基于角点匹配的医学图像分类方法与流程
本发明属于医疗健康数据挖掘领域,具体涉及一种基于角点匹配的医学图像分类方法。
背景技术:
医学图像能很好地展示人体器官的空间结构,同时能较为清楚地显示病人身体的病变信息,为医生的诊断提供可靠依据。医学影像技术的成熟发展促进了医学图像数据的急速增长,这也促使一些存储医学图像的系统的出现,例如,影像归档和通信系统(Picture Archiving and Communication Systems,PACS)、医学数字成像和通信(Digital Imaging and Communications in Medicine,DICOM)等。这些系统中保存大量的患者信息、患者病情的发展信息以及医生对患者做出的一系列珍贵的诊断等。通过找到系统中与患者图像相似的医学图像、发现和患者患有相同或相似病理情况的病人,然后通过以往医生对以往此类病人做出的决策结果,来评估此患者的病情,为医生诊断提供参考意见,辅助医生进行诊断。因此,基于医学图像的数据挖掘技术,尤其是医学图像的分类,已经成为医疗健康大数据的一个热点研究。
目前已经存在一些针对医学图像的分类方法。Nanthagopal等人提取二级小波纹理图像的6个特征,利用SVM对脑部CT图像进行分类,将其分为良性和恶性两类。荣晶施等人提出一种基于对称性理论的脑部图像三阶段分类算法。此方法根据脑中垂线将图像分为左、右脑半球,首先依据左、右脑半球的灰度直方图差异将脑部图像分为正常图像和异常图像;若是异常图像,根据医学图像固有的不确定性对左、右脑半球的纹理图像进行匹配,判断出图像是左侧或者右侧异常;接着,将分其分为良性或恶性图像。
以上方法均是对医学图像进行纹理化,接着提取纹理图像的特征,根据纹理图像的特征对医学图像进行分类。纹理图像提取了灰度图像的重要特征,但其仍包含很多非关键的、冗余信息。为此WuPing等人提出基于角点的KAP有向图模型,并根据KAP图的匹配对医学图像进行分类。此方法的思想如下:给定待分类的医学图像和带标签的医学图像集(图像标签为正常或者异常),首先对每幅图像提取角点;然后根据角点和其它角点的空间关系,对每幅图像建立KAP有向图,其中每个顶点具有一个重要性值和可移动范围,得到一个待匹配图和模板图集;接着提出基于KAP的粗粒度和细粒度顶点匹配方法:在粗粒度匹配时,将待匹配图和每个模板图进行顶点匹配,若匹配图中的顶点在模板图的顶点的可移动范围内,则此对顶点对为匹配顶点对,从而得到待匹配图和每个模板图的一个匹配顶点对序列,接着根据此匹配顶点对序列进行细粒度匹配;最后对每一个匹配顶点对序列中属于模板图的顶点集的重要性求和作为两个图的相似值,找出和待分类图相似的前t个图,统计这t个图对 应的图像的标号,利用多数服从少数的投票决策方法将带分类图像分为正常或异常图像。此方法存在如下不足:(1)效率低。粗粒度匹配仅用到角点的可移动范围性质,而没有用到角点和其他角点的空间关系,因此这个过程中KAP图的建立增加了算法的执行时间和复杂性。(2)丢失部分重要的匹配顶点对。这是由于当粗粒度匹配过程中,若顶点对出现一对多的情况,此方法采用的最近顶点分配策略导致部分重要匹配顶点对的丢失。(3)待分类图和模板图的相似度只考虑匹配顶点对,而忽视了两幅图像中未匹配的顶点。
为此,本发明提出一种基于角点最大匹配序列的医学图像分类方法。此方法通过以下策略解决了基于KAP有向图模型的医学图像分类方法的不足:
(1)本发明给出一个基于角点最大匹配的医学图像分类方法。
(2)本发明给出了一对一最大匹配角点对序列的定义。
(3)本发明将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转化为求二分图最大匹配的问题,并用匈牙利方法求解这一问题,避免了部分匹配角点对的丢失。
