产生实现被设计为更新根据应用数据模型指定的对象的规则的指令集的制作方法
本专利申请涉及以下共同未决申请,并且要求这些申请的优先权,这些申请全文并入本文:
A.以与本专利申请同一申请人的名义于2014年9月9日提交的印度专利申请No.4421/CHE/2014,标题为“Generating Instruction Sets Implementing Business Rules Designed To Update Business Objects Of Financial Applications”;以及
B.以与本专利申请同一申请人的名义于2015年1月13日提交的美国非临时专利申请No.14/595,223,标题为“Generating Instruction Sets Implementing Business Rules Designed To Update Business Objects Of Financial Applications”。
技术领域
本公开涉及企业应用服务器,并且更具体地涉及产生实现被设计为更新根据应用数据模型指定的对象的规则的指令集。
背景技术:
应用被用来处理数据并且提供对应的期望功能。金融应用是与金融工具(诸如信用卡、贷款、银行账户等)的管理有关的一类应用。如相关领域中众所周知的,金融应用在各种商业企业(诸如银行、保险公司、证券经纪业等)中得到使用。
应用经常是基于数据模型(“应用数据模型”)开发的,这些数据模型可以不同于根据其存储数据的数据模型。例如,数据可以根据关系数据库模型以表格的形式存储,而应用可以基于根据应用数据模型指定的对象(以下“数据对象”)而被开发。数据对象被定义为包含各种属性,数据对象的实例(“对象实例”)具有各个属性的对应值。
规则被用在应用中以更新根据应用数据模型指定的数据对象。规则处于概念层次,是可能对更接近于机器能够进行操作的层次(例如,编程语言、SQL查询等)的对应实现不熟悉的用户(例如,管理员、管理者、分析员、高级管理人员等)可理解的。
更新数据对象意味着改变数据对象的各个对象实例的一个或多个属性的对应值。作为简单的情况,银行可能具有如下规则:该规则根据客户的信用评级的不同水平(高风险、中等风险和低风险)以及贷款的类型(例如,住房、汽车、个人等)来更新利率。可以容易地理解,规则的执行引起多个对象实例的改变。复杂的规则典型地涉及几个更多的变量/维度、对多个属性的更新和/或对于被更新属性的值的复杂计算。
规则被转换为更适合于在机器上执行的等效指令集。例如,假定数据对象存储在管理数据库系统中,指令集包括指向关系数据库系统的表格的SQL(结构化查询语言)查询。
本公开的各方面针对的是产生这样的指令集:该指令集实现被设计为更新根据应用数据模型指定的对象的规则。
附图说明
参照下面简要描述的附图来描述本公开的示例实施例。
图1是例示了在其中可以实现本公开的几个方面的示例环境的框图。
图2是例示了根据本公开的一方面的产生实现被设计为更新根据应用数据模型指定的对象的规则的指令集的方式的流程图。
图3A例示了在一个实施例中为执行而指定规则的方式。
图3B例示了在一个实施例中根据本公开的几个方面对规则进行处理的方式。
图4A例示了在一个实施例中向用户显示被确定为适合合并的规则子集的方式。
图4B例示了在一个实施例中向用户显示合并规则子集的结果的方式。
图5是例示了在其中本公开的几个方面可通过执行适当的软件指令而操作的数字处理系统的细节的框图。
在附图中,相似的附图标记一般指示相同的、功能上类似的和/或结构上类似的要素。要素首次出现的附图由对应附图标记中的最左边的数字指示。
具体实施方式
1.概述
本公开的一个方面产生这样的指令集:该指令集实现被设计为更新根据应用数据模型指定的对象的规则。在一个实施例中,对被设计为更新对象的规则进行处理以形成(规则的)桶集以使每个桶包含在执行次序上不具有相互依赖性的规则。然后,对于每个桶,确定被设计为更新公共(数据)对象的规则子集,并且为每个确定的规则子集产生对应的单个指令集。然后,并行地执行为每个桶中包含的规则子集产生的指令集。
