一种文档文字的深度处理方法与流程
本发明涉及翻译技术领域,具体地说涉及一种文档文字的深度处理方法。
背景技术:
从上世纪80年代中期开始,基于语料和多引擎机译方法的广泛运用,翻译软件的性能和效率有了明显提高,各式各样的翻译软件如雨后春笋般问世。采用预先编写的软件程序翻译,极大提高了文本的翻译速度。但由于语言表达的特殊性,翻译软件的翻译质量一直屡遭诟病,翻译软件的原理是将两种语言的语义一一对应存储,翻译时机械调用替换,由于语言表达的多样性,每个字、单词、词组或单句往往对应不止一个意思,完全使用翻译软件所得到的译文通常不能正常表达原文含义,因此人工翻译仍然是获得高翻译质量的保证。
现有技术中,针对一个项目或长篇文档来说,往往是在一个团队中分成多份来翻译,但由于译员翻译习性的不同,往往会出现不同译员翻译相同含义的一句话而导致译文不一致的情况。另外,这种采用团队分成多份翻译的方式,导致译员经常重复翻译具有相同含义的单词、词组或单句,不仅大幅增大了译员的翻译强度,还极大地降低了翻译效率。
技术实现要素:
本发明的目的在于解决现有技术中存在的上述问题,提供一种文档文字的深度处理方法,本发明能够更进一步地在处理文档前预先深度去除文档中重复的单词、词组或单句,同时参考匹配的专有术语词汇,从而达到简化译员翻译量、提高翻译效率和提高翻译前后准确率的目的。
为实现上述目的,本发明采用的技术方案如下:
一种文档文字的深度处理方法,其特征在于包括以下步骤:
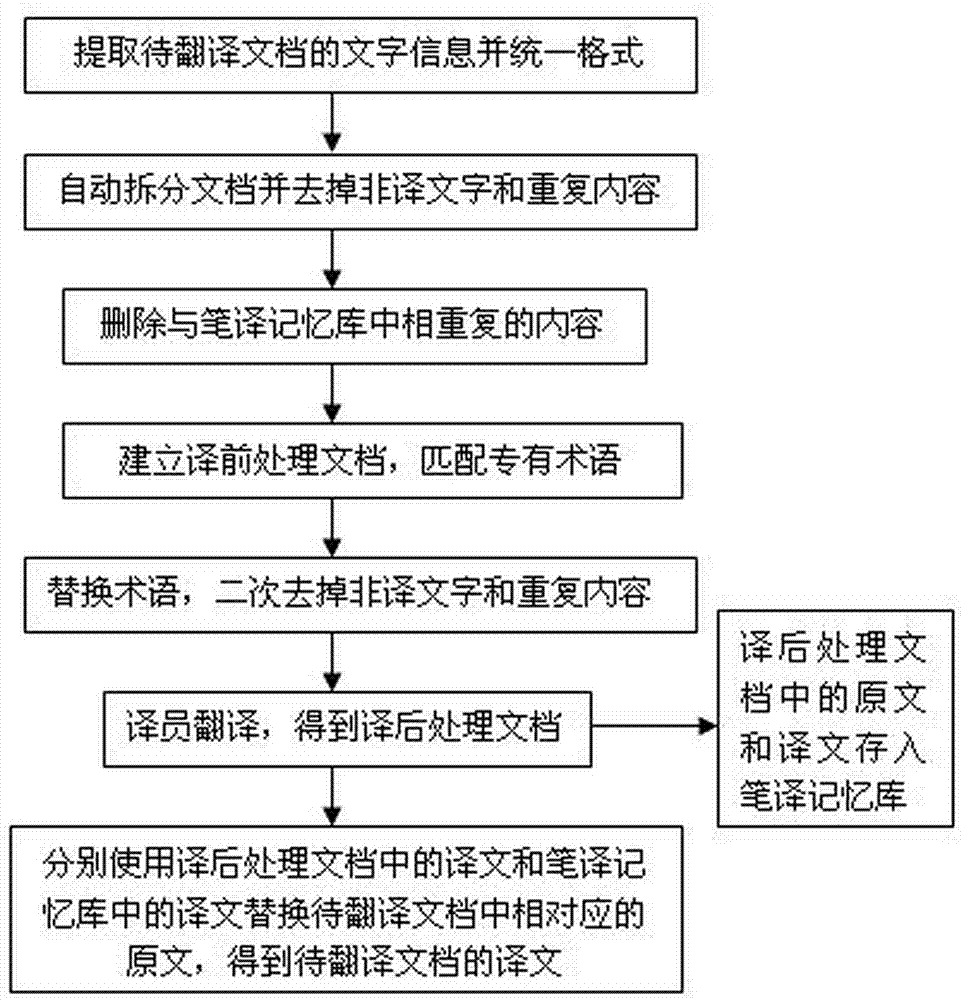
(1)、提取待翻译文档中的文字信息,并统一文字信息的格式,得到格式统一的文档;
(2)、对格式统一的文档进行拆分,将其拆分成以单词、词组、单句中的任意一种或几种为最小单位的待译文字数据集合,去掉非译文字后再去掉待译文字数据集合中重复的待译文字数据,然后将剩下的每一个待译文字数据依次与笔译记忆库中的内容进行比对,而后删除待译文字数据集合中与笔译记忆库中相重复的内容;其中,所述的笔译记忆库中设置有原文列一和译文列一,原文列一中存储有已译文档的原文,译文列一中对应存储有已译文档的译文;
(3)、建立一个译前处理文档,并在该译前处理文档中设置原文列、译文列和专有术语列,先将经步骤(2)处理后的待译文字数据集合中的每一个待译文字数据按顺序复制到原文列中,再根据预先制作的专有术语表,将每一个待译文字数据中涉及到的专有术语的原文和译文写入对应的专有术语列,得到匹配有专有术语的译前处理文档;
(4)、提取译前处理文档中原文列的待译文字数据集合,同时提取专有术语表中的原文和译文的文字信息并建立专有术语表文字数据集合,将译前处理文档中原文列包含的专有术语表中的原文文字数据替换成专有术语表中的译文文字数据,替换后得到译文和原文混杂的原文列文字数据,使用步骤(2)中的去掉重复工序和比对工序对此文字数据进行二次处理,得到最终的译前处理文档;