(4)本发明给出一个基于公共K近邻匹配角点对序列的医学图像的相似值的计算公式,此公式既考虑了匹配角点对序列,也考虑了未匹配上的角点。
技术实现要素:
本发明的目的是提出一个有效提高结果的准确度的基于角点匹配的医学图像分类方法。
本发明的目的是这样实现的:
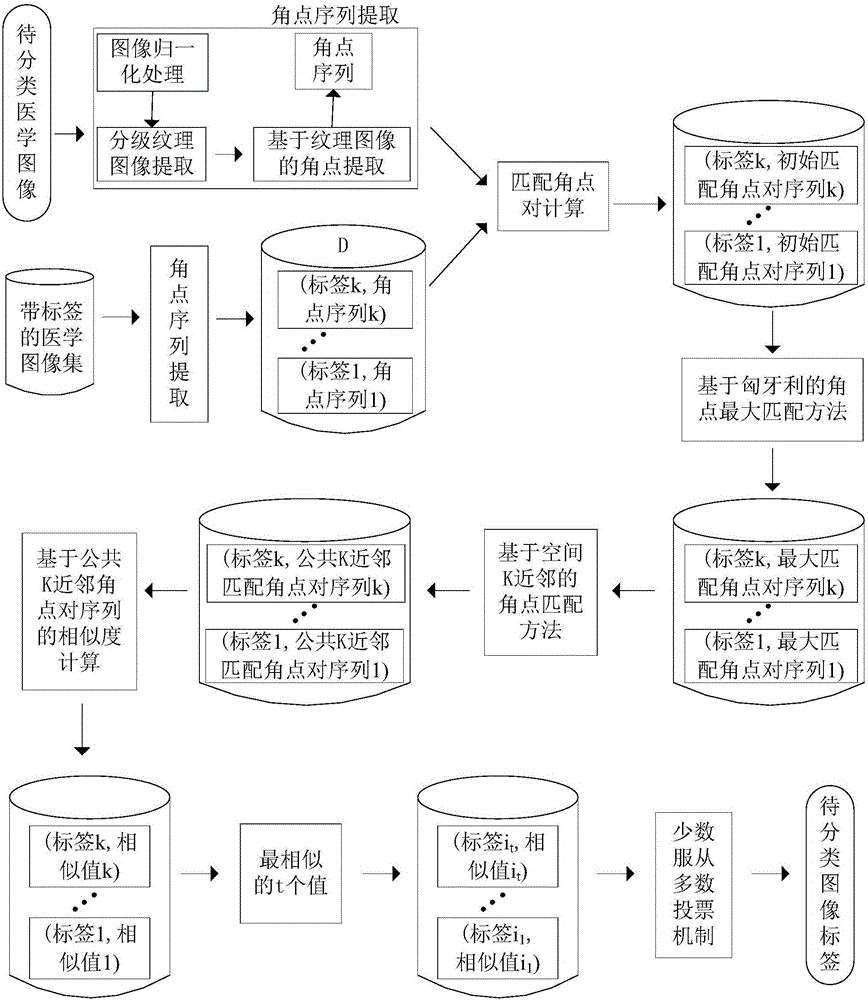
本发明包括如下步骤:
(1)待分类的医学图像I提出分类请求:针对已存在的带标签的k个医学图像对应的角点序列集D={(Li,Ci)|i∈{1,…,k}},I请求给出类标号,其中Li为医学图像Ii的类标签,Ci={(xjCi,yjCi,rjCi)|jCi∈{1,…,mCi}为角点的标号为第Ii的角点序列,xjCi,yjCi和rjCi分别为Ci中第jCi个角点的横坐标、列坐标及其重要性值;
(2)提取I的角点序列C:对I进行预处理得到归一化后的图像;对图像进行分级纹理提取,进行角点提取,得到I的角点序列C={(xj,yj,rj)|j∈{1,…,n}};
(3)初始匹配角点对序列集DS的计算:将C与Ci的角点进行匹配,得到初始匹配角点对序列Si={[pjS,qjSi]|pjS∈C,qjSi∈Ci},从而得到DS={(Li,Si)|i∈{1,…,k}};
(4)最大匹配角点对序列集DM的计算:初始匹配角点对序列Si中存在一对多的匹配角点对,给出一对一的最大匹配角点对序列的定义;将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转为求二分图中最大匹配的问题;利用匈牙利算法求解二分图最大匹配问题,得到的结果为一对一的最大匹配角点对序列Mi={[pjM,qjMi]|pjM∈C,qjMi∈Ci}, 从而得到DM={(Li,Mi)|i∈{1,…,k}};
(5)公共K近邻匹配角点对序列集DT的计算:根据Mi中匹配角点对的空间K近邻角点的分布,找到并去除所有异常匹配角点对,得到公共K近邻匹配角点对序列Ti,进而得到DT={(Li,Ti)|i∈{1,…,k}};
(6)计算和I最相似的t幅医学图像:给出两幅医学图像的相似值的计算公式SIMi,计算I与每幅图像的相似值,从而得到和I最相似的t幅图像;
(7)根据投票机制输出I的类标签:根据t幅图像的标签对所有类标签{L1,…,Lk}进行投票,得票个数最多的类标签为I的标签。
所述的一对一的最大匹配角点对序列为:给定一个存在一对多的匹配角点对序列Si={[p1S,q1Si],…,[pjS,qjSi],…},如果{M1,…,Mi,…}是Si对应的一对一的匹配角点对序列集合,那么其对应的一对一的最大匹配角点对序列Mi={[p1M,q1Mi],…,[pjM,qjMi],…}满足如下条件:(1)pjM和qjMi在Mi中均只能出现一次;(2)Mi中的所有匹配角点对的距离之和是所有一对一匹配角点对序列中最小的;(3)Mi中匹配角点对的个数是最多的。
所述的将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转为二分图中求最大匹配的问题的具体过程为:给定一个存在一对多的匹配角点对序列Si={[p1S,q1Si],…,[pjS,qjSi],…},首先将每个角点pjS建立为顶点vjS∈V1,每个角点qjSi建立为一个顶点vjSi∈V2,从而得到顶点集V=V1∪V2;其次,将每个角点对[pjS,qjSi]对应的顶点对之间建立边(vjS,vjSi),从而得到边集E;将每个角点对[pjS,qjSi]之间的距离作为边(vjS,vjSi)上的属性ej,得到属性集WE;最后,得到一个二分图Gi=(V,E,WE)。
所述的相似值计算公式表示医学图像I与Ii之间的相似值;其中,
