用于节流数据访问的数据沿的制作方法
背景技术:
用于保护服务器上的信息的现代技术可以包括对恶意使用者进行数据节流以防止盗用大量数据。此类技术可以实施为软件。因为软件有效地控制对数据的访问,危害软件的有效恶意攻击可以导致恶意实施者对计算环境的数据具有完全访问。
附图说明
以下详细描述参考附图,其中:
图1是使用数据沿用于节流数据访问的示例计算装置的方框图;
图2是用于由使用数据沿用于节流数据访问的计算装置执行的示例方法的流程图;
图3a是具有共享存储器的示例节流数据缓冲器的方框图;
图3b是具有单独的进入和流出共享存储器的示例节流数据缓冲器的方框图;以及
图4是具有存储页控制器的示例节流数据缓冲器的方框图。
具体实施方式
如上文详细描述的,可以使用软件来通过使用数据加密保护计算装置。然而,如果损害了此类软件,恶意实施者可以获得对计算装置的数据的完全访问。本文公开的实例可以使从损害的系统远程偷窃大量数据对于恶意实体来说更加困难。具体地,尽管大部分现有的方法聚焦于限制经由软件对系统的访问,所提出的方案物理地限制系统中可以经由硬件访问的数据的量,这充当对潜在的数据盗窃的抑制因素。
通用型计算机存储器和数据访问逻辑通常针对读/写(即,访问速度)性能进行优化,并且一般提供对软件的开放访问,而不管内容的敏感性。结果,数据访问限制通常被实施为较高水平的软件特征,所述软件特征能遭受远程实体的恶意攻击。相反,本文描述的实例物理地限制可以经由实施在硬件中的限制性通道从给定系统访问的数据的量,这充当对潜在的数据盗窃的抑制因素。具体地,因为没有经由软件重载或绕过装置内的数据节流实施的手段,外部访问的速率被限制于保持在片上系统(soc)内的数据。因此,修改平台被限于在硅水平上通过对装置的物理访问的修改。因为可以访问的数据的速率按单位时间进行限制(例如,经由嵌入在soc内的自清理存储器访问锁),所以询问器受到阻止,这是因为直到已经集聚足够数量的块(这会花费过长的时间)之前,可以访问的小块的数据都是无效的。
现在参考附图,图1是使用数据沿用于节流数据访问的示例计算装置100的方框图。计算装置100可以是能够提供计算服务的任何装置,如台式电脑、笔记本电脑、平板电脑、智能手机、网页服务器、数据服务器,或其他计算装置。在图1的实例中,计算装置100包括分析引擎110、节流数据缓冲器120和数据沿130。
分析引擎110可以处理由计算装置100接收的数据请求。在该实例中,分析引擎110至少包括一组中央处理单元(cpu)114a和存储器112。
存储器112可以是为计算装置100储存数据的任何电子、磁性、光学或其他物理储存装置。因此,存储器112可以是,例如,随机存取存储器(ram)、只读存储器(rom)、电可擦除只读存储器(eeprom)、闪速存储器等。在该实例中,存储器112是嵌入在分析引擎110中的共享存储器。在其他情况中,每个cpu114a可以具有单独的存储器112和/或存储器112可以在分析引擎110外部。存储器可访问分析引擎110的cpu组114a,但是不能访问数据沿130的cpu组114b。
