一种建立数据识别模型的方法及装置与流程
本发明属于数据处理技术领域,尤其涉及一种建立数据识别模型的方法及装置。
背景技术:
商家的信用是消费者决定是否消费的重要指标,目前网上电商平台也是按照商家的信用高低进行排名。商家的信用根据交易的数量和评分逐步累积,刚开的店铺没有信用,排名就会靠后。消费者出于对自身权益的考虑,更愿意选择信用较高的商家或者销量较高的商品。而商家排名的先后直接关系到消费者是否能够搜索到商家,搜索不到的情况下,消费者就无法进入商家的店铺进行消费。
因此网上商家都有提升信用的需求,催生了一些专为商家提升信用的网站和个人,通过刷单等虚假交易行为来提升商家的信用。虚假交易行为不利于市场的健康发展,不利于保护消费者的权益,属于电商平台需要严厉打击的行为。
电商平台例如小微金服花呗和信贷业务,在使用时都要利用训练得到的识别模型来识别交易是否是虚假交易。通常在业务上通过top抓坏率来衡量对虚假交易的识别是否准确,所谓抓坏率也称为召回率,是指识别出的虚假交易占虚假交易总数的比率。top抓坏率是用于对训练得到的模型进行评估的指标,按模型识别得到的虚假交易概率对交易记录进行排序,然后对排序后的交易记录进行分组,计算各组的抓坏率,如果top抓坏率保持稳定且能达到设定的标准,则判断模型可靠,可用于后续的识别。
然而目前小微金服等电商平台在训练识别模型时,一般是先对训练样本通过特征工程处理后,经过逻辑回归算法训练得到识别模型,然后采用测试样本来计算抓坏率,根据抓坏率来判断训练得到的识别模型是否可靠。
但是现在训练得到的识别模型是使用逻辑回归模型,对于训练样本按比例采样,没有对正样本进行区分,导致噪音进入逻辑回归算法,无法有效提高top抓坏率和保证稳定性。并且随着虚假交易维度越来越多,线性模型已经无法学到更多维度的信息,模型单一,效果受限。
技术实现要素:
本发明的目的是提供一种建立数据识别模型的方法及装置,以解决现有技术逻辑回归模型训练时噪音的影响,以及模型单一、效果不理想等问题。结合机器学习和深度学习进行训练,在判断虚假交易时,有效提高top抓坏率,取得很好的效果。
为了实现上述目的,本发明技术方案如下:
一种建立数据识别模型的方法,用于根据包括正、负样本的训练样本建立数据识别模型,所述建立数据识别模型的方法包括:
采用训练样本进行逻辑回归训练,得到第一模型;
对训练样本按比例采样,获得第一训练样本集;
采用训练得到的第一模型对正样本进行识别,从第一模型识别后具有识别结果的正样本中选择出第二训练样本集;
采用采样后得到的第一训练样本集与所述第二训练样本集进行深度神经网络dnn训练,得到最终的数据识别模型。
进一步地,所述建立数据识别模型的方法,在进行按比例采样或进行逻辑回归训练前,还包括:
对训练样本进行特征工程预处理。
进一步地,所述建立数据识别模型的方法,在采用训练样本进行逻辑回归训练之前,还包括:
对训练样本进行特征筛选,所述特征筛选通过计算特征的信息值,去除信息值小于设定阈值的特征。
优选地,所述从第一模型识别后具有识别结果的正样本中选择出第二训练样本集之前,还包括:
采用第一训练样本集进行dnn训练,得到第二模型。
进一步地,所述从第一模型识别后具有识别结果的正样本中选择出第二训练样本集,包括:
对训练得到的第一模型进行评估,得到第一模型对应的roc曲线;
对训练得到的第二模型进行评估,得到第二模型对应的roc曲线;
根据第一模型与第二模型roc曲线的交点对应的阈值概率,从第一模型识别后具有识别结果的正样本中选择出概率小于所述阈值概率的样本作为第二训练样本集。
本发明优选地选择第二训练样本集的方法能够选择出更加符合训练要求的样本,提高最终数据识别模型的稳定性。
