优化分段清除技术的制作方法
本公开涉及存储系统,并且更具体地涉及群集的一个或多个存储系统中的优化分段清除。
背景技术:
存储系统通常包括可以根据需要向其录入信息以及从其获得信息的一个或多个存储设备,诸如体现为存储阵列的快闪存储设备的固态驱动器(SSD)。存储系统可以实现高层级模块(诸如文件系统)以在逻辑上将存储在阵列的存储设备上的信息组织为存储容器,诸如文件或逻辑单元(LUN)。每个存储容器可以被实现为一组数据结构,诸如为存储容器存储数据的数据块以及描述存储容器中的数据的元数据块。例如,元数据可以描述(例如,标识)数据在设备上的存储位置。另外,元数据可以包含对数据的存储位置的引用的拷贝(即,多对一),由此在数据的位置改变时需要对引用的每个拷贝进行更新。这显著有助于写入放大以及系统复杂度(即,跟踪将要更新的引用)。
某些类型的SSD(尤其是具有NAND快闪部件的那些SSD)可以包括或者可以不包括内部控制器(即,对于SSD的用户不可访问),该内部控制器在以页面粒度(例如,8Kbyte)的那些部件之间将有效数据从旧的位置移动到新的位置,继而仅移动到先前擦除的页面。此后,页面被存储的旧的位置被释放,即,页面被标记用于删除(或无效)。通常,页面以32或更多页面的块(即,256KB或更多)被排他地擦除。将有效数据从旧的位置移动到新的位置(即,垃圾收集)有助于系统中的写入放大。因此,期望尽可能不频繁地移动有效数据,以便不放大数据被写入的次数,即,减少写入放大。
技术实现要素:
本文所述各实施例涉及优化分段清除技术,该优化分段清除技术被配置为有效清除耦合至群集的一个或多个节点的存储阵列的一个或多个选定部分或分段。在一个或多个节点上执行的存储输入/输出(I/O)栈的文件系统的盘区存储层在存储阵列的固态驱动(SSD)上提供数据和元数据的顺序存储。数据(和元数据)可以被组织为由节点提供服务的一个或多个主机可见LUN的任意数目的可变长度盘区。元数据可以包括从LUN的主机可见逻辑块地址范围(即,偏移范围)到盘区键值的映射,以及盘区键值到盘区在SSD上存储的位置的映射。盘区键值到盘区的位置的映射示例性为组织为哈希表的条目的盘区元数据以及一个或多个节点的存储器(内核)中存储的其他元数据数据结构。盘区的位置示例性包括包含最近版本盘区的分段的分段标识符(ID)以及包含该盘区的分段块的偏移(即,分段偏移)。
在一个实施例中,盘区存储层保持计数结构(例如,指示分段空闲空间量的空闲分段图)以及具有关于试探法和策略的信息的其他数据结构,其由分段清除过程示例性用于确定将要清除的分段(即,旧分段)的分段ID。分段清除处理可以使用分段ID扫描内核哈希表和元数据数据结构的条目以找到与分段ID的匹配。注意,条目的盘区元数据(例如,位置)包括对最近版本盘区的引用;因此,旧分段中需要被重定位的任意有效盘区可以被标识并且被拷贝到新分段。
在一个实施例中,分段清除技术的自下而上法被配置为读取将要清除的分段(即,“旧”分段)的所有块以定位分段的SSD上存储的盘区并且检查盘区元数据以确定盘区是否有效。SSD上存储的每个盘区是自描述的;即,盘区包括包含描述该盘区的信息(例如,盘区键值)的报头。盘区存储层的分段清除过程使用每个盘区的盘区键值来找到内核哈希表和元数据数据结构的盘区元数据条目,以确定包含最近版本盘区的分段的分段ID。如果条目的分段ID(和其他位置信息)匹配旧分段的分段ID(和其他位置信息),则由盘区键值引用的盘区被确定为有效(即,最近版本)并且由分段清除过程拷贝(重定位)到正被写入的分段(即,“新”分段)。如果条目的分段ID不匹配旧分段的分段ID,则由盘区键值引用的盘区不是最近版本(即,被确定为无效)并且可以被复写。
在一个实施例中,优化分段清除技术的自上而下法排除对旧分段的块进行读取来定位盘区,相反检查内核盘区元数据以确定旧分段的有效盘区。分段清除技术的此方法考虑到旧分段可能曾经具有相对满的有效盘区,但在清除之前,那些盘区中的某些盘区可能已经被逻辑复写(即,相同LBA范围),从而将复写盘区留作分段上的过期数据。因此,逻辑复写盘区(即,无效盘区)不需要被拷贝(重定位)。
在一个实施例中,分段清除技术的混合方法被配置为进一步减少旧分段块的读取,尤其是共享盘区的压缩块。混合方法可以执行合并全条带读取操作,尤其是在从丢失或不可访问SSD中重建丢失块(数据/元数据)的情况。为此,混合方法使用自上而下法确定旧分段的分段ID,扫描内核哈希表和元数据表的条目以找到与分段ID的匹配,并且标识旧分段中需要被重定位到新分段的有效盘区。重定位列表可以例如由分段清除过程创建,该重定位列表标识旧分段中需要被读取(和重定位)的有效盘区的块以及需要在可访问SSD上被读取以满足丢失SSD的丢失块的重建的任意块。分段清除过程继而可以根据将要重定位盘区的块所需的读取操作通过SSD位置对块(盘区)进行排序,继而i)将一个或多个邻近位置组合成单个更大读取操作;以及ii)将任意冗余位置引用合并到块,例如重定位在SSD上共享共同块的两个有效盘区所需的两个读取操作可以被合并到共同块的一个读取操作。在对列表排序和合并之后,减少数目的读取操作可以被确定以重定位块并且优化分段清除。
优势在于,自下而上法可以在旧分段(即,将要清除)的SSD具有相对满(即,超过容量阈值)的有效盘区(块)时被采用,以利用全条带读取操作来减少针对存储I/O栈的读取路径的SSD访问。相反,在i)SSD不可访问(即,丢失或故障)时;以及ii)分段的SSD相对空(即,针对有效盘区低于容量阈值)时可以采用自上而下法,因为该自上而下法仅需要读取旧分段中块的一部分以访问那些有效盘区,与读取分段的所有块相反。混合方法可以被用于扩展自上而下法以仅包括针对块重定位和重建所需的全条带读取操作,同时还避免自下而上法的任何不必要的读取操作。注意,在执行全条带读取操作之后,混合方法可以使用例如从扫描哈希表获得的分段偏移从条带中直接检索任意有效盘区。
附图说明
通过参考下面结合附图所做出的描述,可以更好地理解本文实施例中的上述优点和其他优点,在这些附图中,相同的附图标记表示相同的或功能上相似的元件,在附图中:
图1是相互连接为群集的多个节点的框图;
图2是节点的框图;
图3是节点的存储输入/输出(I/O)栈的框图;
图4示出了输入/输出(I/O)栈的写入路径;
图5示出了输入/输出(I/O)栈的读取路径;
图6示出了通过存储I/O栈的分层文件系统的分段清除;
图7示出了由分层文件系统执行的RAID条带;
图8示出了优化分段清除技术的自下而上法和盘区位置元数据;以及
图9a示出了优化分段清除技术的自上而下法;以及
图9b示出了在存储设备故障期间优化分段清除技术的方法。
具体实施方式
存储群集
