基于两阶段包裹式特征选择的软件缺陷预测方法与流程
本发明属于软件质量保障领域,具体涉及一种基于两阶段包裹式特征选择的软件缺陷预测方法。
背景技术:
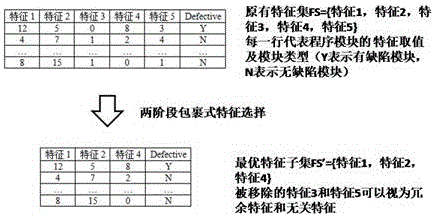
:软件缺陷预测通过分析软件历史仓库,构建缺陷预测模型,来预先识别出被测项目内的潜在缺陷程序模块,通过将更多测试资源优先分配到这些程序模块,可以达到优化测试资源分配,提高软件产品质量的目的。但在搜集缺陷预测数据集时,若考虑多个度量元(即特征),则容易造成数据集存在维数灾难问题,即数据集内会含有无关特征和冗余特征。其中冗余特征是指大量或完全重复了其他单个或多个特征中含有的信息,而无关特征则对采用的分类算法不能提供任何的帮助。特征选择是一种有效方法,可以尝试识别并移除特征空间中的无关特征和冗余特征,最终达到降低数据集的维数、减少训练集的规模、缩短训练时间、以及提高缺陷预测模型的性能。特征选择方法在研究时主要存在两个难点:(1)特征交互问题。该问题是指特征之间存在两两交互、三三交互甚至更高强度的交互。一方面,一个特征可能跟类标的关联度不大,但如果该特性与其他特征存在互补关系,则可以显著提升分类方法的性能,因此,移除这类特征会造成选出的特征子集并不是最优的。另一方面,某一特征虽然与类标存在很强的相关性,但若与其他特征放在一起时,可能会具有一定冗余性,因此会造成分类方法性能的下降。(2)搜索空间大。搜索空间会随着特征数的增加呈指数级增长(即相对于n个特征,其可能的特征子集数为2n个)。在大部分情况下,搜索所有可能的子集是不可行的。目前常见的特征选择方法可以简单分为包裹式方法和过滤式方法。其中包裹式方法借助预先指定的分类方法的预测性能来决定选择出的特征子集,虽然可以取得更好的预测性能,但以增加计算开销为代价。而过滤式方法则根据数据集的特征完成特征的选择,因此与选择的分类方法无关,通用性更好且计算开销较小,但性能并不保证。在软件缺陷预测问题中,模型的性能非常重要,因此发明重点关注包裹式特征选择方法。除此之外,由于软件缺陷在被测项目内部的分布存在类不平衡问题,即大部分缺陷都集中存在于少数程序模块之内。因此搜集到的缺陷预测数据集存在明显的类不平衡问题,即缺陷模块(多数类)的数量要远远少于无缺陷模块(少数类)的数量。因此在设计包裹式特征选择方法的同时,需要考虑类不平衡问题。综上所述,为有效缓解缺陷预测数据集内存在的维数灾难问题和类不平衡问题,有必要设计出一种有效的基于包裹式特征选择的软件缺陷预测方法。本发明由此而生。技术实现要素:本发明的目的在于提供基于两阶段包裹式特征选择的软件缺陷预测方法,一方面可以有效识别并移除缺陷预测数据集内的冗余特征和无关特征,另一方面可以有效缓解缺陷预测数据集内的类不平衡问题;具有缺陷预测模型构建时间短和模型预测性能高的优点,从而可以更为精准的预测出被测项目内的潜在缺陷程序模块,最终达到优化测试资源分配和提高软件产品质量的目的。为实现上述目的,本发明采用如下的技术方案:一种基于两阶段包裹式特征选择的软件缺陷预测方法,包括如下步骤:(1)挖掘软件项目的版本控制系统和缺陷跟踪系统,从中抽取程序模块;所述程序模块的粒度根据缺陷预测的目的可设置为文件、包、类或函数;随后对上述每个程序模块,通过分析缺陷跟踪系统内的缺陷报告信息进行标记;最后基于软件代码复杂度或软件开发过程分析,设计出与软件缺陷存在相关性的度量元,并借助这些度量元完成对每个程序模块的度量;通过对程序模块进行类型标记和软件度量,生成缺陷预测数据集D;(2)对缺陷预测数据集D进行两阶段包裹式特征选择,从原有特征集FS中移除原有数据集内的冗余特征和无关特征,得到最优特征子集FS';(3)基于最优特征子集FS',对数据集D进行预处理并形成预处理后的数据集D',即保留最优特征子集FS'中的特征,最终采用决策树分类方法,构建出缺陷预测模型。