检索方法和检索系统与流程
本发明涉及检索
技术领域:
,具体而言,涉及一种检索方法和检索系统。
背景技术:
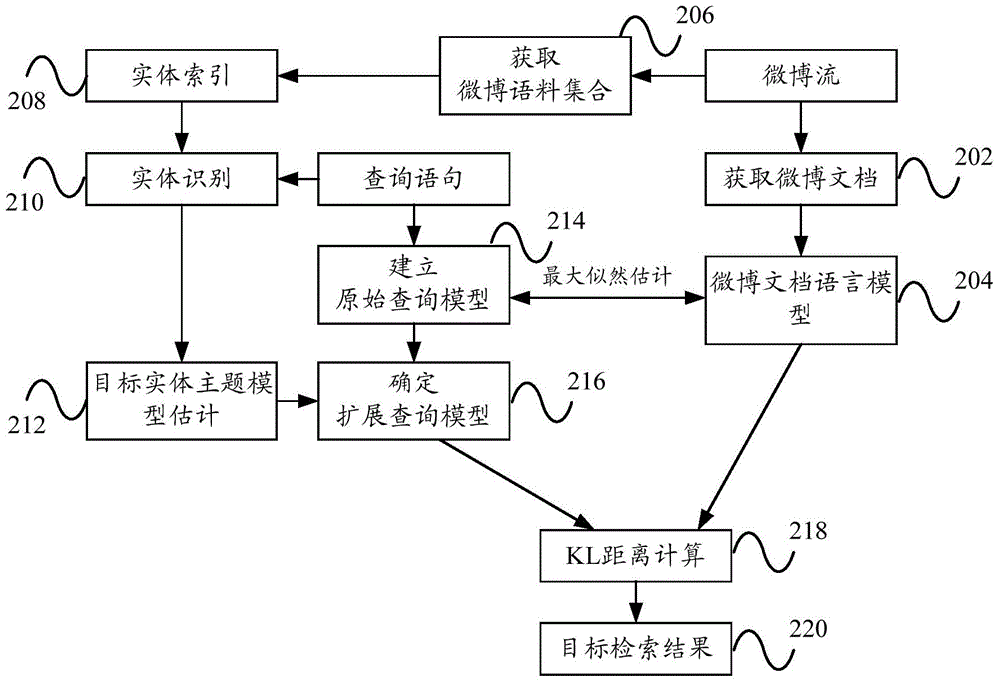
:微博是一个基于用户关系的轻量级信息传播平台,用户可以广播并分享关于他的活动及状态信息。微博的流行带来了对微博文档进行检索的需求,用户也逐渐习惯对微博文档进行各种内容的搜索。与传统的Web检索不同,对微博文档的检索面临很大的挑战,首先,由于微博文档的长度限制,使微博检索面临着严峻的词汇不匹配问题。此外,由于同一个实体具有不同别名,因此,不同用户在对同一个实体进行检索时可能会采用与该实体对应的别名进行检索,例如实体“周杰伦”的别名有“周董、杰伦、伦宝”等,这样通过别名在微博文档中检索得到的目标检索结果也就不准确,而且检索的效率也不高,另一方面,微博文档本身中也包含有很多实体,这样都会使检索得到的目标检索结果不准确。因此,如何使用户可以准确地在微博文档中检索到目标检索结果,成为亟待解决的问题。技术实现要素:本发明正是基于上述问题,提出了一种新的技术方案,可以解决用户在微博文档中不能准确地检索得到目标检索结果的技术问题。有鉴于此,本发明的一方面提出了一种检索方法,包括:在接收到对微博语料集合中的微博文档进行检索的查询语句时,根据所述查询语句创建与所述查询语句相应的原始查询模型;识别所述查询语句中的目标实体;根据与所述目标实体相应的目标实体主题模型、所述原始查询模型和根据所述微博文档集合中的每条微博文档建立的微博文档语言模型,对所述原始查询模型进行扩展,以得到扩展查询模型;统计所述扩展查询模型与所 述微博文档语言模型之间的相似度,以根据所述相似度确定所述查询语句的目标检索结果。在该技术方案中,在使用查询语句对微博语料集合中的微博文档进行检索时,由于查询语句中包含有目标实体的别名,因此,通过识别查询语句中的目标实体可以有效地提高了检索效果,另外,通过对查询语句相应地原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而使对微博文档进行检索地更加全面,而且通过统计扩展查询模型和每条微博文档相应的微博文档语言模型之间的相似度来确定目标检索结果,从而使目标检索结果更加准确,同时还提高了检索的鲁棒性。因此,通过本技术方案,用户可以在微博文档中准确地检索得到目标检索结果,从而提高检索的准确率,其中,目标实体为查询语句中的关键词,例如查询语句为“周杰伦新电影”中的目标实体为“周杰伦”。在上述技术方案中,优选地,通过以下公式统计所述扩展查询模型与所述微博文档语言模型之间的所述相似度,并将相似度大于或等于预设相似度的目标微博文档作为所述目标检索结果:Score(Q,D)=-KL(θ^Q′||θ^D)∝Σw∈Vp(w|θ^Q′)×logp(w|θ^D);]]>其中,Score(Q,D)表示所述相似度,V表示所述微博文档语言模型中的所有实体,表示所述扩展查询模型,表示所述微博文档语言模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述微博文档语言模型中所占有的概率。在该技术方案中,通过扩展后的扩展查询模型可以检索到大量的微博文档,但是在这大量的微博文档中可能包含有很多用户不太关注的信息或这些信息没有按照一定的优先次序进行排列,即用户不太关注的信息可能会排在用户非常关注的信息之前,因此,通过统计扩展查询模型与微博文档语言模型之间的相似度,并根据该相似度的高低确定目标检索结果,可以过滤掉很多不重要、关联性较小或用户不太关注的信息,因此,通过该技术方案,可以提高检索结果的匹配准确率,进一步提高目标检索结果的 准确性,其中,上述公式为KL距离(Kullback-LeiblerDivergence,又称相对熵)的计算,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,根据下列公式计算得到所述扩展查询模型:p(w|θ^Q′)=(1-α)×p(w|θ^Q)+α×p(w|θ^E);]]>其中,表示所述扩展查询模型,表示所述原始查询模型,表示所述目标实体主题模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述原始查询模型中所占有的概率,表示所述目标实体在所述目标实体模型中所占有的概率,所述α表示初始插值参数。在该技术方案中,由于原始查询模型对应的检索结果比较少,甚至还不包含用户需要检索的信息,因此,需要对原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而对微博文档进行检索地更加全面,进一步地提高了检索效果。在上述技术方案中,优选地,根据接收到的更新命令,按照以下公式更新所述α,以得到α′:α′=α×Σw∈EIDF(w)Σw1∈QIDF(w1)]]>其中,w表示所述目标实体,E表示所述目标实体模型中的所有实体,Q表示所述查询语句中的所有实体,w1表示所述查询语句中的任一实体,IDF(w)表示所述目标实体在所述微博语料集合中的逆向文档频率、IDF(w1)表示所述任一实体在所述微博语料集合中的逆向文档频率。在该技术方案中,由于在不同的查询语句中同一个目标实体的重要程度是不一样的,且初始插值参数α会对和与目标实体相应的目标实体模型 有一定的关系,因此,在对不同的查询语句进行检索时需要对初始插值参数α进行更新使其变为自适应的插值参数,并根据更新后的α′来确定扩展查询模型,从而使得扩展查询模型更加准确,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,当所述目标实体为多个时,根据每个所述目标实体在所述微博语料集合中的逆向文档频率和每个所述目标实体的所述目标实体主题模型,确定最终的实体主题模型,以使用所述最终的实体主题模型、所述原始查询模型和与所述微博文档语言模型来创建所述扩展查询模型。在该技术方案中,当查询语句中具有多个目标实体时,根据每个目标实体的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率来确定最终的实体主题模型,以通过最终的实体主题模型得到的扩展查询模型来进行检索,从而得到的目标检索结果更加准确,即目标检索结果具有多个目标实体中的每个目标实体的相关微博文档,进而使目标检索结果是用户想要检索到的微博文档,提升了用户体验。在上述技术方案中,优选地,根据接收到的第一创建命令,通过以下公式确定所述最终的实体主题模型:p(w|θ^E′)=Σi=1nIDF(Ei)×p(w|θ^Ei)Σi=1nIDF(Ei)]]>其中,表示所述最终的实体主题模型,表示每个所述目标实体在所述最终的实体主题模型中所占有的概率,n表示所述目标实体的数目,表示每个所述目标实体的目标实体主题模型,IDF(Ei)表示每个所述目标实体在所述微博语料集合中的逆向文档频率,表示每个所述目标实体在与所述目标实体相应的所述目标实体主题模型中所占有的概率,Ei表示多个所述目标实体中的第i个所述目标实体。