一种基于随机算法的分布式实体匹配方法与流程
本发明属于数据集成与管理
技术领域:
,尤其涉及一种基于随机算法的分布式实体匹配方法。
背景技术:
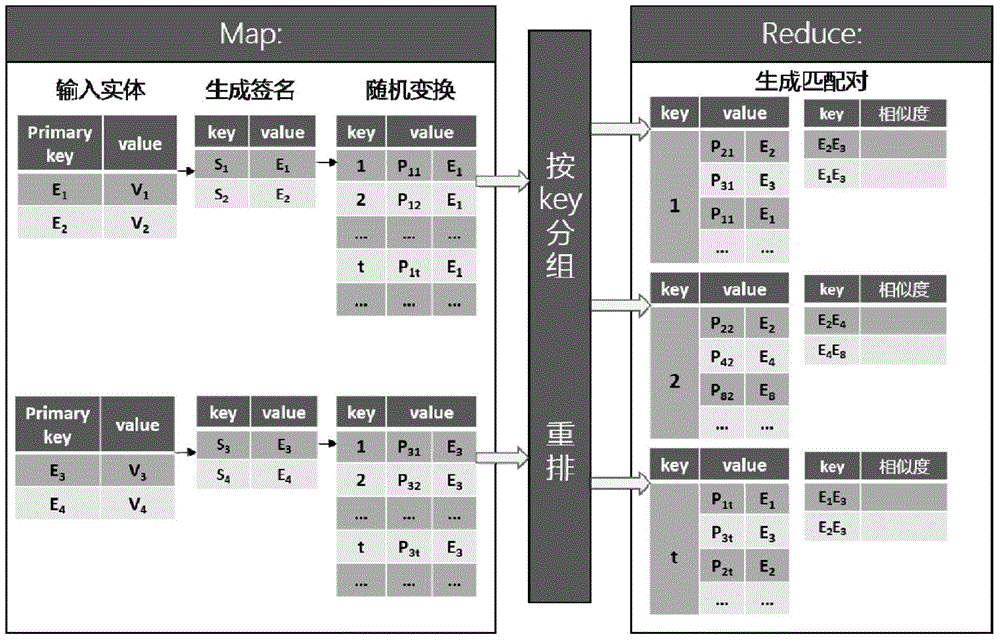
:实体匹配技术(也称实体解析、数据关联与重复检测等)旨在从目标数据集中识别出描述相同实体或对象的记录,并通过对描述相同实体的多条记录进行筛选融合,实现对数据的集成与清洗。例如,在一个顾客对顾客(C2C)的在线市场中,人们可以轻松地开办在线商店并且列出任何他们想卖的东西,所以同一件商品很可能被多个卖家以不同价格、品质以及不同的商品描述来进行贩卖,这导致买家在选择时感到困惑。实体匹配的目的是通过评估各个商品记录的相似度,找出哪些实体信息对应同种商品。经过对这些实体信息中的脏数据进行清洗,构成一个相似商品信息的集合,供顾客挑选。在当前的互联网环境中,网络数据和用户生成内容(UserGeneratedContent)的飞速增长改变了我们过去收集和管理信息的方式。数量庞大的网络用户群体作为数据的主要生产者,其极高的参与度使得数据生成过程变得更为简单,但松散的管理模式却导致数据变得更难管理。网络数据与用户生成内容(UGC)具有数据总量大、数据结构复杂、数据质量差等多个特点。很多研究工作尝试过分别解决上述的问题:1)采用文本相似度来衡量非结构化数据(如在线文档)的相似性。它为半结构化和非结构化数据提供了一种标准的度量方法;2)分词技术被用来减少拼写错误和人为错误对于数据质量的负面影响。这已经成为数据清理中一项重要的步骤,而且提高了实体匹配的精确度;3)数据分块策略根据相似度将数据划分成多个部分。因为只需要比较相同分块中的数据,所以这些分块策略能有效地减少比较代价。分布式环境相比于集中式环境,大幅度增加了运算的并行度与系统的可拓展性,为大数据量的实体匹配提供了可能。借助如MapReduce的分布式运算模型,可以将传统方法运用到分布式环境下,因此那些集中环境下的研究成果可以为分布式环境下的实体匹配提供解决思路。另一方面,一些传统实体匹配方法移植到分布式环境时,通常无法充分利用分布式的并发优势,出现了负载均衡和网络传输开销等问题,性能较差。为了克服上述现有技术的缺陷,本发明在分布式系统环境下,为半结构化和非结构化数 据提出一种随机匹配方法,并希望继承一些先前的研究成果,减少计算开销和网络传输开销。技术实现要素:本发明提出了一种基于随机算法的分布式实体匹配方法,包括如下步骤:数据预处理步骤:对原始数据进行特征抽取,生成实体及其向量;签名生成步骤:根据所述实体及其向量生成多个随机向量,生成每一个随机向量相应的签名,对所述签名进行多次随机变换,再将实体编号、变换后签名和变换序号传输到分布式节点内;匹配对生成步骤:在分布式节点内对所述签名重排并分组,从组中提取匹配对;相似度计算步骤:通过计算海明距离得到所述匹配对的相似度。本发明的基于随机算法的分布式实体匹配方法中,在所述数据预处理步骤包括:对于所述原始数据中进行实体分词,构造出包含所有记录中所出现的词的词典,最后根据每条所述记录中各个词的出现频率将所述记录转化为统一的向量。本发明的基于随机算法的分布式实体匹配方法中,使用Part-Of-SpeechTagger对所述原始数据进行实体分词。本发明的基于随机算法的分布式实体匹配方法中,在所述生成签名步骤中,使用位置敏感哈希函数生成数量小于所述向量维度的随机向量。