图1是多个节点200的框图,这些节点相互连接为群集100并且被配置成提供与存储设备上信息的组织相关的存储服务。节点200可以通过群集互连结构110相互连接,并且包括多个功能部件,这些功能部件协作以提供群集100的分布式存储架构,该分布式存储架构可以被部署到存储区域网络(SAN)中。如本文所描述的,每个节点200的各部件包括硬件和软件功能,该硬件和软件功能使得该节点能够通过计算机网络130连接到一个或多个主机120、以及通过存储互连140连接到存储设备的一个或多个存储阵列150,从而按照分布式存储架构提供存储服务。
每个主机120可以被体现为通用计算机,该通用计算机被配置成按照信息递送的客户端/服务器模型与任意节点200交互。即,客户端(主机)可以请求节点的服务,并且节点可以通过经由网络130交换分组的方式返回主机所请求的服务的结果。当主机访问节点上的形式为存储容器(诸如文件和目录)的信息时,该主机可以发出包括基于文件的访问协议(诸如,传输控制协议/互联网协议(TCP/IP)上的网络文件系统(NFS)协议)的分组。然而,在一种实施例中,当主机120访问形式为存储容器(诸如逻辑单元(LUN))的信息时,该主机120示例性地发出包括基于块的访问协议(诸如,在TCP上封装的小型计算机系统接口(SCSI)协议(iSCSI)和在FC上封装的SCSI)的分组。注意,任意节点200可以为针对群集100上所存储的存储容器的请求提供服务。
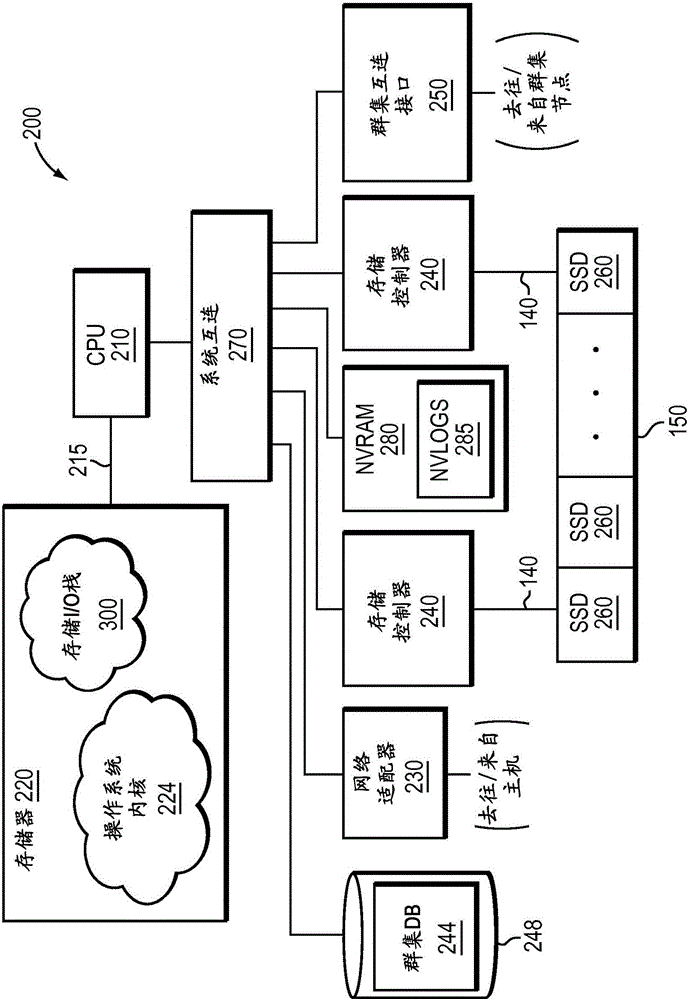
图2是节点200的框图,该节点200被示例性地体现为存储系统,该存储系统具有经由存储总线215耦接至存储器220的一个或多个中央处理单元(CPU)210。CPU 210还经由系统互连270耦接至网络适配器230、存储控制器240、群集互连接口250和非易失性随机访问存储器(NVRAM 280)。网络适配器230可以包括被适配成通过计算机网络130将节点200耦接至主机120的一个或多个端口,计算机网络130可以包括点对点链路、广域网、通过公共网络(互联网)或局域网实现的虚拟专用网络。因此,网络适配器230包括需要将节点连接至网络130的机械的、电气的和信令电路,该网络130示例性地体现了以太网或光纤通道(FC)网络。
存储器220可以包括CPU 210可寻址的存储器位置,该存储器位置用于存储软件程序以及与本文所描述的实施例相关联的数据结构。CPU 210则可以包括处理元件和/或逻辑电路,该处理元件和/或逻辑电路被配置成执行软件程序(诸如,存储输入/输出(I/O)栈300)以及操作数据结构。示例性地,存储输入/输出(I/O)栈300可以被实现为一组用户模式进程,该用户模式进程可以被分解为多个线程。操作系统内核224在功能上尤其是通过调用受节点(尤其是存储器I/O栈300)所实现的存储服务支持的操作来组织节点,操作系统内核224的一部分通常保留在存储器220(内核)并且由处理元件(即,CPU 210)执行。合适的操作系统内核224可以包括通用操作系统(诸如,操作系统的系列或Microsoft系列),或者具有可配置功能的操作系统(诸如,微内核和嵌入式内核)。然而,在本文中的一种实施例中,操作系统内核示例性地为操作系统。本领域技术人员应当理解,包括各种计算机可读介质的其他处理和存储器装置也可以用于存储并执行与本文的实施例有关的程序指令。
每个存储控制器240与节点200上执行的存储I/O栈300协作以获取主机120所请求的信息。该信息被优选地存储在存储设备(诸如,固态磁盘(SSD)260)上,该SSD被示例性地体现为存储阵列150的闪存存储设备。在一种实施例中,尽管本领域技术人员理解其他非易失性、固态电子设备(例如,基于存储类的存储器组件的驱动器)可以有利地结合本文所描述的实施例使用,但是闪存存储设备也可以是基于NAND的闪存组件(例如,单层单元(SLC)闪存、多层单元(MLC)闪存或三层单元(TLC)闪存)。因此,存储设备可以是或可以不是面向块的(即,作为块进行访问)。存储控制器240包括一个或多个具有I/O接口电路的端口,该I/O接口电路通过存储互连140耦接至SSD 260,存储互连140示例性地体现为串行连接SCSI(SAS)拓扑结构。备选地,可以使用其他的点对点I/O互连装置,诸如,常规串行ATA(SATA)拓扑结构或PCI拓扑结构。系统互连270还可以将节点200耦接至本地服务存储设备248(诸如,SSD),本地服务存储设备248被配置成将群集相关的配置信息本地存储为例如群集数据库(DB)244,群集数据库(DB)244可以被复制到群集100中的其他节点200。
群集互连接口250可以包括一个或多个端口,这些端口被适配成将节点200耦接至群集100的其他节点。在一种实施例中,可以使用以太网作为群集协议和互连结构介质,但是本领域技术人员应当理解,本文所描述的实施例中可以使用其他类型的协议和互连(诸如,无线带宽)。NVRAM 280可以包括能够根据节点的故障和群集环境来维护数据的后备电池或其他内建的最后状态保持能力(例如,非易失性半导体存储器,诸如,存储类存储器)。示例性地,NVRAM 280的一部分可以被配置为一个或多个非易失性日志(NVLog 285),这些非易失性日志被配置成临时地记录(“记入(log)”)I/O接收自主机120的请求(诸如写入请求)。
存储I/O栈
图3是存储I/O栈300的框图,该存储I/O栈300可以有利地结合本文所描述的一个或更多个实施例使用。存储I/O栈300包括多个软件模块或层,这些软件模块或层与节点200的其他功能组件协作以提供群集100的分布式存储架构。在一种实施例中,分布式存储架构表示单个存储容器的抽象化,即,所有关于整个群集100的节点200的存储阵列150被组织为一个大存储池。换句话说,该架构整合(consolidate)整个群集(通过群集范围键值可检索的)的存储(即,阵列150的SSD 260)以实现LUN的存储。随后,可以通过将节点200添加至群集100来缩放(scale)存储容量和性能。
示例性地,存储I/O栈300包括管理层310、协议层320、持久层330、卷层340、盘区存储层350、独立磁盘冗余阵列(RAID)层360、存储层365,以及与消息传送内核370互连的NVRAM(用于存储NVLog)层。该消息收发内核370可以提供基于消息(或基于事件)的调度模型(例如,异步调度),基于消息(或基于事件)的调度模型采用消息作为上述层之间交换(即,传递)的基本的工作单元。消息收发内核提供了一些合适的消息传递机制来在存储I/O栈300的上述层之间传送信息,这些消息传递机制可以包括:例如,针对节点内通信:i)在线程池上执行的消息传送;ii)通过存储I/O栈作为一种操作进行的在单线程上执行的消息传送;iii)使用进程间通信(IRC)机制的消息传送,以及例如,针对节点间通信:根据功能传送实现方式使用远程过程调用(PRC)机制的消息传送。备选地,I/O栈可以使用基于线程或基于栈的执行模型来实现。在一种或多种实施例中,消息传送内核370对来自操作系统内核224的处理资源进行分配以执行消息传送。每个存储I/O栈层可以被实现为执行一个或多个线程(例如,在内核或用户空间中)的一个或多个实例(即,进程),这些实例对上述层之间传递的消息进行处理使得消息能够针对上述层的阻断或非阻断操作提供同步化。