(5)、由译员对最终的译前处理文档中原文列对应的所有待译文字数据进行翻译,并将译文填写至对应的译文列,得到译后处理文档;
(6)、先将待翻译文档中与译后处理文档中的原文列相同的待译文字数据替换成译文,再使用原文列一中原文所对应的译文列一中的译文替换待翻译文档中出现在原文列一中的原文,最后得到与待翻译文档相同格式的译文。
所述的专有术语表包括专有单词术语表、专有词组术语表和专有单句术语表。
所述的处理方法中涉及到的文档均为Office文档。
所述步骤(2)中采用换行符、标点符号、空格中的一种或几种的组合对文档自动进行拆分。
所述步骤(2)中的非译文字包括标点符号、数字、单个字母、非原文文字的文字中的一种或几种的组合。
所述步骤(6)中的译后处理文档中的原文列和译文列以一一对应的方式存储在笔译记忆库中,存储后的已译文档可导出。
采用本发明的优点在于:
一、本发明的重点改进之处在于直接去掉“不完全重复”中因非译文字不同而不同的原文文字,增加了去重文字的比例,较同类翻译工具更为彻底、更为精准。译员在笔译过程中,只需笔译未重复的待译文字数据即可完成整篇文档的处理,大幅减少了笔译工作量,缩短了笔译工作时间,大大提高了笔译工作效率。与平均去重率为30%的现有技术相比,本发明可达到50%—60%的去重率。
二、本发明在译前和译后的格式统一,排版难度低,可批量化处理,处理量达到24小时三千万字,并且兼容六十多种语言。
三、本发明适用Office系列格式文档,门槛低,无需其他CAT(翻译辅助)工具。
四、本发明在处理过程中锁定常见翻译文字,能够实现模板化生产,减少待翻译文字的灵活性,增强机器智能翻译的可能性。
五、本发明无需服务器进行数据交互,仅仅一台电脑就可实现文档文字的处理。
附图说明
图1为本发明的流程图;
图2为本发明步骤(1)的示意图;
图3为本发明步骤(2)中拆分文档的示意图;
图4为本发明步骤(2)中去掉非译文字的示意图;
图5为本发明步骤(2)中去掉重复待译文字数据的示意图;
图6为本发明步骤(2)中去掉与笔译记忆库中重复待译文字数据的示意图;
图7为本发明步骤(3)中匹配专有术语的示意图;
图8为本发明步骤(3)中匹配有专有术语后的译前处理文档;
图9为本发明步骤(4)中得到译文和原文混杂的原文列文字数据的示意图;
图10为本发明步骤(4)中进行二次处理的示意图;
图11为本发明步骤(5)中得到的译后处理文档;
图12为本发明步骤(6)中使用译后处理文档中的译文替换原文的示意图;
图13为本发明步骤(6)中使笔译记忆库中的译文替换原文的示意图。
具体实施方式
一种文档文字的深度处理方法,包括以下步骤:
(1)、提取待翻译文档中的文字信息,待翻译文档为Word文档或Excel文档等,然后通过清除格式功能或复制替换功能等对提取到的文字信息进行处理,统一文字信息的格式,从而得到格式统一的文档,如附图2所示。
