一种个性化信息推送时间的确定方法及确定系统与流程
本发明涉及电子商务领域中的信息推送领域,具体来说,涉及一种个性化信息推送时间的确定方法及确定系统。
背景技术:
目前,很多网站在关于会员精准营销(例如电子邮件营销EDM,短信息服务SMS,服务信息PUSH等渠道)发送周期和频次方面,仅仅是根据经验主观判断决定发送时间和发送周期。这一方面造成成本浪费,另一方面在不恰当的时机推送信息,影响用户体验,导致客户流失。为了避免无节制的EDM,SMS和PUSH等狂轰滥炸式的、无规律的营销方式,如何选择合适的时间,向用户推送信息成为本领域的一个技术难题。
技术实现要素:
本发明实施例提供一种个性化信息推送时间的确定方法及确定系统,基于用户行为反馈,选择合适时间给用户进行信息推送,避免盲目推送信息,影响用户体验。
为解决上述技术问题,本发明实施例根据如下的技术方案:
一方面,本实施例提供一种个性化信息推送时间的确定方法,该方法包括以下步骤:
S10采集用户在电子商务网站的历史访问记录,构建特征向量;
S20根据S10构建的特征向量,利用生存分析模型对用户进行分类;
S30对S20分类后的每一类用户,分别确定信息推送时间。
作为一种实施例,所述的步骤S10中,根据用户注册时间和访问的历史记录,将用户分为老用户和新用户。
作为一种实施例,所述的步骤S10中,用户在电子商务网站的历史访问记录包括用户在PC端、APP端以及WAP端的历史行为记录。
作为一种实施例,所述的步骤S20中,运用生存分析模型对老用户和新用户分别进行分类,首先利用式(1)测算用户的特征值:
COX=X1*B1+X2*B2+…+Xn*Bn 式(1)
式(1)中,COX表示用户的特征值,X1表示该用户的第一个特征向量,B1表示X1的对应系数,X2表示该用户的第二个特征向量,B2表示X2的对应系数,Xn表示该用户的第n个特征向量,Bn表示Xn的对应系数;n为大于等于3的整数;
然后根据各用户的特征值和事先设定的阈值,对老用户和新用户分别进行分类。
作为一种实施例,所述的步骤S30,对于老用户中每类用户,利用逻辑回归模型测算用户未来W天最有可能回访或者最有可能购买的概率,然后按照事先设定的概率阈值,进行比较后,选择推送时间;对于新用户中每类用户,根据事先设定确定推送时间。
作为一种实施例,所述的逻辑回归模型如式(2)所示,
P=exp(A0+Y1*A1+Y2*A2+…+Yn*An)/(1+exp(A0+Y1*A1+Y2*A2+…+Yn*An))式(2)
式(2)中,P表示用户最有可能回访或者最有可能购买的概率,A0表示常数项,Y1表示影响用户购买行为的第一因素,A1表示Y1的对应系数,Y2表示影响用户购买行为的第二因素,A2表示Y2的对应系数,Yn表示影响用户购买行为的第n因素,An表示Yn的对应系数;n为大于等于3的整数。
另一方面,本实施例提供一种个性化信息推送时间的确定系统,该系统包括:
采集模块:用于采集用户在电子商务网站的历史访问记录;
构建模块:用于利用采集模块采集的历史访问记录,构建特征向量;
分类模块:用于根据构建模块构建的特征向量,利用生存分析模型对用户进行分类;
确定模块:用于根据分类模块对用户的分类,确定向每一类用户推送信息的时间。
作为一种实施例,所述的分类模块运用生存分析模型对用户进行分类:首先利用式(1)测算用户的特征值:
COX=X1*B1+X2*B2+…+Xn*Bn 式(1)
式(1)中,COX表示用户的特征值,X1表示该用户的第一个特征向量,B1表示X1的对应系数,X2表示该用户的第二个特征向量,B2表示X2的对应系数,Xn表示该用户的第n个特征向量,Bn表示Xn的 对应系数;n为大于等于3的整数;
然后根据各用户的特征值和事先设定的阈值,对老用户和新用户分别进行分类。
作为一种实施例,所述的确定模块包括:
测算子模块:用于对老用户利用逻辑回归模型测算用户未来最有可能回访或者最有可能购买的概率;
比较子模块:用于将测算子模块测算的概率,与事先设定的概率阈值,进行比较;
确定子模块:用于根据比较子模块的比较结果,确定推送时间。
