基于Hadoop的日志数据挖掘方法及系统与流程
本发明涉及计算机数据处理领域,尤其涉及一种基于Hadoop的日志数据挖掘方法及系统。
背景技术:
进入互联网时代以来,如何在不断暴增的海量用户信息中,快速寻找更合适、可量化、可预测的精准营销策略,成为了包括运营商在内众多企业的核心需求。
然而,传统数据库对数据运算能力有限,存储成本昂贵,无法满足海量数据的挖掘的需求。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
本发明的主要目的在于提供一种基于Hadoop的日志数据挖掘方法及系统,旨在解决传统数据库对数据运算能力有限,存储成本昂贵,无法提供海量数据的挖掘的技术问题。
为实现上述目的,本发明提供的一种基于Hadoop的日志数据挖掘方法,包括:
将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中;
若所述Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对所述Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合;
根据所述第二日志数据集合中的日志数据的维度对所述第二日志数据集合中的日志数据进行维度划分,将得到的不同维度对应的第三日志数据集合保存至所述Hadoop数据库中。
优选地,所述方法还包括:
从网络侧获取当前时间段内的日志数据;
对所述当前时间段内的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
优选地,所述从网络侧获取当前时间段内的日志数据的步骤之后还包括:
对所述当前时间段内的日志数据进行数据清洗,得到当前时间段内清洗后的日志数据;
则所述对所述当前时间段内的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合的步骤包括:
对所述当前时间段内清洗后的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
优选地,所述方法还包括:
若接收到数据查询指令,则按照所述数据查询指令中包含的查询维度从所述Hadoop数据库中读取与所述查询维度对应的第三日志数据集合;
对所述第三日志数据集合进行数据分析,并在显示界面上显示数据分析的结果。
优选地,所述对所述第三日志数据集合进行数据分析,包括:
按照预先设置的聚类算法对所述第三日志数据集合中的用户进行用户分组,得到用户分组列表;
根据用户分组列表中的用户的日志数据得到至少两个用户维度对应的级别配置表,所述用户维度是预先设置的,所述级别配置表中包含所述用户分组列表中的用户按照所述用户维度进行分级确定的级别。
为实现上述目的,本发明还提供一种基于Hadoop的日志数据挖掘系统,包括:
第一保存模块,用于将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中;
并行聚集模块,用于若所述Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对所述Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合;
划分保存模块,根据所述第二日志数据集合中的日志数据的维度对所述第二日志数据集合中的日志数据进行维度划分,将得到的不同维度对应的第三日志数据集合保存至所述Hadoop数据库中。
优选地,所述系统还包括:
获取模块,用于从网络侧获取当前时间段内的日志数据;
第一聚集模块,用于对所述当前时间段内的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
优选地,所述系统还包括清洗模块;
所述清洗模块用于在所述获取模块获取所述当前时间段内的日志数据之后,对所述当前时间段内的日志数据进行数据清洗,得到当前时间段内清洗后的日志数据;
且所述第一聚集模块具体用于对所述当前时间段内清洗后的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
优选地,所述系统还包括:
读取模块,用于若接收到数据查询指令,则按照所述数据查询指令中包含的查询维度从所述Hadoop数据库中读取与所述查询维度对应的第三日志数据集合;
分析模块,用于对所述第三日志数据集合进行数据分析,并在显示界面上显示数据分析的结果。
优选地,所述分析模块包括:
聚类模块,用于按照预先设置的聚类算法对所述第三日志数据集合中的用户进行用户分组,得到用户分组列表;
