处理系统1300可以包括与特定组件或模块相关联的单元或动作的一个特定集合,但是这些单元或动作可以与和此处所图示的特定组件或模块不同的组件或模块相关联。
参照图14,依照本公开的示例系统1400操作本文描述的图像处理系统的一个或多个方面。将从下文描述的系统组件的本质理解到,这样的组件可以与以上描述的图像处理系统的某一个或多个部分相关联或者用于操作它,包括执行面部表情识别相关操作。在各种实现中,系统1400可以是媒体系统,尽管系统1400不限于该上下文。例如,系统1400可以并入数字静止相机、数字视频相机、具有相机或视频功能的移动设备中,诸如成像电话、网络摄像机、个人计算机(PC)、膝上型计算机、超级本计算机、平板电脑、触摸板、便携式计算机、手持式计算机、掌上计算机、个人数字助理(PDA)、蜂窝电话、组合蜂窝电话/PDA、电视、智能设备(例如,智能电话、智能平板电脑或智能电视)、移动互联网设备(MID)、消息设备、数据通信设备等。
在各种实现中,系统1400包括耦合到显示器1420的平台1402。平台1402可以从内容设备接收内容,内容设备诸如(多个)内容服务设备1430或者(多个)内容递送设备1440或者其它类似的内容源。包括一个或多个导航特征的导航控制器1450可以用于与例如平台1402和/或显示器1420交互。这些组件中的每一个在下文更详细地描述。
在各种实现中,平台1402可以包括芯片组1405、处理器1410、存储器1412、存储装置1414、图形子系统1415、应用1416和/或无线电1418的任何组合。芯片组1405可以提供处理器1410、存储器1412、存储装置1414、图形子系统1415、应用1416和/或无线电1418当中的相互通信。例如,芯片组1405可以包括能够提供与存储装置1414的相互通信的存储适配器(没有描绘)。
处理器1410可以实现为复杂指令集计算机(CISC)或精简指令集计算机(RISC)处理器;x86指令集兼容处理器、多核、或者任何其它微处理器或中央处理单元(CPU)。在各种实现中,处理器1410可以是(多个)双核处理器、(多个)双核移动处理器等。
存储器1412可以实现为易失性存储器设备,诸如但不限于随机存取存储器(RAM)、动态随机存取存储器(DRAM)或静态RAM(SRAM)。
存储装置1414可以实现为非易失性存储设备,诸如但不限于磁盘驱动器、光盘驱动器、带驱动器、内部存储设备、附连的存储设备、闪速存储器、电池备用SDRAM(同步DRAM)和/或网络可访问存储设备。在各种实现中,存储装置1414可以包括在例如包括多个硬盘驱动时增加用于有价值的数字媒体的存储性能增强保护的技术。
图形子系统1415可以执行诸如静止或视频之类的图像的处理以用于显示。图形子系统1415可以是图形处理单元(GPU)或者例如视觉处理单元(VPU)。模拟或数字接口可以用于通信地耦合图形子系统1415和显示器1420。例如,接口可以是高清晰度多媒体接口、显示端口、无线HDMI和/或无线HD兼容技术中的任一个。图形子系统1415可以集成到处理器1410或芯片组1405中。在一些实现中,图形子系统1415可以是通信耦合到芯片组1405的独立卡。
本文描述的图形和/或视频处理技术可以实现在各种硬件架构中。例如,图形和/或视频功能性可以集成在芯片组内。可替换地,可以使用分立的图形和/或视频处理器。作为又一种实现,图形和/或视频功能可以通过包括多核处理器的通用处理器提供。在另外的实现中,功能可以实现在消费者电子设备中。