(2)、采用换行符、标点符号、空格中的一种或几种的组合等方式对格式统一后的文档自动进行拆分,将其拆分成以单词、词组、单句中的任意一种或几种为最小单位的待译文字数据集合,如附图3所示。拆分后,先通过文字、标点符号、数字、字母等进行类型分类,去掉文档中的非译文字,如附图4所示,所述的非译文字包括标点符号、数字、单个字母、非原文文字的文字中的一种或几种的组合。去掉非译文字后,再通过排序比对去掉待译文字数据集合中重复的待译文字数据,如附图5所示。然后将剩下的每一个待译文字数据依次与笔译记忆库中的内容进行比对,而后删除待译文字数据集合中与笔译记忆库中相重复的内容,如附图6所示。其中,所述的笔译记忆库中设置有原文列一和译文列一,原文列一中存储有已译文档的原文,译文列一中对应存储有已译文档的译文,比对时主要是将待译文字数据中的内容与笔译记忆库中原文列一对应的原文进行比对。
本步骤中,所述的非译文字是指与待翻译文档中的文字信息不属于同一种类的文字及其它符号等,例如,待翻译文档为中文,那么非译文字为除中文文字之外的文字及符号等。
其中,本步骤中所述的将文档拆分成以单词、词组、单句中的任意一种或几种为最小单位的待译文字数据集合,拆分方式主要是根据待翻译文档类型所决定的,具体包括以下几种拆分方式:
a、将文档拆分成以单词为最小单位的待译文字数据集合,这种方式主要用于财务报表、词典和产品清单等文档的处理,即待译文字数据集合由单词组成,待译文字数据集合中的每一个待译文字数据对应一个单词。
b、将文档拆分成以词组为最小单位的待译文字数据集合,这种方式主要用于财务报表、词典和产品清单等文档的处理,即待译文字数据集合由词组组成,待译文字数据集合中的每一个待译文字数据对应一个词组。
c、将文档拆分成以单句为最小单位的待译文字数据集合,这种方式主要用于文稿类等文档的处理,即待译文字数据集合由单句组成,待译文字数据集合中的每一个待译文字数据对应一个单句。
d、将文档拆分成以单词为最小单位和词组为最小单位的待译文字数据集合,这种方式主要用于文稿类等文档的处理,即待译文字数据集合由单词和词组组成,待译文字数据集合中的每一个待译文字数据对应一个单词或词组。
e、将文档拆分成以单词为最小单位和单句为最小单位的待译文字数据集合,这种方式主要用于文稿类等文档的处理,即待译文字数据集合由单词和单句组成,待译文字数据集合中的每一个待译文字数据对应一个单词或单句。
f、将文档拆分成以词组为最小单位和单句为最小单位的待译文字数据集合,这种方式主要用于文稿类等文档的处理,即待译文字数据集合由词组和单句组成,待译文字数据集合中的每一个待译文字数据对应一个词组或单句。