获取显示模块,用于根据用户分组列表中的用户的日志数据得到至少两个用户维度对应的级别配置表,所述用户维度是预先设置的,所述级别配置表中包含所述用户分组列表中的用户按照所述用户维度进行分级确定的级别
本发明提供一种基于Hadoop的日志数据挖掘方法,将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中,若Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对该Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合,根据该第二日志数据集合中的日志数据的维度对该第二日志数据集合中的日志数据进行维护划分,将得到的不同维度对应的第三日志数据集合保存至该Hadoop数据库中,以完成日志数据的挖掘。由于Hadoop数据库 具有较好的分布式存储能力及并行运算能力,利用该Hadoop数据库对日志数据进行分布式存储及利用并行运算模型进行并行运算,能够快速有效地实现海量数据的挖掘,满足对海量数据进行挖掘的存储及运算需求。
附图说明
图1为本发明第一实施例的基于Hadoop的日志数据挖掘方法的流程示意图;
图2为图1中的第一实施例的步骤101之前追加步骤的流程示意图;
图3为图1中的第一实施例的步骤103之后追加步骤的流程示意图;
图4为本发明第二实施例中基于Hadoop的日志数据挖掘系统的功能模块的示意图;
图5为图4的第二实施例中追加的功能模块的示意图;
图6为图4的第二实施例中追加的功能模块的示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种基于Hadoop的日志数据挖掘方法,将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中,若Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对该Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合,根据该第二日志数据集合中的日志数据的维度对该第二日志数据集合中的日志数据进行维护划分,将得到的不同维度对应的第三日志数据集合保存至该Hadoop数据库中,以完成日志数据的挖掘。由于Hadoop数据库具有较好的分布式存储能力及并行运算能力,利用该Hadoop数据库对日志数据进行分布式存储及利用Hadoop中的预置的并行运算模型进行并行运算,能够快速有效地实现海量数据的挖掘,满足对海量数据进行挖掘的存储及运算需求。
请参阅图1,为本发明第一实施例中基于Hadoop的日志数据挖掘方法的流程示意图,包括:
步骤101、将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中;
在本发明实施例中,基于Hadoop的日志数据挖掘方法可以应用在基于Hadoop的日志数据挖掘系统(以下简称为:挖掘系统)中,挖掘系统将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中。
其中,挖掘系统是按照时间段获取第一日志数据集合的,例如,若时间段是15分钟或者是30分钟,则挖掘系统获取当前的15分钟时间段内的第一日志数据集合或者获取当前的30分钟时间段内第一日志数据集合。
其中,该时间段是获取数据的周期,可以按照数据量的大小确定该时间段的时长。
其中,Hadoop可实现分布式文件系统(Hadoop Distributed File System,HDFS),Hadoop的框架核心是Hadoop数据库及并行运算模型,其中,Hadoop数据库能够为海量的数据提供分布式存储,并行运行模型能够为海量的数据提供并行运算。
优选的,该并行运算模型为mapreduce运算模型。
步骤102、若Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合;
在本发明实施例中,挖掘系统在每个时间段内都将获取到的第一日志数据集合保存至Hadoop数据库中,若该Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则可利用该Hadoop框架中的预置的并行运算模型对Hadoop数据库中的第一日志数据集合进行聚集处理,得到第二日志数据集合。
其中,在实际应用中可根据具体的需要预先设置该数值,例如,若上述的时间段为15分钟,且需要对一个小时内的第一日志数据集合进行聚集处理,则该预先设置的数值为4;若上述的时间段为30分钟,且需要对1天内的第一日志数据集合进行聚集处理,则该预先设置的数值为48。