无线电1418可以包括能够使用各种适当的无线通信技术传送和接收信号的一个或多个无线电。这样的技术可以牵涉到跨一个或多个无线网络的通信。每一个无线网络包括(但不限于)无线局域网(WLAN)、无线个域网(WPAN)、无线城域网(WMAN)、蜂窝网络和卫星网络。在跨这样的网络通信时,无线电1418可以依照任何版本的一个或多个合适的标准进行操作。
在各种实现中,显示器1420可以包括任何电视类型的监控器或显示器。显示器1420可以包括例如计算机显示屏、触摸屏显示器、视频监控器、电视类设备和/或电视。显示器1420可以是数字和/或模拟的。在各种实现中,显示器1420可以是全息显示器。而且,显示器1420可以是可以接收视觉投射的透明表面。这样的投射可以传达各种形式的信息、图像和/或对象。例如,这样的投射可以是用于移动增强现实(MAR)应用的视觉叠层。在一个或多个软件应用1416的控制之下,平台1402可以在显示器1420上显示用户接口1422。
在各种实现中,(多个)内容服务设备1430可以由任何全国、全球和/或独立的服务托管并且因而经由例如互联网对于平台1402可访问。(多个)内容服务设备1430可以耦合到平台1402和/或显示器1420。平台1402和/或(多个)内容服务设备1430可以耦合到网络1460以向以及从网络1460传达(例如,发送和/或接收)媒体信息。(多个)内容递送设备1440还可以耦合到平台1402和/或显示器1420。
在各种实现中,(多个)内容服务设备1430可以包括有线电视盒子、个人计算机、网络、电话、启用互联网的设备或者能够递送数字信息和/或内容的家电、以及能够在内容提供商和平台1402和/或显示器1420之间经由网络1460或者直接地单向或双向传达内容的任何其它类似设备。将领会到,内容可以经由网络1460向以及从系统1400和内容提供商中的组件中的任一个单向地和/或双向地传达。内容的示例可以包括任何媒体信息,包括例如视频、音乐、医用和游戏信息等。
(多个)内容服务设备1430可以接收内容,诸如有线电视节目,包括媒体信息、数字信息和/或其它内容。内容提供商的示例可以包括任何有线或卫星电视或无线电或互联网内容提供商。所提供的示例不意为以任何方式限制依照本公开的实现。
在各种实现中,平台1402可以从具有一个或多个导航特征的导航控制器1450接收控制信号。控制器1450的导航特征可以用于例如与用户接口1422交互。在实现中,导航控制器1450可以是指向设备,其可以是允许用户向计算机中输入空间(例如,连续和多维)数据的计算机硬件组件(具体地,人类接口设备)。许多系统,诸如图形用户界面(GUI)、以及电视和监控器,允许用户使用物理手势控制以及向计算机或电视提供数据。
控制器1450的导航特征的运动可以通过显示在显示器上的指针、光标、对焦光环或其它视觉指示符而在显示器(例如,显示器1420)上复制。例如,在软件应用1416的控制之下,位于导航控制器1450上的导航特征可以映射到例如显示在用户接口1422上的虚拟导航特征。在实现中,控制器1450可以不是分离的组件,而是可以集成到平台1402和/或显示器1420中。然而,本公开不限于本文示出或描述的上下文或者元件。
在各种实现中,驱动器(未示出)可以包括使得用户能够在初始启动之后(例如,在启用时)利用按钮的触碰即刻接通和关断平台1402的技术。程序逻辑可以允许平台1402将内容流式传送给媒体适配器或(多个)其它内容服务设备1430或(多个)内容递送设备1440,甚至是在平台“关断”时。此外,芯片组1405可以包括对于例如8.1环绕立体声和/或高清晰度(7.1)环绕立体声音频的硬件和/或软件支持。驱动器可以包括用于集成图形平台的图形驱动器。在实现中,图形驱动器可以包括外围组件互连(PCI)Express图形卡。