本发明步骤(2)中执行两阶段包裹式特征选择方法包括如下步骤:2-1)在缺陷预测数据集中,有缺陷模块的数量要远少于无缺陷模块的数量,因此在第一阶段用类不平衡学习方法SMOTE合成新的少数虚拟的有缺陷模块,即每一次从有缺陷模块中随机选择模块a,并从该模块a的最近邻中随机选择一个模块b,然后在模块a和模块b之间构成的连线上随机选择1点,作为新合成的虚拟的有缺陷模块;若原有缺陷预测数据集D中的无缺陷模块的实例数为nmax,有缺陷模块的实例数为nmin,则应用SMOTE方法后会额外合成nmin个有缺陷模块样本,最终形成预处理后的数据集D1;2-2)在第二阶段,基于数据集D1,采用一种针对缺陷预测问题定制的遗传算法,从原有特征集FS中移除原有数据集内的冗余特征和无关特征,选出最优特征子集FS',形成预处理后的数据集D';本发明步骤2-2)中的遗传算法包括如下步骤:2-2-1)初始化种群:假设缺陷预测数据集原有特征集FS包含n个特征,则种群内的每个染色体用n比特串进行编码,若第i个比特取值为1,则表示对应的第i个特征被选择,否则比特取值为0;在初始化种群时,针对每个染色体,每个比特随机赋值,即赋值为1或赋值为0;随后依次计算每个染色体的适应值,其计算过程按照以下步骤进行:2-2-1-1)首先读取染色体对应的特征子集FSt;然后将数据集D'均匀划分为5份,并确保每一份数据与原数据集的类分布保持一致;2-2-1-2)取其中四份构成训练集,剩余一份构成测试集,借助选出的特征子集FSt对训练集和测试集进行预处理,仅保留选中的特征,基于预处理后的训练集,借助决策树分类方法构建预测模型,并基于预处理后的测试集计算出模型的AUC值;上述过程重复5次,确保每份数据都至少被用做测试集一次;2-2-1-3)计算出这5个AUC值的均值AUCavg,并将1-AUCavg作为染色体对应的适应值并返回;2-2-2)基于上一种群,依次执行选择算子、交叉算子和变异算子,形成新的种群;其中选择算子在执行时,每一次从上一个种群中选出适应值最高的染色体,并重复一份放入新的种群中;交叉算子在每次执行时,基于交叉概率,从上一种群中随机选择两个染色体,并随机确定交叉点,然后进行交叉并形成两个新的染色体,并将这两个新的染色体放入新的种群;变异算子在每次执行时,基于变异概率,从上一种群中随机选择一个染色体,并随机确定变异点,然后进行变异并形成一个新的染色体,并将这个新的染色体放入新的种群;当新的种群生成结束后,依次计算出每个染色体的适应值,并更新种群中的最优染色体,所述最优染色体为适应值最小的染色体;针对软件缺陷预测问题,在种群最优染色体更新的时候,按照如下步骤进行:2-2-2-1)若当前染色体c的适应值小于种群最优染色体,则用染色体c替换种群最优染色体;2-2-2-2)若当前染色体c的适应值与种群最优染色体一样,则进一步比较当前染色体对应的特征子集的规模,并与种群最优染色体对应的特征子集规模进行比较,若当前染色体对应的特征子集的规模更小,则用染色体c替换种群最优染色体;2-2-3)若满足种群演化的终止准则,则返回当前种群中的最优染色体对应的特征子集FS',否则继续执行步骤2-2-2);其中种群在演化时,若达到指定的代数或种群提前收敛,则满足终止准则并停止种群演化。传统的软件缺陷预测方法在进行包裹式特征选择时,主要考虑了两类方法:(1)基于前向搜索的包裹式特征选择方法。