cpu组114a可以包括适合于指令的检索和执行的一个或多个中央处理单元(cpu)、一个或多个微处理器和/或一个或多个其他硬件装置。cpu组114a中的每个cpu可以读取、解码和执行指令以进行分析并且针对数据请求提供应答等。由分析引擎110处理的数据可以经由节流数据缓冲器120提供给数据沿130。作为检索和执行指令的替代方案或此外,cpu组114a可以包括包含一些用于执行此类功能的电子元件的电子电路。
数据沿130可以从其他计算装置接收数据请求并且向所述其他计算装置提供数据应答。在该实例中,数据沿130包括一组中央处理单元114b和存储器远程输入/输出(i/o)132。数据沿130充当发送到其他计算装置和从所述其他计算装置接收的数据包的分离的保存区。例如,数据包可以被保留在数据沿130上,用于由其他计算装置收集,而不使其他计算装置获得对分析引擎110的敏感区域的访问。
类似于cpu组114,cpu组114b可以包括适合于指令的检索和执行的一个或多个中央处理单元(cpu)、一个或多个微处理器和/或一个或多个其他硬件装置。cpu组114b中的每个cpu可以读取、解码和执行指令以经由远程i/o132等与其他计算装置通信。作为检索和执行指令的替代方案或此外,cpu组114b可以包括包含一些用于执行此类功能的电子元件的电子电路。
在一个实例中,计算装置100将它决定共享的任何数据放置在数据沿130上,以供其他计算装置或实体(用户、应用程序等)经由远程i/o132收集。同样地,来自其他装置的外部请求也经由远程i/o132被放置在数据沿130上,以供计算装置100解译和响应。计算装置100可以被包括在计算装置的群组(即,集群、分布式计算系统、网络服务器等)中,所述计算装置中每个具有如图1中所示的分析引擎110和数据沿130。例如,计算装置的群组中的节点可以被配置为纯的分析引擎。在另一个实例中,计算装置的群组中的节点也可以被配置成连接到本地数据源或信宿(例如,各种传感器和致动器、本地子系统或数据储存库等)。数据沿130限制分析引擎110和数据沿130之间的信息的交换。如果节流数据缓冲器120更开放,节点内的数据变得更不安全,而过度限制性的节流数据缓冲器可以减少数据沿130的实用性。
节流数据缓冲器120具有限制数据沿130和分析引擎110之间的数据访问的节流数据带宽。在一些情况中,节流数据缓冲器120可以动态地被配置来提供可调谐的数据带宽,从而请求和/或应答的体积(即速率和/或尺寸)可以取决于计算装置100的使用情况或操作状态来修改。
在图1中,计算装置100在同一片上系统(soc)上包括经由节流数据缓冲器互相连接的两个分离的计算区域(即,分析引擎110和数据沿130)。如上文描述的,分析引擎110包括用于通用型计算的cpu114a。在一些情况中,专用型硬件单元(例如,数字信号处理器、图形处理单元、场可编程门阵列等)也可以被包括在分析引擎110中,但是为简单起见,这些没有示出在附图中。分析引擎110还可以包括本地输入/输出接口(未示出),以访问诸如数据储存器、传感器和致动器的数据源。