在该技术方案中,当查询语句中具有多个目标实体时,从公式中可以看出,根据每个目标实体相应的目标实体主题模型和每个目标实体在所述 微博语料集合中的逆向文档频率计算得到最终的实体主题模型,由于每个目标实体在所述微博语料集合中的逆向文档频率表示每个目标实体在微博语料集合中的重要程度,因此,通过由最终的实体主题模型得到的扩展查询模型来进行检索,使目标检索结果具有与多个目标实体中的每个目标实体均相关的微博文档,且根据每个目标实体在微博语料集合中的重要程度确定目标检索结果,从而使目标检索结果即为用户想要检索到的信息,进而提高了检索效果,其中,逆向文档频率(InverseDocumentFrequency,IDF)是用于衡量目标实体的重要程度,对于目标实体的IDF可以由微博语料集合中微博文档的总数量除以包含该目标实体的微博文档的数量,再将得到的商取对数得到,且目标实体的IDF可以影响更新后的初始差值参数。在上述技术方案中,优选地,根据接收到的第二创建命令,通过以下过程创建与所述目标实体相应的目标实体主题模型:当所述微博语料集合所在的语料集合数据库接收到所述目标实体时,根据所述目标实体从所述微博语料集合中提取与所述目标实体相关的M条微博文档;根据所述目标实体所属的目标领域,在与所述语料集合数据库相连接的目标领域知识库中搜索与所述目标领域相关的多个关键词,其中,多个所述关键词包括所述目标实体;根据多个所述关键词生成与所述目标领域对应的虚拟文档;根据所述虚拟文档建立领域语言模型,并根据所述微博语料集合中的每条微博文档中的所有实体建立背景语言模型;使用所述领域语言模型、所述背景语言模型和与所述目标实体对应的初始实体模型遍历所述M条微博文档,并进行N次迭代运算,以得到所述目标实体主题模型,其中,M≥1,N≥1,且M和N均为正整数。在该技术方案中,通过建立的领域语言模型、背景语言模型和与目标实体对应的初始实体模型可以控制“背景噪音”和“领域相关噪音”,净化微博文档,从而准确确定目标实体的目标实体主题模型,从而通过由目标实体主题模型扩展得到的扩展查询模型进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而提高了检索效果,其中,所有实体指微 博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,还包括:在生成与所述目标领域对应的所述虚拟文档后,统计所述目标实体在与所述目标领域对应的所述虚拟文档中的第一出现次数,以及多个所述关键词中的每个所述关键词在所述目标领域对应的所述虚拟文档中的第二出现次数;根据所述第一出现次数和所述第二出现次数确定所述目标实体的领域先验值;根据所述领域先验值更新所述领域语言模型。在该技术方案中,通过统计目标实体在与目标领域对应的虚拟文档中的第一出现次数和多个关键词中的每个关键词在目标领域对应的虚拟文档中的第二出现次数,确定目标实体的领域先验值,从而根据领域先验值对领域语言模型进行更新,进而得到的领域语言模型更加准确,即领域语言模型中涉及目标实体的每个领域,进而提高了检索效果。本发明的另一方面提出了一种检索系统,包括:第一模型创建单元,在接收到对微博语料集合中的微博文档进行检索的查询语句时,根据所述查询语句创建与所述查询语句相应的原始查询模型;实体识别单元,识别所述查询语句中的目标实体;模型扩展单元,根据与所述目标实体相应的目标实体主题模型、所述原始查询模型和根据所述微博文档集合中的每条微博文档建立的微博文档语言模型,对所述原始查询模型进行扩展,以得到扩展查询模型;检索结果确定单元,统计所述扩展查询模型与所述微博文档语言模型之间的相似度,以根据所述相似度确定所述查询语句的目标检索结果。在该技术方案中,在使用查询语句对微博语料集合中的微博文档进行检索时,由于查询语句中包含有目标实体的别名,因此,通过识别查询语句中的目标实体可以有效地提高了检索效果,另外,通过对查询语句相应地原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微 博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而使对微博文档进行检索地更加全面,而且通过统计扩展查询模型和每条微博文档相应的微博文档语言模型之间的相似度来确定目标检索结果,从而使目标检索结果更加准确,同时还提高了检索的鲁棒性。因此,通过本技术方案,用户可以在微博文档中准确地检索得到目标检索结果,从而提高准确率,其中,目标实体为查询语句中的用户想要查询的目标关键词,例如查询语句为“周杰伦新电影”中的目标实体为“周杰伦”,而“新”和“电影”也即为其他实体或指我们通常意义上的词。在上述技术方案中,优选地,所述检索结果确定单元包括:相似度统计单元,通过以下公式统计所述扩展查询模型与所述微博文档语言模型之间的所述相似度,并将相似度大于或等于预设相似度的目标微博文档作为所述目标检索结果:Score(Q,D)=-KL(θ^Q′||θ^D)∝Σw∈Vp(w|θ^Q′)×logp(w|θ^D);]]>其中,Score(Q,D)表示所述相似度,V表示所述微博文档语言模型中的所有实体,表示所述扩展查询模型,表示所述微博文档语言模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述微博文档语言模型中所占有的概率。在该技术方案中,通过扩展后的扩展查询模型可以检索到大量的微博文档,但是在这大量的微博文档中可能包含有很多用户不太关注的信息或这些信息没有按照一定的优先次序进行排列,即用户不太关注的信息可能会排在用户非常关注的信息之前,因此,通过统计扩展查询模型与微博文档语言模型之间的相似度,并根据该相似度的高低确定目标检索结果,可以过滤掉很多不重要、关联性较小或用户不太关注的信息,因此,通过该技术方案,可以提高检索结果的匹配准确率,进一步提高目标检索结果的准确性,其中,上述公式为KL距离(Kullback-LeiblerDivergence,又称相对熵)的计算,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、 “电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,模型扩展单元具体用于:根据下列公式计算得到所述扩展查询模型:p(w|θ^Q′)=(1-α)×p(w|θ^Q)+α×p(w|θ^E);]]>其中,表示所述扩展查询模型,表示所述原始查询模型,表示所述目标实体主题模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述原始查询模型中所占有的概率,表示所述目标实体在所述目标实体模型中所占有的概率,所述α表示初始插值参数。在该技术方案中,由于原始查询模型对应的检索结果比较少,甚至还不包含用户需要检索的信息,因此,需要对原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而对微博文档进行检索地更加全面,进一步地提高了检索效果。