在一种实施例中,协议层320可以根据预定义的协议(诸如iSCSI和FCP)通过交换被配置为I/O请求的离散帧或分组的方式经由网络130与主机120通信。I/O请求(例如,读取或写入请求)可以针对LUN,并且可以包括I/O参数(诸如,尤其是LUN标识符(ID)、LUN的逻辑块地址(LBA)、长度(即,数据量),以及写数据(在写入请求的情况下)。协议层320接收I/O请求并且将I/O请求转发给持久层330,该持久层330将该请求记录到持久回写高速缓存380中并且经由协议层320向主机120返回确认通知,该持久回写高速缓存380示例性地体现为日志;例如,在一些随机访问替换策略,而不只是串行方式的情况下,日志的内容可以进行随机替换。在一种实施例中,仅记录了修改LUN的I/O请求(例如,写入请求)。注意,可以将I/O请求记录到接收I/O请求的节点处,或者,在备选实施例中,可以根据功能传送实现方式将I/O请求记录在其他节点处。
示例性地,专用日志可以通过存储I/O栈300的各个层维护。例如,专用日志335可以通过持久层330维护以内部等效地记录I/O请求的I/O参数(即,存储I/O栈、参数(例如,卷ID、偏移量和长度))。在写入请求的情况下,持久层330还可以与NVRAM 280协作以实现回写高速缓存380,该回写高速缓存380被配置成存储与写入请求相关联的写数据。在一种实施例中,回写高速缓存可以被构造为日志。注意,关于写入请求的写数据可以被物理地存储在高速缓存380中使得日志335包括对相关联的写数据的引用。本领域技术人员应当理解,可以使用数据结构的其他变型来存储或维护NVRAM中的写数据,包括使用没有日志的数据结构。在一种实施例中,还可以将回写高速缓存的副本维护在存储器220中以促进对存储控制器的直接存储器访问。在其他实施例中,可以按照维护数据被存储在高速缓存与群集之间的相关性的协议在主机120处或接收节点处执行高速缓存。
在一种实施例中,管理层310可以将LUN分成多个卷,每个卷可以被分区成多个区域(例如,根据不相交块地址范围进行分配),每个区域具有一个或多个分段,这些分段作为多个带被存储在阵列150上。因此,节点200中分布的多个卷可以为单个LUN提供服务,即,LUN内的每个卷为LUN内的、不同的LBA范围(即,偏移量范围和长度,以下称为偏移量范围)或一组范围提供服务。因此,该协议层320可以实施卷映射技术来对I/O请求所针对的卷(即,为I/O请求的参数所指示的偏移量范围提供服务的卷)进行识别。示例性地,群集数据库244可以被配置成针对多个卷中的每个卷维护一个或多个关联(例如,键值对),例如,LUN ID与卷之间的关联以及卷与用于管理该卷的节点的节点ID之间的关联。管理层310还可以与数据库244协作以创建(或删除)与LUN相关联的一个或多个卷(例如,在数据库244中创建卷ID/LUN键值对)。通过使用LUN ID和LBA(或LBA范围),卷映射技术可以提供卷ID(例如,使用群集数据库244中的适当关联)以及将LBA(或LBA范围)转化成卷内的偏移量和长度,该卷ID用于识别卷和为该卷提供服务的节点,该卷是所述请求的目的地。具体地,卷ID用于确定卷层实例,该卷层实例管理与LBA或LBA范围相关联的卷元数据。如前所述,协议层320可以将I/O请求(即,卷ID,偏移量和长度)传递至持久层330,持久层330基于卷ID可以使用功能传送(例如,节点间)实现方式将I/O请求转发至群集中的节点上执行的合适的卷层实例。
在一种实施例中,卷层340可以通过以下方式管理卷元数据,例如:维护主机可见容器的状态(诸如,LUN的范围),以及对与管理层310协作的LUN执行数据管理功能(诸如,创建快照和克隆)。卷元数据被示例性地体现为LUN地址(即,偏移量)到持久性盘区键值的内核映射,持久性盘区键值是群集范围内的存储容器的盘区键值空间内的、与盘区的SSD存储位置相关联的唯一的群集范围内的ID。也就是说,盘区键值可以用于检索位于SSD存储位置处的盘区中、与该盘区键值相关联的数据。备选地,群集中可以具有多个存储容器,其中每个容器具有其自身的盘区键值空间,例如,在该盘区键值空间中管理层310将盘区分布在存储容器中。盘区是可变长度的数据块,该数据块提供位于SSD上的存储单元并且不需要与任何特定边界对齐,即,可以是字节对齐。因此,为了维持这样的对齐,盘区可以是来自多个写入请求的写数据的聚集体。示例性地,卷层340可以将所转发的请求(例如,表征该请求的信息或参数)以及卷元数据的变化记录到卷层340所维护的专用日志345中。随后,可以按照核查点(例如,同步)操作将卷层日志345的内容写入存储阵列150,所述核查点操作将内核元数据存储到阵列150上。也就是说,核查点操作(核查点)确保内核所处理的元数据的一致状态被提交(即,存储)至存储阵列150;而日志条目的引退通过例如在核查点操作之前引退累积的日志条目的方式来确保卷层日志345中所累积的条目与提交到存储阵列150的元数据核查点同步。在一个或多个实施例中,核查点和日志条目的引退可以是数据驱动的、周期的、或以上二者。
在一种实施例中,盘区存储层350负责将盘区存储到SSD 260上(即,在存储阵列150上),并且(例如,响应于所转发的写入请求)将盘区键值提供给卷层340。盘区存储层350还负责(例如,响应于所转发的读取请求)使用盘区键值检索数据(例如,现有的盘区)。盘区存储层350可以负责在对盘区进行存储之前对该盘区进行解重复和压缩。盘区存储层350可以对盘区键值到SSD存储位置(即,阵列150的SSD 260上的偏移量)的内核映射(例如,体现为哈希表)进行维护。盘区存储层350还可以对条目的专用日志355进行维护,所述条目累积所请求的“放入”和“删除”操作(即,从其他层向盘区存储层350发出的针对盘区的写入请求和删除请求),而这些操作会改变内核映射(即,哈希表条目)。随后,可以根据“模糊”核查点390(即,记录在一个或多个日志文件中的具有增量变化的核查点)将内核映射和盘区存储层日志355的内容写入存储阵列150,其中将所选择的内核映射(少于总量的内核映射)按照不同的时间间隔(例如,通过大量内核映射的变化驱动、通过日志355的大小阈值驱动的或定期地驱动)提交到阵列150。注意,一旦所有的已经提交的内核映射包括日志355中的所累积的条目所记录的变化时,则可以将这些条目引退。
