爬取电商网站关键词品类信息的方法及装置与流程
本发明涉及互联网技术领域,尤其涉及一种爬取电商网站关键词品类信息的方法及装置。
背景技术:
关键词分类信息是一项十分重要的信息。尤其针对电商网站,针对用户的一个搜索关键词,正确的给出关键词所属的品类,对于电商网站以及对于搜索引擎营销都有十分重要的意义。其中,该处的品类只针对电商,其是指依据商品的属性,将商品划分为若干的类别,且根据不同的维度可以进行多级品类。
网络爬虫是一项互联网中十分通用,普遍存在技术。许多公司,个人都会通过网络爬虫来批量的、大规模的爬取万维网上的信息。通用的网络爬虫,其爬取信息的原理一般为,其维护一组统一资源定位符(Uniform Resource Locator,URL)列表,首先在列表中添加一个最初的URL,然后遍历URL列表中的每一个URL,获取URL对应的页面,然后提取页面中的URL,更新到URL列表中。
目前,在爬取电商网站关键词品类信息时,通常使用的就是通用的网络爬虫。由于电商网站的商品信息繁多,其不同商品对应不同的页面,故要获取不同关键字对应商品的品类信息,就需要反复的去从新爬取的网页提取网页的URL信息然后维护到URL列表中,之后再进行URL对应页面的获取,使得爬取电商网站关键词品类信息的效率较低。
技术实现要素:
有鉴于此,本发明提供一种爬取电商网站关键词品类信息的方法及装置,其主要目的在于提高爬取电商网站关键词品类信息的效率。
为达到上述目的,本发明提供如下技术方案:
一方面,本发明提供一种爬取电商网站关键词品类信息的方法,包括:
根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索统一 资源定位符URL;
访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息;
对所述网页的页面信息进行解析,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
另一方面,本发明提供一种爬取电商网站关键词品类信息的装置,包括:
构造单元,用于根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索统一资源定位符URL;
访问单元,用于访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息;
解析单元,用于对所述网页的页面信息进行解析,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
本发明提供的爬取电商网站关键词品类信息的方法及装置,其进行爬取电商网站关键词品类信息的网页URL不是从已知网页中提取的,而是根据电商网站信息、爬取品类信息的关键词构造的,这样相对于现有技术,省掉了从已知网页中提取URL并且将URL存储在URL列表中,之后再进行URL对应网页的爬取,在一定程度上提高了爬取的网页的效率,进而提高了爬取电商网站关键词品类信息的效率。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明实施例提供一种爬取电商网站关键词品类信息的方法流程图;
图2示出了本发明实施例提供一种爬取电商网站关键词品类信息的装置组成框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
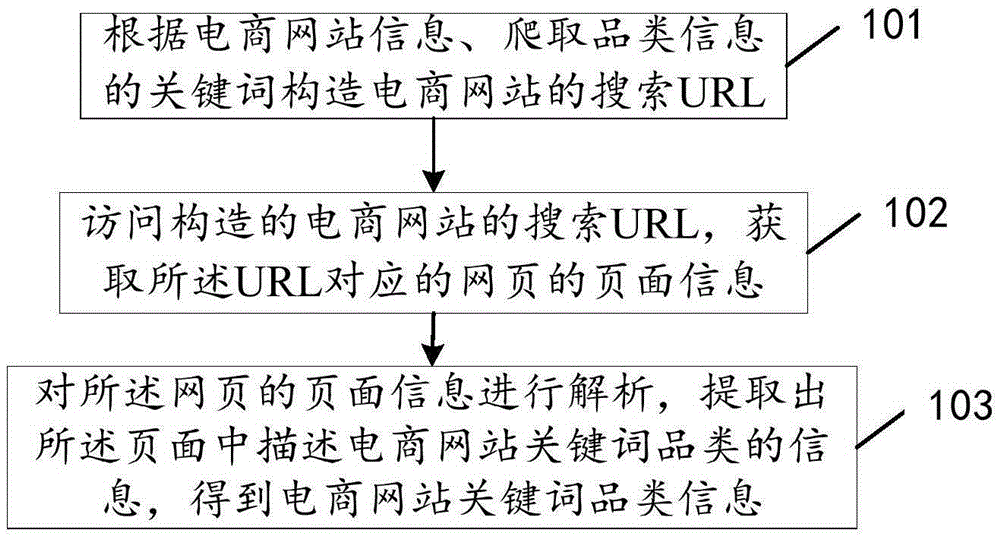
本发明实施例提供一种爬取电商网站关键词品类信息的方法,如图1所示,该方法包括:
101、根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索URL。
需要说明的是,爬取品类信息的访问关键词对应的URL,与在电商网站中输入关键词进行搜索,返回的页面是相同的,一般来说,电商网站的搜索URL有如下的格式http://search.XXX.com/Search?keyword=YYY,其中,XXX是电商网站的域名,YYY是指具体的爬取品类信息的关键词。
基于该种原理,本发明实施例中的电商网站信息可以为但不局限于电商网站的域名,根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索URL可以根据电商的域名信息、爬取品类信息的关键词构造如下形式的电商网站的搜索URL,构建的搜索URL的形式如上所示。对于每一个输入的关键词,替换URL中的YYY部分,构造对应的搜索URL。
102、访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息。
进一步的,为了加快访问构造的电商网站的搜索URL,在访问的时候,可以批量进行。例如,通过编程语言提供的网络库(如Python中的requests库)批量访问构造的电商网站的搜索URL。具体的可以通过一些多线程的方法,通过多线程同时并发批量访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息。当然也可以采用其他的批量访问方法,具体实施时本发明实施例对此不进行限制。
需要说明的是,在获取所述URL对应的网页的页面信息时,获取的页面信息可以为超文本标记语言(Hyper text Markup Language,HTML)代码格式,具体本发明实施例对此不进行限定。但是为了方便后续页面信息的解析,本发明实施例优选HTML代码格式的页面信息。
103、对所述网页的页面信息进行解析,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
其中,需要说明的是,在对所述网页的页面信息进行解析提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息时,根据获取的页面信息的格式不同会有所不同。