可以理解的是,基于上述的聚集处理,挖掘系统还可以利用类似的方式 得到不同时间周期内的日志数据集合,例如:可以利用4个时间段为15分钟的第一日志数据集合得到一个小时内的日志数据集合,可以利用24个一个小时内的日志数据集合得到一天内的日志数据集合,可以利用30个一天内的日志数据集合得到一个月内的日志数据集合,且以此类推,可以得到不同时间内的日志数据集合,以满足不同的需求。
在本发明实施例中,挖掘系统在利用预置的并行运算模型进行并行聚集处理时,是将相同的日志数据的计数值进行累加。
步骤103、根据第二日志数据集合中的日志数据的维度对第二日志数据集合中的日志数据进行维度划分,将得到的不同维度对应的第三日志数据集合保存至Hadoop数据库中。
在本发明实施例中,挖掘系统在得到第二日志数据集合之后,将根据该第二日志数据集合中的日志数据的维度对第二日志数据集合中的日志数据进行维度划分,且将得到的不同维度对应的第三日志数据集合保存至Hadoop数据库中,以实现海量日志数据的挖掘,且保存的第三日志数据集合可以作为用户数据查询的数据源,支持显示界面的图标、图形查询及多维度查询,使得能够多角度展示数据,达到数据挖掘的展示效果。
其中,日志数据的维度有很多,包括但不限于上网内容、上网位置和上网时间,其中,上网内容是指在用户的浏览位置,该浏览位置可以是具体的某一个位置,例如可以是百度、搜狐、新浪微博等等,也可以是一类网址,例如:音乐、电影等等。上网位置是指用户使用的IP位置所处的地理位置范围,上网时间是指生成日志数据的时间。且维度的划分是根据系统的要求,通过维度上的数据完成对用户整体行为的进一步刻画。需要说明的是,对于不同类型的日志数据,其日志数据的维度也是不一样的,例如:在对日志数据中的用户的流量数据采用本发明实施例中的技术方案进行数据挖掘时,其维度除了上述的上网内容、上网位置和上网时间以外,还可以包含上网频率、用户年龄、月消费等等,因此在实际应用中,可以根据具体的需要进行维度划分,此处不做限定。
优选的,在本发明实施例中,挖掘系统在将不同维度对应的第三日志数据集合保存至Hadoop数据库中之后,还可以将该不同维度对应的第三日志数据集合保存至列存储阵列中,使得能够实现Hadoop数据库和列存储阵列的协 同工作,使得能够满足不同的应用场景的数据需求。
优选的,由于挖掘系统是在Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值的情况下才会执行上述的并行聚集处理及维度划分的操作的,因此,得到的第三日志数据集合其实也对应着一个时间段,挖掘系统在保存时,可以保存维度、时间段及第三日志数据集合三者之间的对应关系。
在本发明实施例中,挖掘系统将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中,若Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用预置的并行运算模型对该Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合,根据该第二日志数据集合中的日志数据的维度对该第二日志数据集合中的日志数据进行维护划分,将得到的不同维度对应的第三日志数据集合保存至该Hadoop数据库中,以完成日志数据的挖掘。由于Hadoop数据库具有较好的分布式存储能力及并行运算能力,利用该Hadoop数据库对日志数据进行分布式存储及利用Hadoop中的并行运算模型进行并行运算,能够快速有效地实现海量数据的挖掘,满足对海量数据进行挖掘的存储及运算需求。
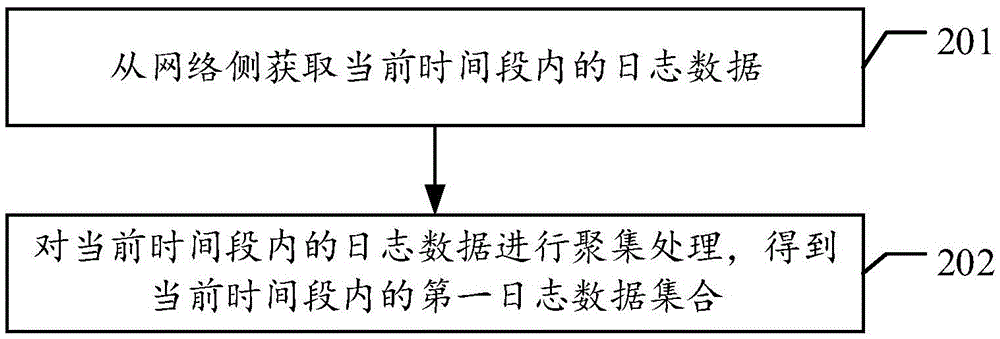
请参阅图2,为本发明图1所示的第一实施例中步骤101之前追加步骤的流程示意图,包括:
步骤201、从网络侧获取当前时间段内的日志数据;
在本发明实施例中,挖掘系统是从网络侧获取当前时间段内的日志数据,具体的:挖掘系统可以通过日志数据的抽取的方式从网络侧获取当前时间段内的日志数据,或者,可以利用网络爬虫技术从网络侧获取当前时间段内的日志数据,或者,可以通过从网络侧的BOSS营帐数据库中获取当前时间段内的日志数据,或者,可以接受网络侧的第三方厂商提供的当前时间段内的日志数据,或者结合上述的至少两种方式获取当前时间段内的日志数据。
步骤202、对当前时间段内的日志数据进行聚集处理,得到当前时间段内的第一日志数据集合。
在本发明实施例中,挖掘系统在获取到当前时间段内的日志数据之后,对当前时间段内的日志数据进行聚集处理,得到当前时间段的第一日志数据 集合。