本发明的基于随机算法的分布式实体匹配方法中,在所述生成签名步骤中,利用可保留向量特征的位置敏感哈希函数计算所述随机向量的签名,在保留空间向量特征的同时减少网络传输开销;所述位置敏感哈希函数以如下公式表示:hr(u)=1r.u≥00r.u<0hr(u)=1r.u≥00r.u<0.]]>本发明的基于随机算法的分布式实体匹配方法中,在所述匹配对生成步骤中,在所述分布式节点内按随机变换序号对所述签名分组,并在组内进行排序,选择每个签名和同组中与其相邻的多个签名生成匹配对。本发明的基于随机算法的分布式实体匹配方法中,在所述相似度计算步骤中,设定阈值并计算海明距离衡量匹配对的相似度,若相似度低于阈值,则认定所述匹配对相似并输出对应的实体编号及相似度。本发明的基于随机算法的分布式实体匹配方法中,在所述相似度计算步骤之后进一步包括所述近实时查询步骤:以用户为单位,对文件路径列表进行分组与去重处理,得到关于源数据的文件路径集合,根据所述集合中的文件路径得到所述外存空间中的源数据文件。本发明的基于随机算法的分布式实体匹配方法中,所述分布式实体匹配方法是基于分布式环境,所述分布式环境包括MapReduce计算框架、Hadoop分布式系统以及Hadoop分布式文件系统。本发明基于MapReduce框架在Hadoop上完成了算法实现,使用Hadoop的分布式文件系统(HDFS)实现数据的存储和读写。Hadoop具有良好的横向扩展能力,通过并行调度实现任务对大数据的高效处理能力。本发明的有益效果在于:本发明在所述生成签名步骤中将高维向量转换成了多个低维签名,有效地减少了网络传输开销。本发明在所述匹配对生成步骤中,在shuffle阶段对所有签名进行分组重排,各组包含所有实体同一次变换后的签名,再将所有组均匀传输给各reduce节点进行相似度计算,各节点接收到的签名数量相近,解决了分布式系统中的负载均衡问题。本发明中只需要执行一个MapReduce任务,相比其他采用多MapReduce任务的实体匹配方法,减轻了因额外任务调度产生的计算代价,带来性能提升。通过实验,本发明与其他分布式实体匹配方法相比,在保证了匹配准确率的同时,性能上有很大的优势,在不同大小的数据集上都展现出了较好的兼容性。附图说明图1是本发明基于随机算法的分布式实体匹配方法的流程图。图2是具体实施中的MapReduce示例图。具体实施方式结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。本发明基于随机算法的分布式实体匹配方法支持对对海量实体的匹配处理。本发明在开源分布式平台上制定有效的数据存储策略、利用高效的数据索引技术支持时间敏感的查询处理,并设计了基于时间敏感的数据存储策略,为查询的快速文件定位提供保障,实现了基于倒排技术的索引,为查询提供高效的文件过滤。如图1所示,本发明基于随机算法的分布式实体匹配方法,其特征在于,包括如下步骤:S1数据预处理步骤:对原始数据进行特征抽取,生成实体及其向量;S2签名生成步骤:根据实体及其向量生成多个随机向量,生成每一个随机向量相应的签名,对签名进行多次随机变换,再将实体编号、变换后签名和变换序号传输到分布式节点内;S3匹配对生成步骤:在分布式节点内对签名重排并分组,从组中提取匹配对;S4相似度计算步骤:通过计算海明距离得到匹配对的相似度。之后进一步包括近实时查询步骤:以用户为单位,对文件路径列表进行分组与去重处理,得到关于源数据的文件路径集合,根据集合中的文件路径得到外存空间中的源数据文件。