在上述技术方案中,优选地,还包括:参数更新单元,根据接收到的更新命令,按照以下公式更新所述α,以得到α′:α′=α×Σw∈EIDF(w)Σw1∈QIDF(w1)]]>其中,w表示所述目标实体,E表示所述目标实体模型中的所有实体,Q表示所述查询语句中的所有实体,w1表示所述查询语句中的任一实体,IDF(w)表示所述目标实体在所述微博语料集合中的逆向文档频率、IDF(w1)表示所述任一实体在所述微博语料集合中的逆向文档频率。在该技术方案中,由于在不同的查询语句中同一个目标实体的重要程度是不一样的,且初始插值参数α会对和与目标实体相应的目标实体模型有一定的关系,因此,在对不同的查询语句进行检索时需要对初始插值参数α进行更新使其变为自适应的插值参数,并根据更新后的α′来确定扩展查询模型,从而使得扩展查询模型更加准确,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的 某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,还包括:所述模型扩展单元还用于:当所述目标实体为多个时,根据每个所述目标实体在所述微博语料集合中的逆向文档频率和每个所述目标实体的所述目标实体主题模型,确定最终的实体主题模型,以使用所述最终的实体主题模型、所述原始查询模型和与所述微博文档语言模型来创建所述扩展查询模型。在该技术方案中,当查询语句中具有多个目标实体时,根据每个目标实体的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率来确定最终的实体主题模型,以通过最终的实体主题模型得到的扩展查询模型来进行检索,从而得到的目标检索结果更加准确,即目标检索结果具有多个目标实体中的每个目标实体的相关微博文档,进而使目标检索结果是用户想要检索到的微博文档,提升了用户体验。在上述技术方案中,优选地,还包括:所述模型扩展单元具体用于:根据接收到的第一创建命令,通过以下公式确定所述最终的实体主题模型:p(w|θ^E′)=Σi=1nIDF(Ei)×p(w|θ^Ei)Σi=1nIDF(Ei)]]>其中,示所述最终的实体主题模型,表示每个所述目标实体在所述最终的实体主题模型中所占有的概率,n表示所述目标实体的数目,表示每个所述目标实体的目标实体主题模型,IDF(Ei)表示每个所述目标实体在所述微博语料集合中的逆向文档频率,表示每个所述目标实体在与所述目标实体相应的所述目标实体主题模型中所占有的概率,Ei表示多个所述目标实体中的第i个所述目标实体。在该技术方案中,当查询语句中具有多个目标实体时,从公式中可以看出,根据每个目标实体相应的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率计算得到最终的实体主题模型,由于每个目标实体在所述微博语料集合中的逆向文档频率表示每个目标实体在微博语料集合中的重要程度,因此,通过由最终的实体主题模型得到的扩展查询模型来进行检索,使目标检索结果具有与多个目标实体中的每个目标实 体均相关的微博文档,且根据每个目标实体在微博语料集合中的重要程度确定目标检索结果,从而使目标检索结果即为用户想要检索到的信息,进而提高了检索效果,其中,逆向文档频率(InverseDocumentFrequency,IDF)是用于衡量目标实体的重要程度,对于目标实体的IDF可以由微博语料集合中微博文档的总数量除以包含该目标实体的微博文档的数量,再将得到的商取对数得到,且目标实体的IDF可以影响更新后的初始差值参数。在上述技术方案中,优选地,还包括:第二模型创建单元,用于根据接收到的第二创建命令,通过以下过程创建与所述目标实体相应的目标实体主题模型:当所述微博语料集合所在的语料集合数据库接收到所述目标实体时,根据所述目标实体从所述微博语料集合中提取与所述目标实体相关的M条微博文档,根据所述目标实体所属的目标领域,在与所述语料集合数据库相连接的目标领域知识库中搜索与所述目标领域相关的多个关键词,其中,多个所述关键词包括所述目标实体,根据多个所述关键词生成与所述目标领域对应的虚拟文档,根据所述虚拟文档建立领域语言模型,并根据所述微博语料集合中的每条微博文档中的所有实体建立背景语言模型,使用所述领域语言模型、所述背景语言模型和与所述目标实体对应的初始实体模型遍历所述M条微博文档,并进行N次迭代运算,以得到所述目标实体主题模型,其中,M≥1,N≥1,且M和N均为正整数。在该技术方案中,通过建立的领域语言模型、背景语言模型和与目标实体对应的初始实体模型可以控制“背景噪音”和“领域相关噪音”,净化微博文档,从而准确确定目标实体的目标实体主题模型,从而通过由目标实体主题模型扩展得到的扩展查询模型进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而提高了检索效果,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周 杰伦”。在上述技术方案中,优选地,所述第二主题模型创建单元还包括::次数统计单元,在生成与所述目标领域对应的所述虚拟文档后,统计所述目标实体在与所述目标领域对应的所述虚拟文档中的第一出现次数,以及多个所述关键词中的每个所述关键词在所述目标领域对应的所述虚拟文档中的第二出现次数;先验值确定单元,根据所述第一出现次数和所述第二出现次数确定所述目标实体的领域先验值;领域模型更新单元,根据所述领域先验值更新所述领域语言模型。在该技术方案中,通过统计目标实体在与目标领域对应的虚拟文档中的第一出现次数和多个关键词中的每个关键词在目标领域对应的虚拟文档中的第二出现次数,确定目标实体的领域先验值,从而根据领域先验值对领域语言模型进行更新,进而得到的领域语言模型更加准确,即领域语言模型中涉及目标实体的每个领域,进而提高了检索效果。通过本发明的技术方案,使用户可以准确地在微博文档中检索得到目标检索结果,从而提高了检索效率和准确率,同时还可以增强检索的鲁棒性。附图说明图1示出了根据本发明的一个实施例的检索方法的流程示意图;图2示出了根据本发明的另一个实施例的检索方法的流程示意图;图3示出了根据本发明的一个实施例的初步获取微博文档的流程示意图;图4示出了根据本发明的一个实施例的确定目标实体主题模型的流程示意图;图5示出了根据本发明的一个实施例的目标实体主题模型的原理示意图;图6示出了根据本发明的一个实施例的确定扩展查询模型以及目标检索结果的流程示意图;图7示出了根据本发明的一个实施例的检索系统的结构示意图;图8示出了根据本发明的另一个实施例的检索系统的结构示意图。具体实施方式为了可以更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。图1示出了根据本发明的一个实施例的检索方法的流程示意图。