在一种实施例中,RAID层360可以将存储阵列150内的SSD 260组织为一个或多个RAID组(例如,SSD集合),该一个或多个RAID组通过在每个RAID组的给定数量的SSD 260上写入具有冗余信息(即,关于分条数据的适当的奇偶校验信息)的数据“条带”来提高阵列上的盘区存储的可靠性和完整性。RAID层360还可以例如根据多个连续范围的写操作来存储多个条带(例如,具有足够深度的条带),从而减少了SSD内可能发生的作为上述操作的结果的数据再定位(即,内部闪存块管理)。在一种实施例中,存储层365实现存储I/O驱动器,该存储I/O驱动器(诸如,Linux虚拟功能的I/O(VFIO)驱动器)可以通过与操作系统内核224共同操作来直接地与硬件(例如,存储控制器和群集接口)通信。
写入路径
图4示出了存储I/O栈300的用于处理I/O请求(例如,SCSI写入请求410)的I/O(例如,写入)路径400。该写入请求410可以由主机120发出并且针对群集100的存储阵列150上所存储的LUN。示例性地,协议层320接收该写入请求并通过对该请求的字段(例如,LUN ID、LBA和长度(在413处示出))以及写数据414进行解码420(例如,解析和提取)来对该写入请求进行处理。协议层320还可以使用针对卷映射技术430(如上所述)解码420的结果422以将写入请求中的LUN ID和LBA范围(即,相当于偏移量和长度)转化为群集100中适当的卷层实例(即,卷ID(卷445)),该适当的卷层实例负责针对LBA范围来管理卷元数据。在一种备选实施例中,持久层330可以实现上述卷映射技术430。然后,协议层将结果432(例如,卷ID、偏移量、长度(以及写数据)传递给持久层330,持久层330将请求记录到持久层日志335中并且将确认信息经由协议层320返回至主机120。持久层330可以将来自一个或多个写入请求的写数据414聚集并组织到新盘区610中,并且根据盘区哈希技术450对该新盘区执行哈希计算(即,哈希函数)以生成哈希值472。
然后,持久层330可以将具有所聚集的写数据的写入请求(包括,例如卷ID、偏移量和长度)作为参数434传递至适当的卷层实例。在一种实施例中,(由持久层接收的)参数434的消息传递可以经由功能传送机制(例如,PRC)重定向至其他节点以用于节点间通信。备选地,参数434的消息传递可以经由IPC机制(例如,消息线程)进行以用于节点内通信。
在一种或更多种实施例中,桶(bucket)映射技术476被提供来将哈希值472转化为适当的盘区存储层的实例(即,盘区存储实例470),该适当的盘区存储层负责存储新盘区610。注意,桶映射技术可以在存储I/O栈的位于盘区存储层上方的任意层中执行。例如,在一种实施例中,桶映射技术可以在持久层330、卷层340、或管理群集范围内的信息的层(诸如,群集层(未示出))中执行。因此,持久层330、卷层340或群集层可以包括CPU 210执行的计算机可执行指令,以进行用于执行本文所描述的桶映射技术476的操作。然后,持久层330可以将哈希值472和新盘区610传递至适当的卷层实例,并且通过盘区存储放入操作将哈希值472和新盘区610传递至适当的盘区存储实例。盘区哈希技术450可以体现近似一致的哈希函数,以确保任意待写入的盘区可以具有近似相同的机会进入任意盘区存储实例470,即,基于可用资源将哈希桶分布到群集100的盘区存储实例中。因此,桶映射技术476在群集的节点200上提供负载均衡的写入操作(以及,出于对称性,读取操作),同时平衡了群集中的SSD 260的闪存磨损。
响应于放入操作,盘区存储实例可以对哈希值472进行处理以执行盘区元数据选择技术460:(i)从盘区存储实例470内的一组哈希表(示例性地,内核)中选择适当的哈希表480(例如,哈希表480a),以及(ii)从哈希值472中提取哈希表索引462以索引所选择的哈希表,并且针对盘区查找具有盘区键值475的表条目,该盘区键值475用于识别SSD 260上的存储位置490。因此,盘区存储层350包括计算机可执行指令,CPU 210执行这些计算机可执行指令以进行用于实现本文所描述的盘区元数据选择技术460的操作。如果找到具有匹配盘区键值的表条目,则使用盘区键值475所映射的SSD位置490来从SSD中检索出现有的盘区(未示出)。然后,将现有的盘区与新盘区610进行比较以确定它们的数据是否相同。如果数据是相同的,则新盘区610本来存储在SSD 260上并且存在解重复机会(表示为解重复452)从而没有必要写入数据的另一副本。因此,表条目中对于现有盘区的引用计数增大,并且现有盘区的盘区键值475被传递至适当的卷层实例用于存储在密集树元数据结构444(例如,密集树444a)的条目(表示为卷元数据条目446)中,使得盘区键值475与卷445的偏移量范围440(例如,偏移量范围440a)相关联。
然而,如果现有盘区的数据与新盘区610的数据不同,则会发生冲突并且确定性算法被调用来按照需要连续地生成许多映射至同一桶的新候选盘区键值(未示出)以提供解重复452或产生尚未在盘区存储实例中存储的盘区键值。注意,另一哈希表(例如,哈希表480n)可以根据盘区元数据选择技术460来通过所述新候选盘区键值来选出。在不存在解重复机会的情况下(即,尚未存储该盘区),根据压缩技术454对新盘区610进行压缩并且将新盘区610传递至RAID层360,RAID层360对新盘区610进行处理用于存储在SSD 260上的、RAID组466的一个或多个条带710内。盘区存储实例可以与RAID层360协作以识别存储分段650(即,存储阵列150的一部分)以及SSD 260上、用于存储新盘区610的分段650内的位置。示例性地,所识别的存储分段是具有较大的连续空闲空间的分段,该空闲空间具有例如在SSD 260上用于存储盘区610的位置490。
在一种实施例中,RAID层360继而跨RAID组466写入条带710,示例性地为一个或多个全条带写入(full stripe write)458。该RAID层360可以写入一系列足够深度的条带710,以减少在基于闪存的SSD 260(即,闪存块管理)中可能出现的数据重定位。然后,盘区存储实例(i)将新盘区610的SSD位置490加载到所选择的哈希表480n(即,根据新的候选盘区键值进行选择的哈希表);(ii)将新盘区键值(表示为盘区键值475)传递至适当的卷层实例用于将该新盘区键值存储到由卷层实例所管理的密集树444的条目(还表示卷元数据条目446)内;以及(iii)将所选择的哈希表的盘区元数据的变化记录到盘区存储层日志355中。示例性地,卷层实例选择跨越卷445的偏移量范围440a的密集树444a,偏移量范围440a包括写入请求的偏移量范围。如前所述,卷445(例如,卷的偏移量空间)被分区为多个区域(例如,根据不相交的偏移量范围进行分配的多个区域);在一种实施例中,每个区域由密集树444表示。然后,卷层实例将卷元数据条目446插入到密集树444a中并且将与卷元数据条目相对应的变化记录到卷层日志345中。因此,在I/O(写入)请求被充分地存储在群集的SSD 260上。
