一种基于特征自动学习的生物医学事件触发词识别方法与流程
本发明涉及一种基于特征自动学习的生物医学事件触发词识别方法,属于生物医学文本挖掘技术领域。
背景技术:
在生物医学领域,如何从蕴含大量文本的数据库中抽取出有用的信息,对于人类医学和生命科学的发展有着重要指导意义。鉴于此,越来越多的科学研究者投入到了生物医学文本的知识挖掘研究中,例如生物领域的命名实体识别、蛋白质与蛋白质之间的关系抽取以及药物与药物之间的关系抽取等研究方向。但是这对于挖掘生物医学文本中隐藏的多元关系仍是不够的,因此专注于蛋白质、基因等生物实体之间的动态作用或关系抽取的生物医学事件抽取任务引起了人们的广泛关注。
生物医学文本的事件抽取实质上就是信息抽取在生物医学领域的一个重要应用,已经成为信息抽取技术的一个有力工具,正在日益影响着生物医学自然语言处理的发展方向。生物医学领域内的事件指的是生物分子之间的交互作用以及作用后产生的结果,事件抽取目的在于从海量的生物医学文献中抽取出如事件主题、事件类型和事件触发词等生物事件的语义与角色信息。例如,给定语料中的一个句子,“LIF induced a dose-dependent increase in p24 antigen production in the chronically infected promonocytic...”,该句包含两个事件,一个是基因表达事件,触发词为“production”,对应事件元素为“antigen”;另一个为正向调控事件,触发词为“increase”,对应两个事件元素主体和客体,主体为上述的基因表达事件,客体为蛋白质“LIF”。
生物医学领域中,生物通路是在细胞和分子水平的一个重要模型,是我们至今较为理解的一个生活系统,这些通路有助于人们确定生物功能,帮助人们深刻认识生物疾病以至于发现新的药物,而生物医学事件抽取技术所具有的广泛应用价值正是在构建通路、丰富数据库等领域。由此可以看出,对生物医学事件抽取技术的学习与研究,对有效地自动识别出生物医学家所需要的信息以及发现被大量的可获得信息掩盖的关系,已经成为了一个必然的趋势。
近年来,事件抽取的步骤大多是分为事件触发词分类与事件元素检测,处于核心地位的事件元素的抽取通常需要在触发词抽取完成后才能进行。那么,事件触发词的检测处于至关重要的位置,它的性能的好坏直接决定了事件元素检测的准确性,所以对于事件触发词识别的研究意义同样十分重大。
由于生物医学事件触发词抽取存在的大量难点(如歧义性、特征选取等问题),寻找到行之有效的方法来进行生物医学事件触发词抽取是非常有必要的。近年来,国内外学者都已经展开了对生物医学事件触发词抽取技术的研究,提出了很多相对比较成熟的理论,一些生物医学事件触发词抽取的原型系统也应运而生。综合来看,生物医学事件触发词抽取的方法主要分为两大类:基于模式匹配方法和基于机器学习方法。
(1)基于模式匹配方法,模式匹配方法是在一些模式的指导下进行的,由此来识别和抽取出某种类型的事件触发词,通过采用各种算法将待抽取的触发词与给定的模式规则进行匹配。通常,模式匹配方法由模式获取和触发词抽取两个基本步骤组成。当然,采用不同的模式匹配,得到的事件触发词抽取系统也是各有千秋的,但从总体性能上来说,基于模式匹配的事件触发词抽取准确率较高,表示直观且清晰。事物都存在两面性,这种方法也存在其局限性,过分依赖于具体领域及文本格式,文本标志过程费时费力且容易产生歧义性,并且一旦语料发生转移或改变,其系统的可移植性就会大大降低,往往还需要重新做很多工作,因此在选取的时候要考虑实际情况。
(2)基于机器学习方法,机器学习方法是将事件触发词抽取看作是分类问题,建立在统计模型的基础之上,它的原理是选取恰当的特征以及核函数使用合适的分类器来达到事件触发词分类的目的。机器学习方法的优点在于灵活性较好,比较客观便于人们的理解,使用起来简单易懂。因此,现如今机器学习方法已经成为事件触发词抽取研究领域的主流和前沿方向。