如图1所示,根据本发明的一个实施例的检索方法,包括:步骤102,在接收到对微博语料集合中的微博文档进行检索的查询语句时,根据所述查询语句创建与所述查询语句相应的原始查询模型;步骤104,识别所述查询语句中的目标实体;步骤106,根据与所述目标实体相应的目标实体主题模型、所述原始查询模型和根据所述微博文档集合中的每条微博文档建立的微博文档语言模型,对所述原始查询模型进行扩展,以得到扩展查询模型;步骤108,统计所述扩展查询模型与所述微博文档语言模型之间的相似度,以根据所述相似度确定所述查询语句的目标检索结果。在该技术方案中,在使用查询语句对微博语料集合中的微博文档进行检索时,由于查询语句中包含有目标实体的别名,因此,通过识别查询语句中的目标实体可以有效地提高了检索效果,另外,通过对查询语句相应地原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而使对微博文档进行检索地更加全面,而且通过统计扩展查询模型和每条微博文档相应的微博文档语言模型之间的相似度来确定目标检索结果,从而使目标检索结果更加准确,同时还提高了检索的鲁棒性。因此,通过本技术方案,用户可以在微博文档中准确地检索得到目标检索结果,从而提高检索的准确率,其中,目标实体为查询语句中的关键词,例如查询语句为 “周杰伦新电影”中的目标实体为“周杰伦”。在上述技术方案中,优选地,通过以下公式统计所述扩展查询模型与所述微博文档语言模型之间的所述相似度,并将相似度大于或等于预设相似度的目标微博文档作为所述目标检索结果:Score(Q,D)=-KL(θ^Q′||θ^D)∝Σw∈Vp(w|θ^Q′)×logp(w|θ^D);]]>其中,Score(Q,D)表示所述相似度,V表示所述微博文档语言模型中的所有实体,表示所述扩展查询模型,表示所述微博文档语言模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述微博文档语言模型中所占有的概率。在该技术方案中,通过扩展后的扩展查询模型可以检索到大量的微博文档,但是在这大量的微博文档中可能包含有很多用户不太关注的信息或这些信息没有按照一定的优先次序进行排列,即用户不太关注的信息可能会排在用户非常关注的信息之前,因此,通过统计扩展查询模型与微博文档语言模型之间的相似度,并根据该相似度的高低确定目标检索结果,可以过滤掉很多不重要、关联性较小或用户不太关注的信息,因此,通过该技术方案,可以提高检索结果的匹配准确率,进一步提高目标检索结果的准确性,其中,上述公式为KL距离(Kullback-LeiblerDivergence,又称相对熵)的计算,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,根据下列公式计算得到所述扩展查询模型:p(w|θ^Q′)=(1-α)×p(w|θ^Q)+α×p(w|θ^E);]]>其中表示所述扩展查询模型,表示所述原始查询模型,表示所述目标实体主题模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述原始查询模型中所占有的概率,表示所述目标实体在所述目标实体模型中所占有 的概率,所述α表示初始插值参数。在该技术方案中,由于原始查询模型对应的检索结果比较少,甚至还不包含用户需要检索的信息,因此,需要对原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而对微博文档进行检索地更加全面,进一步地提高了检索效果。在上述技术方案中,优选地,根据接收到的更新命令,按照以下公式更新所述α,以得到α′:α′=α×Σw∈EIDF(w)Σw1∈QIDF(w1)]]>其中,w表示所述目标实体,E表示所述目标实体模型中的所有实体,Q表示所述查询语句中的所有实体,w1表示所述查询语句中的任一实体,IDF(w)表示所述目标实体在所述微博语料集合中的逆向文档频率、IDF(w1)表示所述任一实体在所述微博语料集合中的逆向文档频率。在该技术方案中,由于在不同的查询语句中同一个目标实体的重要程度是不一样的,且初始插值参数α会对和与目标实体相应的目标实体模型有一定的关系,因此,在对不同的查询语句进行检索时需要对初始插值参数α进行更新使其变为自适应的插值参数,并根据更新后的α′来确定扩展查询模型,从而使得扩展查询模型更加准确,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,当所述目标实体为多个时,根据每个所述目标实体在所述微博语料集合中的逆向文档频率和每个所述目标实体的所述目标实体主题模型,确定最终的实体主题模型,以使用所述最终的实体主题模型、所述原始查询模型和与所述微博文档语言模型来创建所述扩展查询模型。在该技术方案中,当查询语句中具有多个目标实体时,根据每个目标 实体的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率来确定最终的实体主题模型,以通过最终的实体主题模型得到的扩展查询模型来进行检索,从而得到的目标检索结果更加准确,即目标检索结果具有多个目标实体中的每个目标实体的相关微博文档,进而使目标检索结果是用户想要检索到的微博文档,提升了用户体验。在上述技术方案中,优选地,根据接收到的第一创建命令,通过以下公式确定所述最终的实体主题模型:p(w|θ^E′)=Σi=1nIDF(Ei)×p(w|θ^Ei)Σi=1nIDF(Ei)]]>其中,表示所述最终的实体主题模型,表示每个所述目标实体在所述最终的实体主题模型中所占有的概率,n表示所述目标实体的数目,表示每个所述目标实体的目标实体主题模型,IDF(Ei)表示每个所述目标实体在所述微博语料集合中的逆向文档频率,表示每个所述目标实体在与所述目标实体相应的所述目标实体主题模型中所占有的概率,Ei表示多个所述目标实体中的第i个所述目标实体。在该技术方案中,当查询语句中具有多个目标实体时,从公式中可以看出,根据每个目标实体相应的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率计算得到最终的实体主题模型,由于每个目标实体在所述微博语料集合中的逆向文档频率表示每个目标实体在微博语料集合中的重要程度,因此,通过由最终的实体主题模型得到的扩展查询模型来进行检索,使目标检索结果具有与多个目标实体中的每个目标实体均相关的微博文档,且根据每个目标实体在微博语料集合中的重要程度确定目标检索结果,从而使目标检索结果即为用户想要检索到的信息,进而提高了检索效果,其中,逆向文档频率(InverseDocumentFrequency,IDF)是用于衡量目标实体的重要程度,对于目标实体的IDF可以由微博语料集合中微博文档的总数量除以包含该目标实体的微博文档的数量,再将得到的商取对数得到,且目标实体的IDF可以影响更新后的初始差值参数。