读取路径
图5示出了用于处理I/O请求(例如,SCSI读取请求510)的存储I/O栈300的I/O(例如,读取)路径500。该读取请求510可以由主机120发出并且在群集100的节点200的协议层320处接收。示例性地,协议层320通过对该请求的字段(例如,LUN ID、LBA和长度(在513处示出))进行解码420(例如,解析和提取)来对该读取请求进行处理,并且针对卷映射技术430使用所解码的结果522(例如,LUN ID、偏移量和长度)。也就是说,协议层320可以实现卷映射技术430(上面描述的)以将读取请求中的LUN ID和LBA的范围(相当于偏移量和长度)转化为群集100中的适当的卷层实例(即,卷ID(卷445)),该适当的卷层实例负责针对LBA(即偏移量)范围来管理卷元数据。协议层然后将结果532传递到持久层330,持久层330可以搜索写入高速缓存380来根据其所高速缓存的数据确定是否可以为一些读取请求或全部读取请求提供服务。如果根据所高速缓存的数据不能对整个请求提供服务,则持久层330可以按照功能传送机制(例如,用于节点间通信的RPC)或IPC机制(例如,用于节点内通信的消息线程)将请求的剩余部分(包括,卷ID、偏移量和长度)作为参数534传递到适当的卷层实例。
卷层实例可以对该读取请求进行处理以访问与卷445的区域(例如,偏移量范围440a)相关联的密集树元数据结构444(例如,密集树444a),卷445的区域包括所请求的偏移量范围(由参数534指定的)。卷层实例可以进一步地对读取请求进行处理,以搜索(查找)密集树444a的一个或多个卷的元数据条目446从而获得所请求的偏移量范围内的、与一个或多个盘区610(或盘区的各部分)相关联的一个或多个盘区键值475。在一种实施例中,每个密树444可以被体现为多级搜索结构,该搜索结构能够在每一级处重叠偏移量范围条目。该多级密集树可以针对同一偏移量具有卷元数据条目446,在这种情况下,较高的级别具有较新的条目并且用来为读取请求提供服务。密集树444的顶级示例性地保留在内核中并且页面高速缓存448可以被用来访问树的较低级。如果顶级中不存在所请求的范围或者其一部分,则可以访问与下一较低树级别(未示出)处的索引条目相关联的元数据页面。然后,对下一级处的元数据页面(例如,在页面高速缓存448中)进行搜索以找到任意重叠的条目。然后,迭代地执行该过程,直到发现一个级的一个或多个卷元数据条目446为止,以确保能够找到对于整个所请求的读取范围的盘区键值475。如果整个或部分所请求的读取范围不存在元数据条目,则未缺失部分被零填充。
一旦找到,则卷层340对每个盘区键值475进行处理以实现例如桶映射技术476,从而将该盘区键值转化为负责存储所请求的盘区610的适当的盘区存储实例470。需要注意的是,在一种实施例中,每个盘区键值475可以基本上等同于与盘区610相关联的哈希值472(即,针对盘区进行写入请求期间所计算的哈希值),使得桶映射技术476和盘区元数据选择技术460可以用于写入路径操作和读取路径操作二者。还需要注意的是,可以根据哈希值472推导出盘区键值475。然后,该卷层340可以将盘区键值475(即,来自先前的针对盘区的写入请求的哈希值)传递(经由盘区存储获取操作)至适当的盘区存储实例470,该盘区存储实例470实现盘区键值至SSD的映射以确定盘区在SSD 226上的位置。
响应于该获取操作,盘区存储实例可以对盘区键值475(即,哈希值472)进行处理以执行元数据选择技术460:(i)从盘区存储实例470内的一组哈希表中选择适当的哈希表480(例如,哈希表480a),以及(ii)从盘区键值475(哈希值472)中提取哈希表索引462以索引到所选择的哈希表,并且针对盘区610查找具有匹配盘区键值475的表条目,该匹配盘区键值475用于标识SSD 260上的存储位置490。也就是说,映射到盘区键值475的SSD位置490可以用于从SSD 260(例如,SSD 260b)中检索现有的盘区(表示为范围610)。然后,盘区存储实例与RAID层360协作以访问在SSD 260b上的盘区并且根据读取请求来检索数据内容。示例性地,RAID层360可以根据盘区读取操作468对盘区进行读取并且将盘区610传递至盘区存储实例。然后,盘区存储实例可以根据解压缩技术456对盘区610进行解压,然而应本领域技术人员应当理解可以在存储I/O栈300的任一层来执行解压。盘区610可以被存储在存储器220的缓冲器(未示出)中,并且对该缓冲区的引用可以通过存储I/O栈的各层被传回。然后,持久层可以将盘区加载到读取式高速缓存580(或其他分级机制),并且可以针对读取请求510的LBA范围从读取式高速缓存580中提取适当的读数据512。此后,协议层320可以创建SCSI读取响应514(包括读数据512)并且将该读取响应返回至主机120。
分层文件系统
本文所述实施例示例性采用了存储I/O栈的分层文件系统。该分层文件系统包括文件系统的闪存优选、日志结构层(即,盘区存储层),该闪存优选、日志结构层被配置为提供群集的SSD 260上的数据和元数据的连续存储(即,日志结构布局)。数据可以被组织为由节点提供服务的一个或多个主机可见LUN的任意数目的可变长度盘区。元数据可以包括从LUN的主机可见逻辑块地址范围(即,偏移范围)到盘区键值的映射,以及盘区键值到盘区在SSD上存储的位置的映射。示例性地,分层文件系统的卷层与盘区存储层协作以提供间接层,该间接层通过盘区存储层促进SSD上盘区的高效日志结构布局。
在一个实施例中,文件系统的日志结构层的功能(诸如写入分配和闪存设备(即,SSD)管理)由盘区存储层350执行并管理。写入分配可以包括收集可变长度盘区,以形成可以被写入以跨一个或多个RAID组的SSD释放分段的全条带。即,文件系统的日志结构层将盘区写到最初空闲(即,干净)分段作为全条带,而不是部分条带。闪存设备管理可以包括分段清除以创建经由RAID组间接映射到SSD的这种空闲分段。因此,部分RAID条带写入被避免,这产生减少的RAID相关写入放大。