g、将文档拆分成以单词为最小单位、词组为最小单位和单句为最小单位的待译文字数据集合,这种方式主要用于文稿类等文档的处理,即待译文字数据集合由单词、词组和单句组成,待译文字数据集合中的每一个待译文字数据对应一个单词、词组或单句。
(3)、建立一个Word或Excel格式的译前处理文档,并在该译前处理文档中设置原文列、译文列和专有术语列,先将经步骤(2)处理后的待译文字数据集合中的每一个待译文字数据按顺序复制到原文列中,再根据预先制作的专有术语表,将每一个待译文字数据中涉及到的专有术语的原文和译文写入对应的专有术语列,如附图7所示,最后得到匹配有专有术语的译前处理文档,如附图8所示。其中,专有术语表由译员根据待翻译文档所属的领域或行业自行制作。
(4)、提取译前处理文档中原文列的待译文字数据集合,同时提取专有术语表中的原文和译文的文字信息并建立专有术语表文字数据集合,将译前处理文档中原文列包含的专有术语表中的原文文字数据替换成专有术语表中的译文文字数据,替换后得到译文和原文混杂的原文列文字数据,如图9所示;再使用步骤(2)中的去掉重复工序和比对工序对此文字数据进行二次处理,得到最终的译前处理文档如图10所示。
(5)、将匹配有专有术语的译前处理文档下发给译员,由译员对译前处理文档中原文列对应的所有待译文字数据进行翻译,并将翻译后的译文填写至对应的译文列,得到译后处理文档,如附图11所示;
其中,译后处理文档中的原文列和译文列以一一对应的方式存储在笔译记忆库中,供下次处理文档前在步骤(2)进行比对使用,且存储后的已译文档可导出成其它多种格式,如PDF格式等。
(6)、先将待翻译文档中与译后处理文档中的原文列相同的待译文字数据替换成译文,如附图12所示,再使用原文列一中原文所对应的译文列一中的译文替换待翻译文档中出现在原文列一中的原文,最后得到与待翻译文档相同格式的译文,如附图13所示。
本发明中,所述的专有术语表包括专有单词术语表、专有词组术语表和专有单句术语表,即将专有术语分为单词、词组和单句三种,通过样的分类方式,能够进一步减小人工翻译量。
本发明在处理过程中涉及到的文档均为Office文档,所有其它相同格式的文档均可处理,只要满足计算机一级资质的人员均可以使用本方法。
本发明在处理过程中,得到的译前处理文档采用USB或网络转发的方式发送给译员处理,译员处理后的同样以USB或网络转发的方式发送给文档分配主管,处理过程简单方便。
本申请与专利号为“201610122855.0”,发明名称为“一种文档文字的处理方法”的申请人和发明人均相同,申请人经过大量实验证明,上述专利的平均去重率可达40%,而本发明的平均去重率可达到50%—60%,其技术效果是远远优于现有技术和上一专利技术。
此发明是以上述技术为基础的进一步深化创新技术,具有实质性的进步和颠覆行业的巨大改革。同时,改变了国外翻译辅助文字处理工具垄断中国翻译行业长达15年的局面。
- 还没有人留言评论。精彩留言会获得点赞!