一种基于文法模板的实体抽取方法与流程
本发明涉及一种基于文法模板的实体抽取方法。
背景技术:
实体识别是自然语言处理中的一个重要基础工具,其主要任务是识别文本中具有特定意义的实体,如人名、地名、机构名、专有名词等,因而是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。
实体识别的过程主要包括两个部分:实体边界识别、确定实体类别(人名、地名或其他)。英语中的实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
目前实体识别的主要技术方法分为:基于规则和词典的方法、基于统计的方法、二者混合的方法。
基于规则和词典,则是语言学专家手工构造规则模板和字典库,以模式和字符串匹配为主要手段。
基于统计的方法,则是利用人工标注的语料进行训练,标注语料时不需要广博的语言学知识,但标注时间和语料的大小成正比,方法主要包括:隐马尔可夫模型、最大熵、支持向量机、条件随机场等。
混合方法则是上述二者的融合。
基于规则和字典的方法需要人工编辑大量模板和词库,维护代价高,且规则多是传统意义的正则表达式,没有上下文信息,识别过程需要依次遍历所有的规则库和字典库,效率不佳。
基于统计的方法虽然利用了机器学习,但只对通用的实体效果较好(如人名),难于兼顾准确率和召回率,并且模型的更新需要重新训练,从而不能实时的解决问题。
且此两种方法均对特定领域的实体识别效果不佳,如单个数字160,二者虽然能识别出为一个数字,但是对特定领域来说,需要更加精细的类别划分才能为应用系统所用,如数字160到底是电话,还是身高等,此时则需要更多的信息方能知晓。
技术实现要素:
针对目前实体识别的问题,特别是在特定领域中的特殊实体识别的缺陷,我们提出了一种基于文法模板抽取实体的方法。用户通过定义带上下文的文法模板,系统动态并行地寻找最佳文法匹配,从而高效地提取出其中特定意义的实体。在根据本发明的技术方案中,能引用已有文法或自身文法,并且支持正则、普通、及其组合,表达能力接近自然语言;抽象出三个匹配过程,采用最长消耗字符的匹配策略,高效地寻找最佳匹配;并且根据文法模板匹配结果进行二次加工,抽取所需的实体。
根据本发明的一个方面,提供了一种基于文法模板的实体抽取方法包括以下步骤:定义带上下文的文法模板,使得所述文法模板之间能够相互引用并且支持正则表达式、普通字符、及其组合;将所述文法模板中定义的每个文法转为文法树,针对所述文法树的结点的多个分支结点中的每一个进行匹配,找出其中消耗字符最多的一个分支结点 作为最佳匹配;并且根据文法模板的匹配结果进行类别过滤,以抽取所需的实体。
根据本发明的一个实施例,基于文法模板的实体抽取方法还包括从入口文法开始匹配的以下步骤:判断是否还有待匹配字符串。如果没有,则匹配完成,如果有,则将待匹配字符串根据文法树进行匹配。如果匹配失败,则将待匹配字符串移动一个字符并且重新执行上述步骤。如果匹配成功,则将待匹配字符串设置为成功匹配后剩余的未匹配的字符串并且重新执行上述步骤。
根据本发明的一个实施例,基于文法模板的实体抽取方法还包括从某个文法树开始匹配的以下步骤:循环遍历文法树的每一个分支结点,并将待匹配字符串根据各个分支结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为匹配状态。如果没有匹配成功的分支结点,则将所述匹配状态设置为失败状态。退出并返回所述匹配状态。