本发明的有益效果在于:
本发明提出了一对一的最大匹配角点对序列的定义,给出了将一对多的匹配角点对序列中求解一对一的最大匹配角点对序列问题转化为求二分图最大匹配的问题并利用匈牙利算法进行求解;其次本发明给出一个基于公共K近邻角点对序列的医学图像的相似值的计算公式,此公式既考虑了匹配角点对序列,也考虑了未匹配上的角点,提高了角点匹配的准确度。本发明能够有效地提高分类结果的准确度。
附图说明
图1是基于角点最大匹配的医学图像分类方法的流程图;
图2是医学图像I的预处理实例;
图3是一个建立的二分图实例;
图4是一个一对一的最大匹配角点对序列实例。
具体实施方式
下面结合附图对本发明做进一步描述。
本发明属于医疗健康数据领域,具体涉及一种基于医学领域知识和角点匹配的医学图像分类方法。本发明包括待分类的医学图像I提出分类请求:针对带标签的k个医学图像对应的角点序列集D={(Li,Ci)|i∈{1,…,k}},原始医学图像I请求给出类标号;提取I的角点序列C;初始匹配角点对序列集DS的计算;最大匹配角点对序列集DM的计算;公共K近邻匹配角点对序列集DT的计算;计算和I最相似的t幅医学图像;根据投票机制输出I的类标签。本发明给出了一对一最大匹配角点对序列的定义,并给出了将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转化为求二分图最大匹配的问题,并用匈牙利算法进行求解;接着给出一个基于公共K近邻角点对序列的医学图像的相似值的计算公式,此公式既考虑了匹配角点序列,也考虑了未匹配上的角点。本发明能够有效地提交分类结果的准确度。
本发明包括如下步骤:
(1)待分类的医学图像I提出分类请求:针对已存在的带标签的k个医学图像对应的角点序列集D={(Li,Ci)|i∈{1,…,k}},原始医学图像I请求给出类标号。其中Li为医学图像Ii的类标签,Ci={(xjCi,yjCi,rjCi)|jCi∈{1,…,mCi}为角点的标号}为Ii的角点序列,xjCi,yjCi和rjCi分别为Ci中第jCi个角点的横坐标、列坐标及其重要性值。rjCi∈[0,1]被赋值为此角点在纹理图像中的像素灰度值,它表明灰度值越大的角点越重要。
(2)提取I的角点序列C:首先,对I进行预处理得到归一化后的图像,具体包括:提取I的外轮廓,旋转至垂直方向,按外轮廓的外接矩阵裁剪图像并归一化到统一大小。其次,对图像进行分级纹理提取,得到纹理图像。接着,利用Harris对纹理图像进行角点提取,得到I的角点序列C={(xj,yj,rj)|j∈{1,…,n}}。
(3)初始匹配角点对序列集DS的计算:将C与Ci的角点进行匹配,得到初始匹配角点对序列Si={[pjS,qjSi]|pjS∈C,qjSi∈Ci},从而得到DS={(Li,Si)|i∈{1,…,k}}。
(4)最大匹配角点对序列集DM的计算:Si中存在一对多的匹配角点对,为此,本发明首先给出一对一的最大匹配角点对序列的定义;其次,将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转为二分图最大匹配的问题;最后,利用匈牙利算法求解二分图的最大匹配,得到一对一的最大匹配角点对序列Mi={[pjM,qjMi]|pjM∈C,qjMi∈Ci},从而得到DM={(Li,Mi)|i∈{1,…,k}}。
(5)公共K近邻匹配角点对序列集DT的计算:根据Mi中匹配角点对的空间K近邻角点的分布,找到并去除所有异常匹配角点对,得到公共K近邻匹配角点对序列Ti,进而得到DT={(Li,Ti)|i∈{1,…,k}}。
(6)计算和I最相似的t幅医学图像:首先,给出两幅医学图像的相似值的计算公式SIMi,其次,计算I与每幅图像的相似值,从而得到和I最相似的t幅图像。