通过为更新公共对象的每个规则子集产生单个指令集(例如,最终被转译为单个SQL查询),可以减少这种公共对象为处理桶中的规则而需要的总持续时间。假定在此类更新期间将为对象提供排他性访问(例如,使用数据库中的表格/列的锁定),排他性访问的持续时间也相应地减少,由此降低与需要对对象进行排他性访问的其他应用对于同一对象的争用冲突的概率。另外,通过并行地执行与桶内的规则对应的指令集,至少当底层环境提供足够的多重处理能力时可以获得类似的效率。
根据本公开的另一个方面,发送桶中经确定的规则子集以供显示,同时指示这些规则子集中的每个规则子集可以被合并(也就是说,可以产生单个指令集)。如此,只有当从用户接收到指示每个规则子集要被合并的输入数据时,才执行与规则子集相对应的指令集的产生。
因此,(应用的)用户便于指示要被合并的特定子集(以及所产生的单个指令集)以及哪些子集将不被合并(也就是说,将产生用于每个规则的单独的指令集)。因此,如果(从用户接收的)输入数据指示规则子集中的特定规则将被排除合并,则为排除该特定规则的规则子集(也就是说,仅为该子集中的其他规则)产生对应的单个指令集。结果,可以向用户提供对规则合并的增强控制。
根据本公开的另一个方面,接收优先数据,该优先数据指示在每个规则的执行之前要被执行的对应规则集。因此,桶被形成为使得对应规则集不被包括在包含所述规则的同一个桶中(因为所述规则关于执行对所述对应规则集具有依赖性)。
根据本公开的又一个方面,根据应用数据模型指定的对象被存储在关系数据库服务器中。如此,每个规则如果被独立地执行,则将被实现为指向关系数据库服务器的对应SQL(结构化查询语言)命令。此外,对应的单个指令集是以指向关系数据库服务器的单个SQL命令的形式实现的。因此,与子集中的规则对应的待执行的不同SQL命令被单个SQL命令取代。
下面参照用于例示的例子来描述本公开的几个方面。然而,本领域技术人员将认识到,可以在没有一个或多个特定细节的情况下或者可以用其他方法、部件、材料等来实施本公开。在其他情况下,众所周知的结构、材料或操作未被详细展示,以免混淆本公开的特征。此外,所描述的特征/方面可以以各种组合实施,但是为简洁起见,在本文中仅描述这些组合中的一些组合。
2.示例环境
图1是例示了在其中可以实现本公开的几个方面的示例环境的框图。该框图被示为包含终端用户系统110A-110Z、互联网120、内联网130、服务器系统140A-140C、管理员系统150以及数据存储器180A-180B。
仅作例示,在该图中仅示出了代表性数量/类型的系统。许多环境经常根据该环境被设计的目的而包含数量和类型都更多的系统。下面更详细地描述图1的每个系统/装置。
内联网130表示在全都设于企业(用点线边界示出)内的服务器系统140A-140C、管理员系统150和数据存储器180A-180B之间提供连接的网络。互联网120扩展这些系统(以及企业的其他系统)与外部系统(诸如终端用户系统110A-110Z)的连接。内联网130和互联网120均可以使用相关领域中众所周知的协议(诸如传输控制协议(TCP)和/或互联网协议(IP))来实现。一般来说,在TCP/IP环境中,IP数据包用作基本传输单元,源地址被设置为向该数据包发源的源系统分配的IP地址,目的地地址被设置为该数据包最终被递送到的目的地系统的IP地址。
当数据包的目的地IP地址被设置为目的地系统的IP地址时,IP数据包被说成是指向(directed to)目的地系统,使得数据包通过网络120和130最终被递送到目的地系统。当数据包包含指定目的地应用的内容(诸如端口号)时,数据包也可以被说成是指向此类应用。目的地系统可以被要求使对应端口号保持可用/开放,并且通过对应的目的地端口对数据包进行处理。互联网120和内联网130均可以使用有线介质或无线介质的任何组合来实现。
数据存储器180A-180B均表示便于由在企业的其他系统(诸如服务器系统140A-140C和管理员系统150)中执行的企业应用存储和检索数据集合的非易失性(持久性)存储器。
数据存储器180A-180B均可以被实现为使用关系数据库技术的数据库服务器,并因此提供使用诸如SQL(结构化查询语言)之类的结构化查询的数据存储和检索。可替代地,如相关领域中众所周知的,数据存储器180A-180B均可以被实现为文件服务器,该文件服务器提供被组织为一个或多个目录的文件的形式的数据的存储和检索。
