一种基于线框模型的三维目标注册定位方法与流程
本发明属于增强现实技术领域,尤其涉及一种基于线框模型的三维目标注册定位方法。
背景技术:
增强现实是一个多学科交叉的创新型研究领域,通过将计算相机产生的图形与文字注释等虚拟信息融合到真实环境中,对人的视觉系统进行景象增强。典型的增强现实系统主要包括图像采集与处理系统、注册定位系统、虚拟信息绘制渲染系统与虚实融合显示系统这几个部分。而注册定位是增强现实系统的关键技术之一,其解决的问题是实时地检测出相机的位置和视线方向,根据这些信息确定添加虚拟信息的正确位置,并进行实时显示。注册定位算法的性能对整个增强现实系统的稳定性和鲁棒性会产生很大的影响。按照注册对象的不同,注册定位技术可以划分为基于二维目标的注册定位技术和基于三维目标的目标注册定位技术。基于二维的目标注册定位通常是针对二维标志物或者特征点显著的二维平面完成的虚实融合,用户体验度往往不高,只能体验到一个二维平面带来的虚实感受。而基于三维目标的注册定位实现了整个三维环境和三维虚拟信息的结合,可以体验更加无缝结合的虚实融合。基于三维目标的注册定位和基于二维目标的注册定位相比在技术实现难度上更高,其难点主要体现在两个方面:一是在透视变换原理上不同于二维目标,对于三维目标,当摄像头移动的时候,三维目标的外观和其拓扑结构也发生相应的变化,其注册定位的难度较二维目标有较大的提升;二是相比较二维目标,三维目标注册定位的运算量庞大,尤其在移动终端上的研发,系统的实时性比较难实现。当前,基于三维目标的注册定位技术根据场景模型的表示形式和注册过程中是否需要预先构建场景分为两大类:基于模型的三维目标注册定位方法和基于并行重建和跟踪的三维注册定位方法。第一种方法的前提是场景的三维模型已经预先建立好,利用建立好的三维模型进行二维特征与三维模型匹配,最后计算摄像相机外参,实现三维注册定位,其中模型包括基准标志、点云模型和线框模型;第二种方法是在场景未知的情况下进行的,在跟踪的同时重建场景的三维结构,这种方法又可以分为SLAM和online-SfM方法。
技术实现要素:
本发明的目的在于提供一种基于线框模型的三维目标注册定位方法,旨在解决三维目标注册定位的问题,以实现整个三维环境和三维虚拟信息的融合,从而可以体验到更加无缝结合的虚实融合。
本发明是这样实现的,一种基于线框模型的三维目标注册定位方法,所述基于线框模型的三维目标注册定位方法包括:
首先对三维目标物体进行三维建模并投影到图像平面上,通过抗噪声能力强的Hausdorff距离形状匹配算法对三维目标进行精准定位,找到和当前三维目标姿态最匹配的三维模型。
该技术方案主要有两个作用:第一个作用是,初始化目标定位。对当前帧图像进行线框模型检测,利用Hausdorff距离形状匹配算法,寻找和当前场景中三维目标物体的线框模型最匹配的三维模型,得到三维目标物体的初始位姿信息。如果在当前帧中,没有找到与场景中三维目标物体的线框模型相匹配的三维模型,则持续在下一帧中继续进行匹配,直到初始化成功为止;第二个作用是,初始化成功之后,在后续的三维目标跟踪中,每跟踪上几帧之后,利用Hausdorff距离形状匹配算法精确匹配三维目标物体,对三维目标物体的位姿进行精调,以得到三维目标物体更加精确的的位姿信息。