代替依赖于SSD中的垃圾收集,存储I/O栈可以在盘区存储层中实现分段清除(即,垃圾收集),以绕开SSD中闪存转换层(FTL)功能(包括垃圾收集)的性能影响。换言之,存储I/O栈允许文件系统的日志结构层使用分段清除操作为数据布局引擎,以有效代替SSD的FTL功能的实质部分。盘区存储层因此可以按照分段清除(即,垃圾收集)来处理随机写入请求以预测其FTL功能内的闪存行为。因此,针对存储I/O栈的写入放大的日志结构等效源可以在盘区存储层合并和管理。另外,文件系统的日志结构层可以被部分采用以改进存储阵列的闪存设备的写入性能。
注意,SSD的日志结构布局通过顺序写入盘区以清除分段来实现。因此,由盘区存储层采用的日志结构布局(即,顺序存储)固有地支持可变长度盘区,由此允许SSD上的存储之前盘区的不严格压缩并且不具有来自SSD的明确块级(即,SSD块)元数据支持,诸如支持512字节数据和8字节元数据(例如,对于包含压缩数据的末端的另一块的指针)的520字节扇区。通常,消费者级别SSD支持为2的幂(例如,512字节)的扇区,而更昂贵的企业级别SSD可以支持增强大小的扇区(例如,520字节)。因此,盘区存储层可以利用较低成本的消费者级别SSD进行操作,同时利用其相伴的无约束压缩来支持可变长度盘区。
分段清除
图6示出了通过分层文件系统的分段清除。在一个实施例中,分层文件系统的盘区存储层350可以将盘区写到空或空闲区域或“分段”。在再次重写入该分段之前,盘区存储层350可以按照分段清除将段进行清除,如图所示该分段清除可以被体现为分段清除过程。该分段清除过程可以从旧分段650a读取所有有效盘区610并且将那些有效盘区(即,未被删除或复写612的盘区)写到一个或多个新分段650b-c,由此释放(即,“清除”)旧分段650a。新盘区继而可以被顺序写到旧(现在干净)分段。分层文件系统可以保持特定量的保留空间(即,空闲分段)以支持分段清除的高效表现。例如,分层文件系统可以如图所示保持等同于近似7%存储容量的空闲分段的保留空间。新盘区的顺序写入可以表现为全条带写入458,使得对存储的单个写入操作跨越RAID组466中的所有SSD。写数据可以被累积直到最小深度的条带写入操作可以被执行。
示例性地,分段清除可以被执行以释放间接映射到SSD的一个或多个选定分段。如本文所使用的,SSD可以包括多个分段块620,其中每个块的大小示例为近似2GB。分段可以包括来自RAID组466中多个SSD的每个SSD的分段块620a-c。因此,针对具有24个SSD的RAID组,其中22个SSD的等效存储空间存储数据(数据SSD)并且2个SSD的等效存储空间存储奇偶校验(奇偶校验SSD),每个分段可以包括44GB的数据和4GB的奇偶校验。RAID层可以进一步按照一个或多个RAID实现方式(例如,RAID1、RAID 4、RAID 5和/或RAID 6)来配置RAID组,由此在例如一个或多个SSD故障的情况下提供对SSD的保护。注意,每个分段可以与不同的RAID组相关联,并且因此可以具有不同的RAID配置,即,每个RAID组可以按照不同的RAID实现方式进行配置。为了释放或清除选定的分段,分段中包含有效数据的盘区被移动到不同的干净分段并且选定的分段(现在干净)被释放用于后续重用。分段清除合并分散的空闲空间以改进写入有效性,例如,通过减少RAID相关的放大率来改进对条带的写入有效性以及通过减少FTL的性能影响来改进对基础闪存块的写入有效性。一旦分段被清除并指定释放,数据就可以被顺序写到该分段。由盘区存储层为写入分配保持的计数结构(例如,指示分段空闲空间的量的空闲分段映射)可以由分段清除过程采用。注意,选择干净分段以从正被清除的分段接收数据(即,写入)可以基于该干净分段中剩余的空闲空间的量和/或该干净分段被使用的最后时间。还应当注意,来自正被清除的分段的数据的不同部分可以被移动至不同“目标”分段。即,多个相关干净分段650b、650c可以从正被清除的分段650a接收数据的不同部分。
示例性地,分段清除可能造成存储阵列(SSD)中的某种程度的写入放大。然而,文件系统可以通过向SSD顺序写入盘区作为日志设备来减少这种写入放大。例如,假设SSD具有近似2MB的擦除块大小,通过向空闲分段顺序写入至少2MB的数据(盘区),整个擦除块可以被复写并且SSD级的存储残片可以被消除(即,减少SSD中的垃圾收集)。然而,SSD通常跨多个闪存部件和跨多个通道(即,存储控制器240)分条数据以便实现性能。因此,对空闲(即,干净)分段的相对大(例如,2GB)写入粒度可能对避免SSD级写入放大(即,覆盖内部SSD分条)而言是必要的。
具体地,因为SSD中的擦除块边界可能是未知的,所以写入粒度应当足够大,以便针对大的连续范围上的盘区的一系列写入可以复写SSD上先前写入的盘区并且有效地覆盖SSD中的垃圾收集。换言之,这种垃圾收集可以被抢占,因为新数据在与先前数据相同的范围上被写入,使得该新数据完全复写先前写入的数据。此方法还避免了新写入数据消耗保留的空间容量。因此,存储I/O栈的日志结构特征(即,文件系统的日志结构层)的优势在于仅利用SSD中最小量的保留空间来减少SSD的写入放大的能力。该日志结构特征将保留空间的闪存设备管理从SSD有效地“移动”到盘区存储层,该盘区存储层使用该保留空间来管理写入放大。因此,仅存在写入放大的一个源(即,盘区存储层)而不是具有写入放大的两个源(即,盘区存储层和SSD FTL,两者进行相乘)。
写入分配
在一个实施例中,每个分段可以有多个RAID条带。每次分段被分配(即,在清除分段之后),该分段内各SSD的块可以包括一系列RAID条带。各块可以位于SSD内的相同或不同偏移。盘区存储层可以出于清除的目的顺序读取块并且将所有有效数据重定位到另一分段。此后,经清除的分组的块620可以被释放并且可以提出如何构成使用该块的下一分段的决策。例如,如果SSD从RAID组被移除,则容量的一部分(即,一组块620)可以从下一分段中省略(即,RAID条带配置中的改变),以便从多个块620中构成较窄的一个块的RAID组,即,使得RAID宽度少一个块宽度。因此,通过使用分段清除,每次新分段被分配,构成分段的块620的RAID组就可以被有效创建,即,当新分段被分配时,RAID组就从可用SSD动态创建。通常不需要在新分段中包括存储阵列150中的所有SSD 260。备选地,来自新引入的SSD的块620可以被添加至在新分段650被分配时创建的RAID组。
图7示出了由分层文件系统形成的RAID条带。注意,写入分配可以包括收集可变长度盘区以形成跨一个或多个RAID组的SSD的一个或多个条带。在一个实施例中,RAID层360可以管理用于RAID组466的SSD 260a-n上盘区610的替换的拓扑信息和奇偶校验计算。为此,RAID层可以与盘区存储层协作以将盘区组织为RAID组内的条带710。示例性地,盘区存储层可以收集盘区610以形成可以被写到空闲分段650a的一个或多个全条带710,使得单个条带写入操作458可以跨越该RAID组中的所有SSD。盘区存储层还可以与RAID层协作以将每个条带710包装为可变长度盘区610的全条带。一旦条带被完成,RAID层可以将盘区的全条带710作为一组块620d-f传递到存储I/O栈的存储层365,用于在SSD 260上存储。通过向空闲分段写入全条带(即,数据和奇偶校验),分层文件系统避免了奇偶校验更新的成本并且跨SSD展开任意请求的读取操作负载。注意,对SSD 260挂起写入操作的盘区610可以被累加至块620d,e,该块作为一个或多个临时近似写入操作被写到SSD(例如,2Gbyte),由此减少了SSD中FTL的性能影响。