根据本发明的一个实施例,基于文法模板的实体抽取方法还包括在某个文法树的内部结点开始匹配的以下步骤:查看当前结点类型,根据不同结点类型分别进行匹配,并记录第一匹配状态。如果第一匹配状态为失败状态,则退出并返回第一匹配状态。如果当前结点还有待匹配的分支结点,则循环遍历当前结点的每一个分支结点,并将剩余的未匹配字符串根据各个分支结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为第二匹配状态,如果所述当前结点没有待匹配的分支结点或分支结点均匹配失败,则直接将第二匹配状态设置为失败状态。如果所述当前结点不为可结束结点,则当所述第二匹配状态为失败状态时,将所述第一匹配状态设置为失败状态。如果所述第一匹配状态和所述第二匹配状态均成功,则将所述第一匹配状态设置为所述第二匹配状态,退出并返回第一匹配状态。
根据本发明的一个实施例,其中能够实时地对所述文法树进行修改。
根据本发明的一个实施例,其中根据文法模板的匹配结果进行类别过滤还包括指定其它的类别和指定不同的类别范围。
附图说明
附图用于更好地理解本发明,并不构成对本发明的不当限定。其中:
图1是根据本发明实施例的基于文法模板的实体抽取方法的示意流程图;
图2是根据本发明实施例的基于文法模板的实体抽取方法中的具体的文法模板匹配步骤的示意流程图;以及
图3是根据本发明实施例的基于文法模板的实体抽取方法中的具体的在某个文法树的内部结点开始匹配的步骤的示意流程图。
具体实施方式
以下结合附图对本发明的示范性实施例做出说明,其中包括本发明实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本发明的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
图1是根据本发明实施例的一种基于文法模板的实体抽取方法的示意流程图。本发明的技术方案的重点在于文法模板的定义和文法模板的匹配,从而提取相关实体,因此下面分别对文法模板定义、文法模板匹配及实体抽取进行详细阐述。
如图1所示,基于文法模板的实体抽取方法包括:步骤S01,定义带上下文的文法模板,使得所述文法模板之间能够相互引用并且支 持正则表达式、普通字符、及其组合;步骤S02,将所述文法模板中定义的每个文法转为文法树,针对所述文法树的结点的多个分支结点中的每一个进行匹配,找出其中消耗字符最多的一个分支结点作为最佳匹配;以及步骤S03,根据文法模板的匹配结果进行类别过滤,以抽取所需的实体。
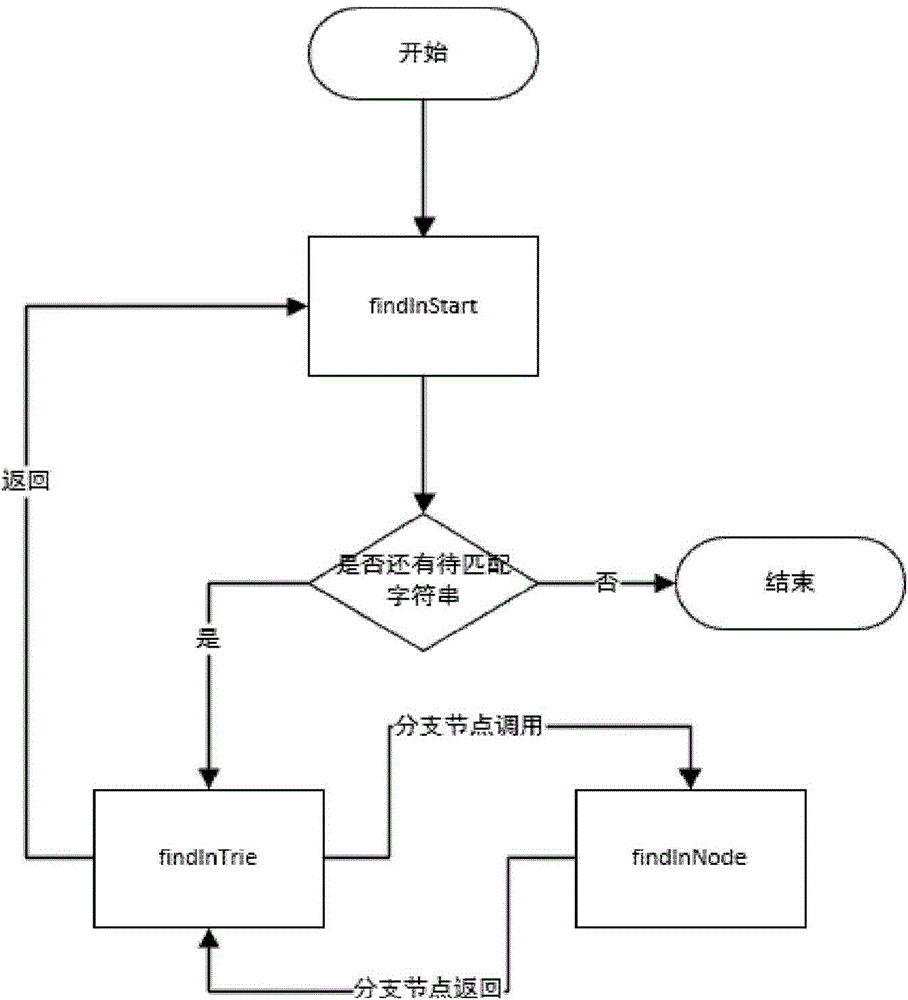
图2是根据本发明实施例的基于文法模板的实体抽取方法中的具体的文法模板匹配步骤的示意流程图。根据本发明的实施例上述三个匹配步骤分别为:findInStart、findInTrie、findInNode。其中,findInStart表示从入口文法开始匹配,findInTrie表示从某个文法树开始匹配,findInNode表示在某个文法树的内部结点开始匹配。
根据本发明的一个实施例,从入口文法开始匹配的过程包括:判断是否还有待匹配字符串。如果没有,则匹配完成,如果有,则将待匹配字符串根据文法树进行匹配。如果匹配失败,则将待匹配字符串移动一个字符并且重新执行上述步骤。如果匹配成功,则将待匹配字符串设置为成功匹配后剩余的未匹配的字符串并且重新执行上述步骤。
根据本发明的一个实施例,从某个文法树开始匹配的过程包括:循环遍历文法树的每一个分支结点,并将待匹配字符串根据各个分支结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为匹配状态。如果没有匹配成功的分支结点,则将所述匹配状态设置为失败状态。退出并返回所述匹配状态。