然后采用深度优先和广度优先结合的搜索算法对三维目标进行跟踪,对三维目标物体进行实时的位姿估计;
该技术方案的主要目的是能够实时的估计得到三维目标物体的位姿。虽然利用Hausdorff距离形状匹配算法,可以对三维目标物体进行精确定位,但其位姿估计实时性较差。所以该发明方法中,采用深度优先和广度优先结合的搜索算法对三维目标进行跟踪,以达到系统的整个实时性要求。
最后利用得到的相机姿态信息在场景中叠加虚拟物体。通过以上步骤,可以实现整个三维环境和三维虚拟信息的结合,从而可以体验更加无缝结合的虚实融合。
进一步,所述基于线框模型的三维目标注册定位方法包括以下步骤:
步骤一,通过三维建模软件预先离线构建出目标物体的三维模型,该三维模型仅包括目标物体的点线面信息即可。
步骤二,打开摄像头,实时获取当前场景的图像帧。同时对获取的每一帧进行一些预处理,主要包括将彩色图像转换为灰度图像,以及噪声的去除。
步骤三,对三维模型以不同的尺度与旋转角度进行模型变换,同时将每个变换后的模型进行透视投影变换,从而将模型投影到图像坐标系下,并保存投影后的模型图像。该步骤的详细过程如下:
将模型归一化到标准大小,并分别以不同的尺度对三维模型进行不同大小的缩放。
对每个尺度下的模型,以多个不同的角度进行旋转变换。
对每个尺度与旋转变换后的模型,进行透视投影变换,将其投影到图像坐标系下,并保存投影后的模型图像,以及尺度缩放因子和旋转角度。那么,就得到了多组尺度不同的模型图像,而每一组内的模型图像具有相同的尺度大小,但是具有不同的旋转角度。并且,由于离线构建的三维模型仅包括三维物体的点线面信息,所以经过这种模型变换与投影变换后的模型图像为线框图像。
步骤四,对步骤二中预处理后的每一帧图像进行线框模型检测。线框检测的具体步骤如下:
利用Canny算子对每一帧图像进行边缘检测,此时检测到的边缘包含背景信息的边缘,而我们仅需要每一帧图像中目标物体的边缘信息即可,这种背景信息的边缘在这里就是所谓的噪声信息。
利用步骤三中的三维模型的几何信息和拓扑信息,采用点线协同的方法来滤去背景信息噪声。线框模型的约束条件为:没有构成拓扑结构的点和线可以滤去,尺寸短小且孤立的点和线可以滤去,以及没有在屏幕中心且稀疏的点和线可以滤去。
步骤五,三维目标的定位。采用Hausdorff距离作为相似度度量标准,在步骤二中得到的模型的所有线框图像中,找到和步骤四中所检测到的三维目标的线框模型最匹配的一个线框图像,并进行显示。
步骤六,场景图像的线框模型的三维目标跟踪。在三维目标定位之后,当相机移动的时候就需要实时地跟踪到三维模型。可以采用广度优先和深度优先相结合的方法,对场景图像的线框模型进行三维目标跟踪。当相机前后移动的时候,在每一层该姿态下的三维模型中搜索,当相机左右平移的时候只在该层不同姿态下的三维模型中搜索。
步骤七,相机的位姿估计。当三维目标初始化成功之后便可进行相机的位姿估计,三维目标初始化成功的判断标准是,连续5帧和正确的三维模型计算得到的Hausdorff距离值都是最小值。初始化成功之后将该初始化模型的投影图像的四个点设为模型点,将相机姿态变化之后匹配搜索出来的三维模型投影之后对应的四个点设为图像点;采用PnP算法估计出相机的第一个姿态,再采用RPP算法进行迭代,最终获得误差最小的正确的姿态。