该方法从空集开始,每次尝试选出一个特征,并加入到特征子集中,当新的特征子集的预测性能不如上一轮的特征子集的预测性能时,添加过程结束。(2)基于后向搜索的包裹式特征选择方法,该方法从考虑所有特征开始,每次尝试移除一个特征,当新的特征子集的预测性能不如上一轮的特征子集的预测性能时,移除过程结束。但上述两种基于贪婪策略的方法均容易陷入局部最优,并造成选出的特征子集未必是最优解。与上述已有技术相比,本发明借助遗传算法这一全局优化算法进行特征选择,遗传算法作为一种全局优化算法,可以有效避免陷入局部最优解,从而有助于找出更优的特征子集,并可以有效提高训练出的缺陷预测模型的性能。除此之外,本发明还通过额外借助SMOTE方法来缓解数据集内的类不平衡问题,从而可以进一步提升缺陷预测模型的性能。实践表明基于本发明设计的两阶段包裹式特征选择方法,可以更为有效的移除缺陷预测数据集内的冗余特征和无关特征,很好的缓解数据集内的类不平衡问题,最终可以训练出具有更高预测性能的缺陷预测模型,因此可以更加精准的预测出被测项目的潜在缺陷程序模块,最终达到优化测试资源分配和提高软件产品质量的目的。附图说明图1是本发明的总体流程图。图2是特征选择方法流程图图3是本发明针对软件缺陷预测问题定制的遗传算法的流程图。图4是本发明染色体适应值计算过程的流程图。图5是本发明交叉算子和变异算子的执行示意图。图6是本发明5次2折交叉验证的流程图。具体实施方式为了更详尽的表述上述发明的技术路线,以下本发明人列举出具体的实施例来说明技术效果;需要强调的是,这些实施例是用于说明本发明而不限于限制本发明的范围。实施例本实施例的基于两阶段包裹式特征选择的软件缺陷预测方法的总体流程图如图1所示,包含如下步骤:(1)挖掘软件项目的版本控制系统(例如CVS、SVN或Git等)和缺陷跟踪系统(例如Bugzilla、Mantis或Jira等),从中抽取程序模块。程序模块的粒度可以根据缺陷预测的目的设置为文件、包、类或函数等。随后对每个程序模块,根据缺陷跟踪系统内的缺陷报告信息进行标记(即将每个程序模块分别标记为有缺陷类型或无缺陷类型)。最后基于软件代码复杂度或软件开发过程分析,设计出与软件缺陷存在相关性的度量元(即特征),并借助这些度量元完成对每个程序模块的度量。通过对程序模块进行标记和软件度量,生成缺陷预测数据集D。若将数据集存储为Weka软件支持的格式,则来自某一实际项目的缺陷预测数据集的具体内容如下所示(其中//后面是注释)。(2)对缺陷预测数据集进行两阶段包裹式特征选择,尝试从原有特征集FS中选出最优特征子集FS',以尽可能多的移除数据集内的冗余特征和无关特征。具体流程如图2所示。(3)基于最优特征子集FS',对数据集D进行预处理(即仅保留FS'中的特征),并形成预处理后的数据集D',最终借助决策树这一分类方法,构建出缺陷预测模型。所述步骤(2)中执行两阶段包裹式特征选择方法按照以下步骤进行:2-1)在第一阶段借助类不平衡学习方法SMOTE,来缓解数据集内有缺陷模块(即少数类)数远少于无缺陷模块(即多数类)数的问题。SMOTE方法尝试合成新的少数类样本,即每一次会从少数类中随机选择模块a,并从该模块的最近邻中随机选择一个模块b,然后在a和b之间构成的连线上随机选择1点,作为新合成的少数类实例。假设原有数据集D中的多数类的实例数为nmax,少数类的实例数为nmin。则应用SMOTE方法后(假设需要虚拟创造出的少数类实例的比例为100%),会额外合成nmin个少数类样本,最终形成预处理后的数据集D1。