其中,步骤202中聚集可以是根据日志数据的内容进行分类,把相同内容或者属于同一类的内容的日志数据作为一条数据进行数目上的累加,聚集后得到的第一日志数据集合的数量级将远远低于获取到的当前时间段内的日志数据的数量级,当时数据意义被完整的保存下来。
在本发明实施例中,挖掘系统通过图2所示的追加的步骤实现第一日志数据集合的获取,且通过对从网络侧获取到的当前时间段内的日志数据进行聚集,能够有效的降低日志数据的数量级,使得在Hadoop数据库中所所需要的存储空间减小,节约存储空间。
优选的,在本发明实施例中,挖掘系统在执行步骤202之前还可以执行以下步骤:
对当前时间段内的日志数据进行数据清洗,得到当前时间段内清洗后的日志数据;
在本发明实施例中,挖掘系统在对获取到的当前时间段内的日志数据进行聚集之前,还可以对当前时间段内的日志数据进行数据清洗,得到当前时间段内清洗后的日志数据。
且若挖掘系统执行了上述步骤,则也需要对步骤202进行适应性的调整,且步骤202适应性调整为:
对当前时间段内清洗后的日志数据进行聚集处理,得到当前时间段内的第一日志数据集合。
其中,对日志数据进行清洗可以是去除一些不满足预先设置的数据类型的日志数据,和/或,发现并纠正日志数据中可识别的错误,并修正或者删除出现可识别的日志数据。
在本发明实施例中,挖掘系统通过对当前时间段内的日志数据进行数据清洗,使得能够除去一些无用或者出错的日志数据,降低日志数据处理的数量,且便于更好的进行数据挖掘。
请参阅图3,为本发明图1所示第一实施例中的步骤103之后追加步骤的流程示意图,包括:
步骤301、若接收到数据查询指令,则按照数据查询指令中包含的查询维度从Hadoop数据库中读取与查询维度对应的第三日志数据集合;
在本发明实施例中,挖掘系统在将得到的第三日志数据保存至Hadoop数据库中之后,用户可以通过输入数据查询指令的方式请求查询数据,且若挖掘系统接收到数据查询指令,则按照数据查询指令中包含的查询维度从Hadoop数据库中读取与维度对应的第三日志数据集合。
优选的,该数据查询指令中还可以包含某个时间段,则挖掘系统将读取在该时间段内,该查询维度对应的第三日志数据集合。
步骤302、对第三日志数据集合进行数据分析,并在显示界面上显示数据分析的结果。
在本发明实施例中,挖掘系统还将对第三日志数据集合进行数据分析,并在显示界面上显示数据分析的结果,具体的:挖掘系统按照预先设置的聚类算法对第三日志数据集合中的用户进行用户分组,得到用户分组列表;根据用户分组列表中的用户的日志数据得到至少两个用户维度对应的级别配置表,并在显示界面上显示级别配置表;用户维度是预先设置的,级别配置表中包含用户分组列表中的用户按照用户维度进行分级确定的级别。
其中,用户维度可以分为横向维度和纵向维度,并且在不同的维度下对用户进行评级。例如:挖掘系统得到的用户分组,包括:所有用户组及微博用户组,对于所有用户组,对该组内的所有用户按照使用的流量大小进行名次排行,排名前20%的为五星级用户,排名前20%至40%的为四星级用户,并以此类推,确定该所有用户组中的每一个用户的星级。此即为横向维度评级。对于微博用户组合中的用户,按照用户启动微博之后产生的流量大小进行名次排行,排名前20%的为五星级用户,排名前20%至40%的为四星级用户,并以此类推,确定该微博用户组中的每一个用户的星级。此即为纵向维度评级。通过横向维度评级和纵向维度评级,使得能够对实现对用户群体的画像展示,以便业务专家针对具体的分组画像得到有针对性的方案。
优选的,该预先设置的聚类算法可以是K-means算法。
其中,查询维度是基于Hadoop数据库中保存的第三日志数据集合对应的维度设置的,例如:查询维度可以是上网内容、上网时间、上网位置等中的任意一种或者任意几种。
在本发明实施例中,挖掘系统通过按照数据查询指令中包含的查询维度从Hadoop数据库中读取与查询维度对应的第三日志数据集合,并对该第三日志数据集合进行数据分析,且在显示界面上显示数据分析的结果,使得能够有效的将数据挖掘的结果显示给用户。
需要说明的是,在本发明实施例中,基于Hadoop数据库的日志数据的挖掘方法可以应用在流量数据的精准营销系统中,例如,可以通过图1至图3所示实施例中描述的技术方案实现目标用户的挖掘及营销选址的挖掘等等,给运营商对目标用户或者目标基站小区做有针对性精细化营销提供数据基础。
其中,若是需要确定目标用户,则在图3所示实施例中的步骤301中,查询维度可以是上网内容或者上网流量,若需要确定目标基站小区,则查询维度可以是上网位置。
在实际应用中,用户可以根据具体的需要选择查询维度,此处不做限定。
