信息发布方法和系统与流程
本发明涉及计算机技术,具体涉及信息发布方法和信息发布系统。
背景技术:
当前,互联网在人们的日常生活中已变得越来越重要,人们使用互联网的频率越来越高,人们的学习、生活、工作、娱乐等各种活动均可通过互联网来进行。而通过互联网来获取信息是人们使用互联网的一个重要方面。
如何通过互联网向用户发布适当的或者说用户所需要的信息成为了当前研究的热点。例如,当用户利用搜索引擎搜索某个检索词以期望获取关于该检索词的信息时,该搜索引擎的运营商可在搜索引擎界面上向用户发布与其所输入的检索词相关的广告内容。这一方面为用户带来了方便,另一方面也为相关厂商带来的商机。
在现有技术中,搜索引擎的广告发布主要有两种方式。一种是检索词匹配,即利用用户输入的检索词,在所有广告的描述性语句中匹配输入的检索词,如果有相应的匹配广告,即将广告显示在界面上。不过这种方法有自身的缺陷,即当没有搜索到匹配的广告时,将没有广告显示给用户。此外,针对复杂的用户输入,存在一定的准确性问题。另外一种方法是判断检索词所属的行业类别,然后推荐该行业内的广告,不过在目前环境下,所有检索词的行业类别标注工作都是人工进行的,效率低下。而且对于尚未标注行业类别的检索词,也将无法进行处理。
类似地,在其他应用场景中,也具有类似的需求。即,根据用户输入的内容向用户提供适当的或用户需要的信息,以满足用户的相关需求。
技术实现要素:
有鉴于此,本发明提出了一种信息发布方法和信息发布系统,以根据用户输入的检索词向用户发布适当的或用户需要的信息。
根据本发明的一个方面,提供了一种信息发布方法,包括:对用户输入的检索词进行扩展;计算扩展的结果与多个行业类别中的每个行业类别的相关度得分;以及向用户发布与所述检索词具有最高相关度得分的行业类别相关联的信息。
根据本发明的另一方面,提供了一种信息发布系统,包括:扩展装置,对用户输入的检索词进行扩展;计算装置,计算所述扩展装置的扩展结果与多个行业类别中的每个行业类别的相关度得分;以及发布装置,向用户发布与所述检索词具有最高相关度得分的行业类别相关联的信息。
根据本发明所提供的技术方案,可以根据用户输入的检索词向用户发布适当的或用户需要的信息。
附图说明
参照附图来阅读本发明的各实施方式,将更容易理解本发明的其它特征和优点,在此描述的附图只是为了对本发明的实施方式进行示意性说明的目的,而非全部可能的实施,并且不旨在限制本发明的范围。在附图中:
图1示出了根据本发明一个实施方式的信息发布方法的流程图;
图2示出了根据本发明一个实施方式对用户输入的检索词进行扩展的流程图;
图3示出了根据本发明一个实施方式的分布式分类模型训练的流程图;
图4示出了根据本发明一个实施方式在每个计算节点上训练与一个行业类别相关的支持向量机模型的流程图;
图5示出了根据本发明一个实施方式的信息发布系统的框图;
图6示出了根据本发明一个实施方式的扩展装置的框图;
图7示出了根据本发明一个实施方式的计算装置的框图;以及
图8示出了可用于实施根据本发明实施例的方法和系统的计算机的示意性框图。
具体实施方式
现参照附图对本发明的实施方式进行详细描述。应注意,以下描述仅 仅是示例性的,而并不旨在限制本发明。此外,在以下描述中,将采用相同的附图标号表示不同附图中的相同或相似的部件。在以下描述的不同实施方式中的不同特征,可彼此结合,以形成本发明范围内的其他实施方式。