作为一种实施例,所述的逻辑回归模型如式(2)所示,
P=exp(A0+Y1*A1+Y2*A2+…+Yn*An)/(1+exp(A0+Y1*A1+Y2*A2+…+Yn*An))式(2)
式(2)中,A0表示常数项,Y1表示影响用户购买行为的第一因素,A1表示Y1的对应系数,Y2表示影响用户购买行为的第二因素,A2表示Y2的对应系数,Yn表示影响用户购买行为的第n因素,An表示Yn的对应系数;n为大于等于3的整数。
本发明实施例提供的一种个性化信息推送时间的确定方法及确定系统,根据用户在电子商务网站的历史访问记录,构建特征向量。利用该特征向量,对用户进行分类,以及测算其回访或购物概率,从而确定推送时间。本实施例对用户进行信息推送,是依据用户的历史行为测算得带的,更符合用户的需求。同时,本实施例对用户进行信息推送,是依据不同分类的用户分别进行的,而不是所有用户都采用同 一推送时间。这使得信息推送能够因人而异,实现精准推送,更符合用户的需求,提高用户体验。
附图说明
图1是本发明实施例的流程框图。
图2是本发明实施例的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚的描述。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部实施例。
如图1所述,本发明实施例提供了一种个性化信息推送时间的确定方法,该方法包括以下步骤:
S10采集用户在电子商务网站的历史访问记录,构建特征向量;
S20根据S10构建的特征向量,利用生存分析模型对用户进行分类;
S30对S20分类后的每一类用户,分别确定信息推送时间。
上述方法中,确定信息推送时间时,首先采集用户在电子商务网站的历史访问记录,构建特征向量。也就是说,推送时间的确定,需要依据用户的历史访问记录,而不是人为任意设定一时间。正是基于构建的特征向量,后续步骤对用户进行分类以及计算用户的购买或回访概率。对用户进行分类后,对每类用户分别确定推送时间,而不是 所有用户都采用同一推送时间。这使得信息推送能够因人而异,实现精准推送,更符合用户的需求,提高了用户体验。
步骤S10中,用户在电子商务网站的历史访问记录包括用户在PC端、APP端以及WAP端的历史行为记录。用户在电子商务网站的历史访问记录,例如:用户根据用户名/密码等登录电子商务网站,点击、商品搜索与查询、浏览、页面停留、将商品放入购物车、询价、与客服人员交互、确认支付、要求售后服务。步骤S10采集的历史访问记录来源于多终端。多终端的数据来源,确保了构建特征向量更加丰富、完整,为后续步骤提供了良好的数据基础。根据用户注册时间和访问的历史记录,将用户分为老用户和新用户。新用户是指当天注册的用户,包括有历史访问记录或者没有历史访问记录的。老用户是指非当天注册的用户,包括有历史访问记录或者没有历史访问记录。
对于老用户而言,构建的特征向量,例如可以是:是否电话验证:IS_PHONE_VERIFY、是否邮箱验证:IS_EMAIL_VERIFY、注册至今天数:RGST_TIME、是否访问列表页:在最近2天是否访问列表页、是否访问商品详情页、最近2天是否访问、是否访问促销页、是否访问注册页等等。
对于新用户而言,构建的特征向量,例如可以是:浏览页面数、浏览四级页面、浏览促销页、浏览订单查询页、浏览来自app的占比、浏览时间在0点~7点的占比、浏览时间在19点到第二天0点的占比、购买单品数等等。
显然,上面所述的特征向量仅仅是例举。在实际中可以根据不同情形设置不同的特征向量。
为实现精准推送信息,需要对各用户分别推送信息。为提高推送效率,对老用户和新用户进行分类,使得用户的分类层次更多。信息向多种分类的用户分别推送,实现在不同的时间向不同分类的用户推送信息,在相同的时间向同一分类的用户推送信息。对老用户和新用户进行分类的方法有很多。本实施例优选运用生存分析模型对老用户和新用户分别进行分类。具体方法如下:
首先利用式(1)测算用户的特征值:
COX=X1*B1+X2*B2+…+Xn*Bn 式(1)