本发明的基于随机算法的分布式实体匹配方法中,实体表示数据集中描述客观物体的记录,实体对表示一对物体记录;键值对为MapReduce计算框架中Map和Reduce作业的输入输出结构,形如(key,value),其中键(key)可作为区分记录的标识,也可作为记录分组的主键,值(value)为记录所包含的具体信息;匹配对表示通过计算相似度得到的相似实体记录对。本发明较小牺牲匹配准确率而显著提升了匹配速度,相较于其他分布式匹配方法,负载均衡、网络传输花销问题都得到了解决,性能上有很大的优势,能够快速匹配处理不同大小的数据集。以下对本发明技术内容做进一步阐述:对于处理半结构化和非结构化的数据,余弦相似度是一个合适的方法。但是高维度的实体特征会使其降低匹配正确率。Charikar提出了用于余弦相似度的位置敏感哈希(LSH)函数,为本发明提供了一个选择。定理:假设有一个在k维向量空间中的向量集(记作Nk),然后从这个k维空间中生成一个随机单位向量r,以如下式(1)定义一个哈希函数hr:hr(u)=1r.u≥00r.u<0(1)hr(u)=1r.u≥00r.u<0(1)hr(u)=1r.u≥00r.u<0---(1);]]>Geomans和Williams证明,对于向量u和v利用式(2)计算出对应的关系。从式(2)中得到了式(3)中表述的余弦关系:Pr[hr(u)=hr(v)]=1-θ(u,v)π---(2)]]>cos(θ(u,v))=cos(1-Pr[hr(u)=hr(v)])π(3)另一种计算余弦相似度的方法是基于前面的定理发现的,能够避免高维度问题。生成大量(d个)随机向量,计算出每个向量u的hr(u),得到一个向量u的d位二进制串{h1(u),2(u),…,d(u)},称之为向量u的d位签名Sd(u)。因为这个签名包含了向量的特征,两个签名之间大的偏差意味着两个向量很不同,所以任意两个签名的余弦相似度可以通过式(3)算得。此外,生成的随机向量越多,得到的向量间的相似度越准确。另一方面,如果用签名之间的相似度来表示式(3)中的概率,可以发现pr[hr(u)=hr(v)]=1-(hammingdistance)/d。这样一来,计算向量之间余弦相似度的问题被转化成了计算签名之间的海明距离。这样更快而且内存效率更高。在这种方式下,将一个k维的向量精简成了d位,并且保留了余弦相似度,这里的d<<k。所以在本发明描述中,海明距离与余弦相似度的意思相同。(1)对原始数据进行特征抽取生成向量在匹配过程之前,对原始数据进行了三步预处理来得到我们想要的输入。首先,本发明用Part-Of-SpeechTagger对实体分词,然后找出数据集中出现的所有不同的词(假设有k个),并构造出包含所有记录中词的词典,最后对每一条实体记录u生成一个k维的向量Vu作为输入,Vu中的第i维是词典中的第i个词在实体u中出现的频率。预处理后得到以实体编号Eu为键、以Vu为值的键值对集合,作为实体匹配的输入。(2)生成数据签名本发明生成数据签名步骤的目的是在尽可能保留实体特征的同时降低特征维度。输入数据是形如(Eu,Vu)的实体对,先随机生成d个k维向量{r1,r2,…,rd},d小于向量维度k,对于每个向量Vu,根据公式(1)所示的哈希函数hr(u)计算它的签名,所以可以将向量Vu的签名表示为:Vu={h1(u),hx(u),…,hd(u)]。