在上述技术方案中,优选地,根据接收到的第二创建命令,通过以下过程创建与所述目标实体相应的目标实体主题模型:当所述微博语料集合 所在的语料集合数据库接收到所述目标实体时,根据所述目标实体从所述微博语料集合中提取与所述目标实体相关的M条微博文档;根据所述目标实体所属的目标领域,在与所述语料集合数据库相连接的目标领域知识库中搜索与所述目标领域相关的多个关键词,其中,多个所述关键词包括所述目标实体;根据多个所述关键词生成与所述目标领域对应的虚拟文档;根据所述虚拟文档建立领域语言模型,并根据所述微博语料集合中的每条微博文档中的所有实体建立背景语言模型;使用所述领域语言模型、所述背景语言模型和与所述目标实体对应的初始实体模型遍历所述M条微博文档,并进行N次迭代运算,以得到所述目标实体主题模型,其中,M≥1,N≥1,且M和N均为正整数。在该技术方案中,通过建立的领域语言模型、背景语言模型和与目标实体对应的初始实体模型可以控制“背景噪音”和“领域相关噪音”,净化微博文档,从而准确确定目标实体的目标实体主题模型,从而通过由目标实体主题模型扩展得到的扩展查询模型进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而提高了检索效果,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,还包括:在生成与所述目标领域对应的所述虚拟文档后,统计所述目标实体在与所述目标领域对应的所述虚拟文档中的第一出现次数,以及多个所述关键词中的每个所述关键词在所述目标领域对应的所述虚拟文档中的第二出现次数;根据所述第一出现次数和所述第二出现次数确定所述目标实体的领域先验值;根据所述领域先验值更新所述领域语言模型。在该技术方案中,通过统计目标实体在与目标领域对应的虚拟文档中的第一出现次数和多个关键词中的每个关键词在目标领域对应的虚拟文档 中的第二出现次数,确定目标实体的领域先验值,从而根据领域先验值对领域语言模型进行更新,进而得到的领域语言模型更加准确,即领域语言模型中涉及目标实体的每个领域,进而提高了检索效果。图2示出了根据本发明的另一个实施例的检索方法的流程示意图。如图2所示,根据本发明的另一个实施例的检索方法,包括:步骤202,在微博流中获取所有微博文档。步骤204,根据每条微博文档建立微博文档语言模型,并进入步骤218。步骤206,在微博流中获取微博语料集合,其中,微博语料集合包括微博文档。步骤208,识别出微博文档中的所有实体,例如,利用实体识别工具TwitterNLP识别出所有实体,建立所有实体中的每个实体的实体索引,其中,每个实体对应一个按照时间顺序排序的微博文档的列表。步骤210,识别查询语句中的目标实体。步骤212,对目标实体的目标实体主题模型进行估计,进入步骤216。步骤214,在接收到对微博语料集合中的微博文档进行检索的查询语句时,通过最大似然估计并根据查询语句创建与查询语句相应的原始查询模型。步骤216,根据目标实体主题模型和原始查询模型(根据与目标实体相应的目标实体主题模型、原始查询模型和根据微博文档集合中的每条微博文档建立的微博文档语言模型),对原始查询模型进行扩展,以得到扩展查询模型。步骤218,根据扩展查询模型和微博文档集合中的每条微博文档建立的微博文档语言模型,进行KL距离计算(统计扩展查询模型与微博文档语言模型之间的相似度)。步骤220,根据相似度确定查询语句的目标检索结果。图3示出了根据本发明的一个实施例的初步获取微博文档的流程示意图。如图3所示,根据本发明的一个实施例的初步获取微博文档,包括:步骤302,识别微博语料集合中的所有实体。步骤304,建立所有实体中的每个实体的实体索引,其中,每个实体对应一个按照时间顺序排序的微博文档的列表。步骤306,根据目标实体在实体索引中搜索出与该目标实体相关的M条微博文档,其中该M条微博文档为实体索引中最新发布的微博文档。图4示出了根据本发明的一个实施例的确定目标实体主题模型的流程示意图;图5示出了根据本发明的一个实施例的目标实体主题模型的原理示意图。下面结合图4和图5详细说明本发明的技术方案:如图4所示,根据本发明的一个实施例的确定目标实体主题模型,包括:步骤402,识别查询语句中的目标实体。步骤404,根据目标实体所属的目标领域,在与语料集合数据库相连接的目标领域知识库中搜索与目标领域相关的多个关键词,其中,多个关键词包括目标实体。步骤406,据多个关键词生成与目标领域对应的虚拟文档,并根据虚拟文档建立领域语言模型,以及根据微博语料集合中的每条微博文档中的所有实体建立背景语言模型和建立与目标实体对应的初始实体模型,从而由领域语言模型、背景语言模型和初始实体模型建立混合模型,如图5所示,并由混合模型的建立过程,推导出目标实体的目标实体模型,其中,图5中示出的λC和λE均为预设参数、γ1和γk表示第1个领域语言模型的权重值和第k个领域语言模型的权重值,EF表示图3中的M条微博文档,表示初始实体模型,表示背景语言模型和表示k个领域语言模型。步骤408(等同于步骤306),根据目标实体在实体索引中搜索出与该目标实体相关的M条微博文档(根据目标实体从微博语料集合中提取与目标实体相关的M条微博文档)。步骤410,通过EM算法遍历M条微博文档进行模型参数迭代计算,其中,EM算法表示期望最大化算法(ExpectationMaximizationAlgorithm, 又称最大期望算法)。步骤412,根据迭代计算后的模型参数对混合模型进行迭代计算,以得到目标实体主题模型,其中,迭代次数为预设次数N次,当进行第一次迭代时,与目标实体对应的初始实体模型可以近似等于背景语言模型,M≥1,N≥1,且M和N均为正整数。图6示出了根据本发明的一个实施例的确定扩展查询模型以及目标检索结果的流程示意图。如图6所示,根据本发明的一个实施例的确定扩展查询模型以及目标检索结果,包括:步骤602,识别查询语句中的目标实体。步骤604,建立与目标实体对应的目标实体主题模型,进入步骤610。步骤606,对初始插值参数α进行计算,以得到α′,进入步骤610。步骤608,根据查询语句创建与查询语句相应地原始查询模型,进入步骤610。步骤610,对目标实体主题模型、初始插值参数α′和原始查询模型进行线性叠加,确定扩展查询模型。步骤612,在微博流中获取微博文档。步骤614,根据微博文档集合中的每条微博文档建立微博文档语言模型。步骤616,对扩展查询模型与微博文档语言模型进行KL距离计算(统计扩展查询模型与微博文档语言模型之间的相似度)。步骤618,将相似度大于或等于预设相似度的目标微博文档作为目标检索结果。图7示出了根据本发明的一个实施例的检索系统的结构示意图。如图7所示,根据本发明的一个实施例的检索系统700,包括:第一模型创建单元702、实体识别单元704、模型扩展单元706和检索结果确定单元708,其中,所述第一模型创建单元702用于在接收到对微博语料集合中的微博文档进行检索的查询语句时,根据所述查询语句创建与所述查询语句相应的原始查询模型;实体识别单元704,识别所述查询语句中 的目标实体;模型扩展单元706,根据与所述目标实体相应的目标实体主题模型、所述原始查询模型和根据所述微博文档集合中的每条微博文档建立的微博文档语言模型,对所述原始查询模型进行扩展,以得到扩展查询模型;检索结果确定单元708,统计所述扩展查询模型与所述微博文档语言模型之间的相似度,以根据所述相似度确定所述查询语句的目标检索结果。