请参阅图4,为本发明第二实施例中基于Hadoop的日志数据挖掘系统的功能模块的示意图,包括:
第一保存模块401,用于将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中;
其中,挖掘系统是按照时间段获取第一日志数据集合的,例如,若时间段是15分钟或者是30分钟,则挖掘系统获取当前的15分钟时间段内的第一日志数据集合或者获取当前的30分钟时间段内第一日志数据集合。
其中,该时间段是获取数据的周期,可以按照数据量的大小确定该时间段的时长。
其中,Hadoop可实现分布式文件系统(Hadoop Distributed File System,HDFS),Hadoop的框架核心是Hadoop数据库及并行运算模型,其中,Hadoop数据库能够为海量的数据提供分布式存储,并行运行模型能够为海量的数据提供并行运算。
优选的,并行运算模型为mapreduce运算模型。
并行聚集模块402,用于若所述Hadoop数据库已保存的第一日志数据集 合的个数满足预先设置的数值,则利用预置的并行运算模型对所述Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合;
其中,在实际应用中可根据具体的需要预先设置该数值,例如,若上述的时间段为15分钟,且需要对一个小时内的第一日志数据集合进行聚集处理,则该预先设置的数值为4;若上述的时间段为30分钟,且需要对1天内的第一日志数据集合进行聚集处理,则该预先设置的数值为48。
可以理解的是,基于上述的聚集处理,并行聚集模块402还可以利用类似的方式得到不同时间周期内的日志数据集合,例如:可以利用4个时间段为15分钟的第一日志数据集合得到一个小时内的日志数据集合,可以利用24个一个小时内的日志数据集合得到一天内的日志数据集合,可以利用30个一天内的日志数据集合得到一个月内的日志数据集合,且以此类推,可以得到不同时间内的日志数据集合,以满足不同的需求。
划分保存模块403,根据所述第二日志数据集合中的日志数据的维度对所述第二日志数据集合中的日志数据进行维度划分,将得到的不同维度对应的第三日志数据集合保存至所述Hadoop数据库中。
其中,日志数据的维度有很多,包括但不限于上网内容、上网位置和上网时间,其中,上网内容是指在用户的浏览位置,该浏览位置可以是具体的某一个位置,例如可以是百度、搜狐、新浪微博等等,也可以是一类网址,例如:音乐、电影等等。上网位置是指用户使用的IP位置所处的地理位置范围,上网时间是指生成日志数据的时间。且维度的划分是根据系统的要求,通过维度上的数据完成对用户整体行为的进一步刻画。需要说明的是,对于不同类型的日志数据,其日志数据的维度也是不一样的,例如:在对日志数据中的用户的流量数据采用本发明实施例中的技术方案进行数据挖掘时,其维度除了上述的上网内容、上网位置和上网时间以外,还可以包含上网频率、用户年龄、月消费等等,因此在实际应用中,可以根据具体的需要进行维度划分,此处不做限定。
优选的,在本发明实施例中,挖掘系统在将不同维度对应的第三日志数据集合保存至Hadoop数据库中之后,还可以将该不同维度对应的第三日志数据集合保存至列存储阵列中,使得能够实现Hadoop数据库和列存储阵列的协同工作,使得能够满足不同的应用场景的数据需求。
在本发明实施例中,第一保存模块401将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中,若所述Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则并行聚集模块402利用预置的并行运算模型对所述Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合,最后划分保存模块403根据所述第二日志数据集合中的日志数据的维度对所述第二日志数据集合中的日志数据进行维度划分,将得到的不同维度对应的第三日志数据集合保存至所述Hadoop数据库中。
在本发明实施例中,挖掘系统将获取的当前时间段内的第一日志数据集合保存至Hadoop数据库中,若Hadoop数据库已保存的第一日志数据集合的个数满足预先设置的数值,则利用Hadoop数据库中的并行运算模型对该Hadoop数据库中的第一日志数据集合进行并行聚集处理,得到第二日志数据集合,根据该第二日志数据集合中的日志数据的维度对该第二日志数据集合中的日志数据进行维护划分,将得到的不同维度对应的第三日志数据集合保存至该Hadoop数据库中,以完成日志数据的挖掘。由于Hadoop数据库具有较好的分布式存储能力及并行运算能力,利用该Hadoop数据库对日志数据进行分布式存储及利用Hadoop中的并行运算模型进行并行运算,能够快速有效地实现海量数据的挖掘,满足对海量数据进行挖掘的存储及运算需求。