技术实现要素:
为了克服现有技术中存在的不足,本发明目的是提供一种基于特征自动学习的生物医学事件触发词识别方法。该识别方法能有效地挖掘句子级别的高层次特征,减少了人工干预,并能进行自动的训练和学习。
为了实现上述发明目的,解决现有技术中所存在的问题,本发明采取的技术方案是:一种基于特征自动学习的生物医学事件触发词识别方法,包括以下步骤:
步骤1、数据预处理,包括对原始语料的处理以及外部数据资源的引入,具体包括以下子步骤:
(a)由于语料中跨句子的生物医学事件比例非常小,则在本发明方法中对生物医学事件触发词的检测是以句子为单位,使用生物医学领域分句工具Genia Sentence Splitter对实验语料中所有txt文件的数据进行句子切分;
(b)为了更好地挖掘生物医学事件触发词的语义和语法信息,本发明方法引入了由领域知识训练得到的词向量查找表,该查找表可以将单词映射成一个向量,这种向量表示的单词可以便捷地度量单词之间的相似度及其隐含的语义和语法信息;本发明方法获取的词向量,是在Pubmed上训练所得到的词向量,每个词向量维度为200维;
步骤2、构建事件触发词词典,采用基于统计的方法构建事件触发词词典,词典中所有单词都来源于训练集中标注为触发词的单词,经过统计分析,本发明发现在训练集已标注的触发词中,大多数的触发词是单个单词,而多个单词组成的触发词数量非常少,对于单个单词形成的触发词,本发明方法不做任何处理直接纳入到候选触发词词典中;而对于多个单词组成的触发词,本发明方法考虑到其不利于后期扩展以及增大了方法复杂度的原因,不直接将其纳入到候选触发词词典中,而是经过拆分成单个单词后,再纳入到候选触发词词典中;
步骤3、构建候选触发词实例,本发明方法设计的候选触发词实例主要包括以下两部分内容:
(a)邻居特征,遍历每个句子,如果句中的某个单词为候选触发词词典中的单词,抽取其在句中固定窗口内的单词作为候选触发词实例,这里,本发明方法选取的窗口大小为9,包括候选触发词本身以及其前4个单词和后四个单词;
(b)蛋白质特征,同时考虑到事件候选触发词和蛋白质通常会成对出现,两者之间有密不可分的联系,所以在构建候选触发词实例时,会将句中蛋白质信息作为人工设计的一个词语表示并加入到构建候选触发词实例中;本发明方法所设计的蛋白质信息包括三类:一是,候选触发词在句子中的前s个单词和后s个单词内是否出现蛋白质,二是,出现的所有蛋白质的名称,三是,出现的所有蛋白质的类型;根据语言表达的一般习惯,事件触发词与它较近的蛋白质构成一个事件的可能性较之远处的蛋白质会更大,所以本发明方法选取的s等于4,即在句子中距离候选触发词小于4个单词的范围内的蛋白质信息,能够更好地描述触发词隐含的类别信息,从而达到提升事件触发词检测整体性能的目的;
步骤4、卷积神经网络模型学习特征,为了学习到候选触发词实例隐含的高层次特征,本发明方法利用卷积神经网络来自动训练和学习特征,具体包括以下子步骤:
(a)对于每个单句里出现在候选触发词词典中的单词,本发明方法都能得到一个由若干个单词组成的序列,称之为一个候选触发词实例;再利用所获得的词向量查找表将候选触发词实例中的每个单词映射成向量,对于在词向量查找表中没有找到对应词向量的单词,本发明方法采用随机初始化的方式,从而得到候选触发词实例矩阵其中词向量的维度k为200维;n表示一个候选触发词实例中所含有的单词数量,即为一个候选触发词实例的长度;
(b)将所得候选触发词实例矩阵输入到含有多个并行卷积层和池化层的卷积神经网络进行更高层特征的学习,卷积神经网络主要涉及到卷积层、池化层和输出层;