例如,当所述页面信息为HTML代码格式时,直接对所述HTML代码进行解析,便可以提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。其中,直接对所述HTML代码进行解析,便可以提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息,具体可以为利用Python中的lxml包,依据CSS(Cascading Style Sheets,它是一种用来表现HTML或XML(标准通用标记语言的一个子集)等文件样式的计算机语言)信息,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
本发明实施例中,其进行爬取电商网站关键词品类信息的网页URL不是从已知网页中提取的,而是根据电商网站信息、爬取品类信息的关键词构造的,这样相对于现有技术,省掉了从已知网页中提取URL并且将URL存储在URL列表中,之后再进行URL对应网页的爬取,在一定程度上提高了爬取的网页的效率,进而提高了爬取电商网站关键词品类信息的效率。
并且,本发明实施例在访问构造的搜索URL时,可以批量进行,进一步的提高了爬取的网页的效率,进而提高了爬取电商网站关键词品类信息的效率。
基于上述方法实施例,本发明实施例还提供一种爬取电商网站关键词品类信息的装置,如图2所示,该装置包括:
构造单元21,用于根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索URL;其中,爬取品类信息的访问关键词对应的URL,与在 电商网站中输入关键词进行搜索,返回的页面是相同的,一般来说,电商网站的搜索URL有如下的格式:
http://search.XXX.com/Search?keyword=YYY,其中,XXX是电商网站的域名,YYY是指具体的爬取品类信息的关键词。
基于该种原理,本发明实施例中的电商网站信息可以为但不局限于电商网站的域名,根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索URL可以根据电商的域名信息、爬取品类信息的关键词构造如下形式的电商网站的搜索URL,构建的搜索URL的形式如上所示。对于每一个输入的关键词,替换URL中的YYY部分,构造对应的搜索URL。
访问单元22,用于访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息;其中,进一步的,为了加快访问构造的电商网站的搜索URL,在访问的时候,可以批量进行。例如,通过编程语言提供的网络库(如Python中的requests库)批量访问构造的电商网站的搜索URL。具体的可以通过一些多线程的方法,通过多线程同时并发批量访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息。当然也可以采用其他的批量访问方法,具体实施时本发明实施例对此不进行限制。
需要说明的是,在获取所述URL对应的网页的页面信息时,获取的页面信息可以为HTML代码格式,具体本发明实施例对此不进行限定。但是为了方便后续页面信息的解析,本发明实施例优选HTML代码格式的页面信息。
解析单元23,用于对所述网页的页面信息进行解析,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。其中,需要说明的是,在对所述网页的页面信息进行解析提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息时,根据获取的页面信息的格式不同会有所不同。
例如,当所述页面信息为HTML代码格式时,直接对所述HTML代码进行解析,便可以提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。其中,直接对所述HTML代码进行解析,便可以提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关 键词品类信息,具体可以为利用Python中的lxml包,依据CSS信息,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
本发明实施例中,其进行爬取电商网站关键词品类信息的网页URL不是从已知网页中提取的,而是根据电商网站信息、爬取品类信息的关键词构造的,这样相对于现有技术,省掉了从已知网页中提取URL并且将URL存储在URL列表中,之后再进行URL对应网页的爬取,在一定程度上提高了爬取的网页的效率,进而提高了爬取电商网站关键词品类信息的效率。
并且,本发明实施例在访问构造的搜索URL时,可以批量进行,进一步的提高了爬取的网页的效率,进而提高了爬取电商网站关键词品类信息的效率。
所述爬取电商网站关键词品类信息的装置包括处理器和存储器,上述构造单元、访问单元和解析单元等均作为程序单元存储在存储器中,由处理器执行存储在存储器中的上述程序单元来实现相应的功能。
处理器中包含内核,由内核去存储器中调取相应的程序单元。内核可以设置一个或以上,通过调整内核参数来提高爬取电商网站关键词品类信息的效率。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM),存储器包括至少一个存储芯片。
本申请还提供了一种计算机程序产品,当在数据处理设备上执行时,适于执行初始化有如下方法步骤的程序代码:根据电商网站信息、爬取品类信息的关键词构造电商网站的搜索统一资源定位符URL;访问构造的电商网站的搜索URL,获取所述URL对应的网页的页面信息;对所述网页的页面信息进行解析,提取出所述页面中描述电商网站关键词品类的信息,得到电商网站关键词品类信息。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个 或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器 (DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!