2-2)在第二阶段,基于数据集D1,借助针对软件缺陷预测问题定制的一种遗传算法(其执行过程如图3所示),尝试从原有特征集FS中选出最优特征子集FS'。步骤2-2)中针对软件缺陷预测问题定制的一种遗传算法按照以下步骤进行:2-2-1)初始化种群。假设缺陷预测数据集原有特征集FS包含n个特征,则种群内的每个染色体用n比特串进行编码,若第i个比特取值为1,则表示对应的第i个特征被选择,否则比特取值为0。在初始化种群时,针对每个染色体,每个比特随机赋值(即赋值为1或赋值为0)。假设有5个特征{f1,f2,f3,f4,f5},则初始种群可能为{00100,10010,10110}。其含义是该初始种群共包括三个染色体,这三个染色体对应的特征子集分别为:{f3},{f1,f4},{f1,f3,f4}。随后依次计算每个染色体的适应值,其计算过程按照以下步骤进行:2-2-1-1)首先读取染色体对应的特征子集FSt。然后将数据集D'均匀划分为5份,并确保每一份数据与原数据集的类分布保持一致。2-2-1-2)取其中四份构成训练集,剩余一份构成测试集,借助选出的特征子集FSt对训练集和测试集进行预处理(即仅保留选中的特征),基于预处理后的训练集,借助决策树分类方法构建预测模型,并基于预处理后的测试集计算出模型的AUC值(模型的一种经典性能评测指标)。上述过程重复5次,确保每份数据都至少被用做测试集一次。具体计算过程如图4所示。2-2-1-3)计算出这5个AUC值的均值AUCavg,并将1-AUCavg作为染色体对应的适应值并返回。不难看出,适应值越小,表示染色体的质量越高。2-2-2)基于上一种群,依次执行选择算子、交叉算子和变异算子,以形成新的种群。其中选择算子在执行时,会每一次从上一个种群中选出适应值最高的染色体,并重复一份放入新的种群中。交叉算子在每次执行时,会基于交叉概率,从上一种群中随机选择两个染色体,并随机确定交叉点,然后进行交叉并形成两个新的染色体,并将这两个新的染色体放入新的种群。假设交叉算子随机选出两个染色体,分别是00100和01101,并随机确定第三位为交叉点并完成交叉操作,最终会形成两个新的染色体,分别是00101和01100。变异算子在每次执行时,会基于变异概率,从上一种群中随机选择一个染色体,并随机确定变异点,然后进行变异并形成一个新的染色体,并将这个新的染色体放入新的种群。当新的种群生成结束后,假设变异算子随机选出一个染色体为01110,并随机确定第三位为变异位,因为当前染色体的第三位取值为1,则应用变异算子后,该值将变为0,并形成一个新的染色体为01010。交叉算子和变异算子的具体示意图如图5所示。依次计算出每个染色体的适应值,并更新种群中的最优染色体(即适应值最小的染色体)。针对软件缺陷预测问题,在种群最优染色体更新的时候,按照如下步骤进行:2-2-2-1)如果当前染色体c的适应值小于种群最优染色体,则用染色体c替换种群最优染色体。2-2-2-2)如果当前染色体c的适应值与种群最优染色体一样,则进一步比较当前染色体对应的特征子集的规模,并与种群最优染色体对应的特征子集规模进行比较,若当前染色体对应的特征子集的规模更小,则用染色体c替换种群最优染色体。2-2-3)若满足种群演化的终止准则,则返回当前种群中的最优染色体对应的特征子集FS',否则继续执行步骤2-2-2)。其中种群在演化时,若达到指定的代数或种群提前收敛,则满足终止准则并停止种群演化。以下通过实际项目,对本发明的有效性进行验证。我们分析了一组实际项目,这些项目在程序模块度量时,考虑的度量元与代码规模、McCabe环路复杂度、以及Halstead复杂度有关。