卷积层,本发明方法利用卷积层中的卷积操作来融合候选触发词实例的邻居特征和蛋白质特征,从而学习到全局特征,本发明方法在输入候选触发词实例上使用滑动窗口的思想,窗口内的w个词向量构成矩阵使用共享权重矩阵W进行卷积操作,从而生成一个新特征Ai:
Ai=f(W*Xi+b) (1)
式(1)中,W表示共享权重矩阵,X表示词向量矩阵,b表示偏倚项,f表示非线性激活函数,通常选自sigmoid函数或Rectified Linear Units函数中的一种;当滑动窗口w个词向量以1为步长,在长度为n的候选触发词实例序列上滑动时,得到n-w+1个词向量矩阵,采取如上所述同样的操作,便可产生一个特征向量A:
A=[A1,A2,…,An-w+1] (2)
式(2)中,A1、A2、An-w+1都是通过公式(1)计算得到的新特征,需要注意的是,该特征向量每一维度的数值都是由同一个共享权重矩阵W操作所得到的,大大减少了模型训练所需的参数个数;
池化层,为了确定上述得到的特征向量A中在哪个维度上的数值是最有用的特征,本发明方法使用池化操作,即最大化操作,选取该特征向量A的最大数值代表这种特征,即:
aj=max{A1,A2,…,An-w+1} (3)
式(3)中,aj表示这种最有代表性的特征,为了获取多种不同的特征,本发明方法采用多个不同的共享权重矩阵进行卷积操作,给定m个不同的共享权重矩阵W,得到一组特征M:
M=[a1,a2,…,aj,…,am] (4)
式(4)中,a1、aj、am是采用公式(3)求得第1、第j和第m个不同共享权重矩阵所得到的最有代表性特征;
输出层,本发明方法采用多个卷积层和池化层并行进行特征学习,这里给出并行度p的定义,即为卷积层和池化层并行操作的数量,通过给定并行度p,求得输出层输出所学习到的特征集F:
F=[M1,M2,…,Mj,…,Mp] (5)
式(5)中,M1、Mj、Mp是通过公式(4)求得,总共有p组,共同构成最后学习到的特征集;
步骤5、神经网络模型训练,本发明方法将卷积神经网络学习到的特征集F输入到含有输入层、隐含层和输出层的三层神经网络模型,使用实验语料中的训练集进行分类模型的训练;
步骤6、事件触发词分类,使用步骤5中训练得到的模型,在实验语料中的测试集上进行事件触发词的检测。
本发明有益效果是:一种基于特征自动学习的生物医学事件触发词识别方法,包括以下步骤:步骤1、数据预处理,步骤2、构建事件触发词词典,步骤3、构建候选触发词实例,步骤4、卷积神经网络模型学习特征,步骤5、神经网络模型训练,步骤6、事件触发词分类。与已有技术相比,本发明方法具有以下优点:一是,简化了对数据的复杂预处理,省去了人工进行特征设计的繁琐步骤;二是,引入了领域知识,有效地利用了大量未标注语料等外部资源;三是,使用卷积神经网络进行特征的自动学习,不仅减少了人工干预,而且能够挖掘和探索到更深层次的句子级别特征,并通过融合局部特征,发现了隐含的全局特征,有助于识别触发词类别;四是,本发明方法在MLEE语料上得到了较好的实验结果,事件触发词检测的整体性能有所提高。
附图说明
图1是本发明方法步骤流程图。
图2是本发明生物医学事件触发词检测实验效果对比图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种基于特征自动学习的生物医学事件触发词识别方法,包括以下步骤:
步骤1、数据预处理,包括对原始语料的处理以及外部数据资源的引入,具体包括以下子步骤:
(a)由于语料中跨句子的生物医学事件比例非常小,则在本发明方法中对生物医学事件触发词的检测是以句子为单位,使用生物医学领域分句工具Genia Sentence Splitter对实验语料中所有txt文件的数据进行句子切分;