式(1)中,COX表示用户的特征值,X1表示该用户的第一个特征向量,B1表示X1的对应系数,X2表示该用户的第二个特征向量,B2表示X2的对应系数,Xn表示该用户的第n个特征向量,Bn表示Xn的对应系数;n为大于等于3的整数;
然后根据各用户的特征值和事先设定的阈值,对老用户和新用户分别进行分类。
例如,将老用户分成五类,具体如下:
TYPE_1:round(COX,1)≤-0.5
TYPE_2:-0.5<round(COX,1)≤-0.2
TYPE_3:-0.2<round(COX,1)≤0.3
TYPE_4:0.3<round(COX,1)≤2.3
TYPE_5:2.3<round(COX,1)
round(COX,1)表示利用式(1)测算出的老用户的特征值,并保留一位小数。-0.5、-0.2、0.3、2.3均为事先设定的阈值。通过这些事先设定的阈值,将老用户分为了五类。对这五类老用户,将分别确定推送时间,以推送信息。对于老用户中每类用户,利用逻辑回归模型测算用户未来W天最有可能回访或者最有可能购买的概率,然后按照事先设定的概率阈值,进行比较后,选择推送时间。
逻辑回归模型如式(2)所示,
P=exp(A0+Y1*A1+Y2*A2+…+Yn*An)/(1+exp(A0+Y1*A1+Y2*A2+…+Yn*An))式(2)
式(2)中,P表示用户最有可能回访或者最有可能购买的概率,A0表示常数项,Y1表示影响用户购买行为的第一因素,A1表示Y1的对应系数,Y2表示影响用户购买行为的第二因素,A2表示Y2的对应系数,Yn表示影响用户购买行为的第n因素,An表示Yn的对应系数;n为大于等于3的整数。影响用户购买行为的因素,例如第一因素、第二因素、第n因素,均由步骤S10采集。例如,这些因素可以为:是否访问加入购物车页面、是否访问咨询服务页、是否访问收藏页、是否访问积分和券页、是否访问退换货页、是否访问搜索页、是否通过PC端访问、是否通过WAP端访问、是否通过APP端访问等。
在式(2)的逻辑回归模型中,可建立如式(3)所示的回归关系:
Log(P/1-P)=A0+Y1*A1+Y2*A2+…+Yn*An 式(3)
通过极大似然法,得到参数A0~An的估计值。再将A0~An的估计值代入式(2)中测算概率。
对上述五类老用户分别计算概率,确定信息推送时间。例如,在上述五类老用户中:
TYPE_1:计算未来D1天的概率。如果未来D2天的概率连续大于S,则仅在第D2天推送一次信息,否则将概率小于S的天数,按照概率从大到小排,选择D3天,分别推送一次信息,如果不够D3天,再按概率从小到大排,选择大于S的天数,凑足D3天。其中,D2<D1,D3<D1,0.5≤S≤1。
对于TYPE_1来说,如果未来D2天的概率连续大于S,则说明该老用户经常购买或访问,所以不需要经常向其推送信息,仅在第D2天推送一次信息。如果未来D2天的概率不是连续大于S,则说明该老用户不是经常购买或访问,则将在未来D1天内,概率小于S的天数,按照概率从大到小排,选择排在前面的D3天,向其推送信息。概率越大,说明购买概率越高,故从大到小进行排序。如果不够D3天,再按概率从小到大排列,选择排在前面的天数,凑足D3天。因为概率越小,购买或访问的可能性越低,所以选择这些小概率的天数推送信息,有利于提醒用户购买商品或访问网站。作为优选,S=0.7,D1=21,D2=3,D3=9。
TYPE_2:计算未来D4天的概率。如果未来D2天的概率连续大于S,则仅在第D2天推送一次;否则把概率小于S的天数,按照概率从大到小排,选择排在前面的D5天,向其推送信息。如果不够D5天,再按概率从小到大排,选择排在前面的天数,凑足D5天。其中,D2<D4,D5<D4,0.5≤S≤1。
对于TYPE_2来说,如果未来D2天的概率连续大于S,则说明该老用户经常购买或访问,所以不需要经常向其推送信息,仅在第D2天推送一次信息。如果未来D2天的概率不是连续大于S,则说明该老用户不是经常购买或访问,则将未来D4天内,概率小于S的天数,按照概率从大到小排,选择排在前面的D5天,向其推送信息。如果不够D5天,再按概率从小到大排列,选择排在前面的天数,这些天数的概率都大于S,凑足D5天。因为概率越小,购买或访问的可能性越低,所以选择这些小概率的天数推送信息,有利于提醒用户购买商品或访问网站。作为优选,S=0.7,D4=14,D2=3,D5=4。