在该技术方案中,在使用查询语句对微博语料集合中的微博文档进行检索时,由于查询语句中包含有目标实体的别名,因此,通过识别查询语句中的目标实体可以有效地提高了检索效果,另外,通过对查询语句相应地原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而使对微博文档进行检索地更加全面,而且通过统计扩展查询模型和每条微博文档相应的微博文档语言模型之间的相似度来确定目标检索结果,从而使目标检索结果更加准确,同时还提高了检索的鲁棒性。因此,通过本技术方案,用户可以在微博文档中准确地检索得到目标检索结果,从而提高准确率,其中,目标实体为查询语句中的用户想要查询的目标关键词,例如查询语句为“周杰伦新电影”中的目标实体为“周杰伦”,而“新”和“电影”也即为其他实体或指我们通常意义上的词。在上述技术方案中,优选地,所述检索结果确定单元708包括:相似度统计单元7082,通过以下公式统计所述扩展查询模型与所述微博文档语言模型之间的所述相似度,并将相似度大于或等于预设相似度的目标微博文档作为所述目标检索结果:Score(Q,D)=-KL(θ^Q′||θ^D)∝Σw∈Vp(w|θ^Q′)×logp(w|θ^D);]]>其中,Score(Q,D)表示所述相似度,V表示所述微博文档语言模型中的所有实体,表示所述扩展查询模型,表示所述微博文档语言模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述微博文档语言模型中所占有的概率。在该技术方案中,通过扩展后的扩展查询模型可以检索到大量的微博 文档,但是在这大量的微博文档中可能包含有很多用户不太关注的信息或这些信息没有按照一定的优先次序进行排列,即用户不太关注的信息可能会排在用户非常关注的信息之前,因此,通过统计扩展查询模型与微博文档语言模型之间的相似度,并根据该相似度的高低确定目标检索结果,可以过滤掉很多不重要、关联性较小或用户不太关注的信息,因此,通过该技术方案,可以提高检索结果的匹配准确率,进一步提高目标检索结果的准确性,其中,上述公式为KL距离(Kullback-LeiblerDivergence,又称相对熵)的计算,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,模型扩展单元706具体用于:根据下列公式计算得到所述扩展查询模型:p(w|θ^Q′)=(1-α)×p(w|θ^Q)+α×p(w|θ^E);]]>其中,表示所述扩展查询模型,表示所述原始查询模型,表示所述目标实体主题模型,表示所述目标实体在所述扩展查询模型中所占有的概率,表示所述目标实体在所述原始查询模型中所占有的概率,表示所述目标实体在所述目标实体模型中所占有的概率,所述α表示初始插值参数。在该技术方案中,由于原始查询模型对应的检索结果比较少,甚至还不包含用户需要检索的信息,因此,需要对原始查询模型进行扩展得到扩展查询模型,这样根据扩展查询模型对微博文档进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而对微博文档进行检索地更加全面,进一步地提高了检索效果。在上述技术方案中,优选地,还包括:参数更新单元710,根据接收到的更新命令,按照以下公式更新所述α,以得到α′:α′=α×Σw∈EIDF(w)Σw1∈QIDF(w1)]]>其中,w表示所述目标实体,E表示所述目标实体模型中的所有实体,Q表示所述查询语句中的所有实体,w1表示所述查询语句中的任一实体,IDF(w)表示所述目标实体在所述微博语料集合中的逆向文档频率、IDF(w1)表示所述任一实体在所述微博语料集合中的逆向文档频率。在该技术方案中,由于在不同的查询语句中同一个目标实体的重要程度是不一样的,且初始插值参数α会对和与目标实体相应的目标实体模型有一定的关系,因此,在对不同的查询语句进行检索时需要对初始插值参数α进行更新使其变为自适应的插值参数,并根据更新后的α′来确定扩展查询模型,从而使得扩展查询模型更加准确,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,还包括:所述模型扩展单元706还用于:当所述目标实体为多个时,根据每个所述目标实体在所述微博语料集合中的逆向文档频率和每个所述目标实体的所述目标实体主题模型,确定最终的实体主题模型,以使用所述最终的实体主题模型、所述原始查询模型和与所述微博文档语言模型来创建所述扩展查询模型。在该技术方案中,当查询语句中具有多个目标实体时,根据每个目标实体的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率来确定最终的实体主题模型,以通过最终的实体主题模型得到的扩展查询模型来进行检索,从而得到的目标检索结果更加准确,即目标检索结果具有多个目标实体中的每个目标实体的相关微博文档,进而使目标检索结果是用户想要检索到的微博文档,提升了用户体验。在上述技术方案中,优选地,还包括:所述模型扩展单元706具体用于:根据接收到的第一创建命令,通过以下公式确定所述最终的实体主题模型:p(w|θ^E′)=Σi=1nIDF(Ei)×p(w|θ^Ei)Σi=1nIDF(Ei)]]>其中,表示所述最终的实体主题模型,表示每个所述目 标实体在所述最终的实体主题模型中所占有的概率,n表示所述目标实体的数目,表示每个所述目标实体的目标实体主题模型,IDF(Ei)表示每个所述目标实体在所述微博语料集合中的逆向文档频率,表示每个所述目标实体在与所述目标实体相应的所述目标实体主题模型中所占有的概率,Ei表示多个所述目标实体中的第i个所述目标实体。在该技术方案中,当查询语句中具有多个目标实体时,从公式中可以看出,根据每个目标实体相应的目标实体主题模型和每个目标实体在所述微博语料集合中的逆向文档频率计算得到最终的实体主题模型,由于每个目标实体在所述微博语料集合中的逆向文档频率表示每个目标实体在微博语料集合中的重要程度,因此,通过由最终的实体主题模型得到的扩展查询模型来进行检索,使目标检索结果具有与多个目标实体中的每个目标实体均相关的微博文档,且根据每个目标实体在微博语料集合中的重要程度确定目标检索结果,从而使目标检索结果即为用户想要检索到的信息,进而提高了检索效果,其中,逆向文档频率(InverseDocumentFrequency,IDF)是用于衡量目标实体的重要程度,对于目标实体的IDF可以由微博语料集合中微博文档的总数量除以包含该目标实体的微博文档的数量,再将得到的商取对数得到,且目标实体的IDF可以影响更新后的初始差值参数。