本发明提供的基于线框模型的三维目标注册定位方法,解决了三维目标的注册定位问题,从而可以实现整个三维环境和三维虚拟信息的融合,而使用户可以体验到更加无缝结合的虚实融合显示效果。
附图说明
图1是本发明实施例提供的基于线框模型的三维目标注册定位方法流程图。
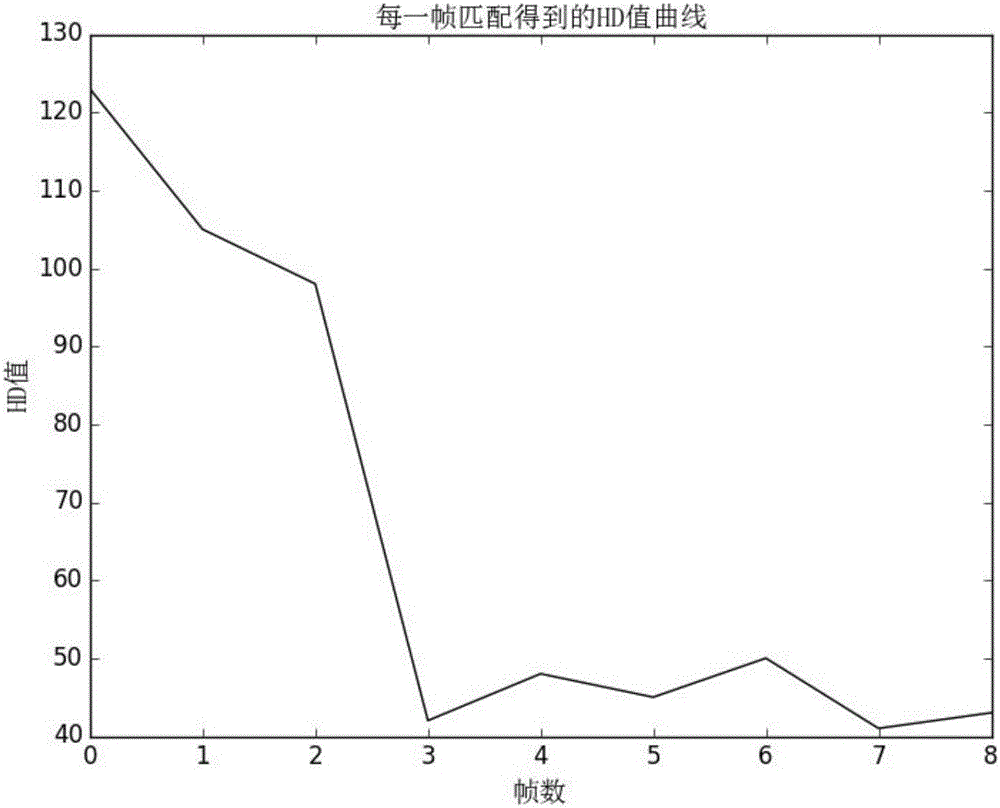
图2是本发明实施例提供的每帧匹配得到的Hausdorff距离值曲线图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
本发明提供的基于线框模型的三维目标注册定位算法,系统框图如图1所示,具体包括如下步骤:
(1)通过三维建模软件预先构建出目标物体的三维模型,其中三维模型是由一组点以及由点的相互关系得到直线构成的,可以使用OpenGL由这些点线绘制渲染出的相应的三维模型图。
(2)场景图像的采集与预处理。
(3)对三维模型以不同的尺度与旋转角度进行变换,并保存变换后的三维模型,然后将这些模型投影到图像坐标系平面上,投影的结果为线框图像。
(4)线框模型检测。利用Canny算子对三维目标进行边缘检测,这时检测到的边缘包含背景信息的边缘。这些背景信息的边缘称为噪声,这些噪声可以采用点线协同的方法来滤去,这种方法是利用线框模型的几何信息和拓扑信息来完成的。约束条件可以定为:
没有构成拓扑结构的点和线可以滤去;
尺寸短小且孤立的点和线可以滤去;
没有在屏幕中心且稀疏的点和线可以滤去;
(5)三维目标的定位。三维目标的定位是为了定位当前三维目标的姿态,即进行形状匹配,在保存的三维模型的投影中找到和当前检测到三维目标的线框模型最匹配的三维模型进行显示。可以采用Hausdorff距离作为相似度度量进行形状匹配,Hausdorff距离的优点是抗干扰能力比较强,目标定位效果是三维目标模型与场景中的三维目标重合在一起。
(6)场景图像的线框模型的三维目标跟踪。在三维目标定位之后,当相机移动的时候就需要实时地跟踪到三维模型。可以采用广度优先和深度优先结合的方法,这种方法的实现过程是:当相机前后移动的时候,只在每一层该姿态下的三维模型中搜索,当相机左右平移的时候只在该层不同姿态下的三维模型中搜索。
(7)相机的位姿估计。当三维目标初始化成功之后便可进行相机的位姿估计,三维目标定位初始化成功的标志可以定为:连续5帧和正确的三维模型计算得到的Hausdorff距离值都是最小值,则认为初始化成功。初始化时每帧匹配得到的HD(Hausdorff Distance)值的曲线图如图2所示。初始化成功之后可将该初始化模型的投影图像的四个点设为模型点,将相机姿态变化之后匹配搜索出来的三维模型投影之后对应的四个点设为图像点,有了对应的点对再联合相机内参,采用PnP(Perspective N Points)算法估计出相机的第一个姿态,再采用RPP算法进行迭代,最终获得误差最小的正确的姿态。估计出相机的正确姿态后,便可利用该位姿信息在指定的位置叠加增强现实物体示。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!