TYPE_3:计算未来D6天的概率。如果未来D2天的概率连续大于S,则仅在第D2天发一次;否则把概率小于S的天数,按照概率从大到小排,选择排在前面的D7天,向其推送信息;如果不够D7天,再按概率从小到大排,选择排在前面的天数,凑足D7天。其中,D2<D6,D7<D6,0.5≤S≤1。
对于TYPE_3来说,如果未来D2天的概率连续大于S,则说明该老用户经常购买或访问,所以不需要经常向其推送信息,仅在第D2天推送一次信息。如果未来D2天的概率不是连续大于S,则说明该老用户不是经常购买或访问,则将未来D6天内,概率小于S的天数,按照概率从大到小排,挑出D7天,向其推送信息。如果不够D7天,再按概率从小到大排列,选择排在前面的天数,这些天数的概率都大于S,凑足D7天。因为概率越小,购买或访问的可能性越低,所以选择这些小 概率的天数推送信息,有利于提醒用户购买商品或访问网站。作为优选,S=0.7,D6=7,D2=3,D7=2。
TYPE_4:计算未来D8天的概率,按,选择排在前面的D9天推送信息。其中,D9<D8。作为优选,D8=14,D9=4。
TYPE_4中,概率从大到小排,可确保计算出来购买概率高的时间,优先推送信息。
TYPE_5:计算未来D10天的概率,按概率从大到小排,选择排在前面的D11天推送信息。其中,D11<D10。作为优选,D10=7,D11=2。
TYPE_5中,概率从大到小排,可确保计算出来购买概率高的时间,优先推送信息。
对新用户而言,则依据事先设定的阈值,进行分类后,直接确定信息推送时间。例如,新用户在未来9天内,信息推送时间如下:
TYPE_11:round(COX,1)≤0.4 第2,3天推送;
TYPE_12:0.4<round(COX,1)≤1.6 第2天推送;
TYPE_13:1.6<round(COX,1) 第3天推送。
对新用户,依据式(1)测算各个新用户的特征值,然后依据事先设定的阈值,对新用户进行分类。上例中,设定的阈值为0.4和1.6,将新用户分成三类。对三类新用户,直接确定信息推送时间。上例中,对于round(COX,1)≤0.4的新用户,则在第2天和第3天均推送信息。对于0.4<round(COX,1)≤1.6的新用户,则在第2天推送信息。对于其他的新用户,则在第3天推送信息。round(COX,1)≤0.4说明这类用户不是活跃用户,则需要推送多次和连续推送;0.4<round(COX,1)≤1.6 说明这类用户是一般活跃用户,所以需要发一天即可。1.6<round(COX,1)说明该类用户是活跃用户,不需要很快给他们推送信息,在第三天推送即可。
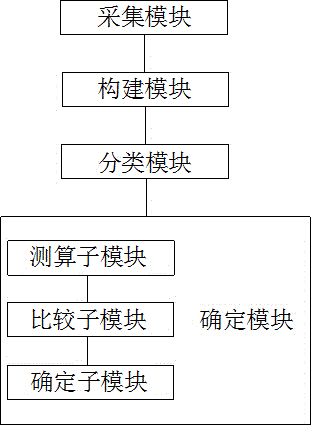
如图2所示,本实施例提供一种个性化信息推送时间的确定系统,该系统包括:
采集模块:用于采集用户在电子商务网站的历史访问记录;
构建模块:用于利用采集模块采集的历史访问记录,构建特征向量;
分类模块:用于根据构建模块构建的特征向量,利用生存分析模型对用户进行分类;
确定模块:用于根据分类模块对用户的分类,确定向每一类用户推送信息的时间。
本确定系统中,利用采集模块采集用户在电子商务网站的历史访问记录,利用构建模块构建特征向量。特征向量源于用户在电子商务网站的历史访问记录。本确定系统中确定模块确定的推送信息时间,正是基于这些特征向量。也就是说,本确定系统中确定的推送信息时间,是基于各用户的历史访问记录。这样确定的推送信息时间就具有个性化,而不是主观统一向各用户设定同一推送信息时间。另外,本确定系统中,分类模块对用户进行分类。对同一分类中的用户确定同一推送时间,有利于提高推送效率。