在一个实施例中,如上面在背景部分中所指出的,数据存储器180A-180B中维护的数据根据包含数据对象、属性和对象实例的应用数据模型(在数据存储器外部提供)被提供访问权。当被存储在关系数据库系统中时,数据对象可以对应于一个或多个表格,每个属性对应于此类表格的相应列,每个对象实例对应于此类表格的行。当被存储在文件服务器中时,每个数据对象可以对应于一个或多个文件,每个对象实例由文件中的一组行表示,每行又指定属性和对应的值。
终端用户系统110A-110Z均表示被用户用来产生并行送指向企业的特定系统的用户请求的系统,诸如个人计算机、工作站、移动站、移动电话、计算平板等。用户请求可以使用适当的用户界面(例如,由在企业中执行的应用提供的网页)来产生。例如,用户可以将用于执行各种任务的用户请求发送给在服务器系统140A-140C中执行的企业应用。
服务器系统140A-140C均表示执行企业应用(例如,金融应用、分析框架等)的服务器,诸如web/应用服务器,其中企业应用能够执行用户使用终端用户系统110A-110Z请求的任务。响应于从终端用户系统接收到请求,每个服务器系统执行请求中指定的任务,并且将任务的执行结果发送到发起请求的终端用户系统。每个服务器系统可以使用内部存储(例如,存储在服务器内的非易失性存储器/硬盘中)的数据、外部数据(例如,数据存储器180A-180B中维护的数据)和/或在执行此类任务时从外部源(例如,从用户)接收的数据。
管理员系统150表示便于用户管理(创建、更新、删除)由在服务器系统140A-140C中执行的不同企业应用访问的对应数据的服务器,诸如web/应用服务器。在一个实施例中,在管理员系统150中指定的分析框架便于用户指定用于更新根据应用数据模型指定的对象的规则,该框架然后将这些规则转换为适合于数据存储器180A-180B的实现的对应指令集(例如,SQL查询)。此类分析框架的例子是从Oracle Corporation可购得的Oracle金融服务分析应用(OFSAA),Oracle Corporation是本申请的预定受让人。
在一种现有方法中,分析框架将每个规则转换为对应的指令集(也就是说,指令集的数量等于规则的数量)。因此,期望的是,为给定的规则集产生最佳数量(更少)的指令集。如下面通过例子描述的,根据本公开的几个方面扩展的管理员系统150促进实现被设计为更新根据应用数据模型指定的对象的规则的此类最佳指令集的产生。
3.产生实现规则的指令集
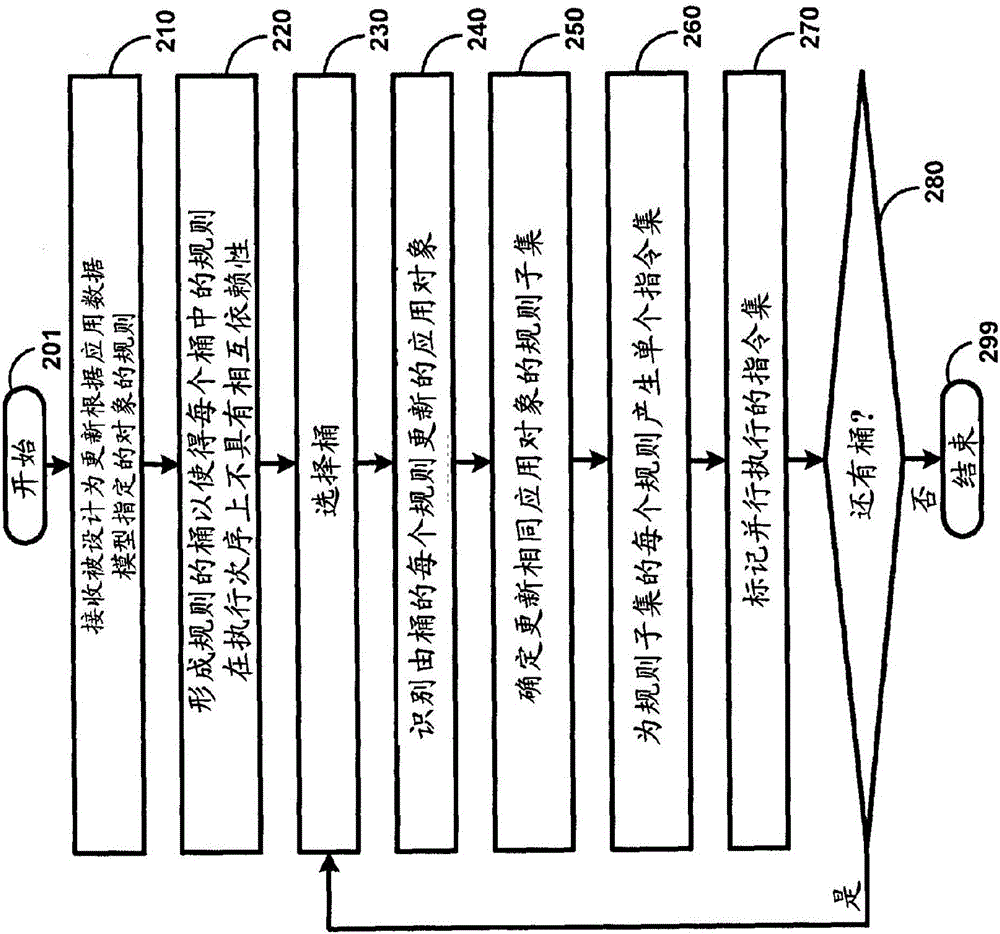
图2是例示了根据本公开的一个方面的产生实现被设计为更新根据应用数据模型指定的对象的规则的指令集的方式的流程图。仅作例示,针对图1特别是管理员系统150来描述该流程图。然而,如相关领域的技术人员通过阅读在此提供的公开内容将明白的,许多特征也可以在其他环境中(并且可能使用其他类型的系统/服务器)实现,而不脱离本公开的几个方面的范围和精神。
另外,如相关领域的技术人员将明白的,所述步骤中的一些步骤可以按与下面描绘的顺序不同的顺序执行,以适合特定环境。此类实现中的许多实现意在被本公开的几个方面所涵盖。该流程图从步骤201开始,在步骤201中,控制立即转到步骤210。
在步骤210中,管理员系统150接收被设计为更新根据应用数据模型指定的数据对象的规则。因此,每个规则包含运算符和运算数,运算数中的至少一个是数据对象或对应的属性。规则可以通过使用终端用户系统110A-110Z之一从用户接收。
在步骤220中,管理员系统150形成规则的桶以使得每个桶中的规则在执行次序上不具有相互依赖性。如果在执行次序上,在后的规则的执行被要求仅在在前的规则的执行结束之后开始,则可以说存在相互依赖性。在没有此类相互依赖性时,两个规则都可以并行执行。
在下面描述的实施例中,用户指定优先数据/排序(即,为了执行给定规则哪些在前的规则必须完成的手动指示),但是此类或其他依赖性可以通过检查对每个规则指定的输入和输出来推断。在此类情形下,管理员系统150确保在前的规则不被包括在包含所述给定规则的桶中。