在各种实现中,在系统1400中示出的组件中的任何一个或多个可以是集成的。例如,平台1402和(多个)内容服务设备1430可以是集成的,或者平台1402和(多个)内容递送设备1440可以是集成的,或者平台1402、(多个)内容服务设备1430和(多个)内容递送设备1440可以例如是集成的。在各种实现中,平台1402和显示器1420可以是集成单元。显示器1420和(多个)内容递送设备1430可以是集成的,或者显示器1420和(多个)内容递送设备1440可以例如是集成的。这些示例不意为限制本公开。
在各种实现中,系统1400可以实现为无线系统、有线系统或二者的组合。当实现为无线系统时,系统1400可以包括适用于在无线共享介质之上进行通信的组件和接口,诸如一个或多个天线、传送器、接收器、收发器、放大器、滤波器、控制逻辑等。无线共享介质的示例可以包括无线频谱的部分,诸如RF频谱等。当实现为有线系统时,系统1900可以包括适用于在有线通信介质之上进行通信的组件和接口,诸如输入/输出(I/O)适配器、连接I/O适配器与对应有线通信介质的物理连接器、网络接口卡(NIC)、盘控制器、视频控制器、音频控制器等。有线通信介质的示例可以包括电线、电缆、金属引线、印刷电路板(PCB)、主平面、交换结构、半导体材料、双绞线、同轴电缆、纤维光学等等。
平台1402可以建立一个或多个逻辑或物理信道以传达信息。信息可以包括媒体信息和控制信息。媒体信息可以是指表示对于用户而言有意义的内容的任何数据。内容的示例可以例如包括来自语音会话、视频会议、流式传送视频、电子邮件(“email”)消息、语音邮件消息、字母数字符号、图形、图像、视频、文本等等的数据。来自语音会话的数据可以例如话语信息、沉默时段、背景噪声、舒适噪声、语调等。控制信息可以是指表示对于自动化系统而言有意义的命令、指令或控制词的任何数据。例如,控制信息可以用于使媒体信息路由通过系统,或者指令节点以预确定的方式处理媒体信息。然而,实现不限于在图14中描述或示出的上下文或元件。
参照图15,小形状因子设备1500是其中可以体现系统1400的变化的物理样式或形状因子的一个示例。通过该方案,设备1500可以实现为具有无线能力的移动计算设备。移动计算设备可以是指具有处理系统和移动电源或电力供应的任何设备,诸如例如一个或多个电池。
如上文所述,移动计算设备的示例可以包括数字静止相机、数字视频相机、具有相机或视频功能的移动设备,诸如成像电话、网络摄像机、个人计算机(PC)、膝上型计算机、超级本计算机、平板电脑、触摸板、便携式计算机、手持式计算机、掌上计算机、个人数字助理(PDA)、蜂窝电话、组合蜂窝电话/PDA、电视、智能设备(例如,智能电话、智能平板或智能电视)、移动互联网设备(MID)、消息设备、数据通信设备等。
移动计算设备的示例还可以包括布置成由用户佩戴的计算机,诸如手腕计算机、手指计算机、指环计算机、眼镜计算机、带扣计算机、腕带计算机、鞋子计算机、衣物计算机以及其它可穿戴计算机。在各种实现中,例如,移动计算设备可以实现为能够执行计算机应用以及语音通信和/或数据通信的智能电话。尽管可以利用作为示例实现为智能电话的移动计算设备描述一些实现,但是可以领会到,也可以使用其它无线移动计算设备实现其它实现。实现在该上下文中不受限制。
如图15中所示,设备1500可以包括外壳1502、包括屏幕1510的显示器1504、输入/输出(I/O)设备1506和天线1508。设备1500还可以包括导航特征1512。显示器1504可以包括用于显示对于移动计算设备适当的信息的任何适合的显示单元。I/O设备1506可以包括用于将信息录入移动计算设备中的任何适合的I/O设备。I/O设备1506的示例可以包括字母数字键盘、数字小键盘、触摸板、输入键、按钮、开关、摇臂开关、麦克风、扬声器、语音识别设备和软件等。还可以通过麦克风(未示出)的方式将信息录入设备1500。这样的信息可以通过语音识别设备(未示出)数字化。实现在该上下文中不受限制。