采集模块采集的用户在电子商务网站的历史访问记录,包括用户在PC端、APP端以及WAP端的历史行为记录。历史访问记录来源于多终 端。多终端的数据来源,确保了构建模块构建的特征向量更加丰富、完整,为后续步骤提供了良好的数据基础。根据用户注册时间和访问的历史记录,可将用户分为老用户和新用户。新用户是指当天注册的用户,包括有历史访问记录或者没有历史访问记录的。老用户是指非当天注册的用户,包括有历史访问记录或者没有历史访问记录。
构建模块的构建特征向量,对于老用户而言可以是:是否电话验证:IS_PHONE_VERIFY、是否访问列表页:在最近2天是否访问列表页、是否访问商品详情页、最近2天是否访问、等等。对于新用户而言可以是:浏览页面数、浏览四级页面、浏览促销页、浏览订单查询页、购买单品数等等。以上仅仅是例举。
分类模型对用户进行分类的方式有很多。本实施例优选运用生存分析模型对老用户和新用户进行分类:首先利用式(1)测算用户的特征值:
COX=X1*B1+X2*B2+…+Xn*Bn 式(1)
式(1)中,COX表示用户的特征值,X1表示该用户的第一个特征向量,B1表示X1的对应系数,X2表示该用户的第二个特征向量,B2表示X2的对应系数,Xn表示该用户的第n个特征向量,Bn表示Xn的对应系数;n为大于等于3的整数;
然后根据各用户的特征值和事先设定的阈值,对老用户和新用户分别进行分类。
将登陆用户的回访并加入购物车行为定义为“死亡”,那么就可以应用生存分析模型来区分用户的“生存”状态(即未加入购物车)。 随着时间延长,“生存”的用户越来越少,即用户的生存曲线是一条单调递减的曲线。用S(x)表示生存曲线的函数,如式(4)所示:
其中,λ(t)表示危险率函数,λ(t)由基准风险率λ0(t)和特征向量Z决定,满足式(5):
λ(t)=λ0(t)*eβZ 式(5)
其中,β表示特征值,用R软件估计出来。R软件是一套完整的数据处理、计算和制图软件系统,R语言是S语言的一种实现。将式(5)代入式(4)可得式(6):
其中,S0(x)表示基准生存函数。对所有用户而言,S0(x)都是相同的。用户之间的差异通过特征向量Z的函数K(Z)=eβZ来决定。通过划分函数K(Z)来实现对用户的分类。
上述确定系统中,确定模块包括:
测算子模块:用于对老用户利用逻辑回归模型测算用户未来最有可能回访或者最有可能购买的概率;
比较子模块:用于将测算子模块测算的概率,与事先设定的概率阈值,进行比较;
确定子模块:用于根据比较子模块的比较结果,确定推送时间。
其中,测算子模块中采用逻辑回归模型如式(2)所示,
P=exp(A0+Y1*A1+Y2*A2+…+Yn*An)/(1+exp(A0+Y1*A1+Y2*A2+…+Yn*An))式(2)
式(2)中,A0表示常数项,Y1表示影响用户购买行为的第一因素,A1表示Y1的对应系数,Y2表示影响用户购买行为的第二因素,A2表示Y2的对应系数,Yn表示影响用户购买行为的第n因素,An表示Yn的对应系数;n为大于等于3的整数。
确定模块中,首先利用测算子模块对老用户利用逻辑回归模型测算用户未来最有可能回访或者最有可能购买的概率;然后利用比较子模块将测算子模块测算的概率,与事先设定的概率阈值,进行比较;最后根据比较子模块的比较结果,利用确定子模块确定推送时间。对不同分类的老用户,确定模块对各类老用户分别确定推送时间。每一类老用户具有相同的推送时间。将所有用户进行分类,依据各分类中的用户的历史访问记录,确定各类老用户的推送时间,使得推送时间更符合各类用户的历史行为。
本确定系统中,基于用户的历史访问记录,运用生存分析模型对用户进行分类,运用逻辑回归模型计算老用户的回访或购买概率,从而计算用户最合适的信息推送时机,提高用户体验。
本领域技术人员应该知晓,实现上述实施例的方法或者系统,可以通过计算机程序指令来实现。该计算机程序指令装载到可编程数据处理设备上,例如计算机,从而在可编程数据处理设备上执行相应的指令,用于实现上述实施例的方法或者系统实现的功能。
本领域技术人员依据上述实施例,可以对本申请进行非创造性的 技术改进,而不脱离本发明的精神实质。这些改进仍应视为在本申请权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!