在步骤230中,管理员系统150从在步骤220形成的一个或多个桶中选择桶。具体地说,选择其规则尚未被处理(按照下述步骤240至270)的桶。此类未被处理的桶的选择可以以已知的方式执行。例如,每个桶可以与指示对应的桶是已经被处理(第一值)、还是尚未被处理(第二值)的标志相关联。因此,管理员系统150可以选择其标志被设置为第二值的桶。
在步骤240中,管理员系统150识别由所选择的桶中的每个规则更新的数据对象(以及对应的属性)。可以通过检查由分析框架维护的元数据来确定对被更新的数据对象的识别。
在步骤250中,管理员系统150确定更新相同数据对象的规则子集。换句话说,桶中更新相同数据对象的规则被包括在同一个子集中。在实施例中,所确定的规则子集被发送以供显示在(与终端用户系统110A-110Z之一相关联的)显示单元上,同时指示每个规则子集均可以被合并(也就是说,可以产生单个指令集)。用户被使得能够选择要被合并的特定子集和/或每个子集中的特定规则。假定从用户接收到指示所有规则子集要被合并的输入数据,继续进行描述。
在步骤260中,管理员系统150为每个规则子集产生单个指令集。为子集产生的单个指令集被设计为执行(与子集相对应的)数据对象的属性的值的更新(由子集中的规则确定)。在实施例中,单个指令集被形成为单个SQL声明,例如,具有用于更新的多个列的“MERGE”声明。
在步骤270中,管理员系统150标记用于并行执行的(为不同规则子集产生的)不同指令集。换句话说,如果在步骤250中形成四个规则子集,则对应的四个指令集可以被并行地执行。
在步骤280中,管理员系统150检查是否还存在要处理的桶(即,其标志被设置为第二值的桶)。在此类检查之前,管理员系统150首先将与所选择的桶相关联的标志设置为第一值以指示所选择的桶已经被处理。如果还有桶,则控制转到步骤230,在步骤230中选择新的(尚未被处理的)桶,否则转到步骤299(在所有桶都已经被处理之后)。流程图在步骤299中结束。
因此,通过识别给定规则集中的哪些规则可以被组合为单个指令集,可以为被设计为更新数据对象的给定规则集产生最佳的指令集。此外,通过使得用户(诸如在高概念层次上进行操作的管理者)能够选择要被合并的特定规则,可以领会到规则的选择可以基于商业/金融考虑、而非基于数据对象的底层实现来执行。
下面通过例子来例示管理员系统150可以根据图2来执行指令集的产生的方式。
4.说明性例子
图3A-3B和图4A-4B共同例示了在一个实施例中产生实现被设计为更新根据应用模型指定的对象的规则的指令集的方式。下面详细地描述这些图中的每个图。
图3A例示了在一个实施例中指定用于执行的规则的方式。作为例示,规则被示为以表格(具有行和列)的形式指定。然而,在替代性实施例中,规则可以以任何方便的方式、使用适当的用户界面指定。标题为“SIMPLIFYING GROUPING OF DATA ITEMS STORED IN A DATABASE”的美国专利No.8856126中详细描述了用于指定规则的用户界面的例子。
因此,表310描绘了用户使用终端用户系统110A-110Z之一在分析框架中指定的(被设计为更新数据对象的)规则集。列311(“规则Id”)指定规则的唯一标识符(诸如R1、R2等),列312(“层级/域”)指定用作规则的输入的对应的值集(被命名为H1、H2等),列313(“量度/范围”)指定由规则更新的(各种数据对象的)属性,诸如M1、M2等。
每个层级/域表示可以在数据对象的属性中存储的对应的潜在值集。潜在值以本领域中众所周知的树数据结构的形式组织。每个量度表示将被用执行相关联的一组计算的结果更新的对应的一个或多个属性(数据对象中的属性)。当数据对象被存储在关系数据库系统中时,每个层级表示可以在数据库系统的列中存储的潜在值,而每个量度表示数据库系统中的(表格的)列。
表310的每行指定要用于更新企业应用的数据对象的对应规则。一般来说,每个规则为层级/域的值的组合(列312中的输入)指定对应的计算,该计算所得的值将被存储在量度/范围(列313)中。例如,行318指示由名称“R3”唯一地标识的规则为层级H4和H5中的值的各种组合指定对应的计算,该计算所得的值被更新在量度M4中。类似地,其他行指定对应规则的细节。
表格320描绘了分析框架中典型地由分析框架的开发者/管理员指定的一组量度。列321(“量度Id”)指定量度的唯一标识符(诸如M1、M2等),而列322(“对象”)和323(“属性”)指定量度所表示的对应的数据对象和属性。