本文描述的各种形式的设备和过程可以使用硬件元件、软件元件或二者的组合来实现。硬件元件的示例可以包括处理器、微处理器、电路、电路元件(例如,晶体管、电阻器、电容器、电感器等)、集成电路、专用集成电路(ASIC)、可编程逻辑器件(PLD)、数字信号处理器(DSP)、现场可编程门阵列(FPGA)、逻辑门、寄存器、半导体器件、芯片、微芯片、芯片组等。软件的示例可以包括软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、功能、方法、过程、软件接口、应用程序接口(API)、指令集、计算代码、计算机代码、代码片段、计算机代码片段、字、值、符号或其任何组合。确定实现是否使用硬件元件和/或软件元件而实现可以依照任何数个因素而变化,诸如期望的计算率、电力水平、热容差、处理循环预算、输入数据率、输出数据率、存储器资源、数据总线速度以及其它设计或性能约束。
至少一种实现的一个或多个方面可以通过存储在机器可读介质上的代表性指令而实现,代表性指令表示处理器内的各种逻辑,代表性指令在由机器读取时使机器编制逻辑以执行本文描述的技术。称为“IP核”的这样的表示可以存储在有形的机器可读介质上并且供应给各种顾客或制造设施以便加载到实际做出逻辑或处理器的制造机中。
尽管已经参照各种实现描述了在本文中阐述的某些特征,但是该描述不意图以限制性含义来解释。因而,本文描述的实现以及对于本公开所属领域中的技术人员清楚的其它实现的各种修改被认为处于本公开的精神和范围内。
以下示例涉及另外的实现。
作为一个示例,一种计算机实现的面部表情识别的方法包括获取至少一个图像的图像数据,所述至少一个图像包括具有至少一个人的面部的内容;以及确定用于至少一个主标志的标志的至少一个子集,其中每一个主标志具有指示关于面部的面部特征的信息的数据。所述方法还可以包括确定至少一个主标志和标志的子集当中的关系;以及通过使用所述关系来使用区别性模型标记用于面部的面部表情分类。
作为另一种实现,所述方法可以包括所述关系是通过使用线性递归类型计算所确定的几何关系,并且所述方法可以包括形成用于多个主标志的多个子集;确定用于每一个子集的几何关系以形成几何关系的分组;以及使用几何关系的分组形成描述符以用于确定面部的面部表情分类。多个主标志中的每一个主标志具有作为主标志的单个子集而同时可用于在其它子集中作为邻居标志;并且其中子集重叠使得至少一个标志处于多于一个子集中。所述方法还可以包括对面部上的标志进行编号以形成索引,维持编号而同时形成关系,以及在与主标志的索引编号相同的数值次序中堆叠和级联关系以便形成描述符;并且其中每一个地理关系是地理关系值的向量,其中每一个值对应于子集中的标志。所述方法可以包括通过在根据对应于几何关系值的标志的索引编号的数值次序中,并且在通过主标志的索引编号针对子集所预留的描述符中的空间内,级联每一个子集中的地理关系值而使用地理关系值来形成描述符;并且其中描述符是包括值的向量,每一个值是当前帧上的子集和开头帧上的对应子集中的标志的值之间的主标志的几何关系中的差异。