本发明还提出了一种建立数据识别模型的装置,用于根据包括正、负样本的训练样本建立数据识别模型,所述装置包括:
第一训练模块,用于采用训练样本进行逻辑回归训练,得到第一模型;
采样模块,用于对训练样本按比例采样,获得第一训练样本集;
选择模块,用于采用训练得到的第一模型对正样本进行识别,从第一模型识别后具有识别结果的正样本中选择出第二训练样本集;
最终模型训练模块,用于采用采样后得到的第一训练样本集与所述第二训练样本集进行深度神经网络dnn训练,得到最终的数据识别模型。
进一步地,所述装置还包括:
预处理模块,用于在进行按比例采样或进行逻辑回归训练前,对训练样本进行特征工程预处理。
进一步地,所述装置还包括:
特征筛选模块,用于在采用训练样本进行逻辑回归训练之前,对训练样本进行特征筛选,所述特征筛选通过计算特征的信息值,去除信息值小于设定阈值的特征。
优选地,本发明所述装置还包括:
第二训练模块,用于采用第一训练样本集进行dnn训练,得到第二模型。
进一步地,所述选择模块从第一模型识别后具有识别结果的正样本中选择出第二训练样本集时,执行如下操作:
对训练得到的第一模型进行评估,得到第一模型对应的roc曲线;
对训练得到的第二模型进行评估,得到第二模型对应的roc曲线;
根据第一模型与第二模型roc曲线的交点对应的阈值概率,从第一模型识别后具有识别结果的正样本中选择出概率小于所述阈值概率的样本作为第二训练样本集。
本发明提出的一种建立数据识别模型的方法及装置,通过对全部训练样本进行特征工程预处理以及特征筛选,并根据逻辑回归训练得到的第一模型识别结果和采用第一训练样本集进行dnn训练的结果,从具有识别结果的所有正样本中选择出第二训练样本集,来结合深度神经网络训练得到最终的数据识别模型,提高了模型的稳定性。
附图说明
图1为本发明建立数据识别模型的方法流程图;
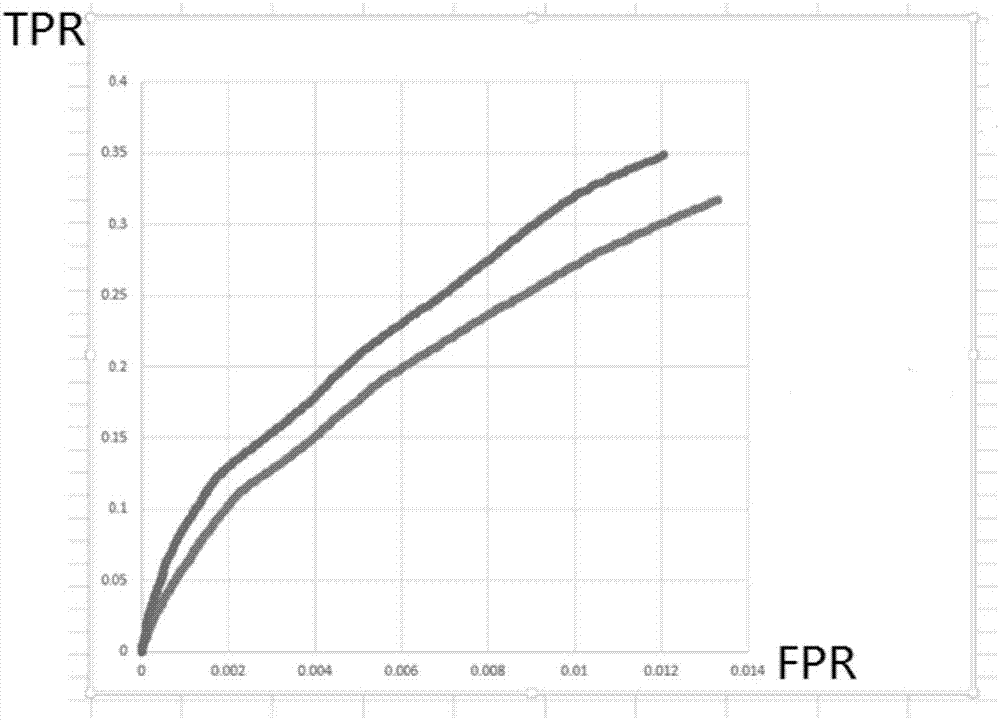
图2为本发明数据识别模型评估效果对照图;
图3为本发明建立数据识别模型的装置结构示意图。
具体实施方式
下面结合附图和实施例对本发明技术方案做进一步详细说明,以下实施例不构成对本发明的限定。
如图1所示,本实施例一种建立数据识别模型的方法,包括:
步骤s1、对训练样本进行特征工程预处理。
对于获取的全部训练样本,由于样本中的特征有些值缺失,或者偏差超出正常的范围,会影响到后续的训练,通常需要对样本进行特征工程处理。本实施例首先对样本进行特征工程预处理,即对样本的特征进行数据替换和清洗,剔除无意义特征。例如对样本中缺失的特征进行数据替换等。
步骤s2、对预处理后的训练样本进行特征筛选,采用特征筛选后的训练样本进行逻辑回归训练,采用训练得到的第一模型对正样本进行识别。
全部训练样本中包括正样本和负样本,本实施例以虚假交易为例来进行说明,正样本表示是虚假交易的样本,负样本表示不是虚假交易的样本。
在模型识别中,因为有些特征与最终识别结果关系不大,若把这些特征作为变量会使得模型识别结果变差,或一般情况下应使特征数大大小于样本数,所以有必要采用特征筛选来筛选掉不重要甚至有负作用的特征。进行特征筛选的方法很多,例如有最近邻算法、偏最小二乘法等。本实施例优选地通过采用信息值iv(informationvalue)来对样本的特征进行筛选。通过计算样本每个特征对应的信息值,将特征对应的信息值小于设定阈值的样本特征去除,减少其对样本分布的影响。
本实施例计算样本特征对应的信息值是根据所有训练样本的特征来计算,假设一条训练样本的特征包括{feature1、feature2、…、featurem},对于其中的一个特征featurei,i属于(1~m),m为特征数量。所有训练样本对应该featurei的值为{i1,i2,…,in},n为训练样本总数。