数据沿130还包括连接到单独的数据底板的cpu114b和远程i/o接口132,用于提供网络连通性(例如,局域网、无线局域网)。节流数据缓冲器120在计算装置110的两个分离的计算环境之间提供通道,并且变成通过其在分析引擎110和外部请求实体之间传输数据的管道。
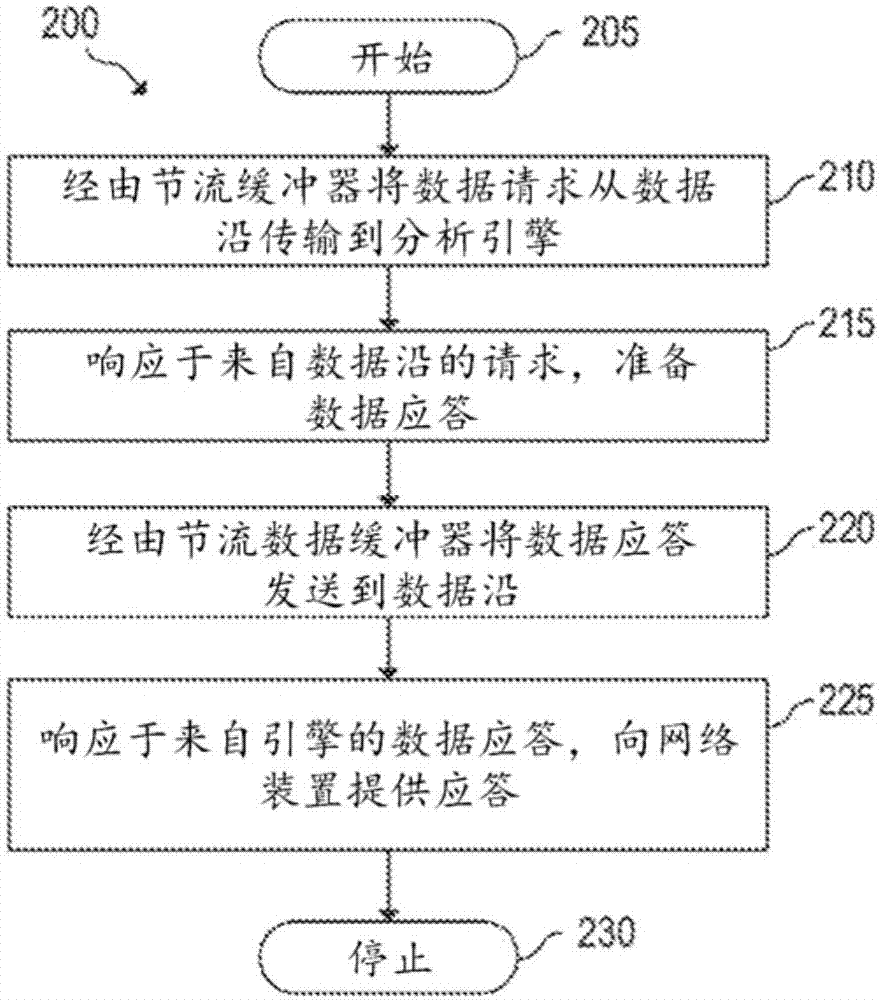
图2是用于由使用数据沿用于节流数据访问的计算装置100执行的示例方法200的流程图。尽管在下文中参考图1的计算装置100对方法200的执行进行了描述,但是可以使用其他适合于执行方法200的装置。方法200可以以储存在机器可读储存介质上的可执行指令的形式和/或以电子电路的形式来实施。
方法200可以在方框205中开始,并且持续到方框210中,其中计算装置100经由节流数据缓冲器将数据请求从数据沿传输到分析引擎。数据请求可以响应于在数据沿的远程i/o接口处从网络装置接收的请求来发起。在方框215中,计算装置100使用分析引擎来准备针对数据请求的数据应答。例如,可以使用分析引擎来响应于数据请求检索数据记录。
在方框220中,计算装置100经由节流数据缓冲器将数据请求从分析引擎发送到数据沿。在传输过程期间,节流数据缓冲器具有限制在检索数据应答时对数据沿有效的数据流的节流数据带宽。数据流可以对应于数据的体积(例如,每秒的兆数)、数据请求的体积(例如,每秒的数据请求),和/或数据请求和数据应答的体积(即,在数据请求和对应的数据应答出现时进行监控)。在方框225中,数据沿向网络装置提供数据应答。因为数据沿与分析引擎分离,网络装置的访问被限制于数据沿可访问的数据。因此,如果网络装置侵入数据沿,网络装置将仍然不能够方位分析引擎中分离的数据。方法200随后可以持续到方框230,在此方法200可以停止。
图3a是具有共享存储器322的示例节流数据缓冲器320a的方框图。如图3a中图示说明和下文描述的,节流数据缓冲器320a可以提供对分析引擎具有节流数据访问的数据沿。节流数据缓冲器320a可以基本上类似于图1的节流数据缓冲器120。
如图示说明的,节流数据缓冲器320a包括读/写分区324a、324b和共享存储器322。节流数据缓冲器320a充当提供共享存储器322的双端口存储区块,在所述共享存储器322内,请求和应答可以在数据沿和分析引擎之间通信。在该实例中,节流数据缓冲器320a经由读/写分区324a、324b在两边都提供读/写访问。限制共享存储器322的物理尺寸在流动通过节流数据缓冲器320a的数据的体积中提供自然收缩,如同为读写工作循环进行子计时(sub-clocking),以延长从共享存储器322插入或移除(即,读/写)数据所需要的时间。