在上述技术方案中,优选地,还包括:第二模型创建单元712,用于根据接收到的第二创建命令,通过以下过程创建与所述目标实体相应的目标实体主题模型:当所述微博语料集合所在的语料集合数据库接收到所述目标实体时,根据所述目标实体从所述微博语料集合中提取与所述目标实体相关的M条微博文档,根据所述目标实体所属的目标领域,在与所述语料集合数据库相连接的目标领域知识库中搜索与所述目标领域相关的多个关键词,其中,多个所述关键词包括所述目标实体,根据多个所述关键词生成与所述目标领域对应的虚拟文档,根据所述虚拟文档建立领域语言模型,并根据所述微博语料集合中的每条微博文档中的所有实体建立背景语言模型,使用所述领域语言模型、所述背景语言模型和与所述目标实体对应的初始实体模型遍历所述M条微博文档,并进行N次迭代运算,以 得到所述目标实体主题模型,其中,M≥1,N≥1,且M和N均为正整数。在该技术方案中,通过建立的领域语言模型、背景语言模型和与目标实体对应的初始实体模型可以控制“背景噪音”和“领域相关噪音”,净化微博文档,从而准确确定目标实体的目标实体主题模型,从而通过由目标实体主题模型扩展得到的扩展查询模型进行检索时,可以检索到大量的与查询语句相关的微博文档,即包括有用户感兴趣的信息,从而可以有效地避免了对微博文档的漏检,进而提高了检索效果,其中,所有实体指微博文档语言模型中的每条微博文档中的所有的词,例如,微博文档语言模型中的某条微博文档为“周杰伦新电影太棒了”,则该条微博文档中的所有实体即为“周杰伦”,“新”、“电影”和“太棒了”,总之,实体就是代表我们通常意义上的词,目标实体就是用户想要查询的关键词如“周杰伦”。在上述技术方案中,优选地,所述第二主题模型创建单元还包括::次数统计单元7122,在生成与所述目标领域对应的所述虚拟文档后,统计所述目标实体在与所述目标领域对应的所述虚拟文档中的第一出现次数,以及多个所述关键词中的每个所述关键词在所述目标领域对应的所述虚拟文档中的第二出现次数;先验值确定单元7124,根据所述第一出现次数和所述第二出现次数确定所述目标实体的领域先验值;领域模型更新单元7126,根据所述领域先验值更新所述领域语言模型。在该技术方案中,通过统计目标实体在与目标领域对应的虚拟文档中的第一出现次数和多个关键词中的每个关键词在目标领域对应的虚拟文档中的第二出现次数,确定目标实体的领域先验值,从而根据领域先验值对领域语言模型进行更新,进而得到的领域语言模型更加准确,即领域语言模型中涉及目标实体的每个领域,进而提高了检索效果。图8示出了根据本发明的另一个实施例的检索系统的结构示意图。如图8所示,根据本发明的另一个实施例的检索系统800(相当于图7示出的实施例的检索系统700),包括:实体微博集合获取模块802,用于收集与目标实体相关的微博文档;实体主题模型估计模块804(相当于图7示出的实施例的第二模型创建单元712),用于进行目标实体主题 模型的估计;适应性查询扩展模块806(相当于图7示出的实施例的模型扩展单元706),用于将目标实体主题模型融入微博文档语言模型中。下面详细说明检索系统800的这几个模块:1.实体微博集合获取模块802具体用于:对查询语句中的目标实体进行识别,实体索引的建立,以及对与目标实体相关的微博文档进行选取。2.实体主题模型估计模块804包括:知识库链接模块8042、先验值计算模块8044(相当于图7示出的实施例的先验值计算单元7124)和生成式模型构建模块8046,知识库链接模块8042用于把目标实体链接到Freebase知识库,并获取该目标实体在Freebase知识库中所属的目标领域(Freebase中的领域可以看成是流行报纸的不同版面:如商业,生活方式,艺术,娱乐,政治,经济等);先验值计算模块8044用于获取与目标领域相关的多个关键词,其中,多个所述关键词包括所述目标实体,根据多个关键词生成与目标领域对应的虚拟文档,在此虚拟文档上进行极大似然估计来生成领域先验值;生成式模型构建模块8046用于搭建与目标实体对应的初始实体模型、背景语言模型和领域语言模型,并利用EM算法在微博文档中进行迭代计算,以得到目标实体主题模型。3.适应性查询扩展模块806,用于对查询语句进行建模得到原始查询模型,以及对微博文档集合中的每条微博文档进行建模得到微博文档语言模型,通过目标实体主题模型对原始查询模型进行扩展,以得到扩展查询模型,对扩展查询模型和微博文档语言模型进行KL距离计算,以根据计算结果得到目标检索结果。下面将进一步详细说明本发明的技术方案:一、识别实体。1.利用实体识别工具TwitterNLP识别出微博文档中的所有实体。2.建立实体索引,对于所有实体中的每个实体对应一个按时间排序的微博文档的列表。3.识别查询语句中的目标实体,并在实体索引中获取最新发布的M条包含该目标实体的微博文档。二、建立目标实体主题模型。1.将目标实体链接到Freebase知识库(目标领域知识库),读取目标 实体在Freebase知识库中的实体信息,以获取目标实体所属的目标领域(例如音乐领域、艺术领域、图书领域)。特别的,如果目标实体未链接到实体信息,则认为该目标实体属于任何一个领域。2.计算领域先验值,根据实体索引中所有实体尝试用Freebase搜索接口链接到Freebase知识库,将不同领域下的属性和类型词构成一个虚拟文档(在与语料集合数据库相连接的目标领域知识库中搜索与目标领域相关的多个关键词,其中,多个关键词包括目标实体,并根据多个关键词生成与目标领域对应的虚拟文档),在此虚拟文档上使用下列公式进行极大似然估计来生成领域先验值:p(w|d)=c(w,d)Σnc(w2,d)]]>其中,w表示目标实体,d表示目标实体所属的目标领域,w2表示多个关键词中的每个关键词,c(w,d)表示w在目标领域d对应的虚拟文档中的第一出现次数,c(w2,d)表示多个关键词中的每个关键词在目标领域对应的虚拟文档中的第二出现次数,n表示关键词的总数量。3.建立目标实体主题模型,根据虚拟文档建立领域语言模型,并根据微博语料集合中的每条微博文档中的所有实体建立背景语言模型,以及建立与目标实体对应的初始实体模型,其中,初始实体模型可以近似于背景语言模型,由领域语言模型、背景语言模型和初始实体模型形成混合模型。4.利用EM算法进行模型估计。根据如图5所示的混合模型,我们可以将返回的M条微博集合EF的对数似然函数表示为:logp(EF|θ^)=ΣiΣwc(w,Di)×log{λE[(1-λC)×p(w,θ^E)+λC×p(w|θ^C)]+(1-λE)×Σd=1kγdp(w,θ^d)}]]>其中,EF表示上文搜索出的M条微博文档,i用于遍历微博语料集合中的所有微博文档,w表示微博语料集合中的每条微博文档中的所有实体中的每个实体,Di表示微博语料集合中的第i条微博文档,k表示目标 实体所属的目标领域的数量,表示w在目标实体模型中所占有的概率,表示词w在背景语言模型中所占有的频率,表示词w在领域语言模型中所占有的频率,c(w,Di)是词w在Di中出现的次数,λC表示第一预设参数,λE表示第二预设参数,λC和λE分别用于控制背景噪音和领域相关噪音,γd表示目标领域语言模型的权重值。