图1示出了根据本发明一个实施方式的信息发布方法的流程图。如图1所示,信息发布方法100包括步骤S110至S130。当用户搜索某个检索词以期望获取关于该检索词的信息时,在步骤S110中,对用户输入的检索词进行扩展,扩展的目的是为了便于后续的计算。在得到扩展的结果后,在步骤S120中,针对多个行业类别,计算扩展的结果与每个行业类别的相关度得分。相关度得分表征了检索词与某个行业的相关程度,相关程度越高,则相关度得分越高,其具体计算方式将在下面详述。根据计算得到的相关度得分,在步骤S130中,向用户发布与该检索词具有最高相关度得分的行业类别相关联的信息。
根据本发明的该实施方式,根据用户输入的检索词,通过对其进行扩展,从而能够计算出该检索词与各个行业类别的相关程度。那么可认为与该检索词相关程度最高的行业类别就是其所属行业类别。由此,可向用户发布与该行业类别相关联的信息,这样的信息则很有可能是用户所需要的信息,从而既方便了用户,又实现了信息的目的性发布。
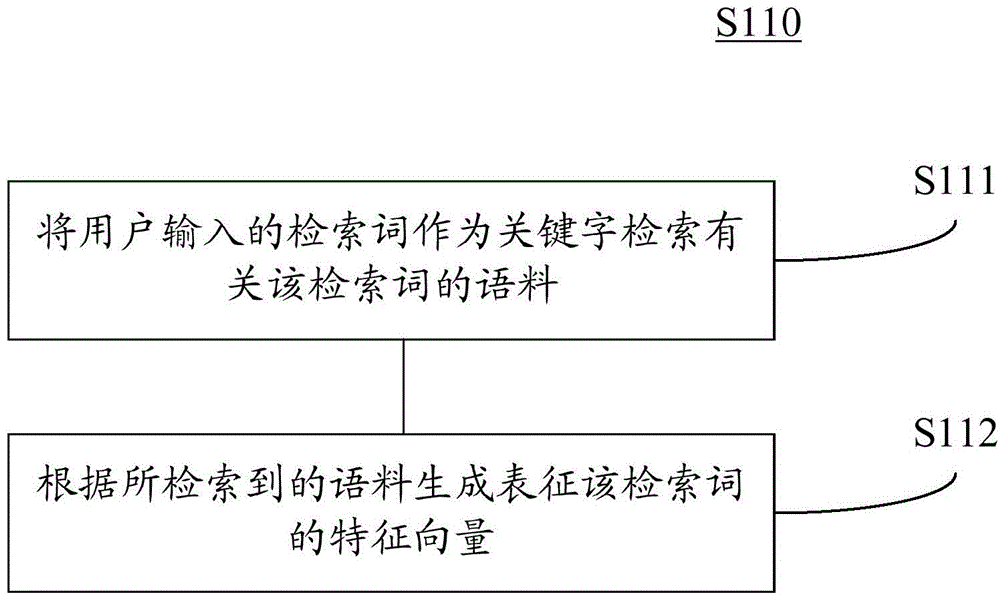
图2示出了根据本发明一个实施方式对用户输入的检索词进行扩展的流程图。如图2所示,上述步骤S110可包括子步骤S111和S112。在子步骤S111中,将用户输入的检索词作为关键字检索有关该检索词的语料。根据一个实施例,可利用任何现有的搜索引擎或数据库或本领域技术人员已知的其他方式检索关键字的语料。所检索到的语料可以包含短语、句子、段落和/或文章。然后,在子步骤S112中,根据所检索到的语料生成表征该检索词的特征向量。该特征向量即为扩展的结果,用于后续的计算。
根据本发明一个实施方式,表征检索词的特征向量可包含这样的特征,这些特征可以表征从该检索词的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息。
下面将示例性地说明表征检索词的特征向量所包含的特征的计算方式。假定已通过搜索引擎检索到检索词的多篇语料。由于通常检索到的结果的数量会非常多,可以选择其中前t个检索结果作为后续处理需要使用的语料,这是本领域技术人员根据实际操作中的需要可以实现的选择。可用下式表示检索词k的语料Corpus(k):
其中表示检索词k的第j篇语料。上述公式中的符号Σ可表示将多篇语料结合到一起。
在得到检索词k的语料Corpus(k)后,可根据其生成检索词k的特征向量Feature(k),其中特征向量Feature(k)可包含表征从该检索词的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
根据一个实施例,可通过下式计算表征从检索词k的语料中提取的文本分割结果的特征f1k:
f1k=Seg(Corpus(k)) (2)
其中Seg是文本分割函数。
根据另一实施例,可通过下式计算表征从检索词k的语料中提取的上下文信息的特征
其中,NGram表示N-Gram算法。例如,假定N-Gram算法中的N为4,用户输入的检索词的语料中包含“连锁酒店”四个字,那么用N-Gram算法得到的特征为“连锁酒店”、“连锁酒”、“锁酒店”、“连锁”、“锁酒”和“酒店”。
根据又一实施例,可通过下式计算表征从检索词k的语料中提取的相邻词组合信息的特征
其中,Combination是相邻词组合函数。例如,用户输入的检索词的语料中包含“园区星湖街创意产业园”,利用上述公式2所得到的文本分割结果为:“园区星湖街创意产业园”,则利用公式4的相邻词组合函数,我们可以得到以下特征:“园区星湖街”、“园区创意”、“园区产业园”、“星湖街创意”、“星湖街产业园”和“创意产业园”。
当检索词k的特征向量包含表征从检索词k的语料中提取的文本分割结果、上下文信息和相邻词组合信息的特征时,可用下式表示检索词k的特征向量:
根据本发明的一个实施方式,上述步骤S120包括分别在多个计算节点上利用多个支持向量机模型分别计算特征向量与多个行业类别的相关度得分,其中每个支持向量机模型均是已经过分布式分类模型训练的模型。由此,采用多个计算节点进行计算,在每个计算节点上,均由一个已经过训练的支持向量机模型对检索词的特征向量相对于一个行业类别进行分类计算,以得出该检索词是否属于该行业类别的概率分数,作为相关度得分。这样,避免了仅在一个计算节点上计算特征向量与所有行业类别的相关度得分所带来的计算时间过长的问题。
对于支持向量机模型而言,如何利用训练数据对其进行训练,也是本发明所需要关注的问题之一。如本领域技术人员所知,此处所指的支持向量机模型能够将一个检索词确定为属于某个行业类别,或不属于某个行业类别。
图3示出了根据本发明一个实施方式的分布式分类模型训练的流程图。如图3所示,分布式分类模型训练300包括步骤S310和S320。在步骤S310中,将训练数据分别发送至多个计算节点。根据一个实施例,训练数据包括已标记行业类别的多个预设的关键字的特征向量。由于已知关键字的行业类别,因此可以利用训练数据在每个计算节点上对每个支持向量机模型进行训练,以使其达到正确分类的目的。
在步骤S320中,在每个计算节点上,利用接收到的训练数据训练与一个行业类别相关的支持向量机模型。这样,在每个计算节点上,均训练了一个支持向量机模型,用于对检索词是否属于一个行业类别的概率进行计算,以得到相关度得分。
与以上关于用户输入的检索词的相关描述类似,在训练数据中,已标记行业类别的每个预设的关键字的特征向量均可包含表征从该预设的关键字的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。而且,每个预设的关键字的语料可包括检索到的与该预设的关键字相关的语料的至少一部分。
对于已知行业类别的预设的关键字,其特征向量也可根据上述公式1-5中的一个或多个来计算得到,在此不再详述。但对于多个已知行业类别的关键字而言,其特征向量的维度可能不同,为了便于对支持向量机模型的训练,可在训练前先统一所有关键词的特征向量维度。根据本发明的 一个实施例,可通过下式来统一多个关键词pi的特征向量维度:
其中我们采用向量D来表示每一个关键词的特征。
图4示出了根据本发明一个实施方式在每个计算节点上训练与一个行业类别相关的支持向量机模型的流程图。如图4所示,上述步骤S320包括子步骤S321和S322。在子步骤S321中,在每个计算节点上将接收到的训练数据分割成多个数据段。随后,在子步骤S322中,在每个计算节点上顺序处理多个数据段,以训练支持向量机模型。对于数据量较大的训练数据,在一个计算节点上,可能在计算时会发生内存溢出的问题。对此,如上所述,将训练数据分割成多个数据段,并顺序处理这些数据段,由此可解决上述问题。此外,可以理解,在对训练数据进行分割时,处于数据分割面附近的训练数据样本通常更能够反映一个支持向量机模型的特性。根据本发明的一个实施方式,上述子步骤S322可包括:在每个计算节点上处理完每个数据段后,存储该数据段中最接近数据分割面的数据样本,并且在处理下一个数据段时,将所存储的数据样本添加至该下一个数据段进行处理。这样,就能够在下一个数据段再次利用该邻近数据分割面的训练数据样本,从而能够获得更好的训练效果。
图5示出了根据本发明一个实施方式的信息发布系统的框图。如图5所示,信息发布系统500可包括扩展装置510、计算装置520和发布装置530。扩展装置510可对用户输入的检索词进行扩展。计算装置520可计算扩展装置510的扩展结果与多个行业类别中的每个行业类别的相关度得分。发布装置530可向用户发布与其输入的检索词具有最高相关度得分的行业类别相关联的信息。