表320的每行指定可以被分析框架中指定的规则更新的对应量度。例如,行328指示量度M4(其由行318指定的规则R3更新)对应于数据对象B1中所包含的属性A5和A6。类似地,其他行指定分析框架中所使用的对应量度的细节。
表330描绘了被定义为分析框架中的运行定义(run definition)的一部分的一组过程。运行定义表示以(按顺序次序执行的)过程/步骤的序列的形式指定的应用过程流程。用户可以将由分析框架提供的一个或多个组件(诸如规则)指示为运行定义中的过程。在下面的描述中,假定运行定义的各种过程仅指示规则。
因此,表330描绘了用户使用终端用户系统110A-110Z之一在分析框架中指定的一组过程步骤。列331(“过程Id”)指定过程的用于过程步骤的标识符(诸如P1、P2等)。应注意,相同的过程标识符可以在多行中重复以指示所述多行中指定的对应的过程步骤是同一个过程的一部分。列332(“规则Id”)指定要作为过程步骤被执行的规则的标识符,列333(“优先”)指示哪些在前的规则必须完成以便执行对应的过程步骤中指定的规则。没有在前的规则(由符号“-”指示)暗示规则(诸如R1、R2、R3)可以并行执行。
表330中的每行指定过程的序列(P1、P2),每个过程被指示执行对应的规则集。例如,过程P1(基于列331中的相同标识符P1)被指示执行作为对应的过程步骤的规则R1、R2、R4、R6、R3、R5和R9。规则中的一些(在列333中)被示为对在前的规则具有相互依赖性,这暗示规则的执行仅在一个或多个在前的规则的执行完成之后才开始。例如,行338指示规则R4对规则R2具有相互依赖性以暗示规则R4的执行仅在规则R2的执行完成之后才可以开始。
可以领会到,上面所指出的序列和优先实施规则之间的执行次序。在此公开中假定,用户对可以引起相互依赖性的各种条件进行检查,并且指定与规则之间存在的条件相符的序列。例如,用户可以检查两个规则是否更新被映射到同一数据对象中的同一属性的量度,并且相应地指定在这两个规则之间存在相互依赖性。在替代性实施例中,执行次序上的此类相互依赖性可以由管理员系统150通过检验每个规则更新的各种量度来确定。
因此,用户被使得能够指定与根据应用数据模型指定的对象的属性相对应的期望量度、用于更新量度(以及对应地,数据对象的属性)的规则以及运行定义,该运行定义指定将根据期望的执行次序执行的规则的序列。下面通过例子描述可以由管理员系统150处理用户指定的规则以产生最佳指令集的方式。
5.处理规则
图3B例示了在一个实施例中对规则进行处理的方式。具体地说,图3A中为过程P1指定的规则的处理在图3B中被示出,并且在下面被更详细地描述。
管理员系统150响应于接收到表330的运行定义,首先形成用于过程P1的规则的桶以使每个桶中的规则在执行次序上不具有相互依赖性。一般来说,不具有列333的优先数据中指示的在前的规则(由符号“-”)的规则被分组到公共桶中。具有优先数据中指示的在前的规则的任何规则然后基于在前的规则所属的桶被分组到其他桶中。特别地,在前的规则与被分组的所述规则不被包括在相同的桶中。
表340指定为所接收的运行定义(表330)的过程P1中的规则形成的桶集。每个桶(诸如#1、#2)被示为包含对应的规则组/集(诸如{R1,R2,R3,R9}和{R4,R5,R6})。可以注意到,桶#1由不具有优先规则(由表330中的“-”指示)的规则形成。其他规则R4、R5和R6被示为被分组到桶#2中,因为所有的规则都具有属于同一个桶#1的对应优先规则。
管理员系统150之后可以对规则的每个桶进行处理。表350和355共同例示了对桶#1中的规则进行处理的方式,而表360和365共同例示了对桶#2中的规则进行处理的方式。下面详细地描述对桶#1中的规则进行处理的方式。
管理员系统150首先识别由桶#1中的每个规则更新的数据对象(和属性)。可以通过如下方式来执行识别,即,首先基于表310来识别由每个规则更新的量度,之后基于表320来确定与经更新的量度相对应的特定属性/数据对象。表350描绘了管理员系统150为桶#1(即,[R1,R2,R3,R9])中的规则识别的数据对象(B1和B2)以及对应的属性(诸如A1、A2等)。