(7)根据投票机制输出I的类标签:根据t幅图像的标签对所有类标签{L1,…,Lk}进行投票,得票个数最多的类标签为I的标签。
所述的匹配角点对的定义为:给定两个角点p1=(x1,y1,r1)和p2=(x1,y1,r1),若存在(x1-x2)2+(y1-y2)2≤(1/r1+1/r2)2,则称p1和p2是匹配角点对,记为[p1,p2]。
所述的一对一的最大匹配角点对序列的定义为:给定一个存在一对多的匹配角点对序列Si={[p1S,q1Si],…,[pjS,qjSi],…},其对应的一对一的最大匹配角点对序列Mi={[p1M,q1Mi],…,[pjM,qjMi],…}满足如下条件:(1)pjM和qjMi在Mi中都只能出现一次;(2)Mi中的所有匹配角点对的距离之和是最小的;(3)Mi中匹配角点对的个数是最多的。
所述的将在一对多的匹配角点对序列中求解一对一的最大匹配角点对序列的问题转为二分图最大匹配的问题的具体过程为:给定一个存在一对多的匹配角点对的序列Si={[p1S,q1Si],…,[pjS,qjSi],…},首先将每个角点pjS建立为一个顶点vjS∈V1,每个角点qjSi建立为一个顶点vjSi∈V2,从而得到顶点集V=V1∪V2;其次,将每个角点对[pjS,qjSi]对应的顶点对之间建立边(vjS,vjSi),从而得到边集E;将[pjS,qjSi]之间的距离作为(vjS,vjSi)上的属性ej,得到属性集WE;最后,得到一个二分图Gi=(V,E,WE)。
所述的找到并去除所有异常匹配角点对的具体做法为:将Mi拆分为两个角点序列,对于其中一个角点序列,根据它的每个角点的K近邻角点,建立两个|Mi|维的方阵:入度矩阵MI1和出度矩阵MO1,若第i个角点是第j个角点的K近邻角点,则令MI1[i,j]=1且MO1[j,i]=1,否则令MI1[i,j]=0且MO1[j,i]=0。按照上述步骤对另一个角点序列建立方阵MI2和MO2。其次,建立差值矩阵ΔMI=|MI1-MI2|和ΔMO=|MO1-MO2|,它们表示匹配角点对的周围K近邻角点的分布差异。再次,根据差值矩阵去除异常匹配角点对。具体为:异常匹配角点对的K近邻角点差异通常较大,因此利用公式(1)找到异常匹配角点对的下标jout,将[(xjoutM,yjoutM,rjoutM),(xjoutMi,yjoutMi,rjoutMi)]从Mi中去除,得到新的匹配角点序列Ti。接着,令Mi=Ti,重复上述过程,直到找不出jout为止。
且
所述的相似值计算公式SIMi表示待分类医学图像I与带标签的医学图像Ii之间的相似值,计算方法如公式(2):
且
其中SDj是第j个匹配角点对的匹配度,它表示两个角点距离越近它们越匹配;Wi是权重,表示两幅图像提取出来的初始角点个数越一样,其公共K近邻匹配角点序列越能表示它们的相似度,其中n是从I中提取的初始角点的个数,mCi是第i个医学图像中初始角点的个数。
下面以脑部CT图像为例,结合附图和具体实施例对本发明作进一步的说明:
(1)待分类的医学图像I提出分类请求:针对已存在的带标签的k个医学图像对应的角点序列集D={(Li,Ci)|i∈{1,…,k}},原始医学图像I,如图2(a),请求给出类标号。
(2)提取I的角点序列C:首先,对I进行预处理得到归一化后的图像,预处理步骤主要包括:利用canny算子提取I的外轮廓,利用LiaoC.C.等在Computers in biology and medicine发表的论文Automatic recognition of midline shift on brain CT images中提出的方法矫正大脑角度至垂直方向,按外轮廓的外接矩阵裁剪图像并归一化到统一大小(285×260),