使用EM算法即来对混合模型进行最大似然估计,在微博语料集合EF上迭代更新参数,从而得到以下公式:td(n)(w)=(1-λE)×γd(n)×p(n)(w|θ^d)λE×[(1-λc)×p(n)(w|θ^E)+λ×p(w|θ^C)]+(1-λE)×Σd′=1kγd′(n)×p(n)(w|θ^d′)]]>s(n)(w)=λE×[(1-λc)×p(n)(w|θ^E)+λ×p(w|θ^C)]λE×[(1-λc)×p(n)(w|θ^E)+λ×p(w|θ^C)]+(1-λE)×Σd′=1kγd′(n)×p(n)(w|θ^d′)]]>r(n)(w)=(1-λc)×p(n)(w|θ^E)(1-λc)×p(n)(w|θ^E)+λ×p(w|θ^C)]]>p(n+1)(w|θ^d)=Σic(w,Di)×td(n)(w)Σw′ΣiΣd′=1kc(w′,Di)×td′(n)(w′)]]>p(n+1)(w|θ^E)=Σic(w,Di)×r(n)(w)×s(n)(w)Σw′Σic(w′,Di)×r(n)(w′)×s(n)(w′)]]>γd(n+1)=ΣwΣic(w,Di)×td(n)(w)ΣwΣiΣd′=1kc(w,Di)×td′(n)(w)]]>其中,n表示当前迭代的次数,w表示目标实体,w′表示微博语料集合的所有实体中的每个实体,d′表示所有领域中的每个领域,s(n)(w),r(n)(w)是为了表示计算方便的中间变量,表示w在第(n+1)轮迭代时的领域语言模型中的概率,表示w在第(n+1)轮迭代时的实体主题模型中的概率,表示第(n+1)轮迭代时的领域语言模型的权重值,在求和下标中,w/w′用于遍历微博语料集合中的所有实体,i用于遍历反馈微博集合中的所有微博文档,d/d′用于遍历所有领域,k表示目标实体E所属的目标领域的数量,λ表示预设迭代参数。另外,更新的过程中可以使用目标实体的领域先验值p(w|d)。在每个一元语言模型p(w|d)上定义一个共轭先验(即狄利克雷先 验),接着,采用最大后验概率(MaximumAPosteriori,MAP)来估计所有的参数,只需要在领域语言模型的更新公式上做很小的更改,通过下列公式进行MAP估计:p(n+1)(w|θ^d)=σd·p(w|d)+Σic(w,Di)·td(n)(w)σd+Σw′ΣiΣd′=1kc(w′,Di)·td′(n)(w′)]]>至此,使用以上公式迭代数轮后(比如100轮),可以得到目标实体主题模型三、适应性查询扩展。1.在接收到对微博语料集合中的微博文档进行检索的查询语句时,根据查询语句创建与查询语句相应的原始查询模型,以及根据微博文档集合中的每条微博文档建立微博文档语言模型。2.通过目标实体主题模型对原始查询模型进行扩展得到扩展查询模型。根据下列公式计算得到扩展查询模型:p(w|θ^Q′)=(1-α)×p(w|θ^Q)+α×p(w|θ^E);]]>其中,表示扩展查询模型,表示原始查询模型,表示目标实体主题模型,表示目标实体在扩展查询模型中所占有的概率,表示目标实体在原始查询模型中所占有的概率,表示目标实体在目标实体模型中所占有的概率,α表示初始插值参数,α控制目标实体主题模型的重要程度。在相关技术中,初始插值参数α对于所有的查询语句均设置为一个固定的值,然而,考虑到不同查询语句中同一个目标实体的重要性程度是不相同的,所以可以对初始插值参数进行更新,按照以下公式更新α,以得到α′:α′=α×Σw∈EIDF(w)Σw1∈QIDF(w1)]]>其中,w表示目标实体,E表示目标实体模型中的所有实体,Q表示查询语句中的所有实体,w1表示查询语句中的任一实体,IDF(w)表示目标实体在微博语料集合中的逆向文档频率、IDF(w1)表示任一实体在微博语料集合中的逆向文档频率。特别的,当查询语句中有多个目标实体被识别出时,根据每个目标实 体的目标实体主题模型的带权平均值确定最终的实体主题模型,具体地,通过以下公式确定最终的实体主题模型:p(w|θ^E′)=Σi=1nIDF(Ei)×p(w|θ^Ei)Σi=1nIDF(Ei)]]>其中,表示最终的实体主题模型,表示每个目标实体在最终的实体主题模型中所占有的概率,n表示目标实体的数目,表示每个目标实体的目标实体主题模型,IDF(Ei)表示每个目标实体在微博语料集合中的逆向文档频率,表示每个目标实体在与目标实体相应的目标实体主题模型中所占有的概率,Ei表示多个目标实体中的第i个目标实体。3.KL距离计算(统计扩展查询模型与微博文档语言模型之间的相似度),通过以下公式统计扩展查询模型与微博文档语言模型之间的相似度,并将相似度大于或等于预设相似度的目标微博文档作为目标检索结果:Score(Q,D)=-KL(θ^Q′||θ^D)∝Σw∈Vp(w|θ^Q′)×logp(w|θ^D);]]>其中,Score(Q,D)表示相似度,V表示微博文档语言模型中的所有实体,表示扩展查询模型,表示微博文档语言模型,表示目标实体在扩展查询模型中所占有的概率,表示目标实体在微博文档语言模型中所占有的概率。下面结合一个实施例对本发明进行进一步地描述:1)进行预处理阶段,对微博流中的每条微博文档均用实体识别工具识别出包含的所有实体。例如微博文档为“周杰伦的新电影真是拍得太棒了”,我们识别出了实体“周杰伦”,则我们将该微博编号(id)存入实体索引中对应的实体项;对于目标实体,我们从实体索引中获得最新加入的M条微博文档作为微博语料集合。2)首先对于目标实体“周杰伦”,使用Freebase搜索接口尝试链接到Freebase知识库中的对象,并获得其所属的目标领域,即电影、音乐、电视、人物、媒体、奖项。构建混合模型,该混合模型包括“周杰伦”对应的初始实体主题模型、背景语言模型和六个领域语言模型。使用领域语言模型、背景语言模型和与目标实体对应的初始实体模型 遍历M条微博文档,并进行N次迭代运算,以得到目标实体主题模型,其中,M≥1,N≥1,且M和N均为正整数。3)对查询语句和每条微博文档进行极大似然建模,例如查询语句为“周杰伦新电影”,分词后得到[“周杰伦”,“新”,“电影”],经过最大似然估计创建原始查询模型,p(周杰伦)=0.33,p(新)=0.33,p(电影)=0.33,以及根据每条微博文档建立微博文档语言模型,其中,对于每条微博文档的极大似然估计建模与原始查询模型的估计建模类似。识别查询语句中的目标实体,例如查询语句为“周杰伦新电影”,识别出目标实体为“周杰伦”。利用“周杰伦”目标实体主题模型来扩展原始查询模型,得到扩展查询模型,计算初始插值参数:根据前面的线性插值公式来来扩展原始查询模型,由于查询语句“周杰伦新电影”中仅有一个目标实体“周杰伦”,因此,可以直接利用该目标实体的目标实体主题模型来进行扩展。利用KL距离计算公式计算出扩展后的扩展查询模型和微博文档语言模型的相似度,微博文档语言模型利用微博文档的极大似然估计,并进行狄利克雷平滑处理。根据相似度确定查询语句的目标检索结果。以上结合附图详细说明了本发明的技术方案,可以使用户准确地在微博文档中检索得到目标检索结果,从而提高了检索准确率,同时还可以有效地增强检索的鲁棒性。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1