则可以根据featurei的值进行分组,例如将featurei的值为a的划分为一组,这样将fenturei分为k组,根据如下公式计算特征featurei的信息值iv:
其中,disgoodki为样本组中负样本数量,disbadki为样本组中正样本数量。本实施例不限定哪个为负样本数量,哪个为正样本数量,即也可以用disgoodki表示正样本数量,disbadki表示负样本数量。从而可以根据特征对应的信息值来筛选特征,将对应信息值小于设定阈值的特征舍弃,保留对结果有影响的特征用来进行后续的训练,提高训练模型的可靠性。
在进行特征筛选后,采用特征筛选后的全部训练样本进行逻辑回归训练得到第一模型,该模型即为现有技术方案中采用的识别模型。本发明在此基础上进一步训练以得到更加可靠的模型。一般来说采用特征筛选后的全部训练样本进行逻辑回归训练得到第一模型稳定性比较好,可以选择其中的一些样本来进行后续的训练,以使得后续训练得到的模型具有较好的稳定性。衡量模型稳定性一般采用top抓坏率指标,top抓坏率可以根 据模型识别样本得到的虚假交易概率来进行计算。
为此,本实施例采用训练得到的第一模型对所有正样本进行识别,得到每个训练样本对应的为虚假交易的概率,记所有正样本及其识别得到的概率为训练集合b,即通过第一模型识别后具有识别结果的正样本。在后续步骤中根据识别结果从训练集合b中选择一部分训练样本作为后续的训练用。
步骤s3、对预处理后的训练样本按比例采样,采用采样后得到的第一训练样本集进行dnn训练,得到第二模型。
为了从训练集合b中选择一部分训练样本作为后续的训练用,可以直接从训练集合b中选择识别准确的样本作为后续训练采用的第二训练样本集。
本实施例优选地对预处理后的全部训练样本按比例采样得到训练集合a(第一训练样本集),例如正负样本的比例为1:10。在操作中,先选择出所有的正样本,然后从负样本中选择足够多的负样本,保持1:10的比例。然后采用采样后得到的第一训练样本集进行dnn训练,可以得到一个第二模型。深度神经网络dnn(deepneuralnetworks)是近年来机器学习领域中的研究热点,dnn训练广泛应用在语音识别及其他数据分类上,关于dnn训练的内容这里不再赘述。
在后续步骤中根据第二模型的训练结果与第一模型的训练结果从训练集合b中选择第二训练样本集。
根据实验得到的经验,第二模型的识别结果稳定性不够。而结合第二训练样本集在后续步骤中进行训练能够得到稳定性好的最终数据识别模型。
需要说明的是,本实施例对全部训练样本进行特征工程预处理,以及采用特征筛选来筛选掉不重要甚至有负作用的特征,都是为了训练得到的模型更加可靠。在具体的实施例中,可以在训练得到第一模型和训练得到第二模型时都需要对训练样本进行预处理和特征筛选,也可以仅在训练得到第一模型时进行特征筛选,而在训练第二模型时不进行特征筛选。容易理解的是,即使不进行特征工程预处理及特征筛选,也能提高训练得到的 模型的识别效果,使得训练得到的模型的识别效果好于现有技术,这里不再赘述。
步骤s4、根据采用第一训练样本集进行dnn训练的结果与采用第一模型对正样本进行识别的结果,从第一模型识别后具有识别结果的正样本中选择出第二训练样本集。