在一个实施例中,盘区存储可以被视为群集的存储阵列150上存储的全局盘区池,其中每个盘区可以被保持在盘区存储实例的RAID组466内。假设一个或多个可变长度(即,小和/或大)盘区被写入分段。盘区存储层可以收集可变长度盘区以形成跨RAID组的SSD的一个或多个条带。虽然每个条带可以包括多个盘区610并且盘区610可以跨越不止一个条带710a,b,每个盘区被完整地存储在一个SSD上。在一个实施例中,条带可以具有深度16KB并且盘区可以具有大小4KB,但是此后盘区可以被向下压缩到1KB或2KB或者更小,从而允许可能超过条带深度(即,块620g深度)的更大盘区被包装。因此,条带可以仅构成盘区的一部分,条带710的深度(即,构成该条带的一组块620d-f)可以独立于被写入任意一个SSD的盘区。因为盘区存储层可以将盘区作为全条带跨SSD的一个或多个空闲分段写入,所以与条带的处理信息相关联的写入放大可以被减少。
优化分段清除技术
本文所述各实施例涉及优化分段清除技术,该优化分段清除技术被配置为有效清除耦合至群集的一个或多个节点的存储阵列的一个或多个选定部分或分段。注意,盘区存储层350在存储阵列150的SSD 260上提供数据和元数据的顺序存储。元数据可以包括盘区键值到SSD上存储的盘区的位置的映射,该映射示例性为组织为内核哈希表480的条目的盘区元数据以及一个或多个节点的其他元数据数据结构。例如,58GB的盘区元数据可以被用于描述在10TB可用存储上存储的盘区的位置(例如,22个数据SSD和2个奇偶校验SSD)。这种盘区元数据可以被组织为内核哈希表480,例如,布谷鸟(cuckoo)哈希表。另外,可能存在与没有被哈希表描述的哈希表自身的元数据(例如,核查点)有关的盘区;这些盘区的位置可以由其他内核元数据数据结构(即,元数据表)的条目描述,并且记录在SSD上。例如,哈希表的盘区元数据自身体现为页面并且写为SSD上的盘区(例如,作为核查点),而哈希表(即,盘区元数据)的变化也在盘区存储层日志355中累积并且被写为SSD上的盘区。
图8示出了优化分段清除技术的自下而上法和盘区位置元数据。示例性地,哈希表480的每个条目810和元数据表850的每个条目852描述了盘区键值到SSD上最近版本的对应盘区的位置490的映射。因此,表中描述的每个盘区是有效盘区(即,使用中)。注意,位置提供了足够信息用于从SSD检索(即,读取)盘区。优化分段清除技术可以被配置为搜索哈希表480的条目810以及元数据表850的条目852以标识将要清除的一个或多个分段内盘区的位置,所述条目存储了针对哈希表的核查点和日志的盘区元数据。每个盘区的位置490示例性包括包含最近版本盘区的分段的分段标识符(ID)824。在一个实施例中,最近版本盘区的位置490可以特别包括(i)1位,用于标识包含该盘区的RAID组(即,RAID ID822),(ii)13位,用于标识包含该盘区的分段(即,分段ID824),(iii)5位,用于标识包含该盘区的RAID组内的数据SSD(即,盘ID 826),(iv)21位,用于标识包含该盘区(例如,盘区报头的第一字节)的一块分段的偏移(即,分段偏移828),以及(v)8位,标识由该盘区(即,盘区大小829)消耗的若干标准大小块(例如,512字节)。
在一个实施例中,盘区存储层保持计数结构(例如,指示分段空闲空间量的空闲分段图)以及具有关于试探法和策略的信息的其他数据结构,其由分段清除过程示例性用于确定将要清除的分段(即,旧分段)的分段ID。因此,基于策略(例如,超过空闲空间阈值诸如25%)选择用于清除的分段并且根据分段清除技术进行清除,示例性为:(i)自下而上法,(ii)自上而下法,或(iii)混合法。示例性地,分段清除技术的选择可以基于检查与选定用于清除的分段相关联的计数结构来确定。
在一个实施例中,分段清除技术的自下而上法被配置为读取将要清除的分段650(即,“旧”分段)的所有块以定位分段的SSD上存储的盘区610并且检查盘区元数据以确定盘区是否有效。示例性地,分段清除技术可以与RAID层360协作以在旧分段开始起并行进到其结束执行连续全条带读取操作。SSD上存储的每个盘区是自描述的;即,盘区包括包含描述该盘区的信息(例如,由SSD上盘区消耗的盘区键值和长度(以字节)(未示出))的盘区报头860。盘区存储层的分段清除过程使用每个盘区的盘区键值来分别找到(例如,索引)内核哈希表480和元数据表850a-n中对应于针对每个盘区的盘区键值的盘区元数据条目810、852,以确定包含最近版本盘区610a的分段的分段ID。注意,盘区元数据选择技术460可以用于快速找到(即,索引)对应于盘区的哈希表条目810a。如果条目810a中位置490a的分段ID 824a(例如,“1”)匹配旧分段650a的分段ID(例如,“1”),则由盘区键值475a引用的盘区被确定为有效(即,最近版本)并且被拷贝(重定位)到正被写入的分段650b(即,“新”分段)。分段清除过程继而可以更新哈希表(或元数据表)条目810a中的位置490a以参考盘区610a在新分段650b中的新位置。然而,如果条目的分段ID 824b(例如,“2”)不匹配旧分段650a的分段ID(例如,“1”)(或者不存在针对盘区键值的哈希表条目810),则由盘区键值475b引用的盘区不是最近版本(即,被确定为无效)并且可以被复写。注意,匹配位置的任意其他部分(即,RAID ID 822、盘ID 826和分段偏移828)的失败指示该盘区无效。因此,条目位置的各部分(即,RAID ID、盘ID和分段偏移)可以被匹配到与该盘区相关联的对应信息,以确定该盘区是否有效。因此,自下而上法被配置为读取旧分段650a上每个盘区610的盘区报头860以确定该盘区是否有效(即,数据/元数据处于使用中),并且如果有效,则将该盘区重定位(拷贝)到新分段以保护有效数据/元数据同时合并由无效盘区612(例如,被删除的盘区)占用的空间。一旦所有有效数据/元数据被重定位,整个旧分段继而可以被安全重用。