请参阅图5,为图4所示的第二实施例中追加的功能模块的示意图,包括:
获取模块501,用于从网络侧获取当前时间段内的日志数据;
在本发明实施例中,获取模块501是从网络侧获取当前时间段内的日志数据,具体的:获取模块501可以通过日志数据的抽取的方式从网络侧获取当前时间段内的日志数据,或者,可以利用网络爬虫技术从网络侧获取当前时间段内的日志数据,或者,可以通过从网络侧的BOSS营帐数据库中获取当前时间段内的日志数据,或者,可以接受网络侧的第三方厂商提供的当前时间段内的日志数据,或者结合上述的至少两种方式获取当前时间段内的日志数据。
第一聚集模块502,用于对所述当前时间段内的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
其中,第一聚集模块502可以是根据日志数据的内容进行分类,把相同 内容或者属于同一类的内容的日志数据作为一条数据进行数目上的累加,聚集后得到的第一日志数据集合的数量级将远远低于获取到的当前时间段内的日志数据的数量级,当时数据意义被完整的保存下来。
在本发明实施例中挖掘系统在执行第一聚集模块502之后才会开始执行图4所示实施例中的第一保存模块401。
在本发明实施例中,系统还包括清洗模块503;
清洗模块503用于在所述获取模块501获取所述当前时间段内的日志数据之后,对所述当前时间段内的日志数据进行数据清洗,得到当前时间段内清洗后的日志数据;
且若挖掘系统执行了清洗模块503,则第一聚集模块502具体用于对所述当前时间段内清洗后的日志数据进行聚集处理,得到所述当前时间段内的第一日志数据集合。
在本发明实施例中,挖掘系统通过图2所示的追加的步骤实现第一日志数据集合的获取,且通过对从网络侧获取到的当前时间段内的日志数据进行聚集,能够有效的降低日志数据的数量级,使得在Hadoop数据库中所所需要的存储空间减小,节约存储空间。且挖掘系统还可以通过对当前时间段内的日志数据进行数据清洗,使得能够除去一些无用或者出错的日志数据,降低日志数据处理的数量,且便于更好的进行数据挖掘。
请参阅图6,为图4所示的第二实施例追加的功能模块的示意图,包括:
读取模块601,用于若接收到数据查询指令,则按照所述数据查询指令中包含的查询维度从所述Hadoop数据库中读取与所述查询维度对应的第三日志数据集合;
分析模块602,用于对所述第三日志数据集合进行数据分析,并在显示界面上显示数据分析的结果。
其中,所述分析模块602包括:
聚类模块603,用于按照预先设置的聚类算法对所述第三日志数据集合中的用户进行用户分组,得到用户分组列表;
获取显示模块604,用于根据用户分组列表中的用户的日志数据得到至少两个用户维度对应的级别配置表,并在显示界面上显示所述级别配置表;所 述用户维度是预先设置的,所述级别配置表中包含所述用户分组列表中的用户按照所述用户维度进行分级确定的级别。
其中,用户维度可以分为横向维度和纵向维度,并且在不同的维度下对用户进行评级。例如:挖掘系统得到的用户分组,包括:所有用户组及微博用户组,对于所有用户组,对该组内的所有用户按照使用的流量大小进行名次排行,排名前20%的为五星级用户,排名前20%至40%的为四星级用户,并以此类推,确定该所有用户组中的每一个用户的星级。此即为横向维度评级。对于微博用户组合中的用户,按照用户启动微博之后产生的流量大小进行名次排行,排名前20%的为五星级用户,排名前20%至40%的为四星级用户,并以此类推,确定该微博用户组中的每一个用户的星级。此即为纵向维度评级。通过横向维度评级和纵向维度评级,使得能够对实现对用户群体的画像展示,以便业务专家针对具体的分组画像得到有针对性的方案。
优选的,该预先设置的聚类算法可以是K-means算法。
其中,查询维度是基于Hadoop数据库中保存的第三日志数据集合对应的维度设置的,例如:查询维度可以是上网内容、上网时间、上网位置等中的任意一种或者任意几种。
在本发明实施例中,挖掘系统通过按照数据查询指令中包含的查询维度从Hadoop数据库中读取与查询维度对应的第三日志数据集合,并对该第三日志数据集合进行数据分析,且在显示界面上显示数据分析的结果,使得能够有效的将数据挖掘的结果显示给用户。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间 接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!