每个向量u被表示成一个长度为d的二进制串Su,并且键值对变成(Su,Eu)。如果直接对一组签名排序,那些高相似度的签名对可能不会靠得比较近。例如,不论两个签名有多相似,如果它们的第一位不同,那么字典序的结果会差很多。PLEB算法引入了签名的随机变换来解决这个问题。在生成随机变换以后,海明距离小(即相似)的签名有更高的可能在排序结果中靠得比较近。因此可以找出每个签名的m个相邻签名然后生成实体对。一次随机变换是根据随机函数,将原签名的每一位映射到一个新的位置,可以看作是签名打乱重排,从而使所有签名尽可能有用均等的机会与相似的签名排到一起。一个随机变换函数类似于π(x)=(ax+b)modp,这里p是素数且0<a<p,0≤b<p,a和b都是随机取的。对每个签名做t次随机变换(随机选择t次a与b的值),这样得到了每个签名原始二进制串的t个不同变换{Pu1,Pu2,…,Put}。在本步骤中将其作为map的输出。因此对每一个实体,在本步骤执行后有t个形如(i,Pui,Eu)的不同输出,这里i表示变换的序号,Pui表示签名Su第i次交换的结果,Eu是实体编号。本发明签名生成步骤结束后,每个k维向量被转化成了t个d位的签名。由于d和t总是远小于k(为了更好的性能,d和t总是几十或几百,而k通常有几十万,这取决于输入数据的大小),对了数据量进行了一次很大的削减,同时也大大减少了分布式节点之间的网络传输代价。(3)分组排列签名并生成匹配对在签名生成步骤后,在分布式节点内引入一个分组排序过程,先根据变换序号对上一步的(i,Pui,Eu)分组,然后在每个分组中按字典序重排,得到t个形如(i,Li)的组,Li是一个有序 的签名列表,例如{(P5i,E5),(P2i,E2),(Pni,En)…,(P3i,E3)},是所有由第i次变换生成的签名安字典序排列的结果。然后在每个有序列表Li中,将每个签名与其相邻的m个签名生成匹配对(在有序列表中相邻签名的相似度较高)。如图2,Map阶段的输入实体包含(E0,V0)和(E4,V4),对应生成的签名为S0和S4;经过t次随机变换,得到其变换后签名{P01,P02,…,P0t},{P41,P42,…,P4t},在Map阶段的输出包含了对应每次变换的(i,P0i,E0)和(i,P4i,E4);在分组重排阶段,按key即变换序号对(i,Pui,Eu)进行分组,在每个分组中按变换后签名Pui的字典序重排得到(i,Li);对于实体对E0,E4,在有序列表L0中其签名相邻,于是生成匹配对E0E4。(4)计算匹配对相似度本发明在计算匹配对的海明距离之前,预先设定一个阈值,因为海明距离越近表示两个实体越相似,故在计算过程中,如果两个实体海明距离的计算结果低于设定的阈值,即实体的特征差异较小,则认为它们相似,以(Eu1Eu2,similarity)的形式输出这对实体及其相似度。如阈值为0.3,签名长度20,若P0i为01101010010110100011,P4i为01101001010011101011,其海明距离为即0.2,小于阈值,认为其相似,若P4i为01100001010011101001,海明距离为即0.35,大于阈值,认为不相似。(5)近实时查询以用户为单位,对文件路径列表进行分组与去重处理,得到关于源数据的文件路径集合,根据集合中的文件路径得到外存空间中的源数据文件。本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1