在图3b中示出的另一个实例中,共享存储器被分成两个单向存储器分区322a和322b,其中每一个负责一个方向上的数据传输。在该情况中,数据应答可以由分析引擎写到写分区a326a,传输到共享存储器a322a,并且随后由数据沿从读分区a328a读取。类似地,数据请求可以由数据沿写到写分区b326b,传输到共享存储器b322b,并且随后由分析引擎从读分区b328b读取。
在再另一个实例中,可获得的缓冲器尺寸可以随着在缓冲器的部分或全部中缩放的读/写分区动态地调整。动态缓冲器能够在完全开放的访问、单向存储器位置混合以及失去所有访问之间支配访问,所有这些都可以被分析引擎动态地配置或修改。在一些情况中,动态缓冲器可以根据传输阈值进行修改。例如,动态缓冲器可以被指定为开放的,直到满足传输阈值(即,在一段时间内已经传输了预先确定的量的数据)。在该实例中,动态缓冲器可以具有由节流数据缓冲器320a的硬件实施形式限制的最大通量。
在再另一个实例中,先入/先出(fifo)缓冲器可以是从节流数据缓冲器的共享存储器分配的。fifo缓冲器提供将数据推入队列的机制,另一方可以从所述队列取出数据。请求和对此类请求的应答可以经由一对单向fifo区块在数据沿和分析引擎之间来回移动。通过限制可以保存在fifo内的数据报的尺寸和数量,fifo区块提供限制请求和应答的体积的手段。一旦满了,每侧(分析引擎和数据沿)保持数据报,直到fifo可以容纳另外的数据报。每个fifo区块的容量可以由分析引擎动态地缩放。例如,共享存储器区块可以动态地被再分配给单向fifo区块中的任一个,使得一个fifo区块能够在损坏另一个的情况下进行缩放。
图4是具有存储页控制器426的示例节流数据缓冲器420的方框图。如图4中图示说明和下文描述的,节流数据缓冲器420可以提供对分析引擎具有节流数据访问的数据沿。节流数据缓冲器420可以基本上类似于图1的节流数据缓冲器120。
如图示说明的,节流数据缓冲器420包括读/写分区424a、424b,共享存储器422,以及存储页控制器426。读/写分区424a、424b和共享存储器422可以基本上类似于上文针对图3a和3b描述的对应的部件。存储页控制器426被配置为将共享存储器422分区为一组虚拟存储空间或页。所述页的分配可以由分析引擎管理以提供一些另外的利用选项。例如,存储页可以被分配为节流数据缓冲器420的任一侧,或者同时被分配为两侧(按照双端口存储器)。每个页的可及性可以以编程方式链接到在每个页上执行的数据访问数,由此限制特定数据报可以被访问的次数。一旦被利用,页可以被解除分配,并且物理存储器被再分配为另一页,或者直到需要之前都保留为暂搁不用的。在一些情况中,大的数据应答可以被放置在共享存储器422的特定页内(确定大小以匹配应答的规模),其中数据沿提供有读取数据的一次机会,在这之后,经由合适的页的解除分配,应答将是不能访问的。
前述公开描述了一些使用数据沿用于节流数据访问的实例。以该方式,本文所公开的实例能够通过经由节流数据缓冲器连接两个分离的计算环境(分析引擎和数据沿)来进行节流数据访问,其中数据可以被保留在分离的数据沿上,以供网络计算装置进行收集。
- 还没有人留言评论。精彩留言会获得点赞!