管理员系统150然后确定更新相同数据对象的规则子集。表355指示为桶#1确定的各种规则子集。可以观察到,规则R1、R3和R9被示为包括在第一子集中,因为所有这些规则都更新相同的数据对象B1,而规则R2被示为包括在第二子集中,因为规则R2更新不同的数据对象B2。
管理员系统150然后产生用于规则{R1,R3,R9}的单个指令集以及用于规则{R2}的另一个指令集。类似地,管理员系统150对桶#2(即,{R4,R5,R6})中的规则进行处理(如表360和365所示那样),并且为子集{R4,R6}和{R5}产生各自的指令集。可以观察到,只产生了与为过程P1确定的四个规则子集相对应的4个指令集。这与在上面指出的现有方法中将会产生的(与过程P1中的七个规则相对应的)7个指令集形成对比。
表380例示了作为运行定义的一部分将所确定的规则子集提供给用户的方式。表380类似于表330,因此为了简洁起见,这里不重复对共同要素的描述。可以观察到,每个规则子集被示为运行定义中的对应过程(P1、P2)下的子过程(诸如S11、S12、S21等)。每个子过程被示为包含被管理员系统150确定在子集中的各种规则。例如,子过程S11对应于管理员系统150为桶#1确定(如表355所示那样)的规则子集{R1,R3,R9}。
在一个实施例中,管理员系统150为作为子过程的一部分而指定的各种规则产生单个指令集。因此,所确定的要被合并的规则子集被示为表380中的对应子过程。然而,在替代性实施例中,子过程可以仅用于子集的视觉表示。管理员系统150然后可以存储指示属于各种子集的规则的附加数据(例如,指示子集的编号),并且相应地基于该附加数据来产生单个的指令集。
根据本公开的一个方面,例如在与终端用户系统110A-110Z之一相关联的显示单元(图1中未示出)上向用户显示所确定的规则子集。规则子集的合并(单个指令集的产生)仅响应于指示要执行(对应子集的)此类合并的(从用户接收的)输入数据而执行。下面通过例子来描述管理员系统150可以显示所确定的子集并且(使用终端用户系统110A-110Z)从用户接收输入数据的方式。
6.显示用于合并的规则
图4A例示了在一个实施例中向用户显示被确定为适合于合并的规则子集的方式。虽然本文中的示例环境对应于银行/金融应用,但是在此描述的特征可以应用于利用类似架构的其他环境。
显示区域400描绘了在与终端用户系统110A-110Z之一相关联的显示单元(图1中未示出)上提供的用户界面的一部分。在一个实施例中,显示区域400对应于显示由管理员系统150提供的各个网页的浏览器。网页响应于用户使用终端用户系统110A中的浏览器(例如,通过指定对应的URL)发送适当的请求而被提供。
特别地,显示区域400的用户界面便于用户/管理者查看(和编辑)过程/运行定义的细节。显示区域410提供过程定义的细节,诸如名称、类型、版本等。显示区域420描绘了作为过程定义的一部分而指定的过程步骤的层级。特别地,显示区域420指示过程包含被命名为“Non-Sec Pre-Migration RWA-EL”和“Non-Sec Pre-Migration RWA-UL”的两个步骤。
显示区域430指定过程定义中指定的每个过程步骤的细节。特别地,显示区域430指示每个对象/过程步骤的唯一标识符(与显示区域420中相同)、对象的优先(其指示哪些在前的步骤/对象/规则要在对应步骤的执行之前被执行)以及对象的类型。可以观察到,对象/过程步骤这两者的对象类型被指示为计算规则。
可以进一步观察到,两个对象都被示为(通过对应复选框的选择)被选择指示两个对象/规则的子集可以被合并(并且产生单个指令集)。应注意到,在替代性实施例中,任何适当的视觉突显(诸如相同颜色、字体等的使用)可以用于指示可以被合并的特定规则子集。例如,不能被合并的所有规则都可以用共同的颜色显示,而每个规则子集可以用对应的唯一颜色(不同于共同颜色)显示。
因此,用户被使得能够通过使用显示区域400的用户界面指示将合并的特定子集。例如,用户可以排除子集中的规则(通过移除对应复选框中的选择)。另外,用户可以(基于子集的指示/视觉突显)观察到,鉴于特定规则不更新由子集中的其他规则更新的公共数据对象,该特定规则不被包括在该规则子集中。用户因此可以修改该特定规则以形成(更新公共数据对象的)经修改的规则,然后执行子集的确定以使经修改的规则被包括在子集中(并且显示在显示区域430中)。