roc曲线是显示模型真正率和假正率的一种图形化方法,常用来评估模型的效果,roc曲线上每个点对应有三个值,分别为纵坐标真正率(truepositiverate,tpr)、横坐标假正率(falsepositiverate,fpr)和阈值概率。真正率(truepositiverate,tpr)是指被模型预测为正的正样本与正样本实际数量的比率;假正率(falsepositiverate,fpr)是指被模型预测为正的负样本与负样本实际数量的比率;阈值概率是用来判定预测结果为正的判定阈值,如果样本预测的结果大于该阈值概率则判定为正,否则判定为负。模型的预测效果越好,其tpr越接近于1,fpr越接近于0。
本实施例从训练集合b中选择一部分训练样本作为后续的训练用,选择的具体方法包括:
对训练得到的第二模型进行评估,得到第二模型对应的roc曲线;
对训练得到的第一模型进行评估,得到第一模型对应的roc曲线;
根据第一模型与第二模型roc曲线的交点对应的阈值概率,选择训练集合b中概率小于该阈值概率的样本,作为第二训练样本集。
需要说明的是,选择的第二训练样本集中的样本数量小于第一训练样本集中的正样本数量,最多不超过第一训练样本集中的正样本数量,这样是为了保证正负样本的比例,以防止正样本过多导致模型整体效果变差。
选择第二训练样本集还可以根据模型评估得到的概率,从训练集合b中按照概率从大到小顺序选择一定数量的样本第二训练样本集。或者根据经验设定一个阈值,从训练集合b中选择概率大于该阈值的样本作为第二训练样本集。本发明优选地根据roc曲线的交点进行选择,能够保证在后续的训练中得到更好的结果。
步骤s5、采用第一训练样本集和第二训练样本集进行dnn训练得到 最终的数据识别模型。
最后采用第一训练样本集和第二训练样本集进行dnn训练得到最终的数据识别模型,关于dnn深度学习训练模型,这里不再赘述。如图2所示的roc曲线表明,本实施例训练得到的最终的数据识别模型效果远远好于直接通过逻辑回归训练得到的第一模型效果。图2中上面的曲线为本实施例训练得到的最终的数据识别模型对应的roc曲线,下面的曲线为直接通过逻辑回归训练得到的第一模型对应的roc曲线。
通过对最终数据识别模型top抓坏率的计算,可以发现本实施例提出的建立数据识别模型的方法大大提高了模型的稳定性。
如图3所示,本实施例还提出了一种建立数据识别模型的装置,用于根据包括正、负样本的训练样本建立数据识别模型,该装置包括:
第一训练模块,用于采用训练样本进行逻辑回归训练,得到第一模型;
采样模块,用于对训练样本按比例采样,获得第一训练样本集;
选择模块,用于采用训练得到的第一模型对正样本进行识别,从第一模型识别后具有识别结果的正样本中选择出第二训练样本集;
最终模型训练模块,用于采用采样后得到的第一训练样本集与所述第二训练样本集进行深度神经网络dnn训练,得到最终的数据识别模型。
与上述方法对应地,容易理解的是,本装置还包括:
预处理模块,用于在进行按比例采样或进行逻辑回归训练前,对训练样本进行特征工程预处理。
以及,本装置还包括:
特征筛选模块,用于在采用训练样本进行逻辑回归训练之前,对训练样本进行特征筛选,所述特征筛选通过计算特征的信息值,去除信息值小于设定阈值的特征。
优选地,本装置还包括:
第二训练模块,用于采用第一训练样本集进行dnn训练,得到第二模型。
则本实施例采用优选的方法来选择第二训练数据集,选择模块从第一模型识别后具有识别结果的正样本中选择出第二训练样本集时,执行如下 操作:
对训练得到的第一模型进行评估,得到第一模型对应的roc曲线;
对训练得到的第二模型进行评估,得到第二模型对应的roc曲线;
根据第一模型与第二模型roc曲线的交点对应的阈值概率,从第一模型识别后具有识别结果的正样本中选择出概率小于所述阈值概率的样本作为第二训练样本集。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!