图3是根据本发明实施例的基于文法模板的实体抽取方法中的具体的在某个文法树的内部结点开始匹配的步骤的示意流程图。根据本发明的一个实施例,在某个文法树的内部结点开始匹配的过程包括:查看当前结点类型,根据不同结点类型分别进行匹配,并记录第一匹配状态。如果第一匹配状态为失败状态,则退出并返回第一匹配状态。 如果当前结点还有待匹配的分支结点,则循环遍历当前结点的每一个分支结点,并将剩余的未匹配字符串根据各个分支结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为第二匹配状态,如果所述当前结点没有待匹配的分支结点或分支结点均匹配失败,则直接将第二匹配状态设置为失败状态。如果所述当前结点不为可结束结点,则当所述第二匹配状态为失败状态时,将所述第一匹配状态设置为失败状态。如果所述第一匹配状态和所述第二匹配状态均成功,则将所述第一匹配状态设置为所述第二匹配状态,退出并返回第一匹配状态。
在根据本发明的一个实施例的基于文法模板的实体抽取方法中还能够实时地对所述文法树进行修改。以及在根据本发明的一个实施例的基于文法模板的实体抽取方法中根据文法模板的匹配结果进行类别过滤还包括指定其它的类别和指定不同的类别范围。
以下进一步参考附图,详细说明根据本发明的根据本发明的基于文法模板的实体抽取方法中的文法模板匹配的具体细节的描述。
(1)文法模板定义
本发明提出的文法模板本质上是一个规则库,但是其可带上下文,且模板之间可相互引用,从而表达能力接近自然语言,且因为可相互引用从而减少了文法模板的数量,具体的规则以如下身高的文法为例说明。
[num]={
r'\d+'
r'^[零一二三四五六七八九十百两]+'
}
[hight_prefix]={
身高
高
}
[hight_num]={
[num]
}
[hight_unit]={
厘米
cm
}
[hight]={
[hight_prefix]是[hight_num]
[hight_prefix]是[hight_num][hight_unit]
[hight_num]的[hight_prefix]
[hight_num][hight_unit]的[hight_prefix]
}
[start]={
[hight]
}
其意义如下:
上述例子中用中括号指出引用已有文法,用r开头表示一个正则表达式,其他的则为普通的字符而已,如身高、厘米。其中start为入口文法,表示识别过程从start开始,从而指定仅需识别的文法,避免无意义文法的识别(本例中单独识别hight_unit或hight_num、hight_prefix均是没有意义的,因为只有在文法hight中方能体现其的意义)。
因此任意一个文法(grammar)可定义如下:
[grammar]={
regx
chars
[other_grammar]
regx和chars和[other_grammar]的任意组合
}
其中regx表示正则表达式,chars表示普通字符,[other_grammar]表示引用已定义文法的other_grammar(注意other_grammar其实也可引用自身,因此具有强大的表达能力)。
(2)文法模板匹配
文法模板的匹配过程主要是将文法模板中定义的每个文法转为文法树(trie),待识别过程转移至该文法时则开始在该文法树上进行匹配,但因为文法树的结点可有多个分支,因此需要在每个可能的分支进行匹配,找出其中消耗字符最多的一个分支作为匹配,如果找不到,则回到原先开始匹配的位置,向前移动一个字符开始下一次匹配。其中因为一个文法可引用其他的文法,因此当识别过程转移至引用结点时,需要相应的转移至其引用的文法树进行匹配。其中可以实时地对所述文法树进行修改。