在一个实施例中,优化分段清除技术的自上而下法排除对旧分段的块进行读取来定位盘区,相反检查内核盘区元数据(即,哈希表和元数据表条目)以确定将要清除的旧分段的有效盘区。分段清除技术的此方法考虑到旧分段可能曾经具有相对满的有效盘区,但在清除之前,那些盘区中的某些盘区可能已经被逻辑复写(即,相同LBA范围),从而将复写盘区留作分段上的过期数据。因此,逻辑复写盘区(即,无效盘区)不需要被拷贝(重定位)。因此,针对具有频繁复写数据的访问模式的I/O工作负载,自上而下法可以是高效的,因为其仅读取和重定位分段中块的有效盘区。相反,自下而上法从旧分段读取有效和无效盘区,然后验证所读取的盘区是否有效。
图9a示出了优化分段清除技术的自上而下法。示例性地,分段清除过程扫描内核哈希表480和元数据表820的条目以找到匹配选定用于清除的分段的分段ID的相应条目810a,b和852。注意,条目的盘区元数据(例如,位置490)包括对最近版本盘区的引用;因此,旧分段650a中需要被重定位的任意有效盘区610a可以被标识并且被拷贝到新分段650b。换言之,无效(例如,被删除)盘区612不被读取,因为其不需要被重定位。分段清除过程继而可以更新条目810a的位置490a以参考盘区610a在新分段650b中的新位置。与可以读取分段中有效(即,使用中)和无效(例如,被删除)盘区两者,然后验证所读取盘区的有效性的自下而上法不同,自上而下法避免了从分段中读取无效盘区。即,自下而上法由SSD上的盘区驱动,而自上而下法由与内核哈希表和元数据表中的条目相关联的有效盘区驱动。通常,自下而上法针对相对满(即,超过容量阈值)的分段更有效,而自上而下法针对相对空(即,低于容量阈值)的分段更有效。
图9b示出了在存储设备故障期间优化分段清除技术的方法。假设响应于RAID组的丢失(例如,故障、不可访问或者其他原因不可用)SSD 260a,新SSD 260n+1被添加到RAID组并且不可访问SSD的数据(例如,有效盘区610a和无效盘区612)被重建并且其有效性在存储在新分段650c之前被验证。使用自下而上法,RAID组的每个条带710可以被读取(经由全条带读取操作),并且丢失数据(例如,不可访问SSD 260a上的有效盘区610a和无效盘区612)可以被重建并且在被写到新分段650c上对应位置之前被验证。使用自上而下法,内核哈希表和元数据表可以被扫描,以通过将要清除的分段(包括丢失SSD)的位置搜索有效盘区。此后,仅在扫描中找到的那些盘区(即,有效盘区610a)需要被重建;注意,不需要对丢失SSD上被复写或删除的数据(例如,无效盘区612)进行重建。注意,多个数据重建可以在丢失SSD上的多个盘区需要重定位时发生。
在一个实施例中,分段清除技术的混合方法被配置为进一步减少旧分段块的读取,尤其是共享盘区的压缩块,使得每个块仅被读取一次。如先前所述,盘区存储层采用的日志结构布局允许在SSD存储之前盘区的非严格压缩。例如,4KB盘区数据可以被压缩到2KB盘区,使得SSD上不是全部4KB块被消耗;相反,另外2KB盘区可以紧邻(例如,同一4KB块上)被压缩的2KB盘区被包装。但是,如果两个盘区被单独读取,则SSD上的同一块可能被读取两次,即,每个盘区使用分段清除的自上而下法或自下而上法一次。然而,混合方法被配置为避免这种冗余,因为读取块两次以从共享相同块的不同盘区重定位信息增加了读取放大率和写入放大两者。为此,混合方法可以被配置为执行合并全条带读取操作,尤其是在从丢失或不可访问SSD中重建丢失块(数据/元数据)的情况。
因此,混合方法使用自上而下法确定旧分段的分段ID,扫描内核哈希表和元数据表的条目以找到与分段ID的匹配,并且标识旧分段中需要被重定位到新分段的有效盘区。重定位列表可以例如由分段清除过程创建,该重定位列表标识旧分段中需要被读取(和重定位)的有效盘区的块以及需要在可访问(丢失)SSD上被读取以满足丢失SSD的丢失块的重建的任意块。分段清除过程继而可以根据将要重定位盘区的块所需的读取操作通过SSD位置(例如,通过存储设备偏移的阶梯排序)对块(盘区)进行排序,继而i)将一个或多个邻近位置组合成单个更大读取操作;以及ii)将任意冗余位置引用合并到块,例如重定位在SSD上共享共同块的两个有效盘区所需的两个读取操作可以被合并到共同块的一个读取操作。在对列表排序和合并之后,减少(理想是最小)数目的读取操作可以被确定以重定位块并且优化分段清除。
在一个实施例中,存在若干类型(例如,5类)的盘区,其中每类盘区指定内核表类型(即,哈希表或元数据表)来扫描以确定旧分段的盘区是否有效,即,旧分段是否存储了最近版本的盘区。当将要清除的旧分段的盘区使用自下而上法被找到时,盘区的盘区报头被读取以确定盘区的类型,从而在那里(即,哪种类型的表)查找描述该盘区的元数据(即,位置元数据)。相反,自上而下和混合方法扫描每个内核表。注意,当一次扫描不止一个分段时,内核表可以针对每个正被清除的分段逐条目进行扫描,以搜索所有正被清除的分段中的有效盘区。
优势在于,自下而上法可以在旧分段(即,将要清除)的SSD具有相对满(即,超过容量阈值)的有效盘区(块)时被采用,以利用全条带读取操作来减少针对存储I/O栈的读取路径的SSD访问。注意,分段清除过程与RAID层协作来使用全条带读取操作示例性读取整个旧分段,以将有效盘区从旧分段重定位到正被写入的新分段。全条带读取操作的表现还排除对在重建数据时响应于RAID组的丢失SSD额外读取操作的需求,例如,丢失SSD的丢失数据可以由RAID层每读取操作使用一次XOR操作来构建,而不考虑正被读取盘区的数目。
相反,在i)SSD不可访问(即,丢失或故障)时;以及ii)分段的SSD相对空(即,针对有效盘区低于容量阈值)时可以采用自上而下法,因为该自上而下法仅需要读取旧分段中块的一部分以访问那些有效盘区,与读取分段的所有块相反,由此减少了读取和写入放大。与自下而上法不同,自上而下法通常不执行全条带读取操作除非重建丢失SSD中的数据。混合方法可以被用于扩展自上而下法以仅包括针对块重定位和重建所需的全条带读取操作,同时还避免自下而上法中实施的无效盘区的任何不必要的读取操作以及针对自上而下法中实施的重建的冗余读取。注意,在执行全条带读取操作之后,混合方法可以使用例如从扫描哈希表获得的分段偏移从条带中直接检索任意有效盘区。
前面的描述针对的是具体的实施例,然而,明显的是,可以对所描述的实施例进行其他变型和修改,这些变型和修改获得了所述实施例的部分或全部优点。例如,明确预期的是,本文所描述的组件和/或元件可以实施为在有形(非临时性)的计算机可读介质(例如,磁盘和/或CD)上进行编码的软件,该有形(非临时性)的计算机可读介质具有执行在计算机、硬件、固件或上述项的组合的程序指令。因此,本说明书仅意在举例说明而并非意在对本文的实施例的范围进行限制。因此,所附权利要求的目的在于覆盖本文的实施例的真正主旨和范围之内所有的这些变型和修改。
- 还没有人留言评论。精彩留言会获得点赞!