图6示出了根据本发明一个实施方式的扩展装置的框图。如图6所示,扩展装置510可包括检索单元511和生成单元512。检索单元511可将用户输入的检索词作为关键字检索有关该检索词的语料。生成单元512可根据检索词的语料生成表征该检索词的特征向量,以作为扩展的结果。
根据本发明的一个实施方式,生成单元512所生成的特征向量可包含表征从检索词的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
可利用上述公式1-5中的一个或多个计算表征检索词的特征向量所包含的特征,其计算过程在此不再详述。
图7示出了根据本发明一个实施方式的计算装置的框图。如图7所示,计算装置520可包括多个计算节点521-1至521-n以及分发单元522。分发单元522可将训练数据分别发送至计算节点521-1至521-n,而每个计算节点利用从分发单元522接收到的训练数据,训练与一个行业类别相关的支持向量机模型,并利用已经过训练的支持向量机模型计算特征向量与该行业类别的相关度得分。根据本发明的一个实施例,训练数据包括已标记行业类别的多个预设的关键字的特征向量。
根据本发明的一个实施方式,在训练数据中,已标记行业类别的每个预设的关键字的特征向量均可包含表征从该预设的关键字的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。而且,每个预设的关键字的语料可包括检索到的与该预设的关键字相关的语料的至少一部分。
对于已知行业类别的预设的关键字,其特征向量也可根据上述公式1-5中的一个或多个来计算得到,在此不再详述。但对于多个已知行业类别的关键字而言,其特征向量的维度可能不同,为了便于对支持向量机模型的训练,可利用上述公式6在训练前先统一所有关键词的特征向量维度。
根据本发明的一个实施方式,计算节点521-1至521-n中的每个均包括:数据分割模块,其用于将从分发单元522接收到的训练数据分割成多个数据段,每个计算节点顺序处理这些数据段,以训练支持向量机模型。
根据本发明的一个实施方式,每个计算节点在处理完已分割的多个数据段中的每个数据段后,可存储该数据段中最接近数据分割面的数据样本,并且在处理下一个数据段时,将所存储的数据样本添加至下一个数据段进行处理。
另外,这里尚需指出的是,上述系统中各个组成部件可以通过软件、固件、硬件或其组合的方式进行配置。配置可使用的具体手段或方式为本领域技术人员所熟知,在此不再赘述。在通过软件或固件实现的情况下,从存储介质或网络向具有专用硬件结构的计算机(例如图8所示的通用计算机800)安装构成该软件的程序,该计算机在安装有各种程序时,能够执行各种功能等。
图8示出了可用于实施根据本发明实施例的方法和系统的计算机的示意性框图。
在图8中,中央处理单元(CPU)801根据只读存储器(ROM)802中存储的程序或从存储部分808加载到随机存取存储器(RAM)803的程序执行各种处理。在RAM 803中,还根据需要存储当CPU 801执行各种处理等等时所需的数据。CPU 801、ROM 802和RAM 803经由总线804彼此连接。输入/输出接口805也连接到总线804。
下述部件连接到输入/输出接口805:输入部分806(包括键盘、鼠标等等)、输出部分807(包括显示器,比如阴极射线管(CRT)、液晶显示器(LCD)等,和扬声器等)、存储部分808(包括硬盘等)、通信部分809(包括网络接口卡比如LAN卡、调制解调器等)。通信部分809经由网络比如因特网执行通信处理。根据需要,驱动器810也可连接到输入/输出接口805。可拆卸介质811比如磁盘、光盘、磁光盘、半导体存储器等等可以根据需要被安装在驱动器810上,使得从中读出的计算机程序根据需要被安装到存储部分808中。