因此上述匹配的过程可抽象为三个过程:findInStart、findInTrie、findInNode。findInStart表示从入口文法开始匹配,findInTrie表示从某个文法树开始匹配,findInNode表示在某个文法树的内部结点开始匹配。具体的步骤如下;
findInStart:
步骤11:是否还有待匹配字符串,无则转步骤15,有则下一步;
步骤12:将待匹配字符串根据start文法树(findInTrie过程)进行匹配,匹配失败则转步骤14,成功则下一步;
步骤13:将待匹配字符串设置为步骤12中成功匹配后剩余的未匹配的字符串,并转步骤11;
步骤14:将带待匹配字符串移动一个字符,转步骤11;
步骤15:匹配完成。
findInTrie:
步骤21:循环遍历文法树的每一个分支结点node,并将待匹配字符串根据各个node结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为匹配状态state,如果没有结点匹配成功则置state为匹配失败,下一步;
步骤22:退出并返回匹配状态state。
findInNode(如图3所示):
步骤31:查看当前结点类型(正则、普通字符、内部引用文法树),根据不同结点类型分别进行匹配,并记录匹配状态state1(匹配成功与否和剩余的未匹配字符串),继续下一步;
步骤32:如果state1的匹配状态失败,则转步骤36;
步骤33:如果当前结点还有分支结点,则循环遍历该结点的每一个分支结点,并将剩余的未匹配字符串根据各个分支结点分别进行匹配,记录其中匹配成功且剩余的未匹配字符串长度最短的作为匹配状态state2,如果当前结点没有分支结点或分支结点均匹配失败则直接置state2为失败状态,继续下一步;
步骤34:如果当前结点不为可结束结点,则当state2的匹配状态失败时,设置state1的匹配状态为失败,继续下一步;
步骤35:如果state1和state2的匹配状态均成功,则将state1置为state2,继续下一步;
步骤36:退出并返回匹配状态state1。
以上文所述的身高文法为例说明,假设待匹配字符串为“身高是162cm”,则进行匹配后与文法模板“[hight_prefix]是[hight_num][hight_unit]”对应,因此hight_prefix=身高,hight_num=162,hight_unit=cm,也即最后文法匹配后返回“[hight_prefix:身高][hight_num:162][hight_unit:cm]”。
(3)实体抽取
实体抽取是根据系统需求指定所需的实体类别,然后在文法模板匹配的结果上进行过滤得到的。具体的步骤如下:
根据系统需求,指定所需的实体类别(与文法模板定义对应)types;
依次查看匹配结果列表中的每个结果,保留那些匹配类别在已指定的types里面,得到实体抽取结果;
退出完成,返回实体抽取结果。
如系统指定实体类别为hight_num、hight_unit,则文法模板匹配结果若为“[hight_prefix:身高][hight_num:162][hight_unit:cm]”过滤得到“[hight_num:162][hight_unit:cm]”,因而抽取了实体hight_num=162,hight_unit=cm。
当然实体的抽取不一定是简单的类别过滤,可以有更多复杂的逻辑,例如指定其它的类别和指定不同的类别范围),但核心思想是在文法模板匹配后得到的结果中进行二次加工所得,具体的抽取逻辑可根据应用场所不同而已。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!