作为其它方案,所述方法还包括通过在使用模型中的描述符之前使用主要组成分析(PCA)来减少描述符的维度;并且其中有以下中的至少一个:(1)比面部的所有标志少的多个标志各自具有用于确定面部的面部表情的邻居标志的子集;以及(2)面部的每一个标志具有在计算中使用的邻居标志的子集;并且其中有以下中的至少一个:(a)相对于主标志的所选数目的最近附近邻居标志包括在主标志的子集中,以及(b)距主标志的某一距离内的任何标志包括在主标志的子集中。以其它方式,子集中的标志的成员关系对于多个帧上的相同面部保持相同。所述方法可以包括追踪图像数据上的标志;通过使用参考面部形状数据对形成面部的图像数据进行归一化来形成经对准的面部形状;提取特征包括:使用参考面部形状数据确定子集,以及使用经对准的面部形状确定关系;以及使用区别性标记模型中的关系的组合提供用于面部的面部表情分类。将当前几何关系和之前帧处的对应几何关系之间的多个差异放置到潜在动态连续随机场(LDCRF)模型中以使面部表情分类与面部匹配;并且其中将多个差异组合到当前描述符中,并且LDCRF模型通过将当前描述符以及具有相同面部的之前帧的至少一个描述符计为因素来确定用于当前面部的面部表情分类。
作为又一种实现,一种计算机实现的面部表情识别的系统具有显示器、通信耦合到显示器的至少一个处理器、通信耦合到至少一个处理器并且存储至少一个静止照片或视频序列的至少一个帧的图像捕获数据的至少一个存储器;以及至少一个面部表情识别单元,其通信耦合到处理器并且用于:获取至少一个图像的图像数据,所述至少一个图像包括具有至少一个人的面部的内容;以及确定用于至少一个主标志的标志的至少一个子集,其中每一个标志具有指示关于面部的面部特征的信息的数据。至少一个面部表情识别单元还可以提供成确定标志的子集和至少一个主标志当中的关系;以及通过使用所述关系来使用区别性模型标记用于面部的面部表情分类。
作为另一个示例,所述系统包括所述关系为通过使用线性递归类型计算确定的几何关系;并且提供面部表情识别单元以:形成用于多个主标志的多个子集;确定用于每一个子集的几何关系以形成几何关系的分组;以及使用几何关系的分组形成描述符以用于确定面部的面部表情分类。多个主标志中的每一个主标志具有作为主标志的单个子集而同时可用于在其它子集中作为邻居标志;其中子集重叠使得至少一个标志处于多于一个子集中。面部表情识别单元对面部上的标志编号以形成索引,维持编号而同时形成关系,以及在与主标志的索引编号相同的数值序列中堆叠和级联关系以便形成描述符。而且,每一个地理关系是地理关系值的向量,其中每一个值对应于子集中的标志。面部表情识别单元通过在根据对应于几何关系值的标志的索引编号的数值次序中,并且在通过主标志的索引编号针对子集所预留的描述符中的空间内,级联每一个子集中的地理关系值来使用地理关系值形成描述符;并且其中描述符是包括值的向量,每一个值是当前帧上的子集和开头帧上的对应子集中的标志的值之间的主标志的几何关系中的差异。
作为其它方案,所述系统提供面部表情识别单元以通过在使用模型中的描述符之前使用主要组成分析(PCA)来减少描述符的维度;其中有以下中的至少一个:(1)比面部的所有标志少的多个标志各自具有用于确定面部的面部表情的邻居标志的子集;以及(2)面部的每一个标志具有在计算中使用的邻居标志的子集;并且其中有以下中的至少一个:(a)相对于主标志的所选数目的最近附近邻居标志包括在主标志的子集中,以及(b)距主标志的某一距离内的任何标志包括在主标志的子集中;其中子集中的标志的成员关系对于多个帧上的相同面部保持相同。而且,面部表情识别单元用于:追踪图像数据上的标志;通过使用参考面部形状数据对形成面部的图像数据进行归一化来形成经对准的面部形状;提取特征包括:使用参考面部形状数据确定子集,并且使用经对准的面部形状确定关系;以及使用区别性标记模型中的关系的组合来提供用于面部的面部表情分类。将当前几何关系和之前帧处的对应几何关系之间的多个差异放置到潜在动态连续随机场(LDCRF)模型中以使面部表情分类与面部匹配;并且其中将多个差异组合到当前描述符中,并且LDCRF模型通过将到当前描述符和具有相同面部的之前帧的至少一个描述符计为因素来确定用于当前面部的面部表情分类。