在用户已经选择要被合并的子集之后,用户点击/选择“合并规则”链接/按钮450以指示所选择的规则子集(这里为“Non-Sec Pre-Migration RWA-EL”和“Non-Sec Pre-Migration RWA-UL”)将被合并。作为响应,管理员系统150创建与被指示要被合并的每个规则子集相对应的子过程(通过在显示区域430中从用户接收的输入数据)。管理员系统150然后可以如下面详细描述的那样向用户显示所创建的子过程。
图4B例示了在一个实施例中向用户显示合并规则子集的结果的方式。具体地说,图4B描绘了响应于用户点击图4A中的“合并规则”链接450的结果。
显示区域470描绘了在合并对应的规则子集之后的过程步骤的层级。可以观察到,显示区域470指示已经创建了被命名为“Merge Exe Sub Process”的新过程步骤,而前面的两个步骤“Non-Sec Pre-Migration RWA-EL”和“Non-Sec Pre-Migration RWA-UL”被显示在该新过程步骤之下。显示区域480指示新过程步骤“Merge Exe Sub Process”是子过程(由类型指示)。
因此,合并规则子集的结果以过程定义的各种子过程的形式被显示给用户。用户然后可以点击/选择“保存”按钮490以指示包括要被合并的各种规则子集的过程定义将被保存/存储作为过程定义的一部分。响应于执行(图4B的)保存的过程/运行定义,管理员系统150为过程步骤“Merge Exe Sub Process”产生单个指令集,并然后(与其他单个指令集并行地)执行该单个指令集,以使得特定量度基于对应计算而被更新。
在一个实施例中,企业应用所使用的数据对象被存储在关系数据库服务器中。因此,每个规则如果被独立地执行,则被实现为针对关系数据库服务器的对应的SQL(结构化查询语言)命令。附录A描绘了如果规则“Non-Sec Pre-Migration RWA-EL”被独立地执行则可以由管理员系统150产生并执行的SQL命令。附录B描绘了可以为规则“Non-Sec Pre-Migration RWA-UL”产生的SQL命令。单个指令集在执行时也以针对关系数据库服务器的单个SQL命令的形式被实现。附录C描绘了可以作为用于经合并的规则子集/子过程“Merged Exe Sub Process”的单个指令集而产生的SQL命令。SQL命令然后被执行,同时可能实现上面在概述部分中指出的功效中的一个或多个。
应进一步领会到,上面描述的特征可以在各种实施例中被实现为硬件、可执行模块和固件中的一个或多个的期望组合。关于当可执行模块中的指令被执行时各种特征可操作的实施例,继续进行描述。
7.数字处理系统
图5是例示了其中本公开的几个方面通过执行适当的软件指令而操作的数字处理系统500的细节的框图。数字处理系统500对应于管理员系统150。
数字处理系统500可以包含一个或多个处理器(诸如中央处理单元(CPU)510)、随机存取存储器(RAM)520、二级存储器530、图形控制器560、显示单元570、网络接口580以及输入接口590。除显示单元570外的所有组件都可以通过通信路径550相互通信,通信路径550可以包含相关领域中众所周知的若干总线。下面更详细地描述图5的组件。
CPU 510可以执行在RAM 520中存储的指令以提供本公开的几个特征。CPU 510可以包含多个处理单元,每个处理单元可能被设计用于特定任务。可替代地,CPU 510可以仅包含单个通用处理单元。RAM 520可以使用通信路径550从二级存储器530检索指令。
RAM 520被示为当前包含构成共享环境525和/或用户程序526(诸如金融应用、分析框架等)的软件指令。共享环境525包含用户程序共享的实用程序,并且此类共享实用程序包括提供用于执行用户程序526的(公共)运行时环境的操作系统、设备驱动器、虚拟机、流程引擎等。