在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质811安装构成软件的程序。
本领域的技术人员应当理解,这种存储介质不局限于图8所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质811。可拆卸介质811的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(CD-ROM)和数字通用盘(DVD))、磁光盘(包含迷你盘(MD)(注册商标))和半导体存储器。或者,存储介质可以是ROM 802、存储部分808中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。
本发明还提出一种存储有机器可读取的指令代码的程序产品。所述指令代码由机器读取并执行时,可执行上述根据本发明实施方式的方法。
相应地,用于承载上述存储有机器可读取的指令代码的程序产品的存储介质也包括在本发明的范围内。所述存储介质包括但不限于软盘、光盘、磁光盘、存储卡、存储棒等等。
应当注意,本发明的方法不限于按照说明书中描述的时间顺序来执行,也可以按照其他的次序顺序地、并行地或独立地执行。因此,本说明书中描述的方法的执行顺序不对本发明的技术范围构成限制。
以上对本发明各实施方式的描述是为了更好地理解本发明,其仅仅是示例性的,而非旨在对本发明进行限制。应注意,在以上描述中,针对一 种实施方式描述和/或示出的特征可以以相同或类似的方式在一个或更多个其它实施方式中使用,与其它实施方式中的特征相组合,或替代其它实施方式中的特征。本领域技术人员可以理解,在不脱离本发明的发明构思的情况下,针对以上所描述的实施方式进行的各种变化和修改,均属于本发明的范围内。
综上,在根据本发明的实施例中,本发明提供了如下技术方案。
方案1.一种信息发布方法,包括:
对用户输入的检索词进行扩展;
计算扩展的结果与多个行业类别中的每个行业类别的相关度得分;以及
向用户发布与所述检索词具有最高相关度得分的行业类别相关联的信息。
方案2.如方案1所述的方法,其中对用户输入的检索词进行扩展的步骤包括:
将所述检索词作为关键字检索有关所述检索词的语料;以及
根据所述检索词的语料生成表征所述检索词的特征向量,作为所述扩展的结果。
方案3.如方案2所述的方法,其中所述检索词的特征向量包含表征从所述检索词的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
方案4.如方案3所述的方法,
其中表征从所述检索词的语料中提取的文本分割结果的特征通过下式计算:
f1k=Seg(Corpus(k))
其中,Seg是文本分割函数,Corpus(k)表示检索词k的语料,
其中表征从所述检索词的语料中提取的上下文信息的特征通过下式计算:
其中,NGram表示N-Gram算法,Corpus(k)表示检索词k的语料,并且
其中表征从所述检索词的语料中提取的相邻词组合信息的特征通过下式计算:
其中,Combination是相邻词组合函数。
方案5.如方案2-4中任一项所述的方法,其中计算扩展的结果与多个行业类别中的每个行业类别的相关度得分的步骤包括:分别在多个计算节点上利用已经过分布式分类模型训练的多个支持向量机模型分别计算所述特征向量与所述多个行业类别的相关度得分,并且
其中,所述分布式分类模型训练包括:
将训练数据分别发送至所述多个计算节点;以及
利用所述训练数据在每个计算节点上训练与一个行业类别相关的支持向量机模型。
方案6.如方案5所述的方法,其中所述训练数据包括已标记行业类别的多个预设的关键字的特征向量。