作为一种方案,至少一个计算机可读物品包括多个指令,所述多个指令响应于在计算设备上执行而使计算设备:获取至少一个图像的图像数据,所述至少一个图像包括具有至少一个人的面部的内容;以及确定用于至少一个主标志的标志的至少一个子集,其中每一个标志具有指示关于面部的面部特征的信息的数据。还可以使计算设备确定至少一个主标志和标志的子集当中的关系;并且通过使用所述关系而使用区别性模型标记用于面部的面部表情分类。
作为另一方案,指令包括所述关系为通过使用线性递归类型计算所确定的几何关系;并且使计算设备:形成用于多个主标志的多个子集;确定用于每一个子集的几何关系以形成几何关系的分组;以及使用几何关系的分组形成描述符以用于确定面部的面部表情分类;其中多个主标志中的每一个主标志具有作为主标志的单个子集而同时可用于在其它子集中作为邻居标志;其中子集重叠使得至少一个标志处于多于一个子集中;使计算设备对面部上的标志编号以形成索引,维持编号而同时形成关系,以及在与主标志的索引编号相同的数值次序中堆叠和级联关系以便形成描述符;并且其中每一个地理关系是地理关系值的向量,其中每一个值对应于子集中的标志。使计算设备通过在根据对应于几何关系值的标志的索引编号的数值次序中,并且在通过主标志的索引编号针对子集所预留的描述符中的空间内,级联每一个子集中的地理关系值来使用地理关系值形成描述符;其中描述符是包括值的向量,每一个值是当前帧上的子集和开头帧上的对应子集中的标志的值之间的主标志的几何关系中的差异。
作为其它方案,指令使计算设备通过在使用模型中的描述符之前使用主要组成分析(PCA)来减少描述符的维度;其中有以下中的至少一个:(1)比面部的所有标志少的多个标志各自具有用于确定面部的面部表情的邻居标志的子集;以及(2)面部的每一个标志具有在计算中使用的邻居标志的子集;其中有以下中的至少一个:(a)相对于主标志的所选数目的最近附近邻居标志包括在主标志的子集中,以及(b)距主标志的某一距离内的任何标志包括在主标志的子集中;并且其中子集中的标志的成员关系对于多个帧上的相同面部保持相同。使计算设备:追踪图像数据上的标志;通过使用参考面部形状数据对形成面部的图像数据进行归一化来形成经对准的面部形状;提取特征包括:使用参考面部形状数据确定子集,并且使用经对准的面部形状确定关系;以及使用区别性标记模型中的关系的组合来提供用于面部的面部表情分类;其中将当前几何关系和之前帧处的对应几何关系之间的多个差异放置到潜在动态连续随机场(LDCRF)模型中以使面部表情分类与面部匹配;并且其中将多个差异组合到当前描述符中,并且LDCRF模型通过将当前描述符和具有相同面部的之前帧的至少一个描述符计为因素来确定用于当前面部的面部表情分类。
在另外的示例中,至少一个机器可读介质可以包括多个指令,所述多个指令响应于在计算设备上执行而使计算设备执行根据以上示例中的任一个的方法。
在又另外的示例中,一种装置可以包括用于执行根据以上示例中的任一个的方法的部件。
以上示例可以包括特征的具体组合。然而,以上示例在该方面不受限制,并且在各种实现中,以上示例可以包括仅承担这样的特征的子集,承担这样的特征的不同次序,承担这样的特征的不同组合,和/或承担除那些明确列出的特征之外的附加特征。例如,关于本文中的任何示例方法描述的所有特征可以关于任何示例装置、示例系统和/或示例物品而实现,并且反之亦然。
- 还没有人留言评论。精彩留言会获得点赞!