得到归一化后的图像,如图2(b)。其次,按照HaiweiPan等在IEEE Journal of Biomedical and Health Informatics发表的论文Brain CT Image Similarity Retrieval Method Based on Uncertain Location Graph中提到的方法对图像进行分级纹理提取,得到纹理图像,如图2(c)。接着,利用Harris对纹理图像进行角点提取,得到I的角点序列C={(xj,yj,rj)|j∈{1,…,n}},提取的角点如图2(d)中的白色像素点。
(3)初始匹配角点对序列集DS的计算:令对于C中每一个角点pjC=(xjC,yjC,rjC)以及Ci中的每一个角点qjCi=(xjCi,yjCi,rjCi),如果存在(xjC-xjCi)2+(yjC-yjCi)2≤(1/rjC+1/rjCi)2,则称pjC和qjCi为匹配角点对,记为[pjC,qjCi],将[pjC,qjCi]加入到初始匹配角点对序列Si中,从而将(Li,Si)加入到DS中。
(4)最大匹配角点对序列集DM的计算:Si中存在一对多的匹配角点对,为此,本发明首先将一对多的匹配角点对序列Si进行建模,得到一个二分图,如图3显示的是一个二分图模型中的一部分,记为Gi=(V,E,WE),其中V=V1∪V2,V1={p1,p2,p3,p4,p5,p6,p7},V2={q1,q2,q3,q4,q5,q6},E={(p1,q1),(p2,q3),(p3,q1),(p3,q3),(p4,q2),(p4,q5),(p5,q6),(p6,q4),(p7,q5),(p7,q6)}且WE={e1,e2,e3,e4,e5,e6,e7,e8,e9,e10};其次,利用匈牙利算法求解二分图最大匹配问题,得到一对一的最大匹配角点对序列Mi={[pjM,qjMi]|pjM∈C,qjMi∈Ci},如图4,显示的是根据匈牙利算法对图3中的二分图求解最大匹配得到的结果,其中有边的匹配角点对集合为Mi={[p1,q1],[p2,q3],[p4,q2],[p5,q6],[p6,q4],[p7,q5]};接着,将(Li,Mi)加入到DM。
(5)公共K近邻匹配角点对序列集DT的计算:令K=4,首先,将Mi拆分为两个角点 序列MC1={p1,p2,p4,p5,p6,p7}和MC2={q1,q3,q2,q6,q4,q5}。对于MC1,根据它的每个角点4近邻角点,建立两个6-维的方阵MI1和MI2。若中第i个角点是第j个角点的4近邻角点,则令MI1[i,j]=1且MI1[j,i]=1,否则令MI1[i,j]=0且MI1[j,i]=0。按照上述步骤对角点序列MC2建立MI2和MO2。其次,分别建立入度差值矩阵ΔMI=|MI1-MI2|和出度差值矩阵ΔMO=|MO1-MO2|,它们分别表示匹配角点对的周围4近邻角点的入度和出度分布差异。再次,根据入度和出度差值矩阵去除Mi中的异常匹配角点对,具体为:异常匹配角点对的4近邻角点差异通常较大,根据公式(1)计算Mi中最有可能是异常匹配角点对的下标jout,从Mi中去除第jout个匹配角点对,得到新的匹配角点序列Ti。接着,令Mi=Ti,重复上述过程,直到找不出jout为止,此时得到的Ti为公共4近邻匹配角点对序列,继而将(Li,Gi)加入到DT中。
(6)计算和I最相似的t幅医学图像:首先,根据公式(2)计算I和医学图像集中每个医学图像的相似值,得到{sim1,…,simk},从这k个相似值中找到前t个最大的相似值和对应的t幅医学图像。
(7)根据投票机制输出I的类标签:根据t幅图像的标签对所有类标签{L1,…,Lk}进行投票,得票个数最多的类标签为I的标签。
- 还没有人留言评论。精彩留言会获得点赞!