表1总结了这些实际项目中的缺陷预测数据集的统计特征,包括项目名称、特征数、模块数、缺陷模块数以及缺陷模块所占的比例。不难看出这些数据的特征数较多,介于36~39之间,包含的模块数介于125~1988之间。同时数据集存在明显的类不平衡问题,其缺陷模块所占比例介于0.02~0.35之间。表1数据集的特征统计在实验中选择AUC(areaunderROCcurve)作为模型的性能评测指标。在性能评估时,主要考虑的是5次2折交叉验证。其中2折交叉验证是指将数据集D划分为2个大小相近的互斥子集D1和D2。其中D1∪D2=D,D1和D2在划分时,借助分层采样来确保这两个子集的数据分别与原有数据集D的分布保持一致。但将数据集划分为2个子集存在很多划分方式,为了减少因样本划分不同而引入的差别,实验时将2折交叉验证重复5次。其具体流程如图6所示。实验重点考虑了三种经典的包裹式特征选择方法:(1)基于前向搜索的包裹式特征选择方法(简称FW),该方法从空集开始,每次尝试选出一个特征,并加入到特征子集中,当新的特征子集的预测性能不如上一轮的特征子集的预测性能时,添加过程结束。(2)基于后向搜索的包裹式特征选择方法(简称BW),该方法从考虑所有特征开始,每次尝试移除一个特征,当新的特征子集的预测性能不如上一轮的特征子集的预测性能时,移除过程结束。(3)不进行特征选择的软件缺陷预测方法(简称Origin),该方法不做特征选择,即保留已有特征。发明提出的方法和基准方法均基于Weka软件包予以实现。其中发明在步骤2-1)中的SMOTE方法的参数取值设置如下:最近邻数设置为5,需要虚拟创造出的少数类实例的比例为100%(假设原有数据集中少数类实例的个数是10,则基于上述参数,SMOTE方法会额外虚拟创造出10个少数类实例)。在步骤2-2)中的遗传算法的参数取值设置如下:种群规模为20,最大迭代次数为20,变异概率为0.7,交叉概率为0.1。发明在模型性能评估的时候,考虑的是5次2折交叉验证。在每一折的运行时,考虑到遗传算法内存在的随机因素,因此我们会独立运行发明设计的方法5次,并最终选择其中的最优值。最终基于决策树分类方法的结果如表2所示。由于每个数据集在不同方法下会有10个不同的执行结果(如图6所示),我们取其中的中位数并列在表中。我们对其中的最优结果进行了加粗表示。表2基于决策树分类方法的AUC值基于表2,不难看出,在所有项目中,发明设计的方法均要优于FW、BW和Origin。发明设计的是一种两阶段包裹式特征选择方法,随后我们进一步分析在第一阶段,考虑SMOTE方法和不考虑SMOTE方法时的性能差异,同样我们也取其中的中位数。最终结果如表3所示。结果表明:除了PC1项目,进行SMOTE的方法在基于决策树分类方法上,均要优于未进行SMOTE的方法。该实验结果验证了发明设计的方法的有效性。表3基于决策树分类方法的AUC值分析项目未进行SMOTE进行SMOTECM10.63650.677KC30.63950.6835MC10.6310.729MC20.63750.694MW10.61650.6335PC10.76550.7465PC20.50.731PC30.71650.7357PC40.8670.8675PC50.6920.712上述实例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。根据本发明精神实质所做的等价变化或修饰,都应涵盖在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1