(b)为了更好地挖掘生物医学事件触发词的语义和语法信息,本发明方法引入了由领域知识训练得到的词向量查找表,该查找表可以将单词映射成一个向量,这种向量表示的单词可以便捷地度量单词之间的相似度及其隐含的语义和语法信息;本发明方法获取的词向量,是在Pubmed上训练所得到的词向量,每个词向量维度为200维;
步骤2、构建事件触发词词典,采用基于统计的方法构建事件触发词词典,词典中所有单词都来源于训练集中标注为触发词的单词,经过统计分析,本发明发现在训练集已标注的触发词中,大多数的触发词是单个单词,而多个单词组成的触发词数量非常少,对于单个单词形成的触发词,本发明方法不做任何处理直接纳入到候选触发词词典中;而对于多个单词组成的触发词,本发明方法考虑到其不利于后期扩展以及增大了方法复杂度的原因,不直接将其纳入到候选触发词词典中,而是经过拆分成单个单词后,再纳入到候选触发词词典中;
步骤3、构建候选触发词实例,本发明方法设计的候选触发词实例主要包括以下两部分内容:
(a)邻居特征,遍历每个句子,如果句中的某个单词为候选触发词词典中的单词,抽取其在句中固定窗口内的单词作为候选触发词实例,这里,本发明方法选取的窗口大小为9,包括候选触发词本身以及其前4个单词和后四个单词;
(b)蛋白质特征,同时考虑到事件候选触发词和蛋白质通常会成对出现,两者之间有密不可分的联系,所以在构建候选触发词实例时,会将句中蛋白质信息作为人工设计的一个词语表示并加入到构建候选触发词实例中;本发明方法所设计的蛋白质信息包括三类:一是,候选触发词在句子中的前s个单词和后s个单词内是否出现蛋白质,二是,出现的所有蛋白质的名称,三是,出现的所有蛋白质的类型;根据语言表达的一般习惯,事件触发词与它较近的蛋白质构成一个事件的可能性较之远处的蛋白质会更大,所以本发明方法选取的s等于4,即在句子中距离候选触发词小于4个单词的范围内的蛋白质信息,能够更好地描述触发词隐含的类别信息,从而达到提升事件触发词检测整体性能的目的;
步骤4、卷积神经网络模型学习特征,为了学习到候选触发词实例隐含的高层次特征,本发明方法利用卷积神经网络来自动训练和学习特征,具体包括以下子步骤:
(a)对于每个单句里出现在候选触发词词典中的单词,本发明方法都能得到一个由若干个单词组成的序列,称之为一个候选触发词实例;再利用所获得的词向量查找表将候选触发词实例中的每个单词映射成向量,对于在词向量查找表中没有找到对应词向量的单词,本发明方法采用随机初始化的方式,从而得到候选触发词实例矩阵其中词向量的维度k为200维;n表示一个候选触发词实例中所含有的单词数量,即为一个候选触发词实例的长度;
(b)将所得候选触发词实例矩阵输入到含有多个并行卷积层和池化层的卷积神经网络进行更高层特征的学习,卷积神经网络主要涉及到卷积层、池化层和输出层;
卷积层,本发明方法利用卷积层中的卷积操作来融合候选触发词实例的邻居特征和蛋白质特征,从而学习到全局特征,本发明方法在输入候选触发词实例上使用滑动窗口的思想,窗口内的w个词向量构成矩阵使用共享权重矩阵W进行卷积操作,从而生成一个新特征Ai:
Ai=f(W*Xi+b) (1)
式(1)中,W表示共享权重矩阵,X表示词向量矩阵,b表示偏倚项,f表示非线性激活函数,通常选自sigmoid函数或Rectified Linear Units函数中的一种;当滑动窗口w个词向量以1为步长,在长度为n的候选触发词实例序列上滑动时,得到n-w+1个词向量矩阵,采取如上所述同样的操作,便可产生一个特征向量A:
A=[A1,A2,…,An-w+1] (2)
式(2)中,A1、A2、An-w+1都是通过公式(1)计算得到的新特征,需要注意的是,该特征向量每一维度的数值都是由同一个共享权重矩阵W操作所得到的,大大减少了模型训练所需的参数个数;
池化层,为了确定上述得到的特征向量A中在哪个维度上的数值是最有用的特征,本发明方法使用池化操作,即最大化操作,选取该特征向量A的最大数值代表这种特征,即:
aj=max{A1,A2,…,An-w+1} (3)
式(3)中,aj表示这种最有代表性的特征,为了获取多种不同的特征,本发明方法采用多个不同的共享权重矩阵进行卷积操作,给定m个不同的共享权重矩阵W,得到一组特征M:
M=[a1,a2,…,aj,…,am] (4)
式(4)中,a1、aj、am是采用公式(3)求得第1、第j和第m个不同共享权重矩阵所得到的最有代表性特征;
输出层,本发明方法采用多个卷积层和池化层并行进行特征学习,这里给出并行度p的定义,即为卷积层和池化层并行操作的数量,通过给定并行度p,求得输出层输出所学习到的特征集F:
F=[M1,M2,…,Mj,…,Mp] (5)
式(5)中,M1、Mj、Mp是通过公式(4)求得,总共有p组,共同构成最后学习到的特征集;
步骤5、神经网络模型训练,本发明方法将卷积神经网络学习到的特征集F输入到含有输入层、隐含层和输出层的三层神经网络模型,使用实验语料中的训练集进行分类模型的训练;
步骤6、事件触发词分类,使用步骤5中训练得到的模型,在实验语料中的测试集上进行事件触发词的检测。
在本发明中,所使用的数据集为Multi-Level Event Extraction(MLEE)。将其训练集和发展集合并一同作为训练模型的数据,测试集用于检测本方法的性能。MLEE数据集共有19种生物事件类型,分为四个大类别,分别为“”Anatomical、“Molecular”、“General”和“Planned”,具体类别信息如表1所示,对应标号的引入是为了简化事件类别的名称。
表1
对于卷积神经网络的训练,本发明方法使用梯度下降算法来优化参数,并且在训练的过程采取自动调整学习率的方法(Adapdelta)。通常情况下,神经网络的训练需要花费大量的时间,所以选择使用python中的类库theano来加速计算。对于模型的一些基本参数设置如表2所示。
表2
并行度p取值为3,滑动窗口大小分别为7、8、9;词向量的维度为200维;不同的共享权重矩阵共设置2500个,则可以得到2500个不同的特征表示,由于并行度为3,可以得到三组特征,共计7500个特征,作为神经网络分类模型的输入,我们设置隐藏层的单元节点数和输入层相同,为7500。
本发明方法所采用的评价指标为准确率(Precision),召回率(Recall)与F值(F-measure),分别用P,R,F表示。针对本发明方法事件触发词识别任务,这三个评价指标通过公式(6)、(7)(8)并结合表3进行计算。
表3
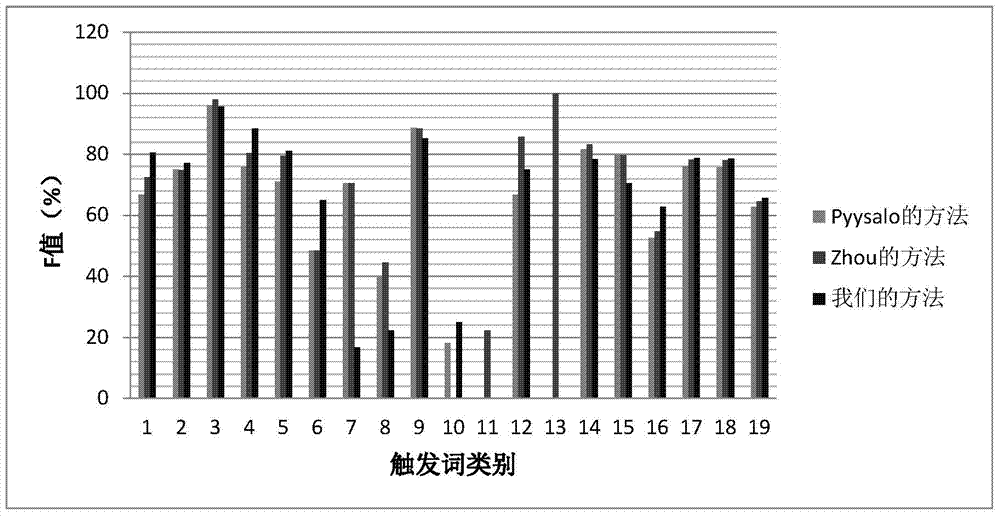
如图2所示,本发明方法选取运用MLEE数据集进行触发词识别的Pyysalo的方法和Zhou的方法作为对比方法。对于MLEE数据集中的所有事件类型的触发词识别结果中,其中有十类事件本发明结果都好于对比方法的结果,而且有五类事件的F值的提高幅度均超过了8%;值得注意的是,对于复杂事件中的三个调节(Regulation,Positive_regulation和Negative_regulation)事件的F值均有提高,说明本发明对于含有嵌套结构的复杂事件的触发词识别有很大帮助;在总体性能方面,本发明得到的识别F值也高于对比实验。这表明,本发明在生物医学事件触发词识别上是有效的。
本发明优点在于:一是,简化了对数据的复杂预处理,省去了人工进行特征设计的繁琐步骤;二是,引入了领域知识,有效地利用了大量未标注语料等外部资源;三是,使用卷积神经网络进行特征的自动学习,不仅减少了人工干预,而且能够挖掘和探索到更深层次的句子级别特征,并通过融合局部特征,发现了隐含的全局特征,有助于识别触发词类别;四是,本发明方法在MLEE语料上得到了较好的实验结果,事件触发词检测的整体性能有所提高。
- 还没有人留言评论。精彩留言会获得点赞!