图形控制器560基于从CPU 510接收的数据/指令来产生给显示单元570的显示信号(例如,RGB格式的显示信号)。显示单元570包含用于显示由显示信号定义的图像(诸如图4A-4B的用户界面的部分)的显示屏幕。输入接口590可以对应于可用于提供各种输入(诸如在图4A-4B的用户界面中指定期望的输入等)的键盘和定点装置(例如,触控板、鼠标)。网络接口580提供与网络的连接(例如,通过使用互联网协议),并且可以用于与其他连接的系统(诸如服务器系统130A-130C、数据存储器180A-180B)通信。
二级存储器530可以包含硬盘驱动器535、闪存536以及可移动存储驱动器537。二级存储器530表示可以存储数据(例如,图3A-3B所示的数据的部分)和软件指令(例如,用于执行图2的步骤的软件指令)以使得数字处理系统500能够提供根据本公开的几个特征的非暂时性介质。二级存储器530中存储的代码/指令要么可以在被CPU510执行之前被拷贝到RAM 520以使执行速度更高,要么可以直接被CPU 510执行。
二级存储器530可以包含硬盘驱动器535、闪存536以及可移动存储驱动器537。数据和指令中的一些或全部可以被提供在可移动存储单元540上,并且数据和指令可以被可移动存储驱动器537读取并且提供给CPU 510。可移动存储单元540可以使用与可移动存储驱动器537兼容的介质和存储格式来实现,以使得可移动存储驱动器537可以读取数据和指令。因此,可移动存储单元540包括存储有计算机软件和/或数据的计算机可读(存储)介质。然而,该计算机(或一般地,机器)可读介质可以为其他形式(例如,不可移动、随机存取等)。
在本文件中,术语“计算机程序产品”一般用来指可移动存储单元540或安装在硬盘驱动器535中的硬盘。这些计算机程序产品是用于向数字处理系统500提供软件的装置。CPU 510可以检索软件指令,并且执行指令以提供上面描述的本公开的各种特征。
在此所使用的术语“存储介质”是指存储使机器以特定方式操作的数据和/或指令的任何非暂时性介质。此类存储介质可以包括非易失性介质和/或易失性介质。非易失性介质包括例如光盘、磁盘或固态驱动器,诸如存储存储器530。易失性介质包括动态存储器,诸如RAM520。常见形式的存储介质包括例如软盘、柔性盘、硬盘、固态驱动器、磁带或任何其他磁性数据存储介质、CD-ROM、任何其他光学数据存储介质、具有孔图案的任何物理介质、RAM、PROM和EPROM、FLASH-EPROM、NVRAM、任何其他存储器芯片或盒。
存储介质不同于传输介质,但是可以与传输介质结合使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴电缆、铜线和光纤,包括构成总线550的导线。传输介质还可以采取声波或光波的形式,诸如无线电波和红外数据通信期间产生的那些。
贯穿本说明书,所引用的“一个实施例”、“实施例”或类似语言意味着与该实施例相关联地描述的特定的特征、结构或特性被包括在本公开的至少一个实施例中。因此,贯穿本说明书,短语“在一个实施例中”、“在实施例中”和类似语言的出现可以全都指同一个实施例,但不一定是全都指同一个实施例。
此外,本公开所描述的特征、结构或特性可以在一个或多个实施例中以任何合适的方式组合。在上面的描述中,为了提供对本公开的实施例的透彻理解,提供了许多具体的细节,诸如编程的示例、软件模块、用户选择、网络事务、数据库查询、数据库结构、硬件模块、硬件电路、硬件芯片等。
8.结论
虽然上面已经描述了本公开的各种实施例,但是应理解,它们仅仅是作为例子呈现的,而非限制。因此,本公开的广度和范围不应受上述任一示例性实施例的限制,而是应仅根据权利要求及其等同来限定。
应理解,在附件中例示的突出本公开的功能和优点的附图和/或抓屏仅是出于举例的目的呈现的。本公开是足够灵活的且可配置的,使得它可以以除附图所示的方式之外的方式利用。
此外,摘要的目的使得专利局和公众、尤其是本领域中不熟悉专利或法律用语或措辞的科学家、工程师和从业者能够快速地通过粗略的审视来确定本申请的技术公开内容的性质和本质。摘要不意在以任何方式限制本公开的范围。
附录A
为Non-Sec Pre-Migration RWA-EL产生的SQL
附录B
为Non-Sec Pre-Migration RWA-UL产生的SQL
附录C
为Merged Exe Sub Process产生的SQL
- 还没有人留言评论。精彩留言会获得点赞!