方案7.如方案6所述的方法,其中已标记行业类别的每个预设的关键字的特征向量包含表征从该预设的关键字的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
方案8.如方案7所述的方法,其中每个预设的关键字的语料包括检索到的与该预设的关键字相关的语料的至少一部分。
方案9.如方案6-8中任一项所述的方法,其中利用所述训练数据在每个计算节点上训练与一个行业类别相关的支持向量机模型的步骤包括:
在每个计算节点上将接收到的所述训练数据分割成多个数据段;以及
在每个计算节点上顺序处理所述多个数据段,以训练支持向量机模型。
方案10.如方案9所述的方法,其中在每个计算节点上顺序处理所述多个数据段的步骤包括:
在每个计算节点上处理完所述多个数据段中的每个数据段后,存储该数据段中最接近数据分割面的数据样本,并且在处理下一个数据段时,将所存储的数据样本添加至所述下一个数据段进行处理。
方案11.一种信息发布系统,包括:
扩展装置,对用户输入的检索词进行扩展;
计算装置,计算所述扩展装置的扩展结果与多个行业类别中的每个行业类别的相关度得分;以及
发布装置,向用户发布与所述检索词具有最高相关度得分的行业类别相关联的信息。
方案12.如方案11所述的系统,其中所述扩展装置包括:
检索单元,将所述检索词作为关键字检索有关所述检索词的语料;以及
生成单元,根据所述检索词的语料生成表征所述检索词的特征向量,作为所述扩展的结果。
方案13.如方案12所述的系统,其中所述生成单元所生成的特征向量包含表征从所述检索词的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
方案14.如方案13所述的系统,
其中所述生成单元通过下式计算表征从所述检索词的语料中提取的文本分割结果的特征:
f1k=Seg(Corpus(k))
其中,Seg是文本分割函数,Corpus(k)表示检索词k的语料,
其中所述生成单元通过下式计算表征从所述检索词的语料中提取的上下文信息的特征:
其中,NGram表示N-Gram算法,Corpus(k)表示检索词k的语料,并且
其中所述生成单元通过下式计算表征从所述检索词的语料中提取的相邻词组合信息的特征:
其中,Combination是相邻词组合函数。
方案15.如方案12-14中任一项所述的系统,其中所述计算装置包括:
多个计算节点;
分发单元,将训练数据分别发送至所述多个计算节点,所述多个计算节点中的每个计算节点利用从所述分发单元接收到的训练数据,训练与一个行业类别相关的支持向量机模型,并利用已经过训练的支持向量机模型计算特征向量与所述一个行业类别的相关度得分。
方案16.如方案15所述的系统,其中所述训练数据包括已标记行业类别的多个预设的关键字的特征向量。
方案17.如方案16所述的系统,其中已标记行业类别的每个预设的关键字的特征向量包含表征从该预设的关键字的语料中提取的文本分割结果、上下文信息和/或相邻词组合信息的特征。
方案18.如方案17所述的系统,其中每个预设的关键字的语料包括检索到的与该预设的关键字相关的语料的至少一部分。
方案19.如方案16-18中任一项所述的系统,其中每个计算节点均包括:数据分割模块,用于将接收到的训练数据分割成多个数据段,每个计算节点顺序处理所述多个数据段,以训练支持向量机模型。
方案20.如方案19所述的系统,其中每个计算节点在处理完所述多个数据段中的每个数据段后,存储该数据段中最接近数据分割面的数据样本,并且在处理下一个数据段时,将所存储的数据样本添加至所述下一个数据段进行处理。
- 还没有人留言评论。精彩留言会获得点赞!