采用拉曼光谱对物质进行聚类分析识别的方法与流程
本发明涉及一种在化学分析和仪器分析领域中对物质进行聚类分析识别的方法,特别是一种采用拉曼光谱对物质进行聚类分析识别的方法。
背景技术:
拉曼光谱常用于物质定性,如公开号为CN102115778A的“食源性致病菌的表面增强拉曼光谱鉴别方法”,公开为CN103487425A的“一种利用表面增强拉曼光谱识别癌细胞的方法”。但是由于物质自身信号较弱而伴随的荧光信号强、以及样本集中的各类样本和孤立样本存在交叠,给聚类和识别造成困扰。尤其对于信噪比不高的微型拉曼光谱仪,影响了这类仪器的实用性。而在强荧光背景下,如果以常见的主成分分析(PCA)进行做可视化描述,难以识别,无法聚类分析。实现这类复杂聚类,要采用SIMCA聚类分析等需要先验知识的有监督方法,这对于探索性实验和建模的要求较高。
技术实现要素:
本发明要解决的技术问题是:本发明针对拉曼光谱的复杂情况,提出一种无监督,可满足探索性检测和现场实际应用需求的采用拉曼光谱对物质进行聚类分析识别的方法。
解决上述技术问题的技术方案是:一种采用拉曼光谱对物质进行聚类分析识别的方法,包括步骤:①通过拉曼光谱仪采集样本的拉曼光谱,构成由p个样本组成的样本集;该方法还包括以下步骤:
②计算所有样本间的差异系数,构造差异系数方阵;
③根据样本间的相互差异系数,去除孤立样本,重新排列出新差异系数方阵;
④从新差异系数方阵中依次聚类出样本集的各类;
⑤重复步骤④,直至所有元素区分完毕;至此,样本集中的所有样本完成聚类;
⑥按照聚类顺序重新排列原始样本顺序,重新绘制差异系数方阵,使各类样本被准确区分成相应区块,实现对各类样本的准确识别。
本发明的进一步技术方案是:步骤② 包括以下具体过程:
对样本集中的p个样本,顺序比较第i个和第j个样本差异,计算彼此的差异系数τij,构成p×p的差异系数方阵DSM。
本发明的进一步技术方案是:步骤③包括以下具体过程:
③-1.找出差异系数方阵DSM中每列的相互差异系数的最小值,即是每个样本与其他样本的差异系数τij(i≠j)中的最小值,构成数组D={min(τij), i≠j};
③-2.找出数组D中元素的w个上侧离群值和p1个保留的下侧元素,p=w+p1;离群值代表的样本与其他样本不存在相似,不与样本集中的任一样本属于同一类;
③-3.将离群值从差异系数方阵DSM的行列中去除,重新排列出新差异系数方阵DSM1。
本发明的进一步技术方案是:步骤④包括以下具体过程:
④-1.选取新差异系数方阵DSM1第1行的p1个元素,作升序排列,完成狄克逊检验,区分出p2个上侧离群值元素和n1个下侧数值较小的系列元素,p1=p2+n1;
④-2.按照上下侧所包含的元素,从新差异系数方阵DSM1中分割出尺寸为n1×n1的第1类样本方阵N1,N1={τij; i,j∈n1 };
④-3.将N1方阵中每列的相互差异系数的最小值,即每个样本与其他样本的差异系数τi(i≠j)的最小值,构成数组D1={min(τij),i≠j};如果经狄克逊检验出现了上侧离群值,则将离群值归入步骤④-1中产生的p2个上侧离群元素集合;
④-4.将剩余的p2个上侧元素构成尺寸为p2×p2的其他类样本方阵DSM2,DSM2={τij; i,j∈p2}。
由于采用上述结构,本发明之采用拉曼光谱对物质进行聚类分析识别的方法与现有技术相比,具有以下有益效果:
1. 是一种无监督的模式聚类方法
由于本发明包括步骤:①通过拉曼光谱仪采集样本的拉曼光谱,构成由p个样本组成的样本集;②计算所有样本间的差异系数,构造差异系数方阵;③根据样本间的相互差异系数,去除孤立样本,重新排列出新差异系数方阵;④从新差异系数方阵中依次聚类出样本集的各类;⑤重复步骤④,直至所有元素区分完毕;至此,样本集中的所有样本完成聚类;⑥按照聚类顺序重新排列原始样本顺序,重新绘制差异系数方阵,使各类样本被准确区分成相应区块,实现对各类样本的准确识别。因此,本发明是利用光谱的差异系数,完成了高背景干扰的拉曼信号聚类,是一种无监督的模式聚类方法。
2.方法简便,成本低
由于本发明利用光谱的差异系数,完成了高背景干扰的拉曼信号聚类,无需建模,其方法简便,成本较低。
3.可满足探索性检测和现场实际应用的需求
由于本发明利用光谱的差异系数,即可完成了高背景干扰的拉曼信号聚类,无需先验知识监督,无需建模,适合于探索性检测和现场实际应用需求。
4.应用范围广
本发明可广泛应用于药物、食品、化学品等领域的物质识别,其应用范围比较广泛。
下面,结合附图和实施例对本发明之采用拉曼光谱对物质进行聚类分析识别的方法的技术特征作进一步的说明。
附图说明
图1:实施例一所述40个样本经主成分分析得到第1和第2主成分的得分图;
图2:实施例一所述40个样本的光谱图;
图3:实施例一所述从A、B、C三类中任选的一个光谱;
图4:实施例一所述差异系数方阵DSM示意图;
图5:实施例一所述数组D的元素光谱图;
图6:实施例一所述选取新差异系数方阵DSM1第1行作升序排列图;
图7:实施例一所述第1类样本N1方阵的示意图;
图8:实施例一所述对其他类样本方阵DSM2的第1行做升序排列图;
图9:实施例一所述第2类样本N2方阵的示意图,
图10:实施例一所述对DSM3第1行作升序排列图;
图11:实施例一所述第3类样本N3方阵的示意图;
图12:实施例一所述重新绘制差异系数方阵的示意图。
具体实施方式
一种药物、食品、化学品等领域中采用拉曼光谱对物质进行聚类分析识别的方法,该方法包括以下步骤:
①通过拉曼光谱仪采集样本的拉曼光谱,构成由p个样本组成的样本集;
②计算所有样本间的差异系数,构造差异系数方阵:
对样本集中的p个样本,顺序比较第i个和第j个样本差异,计算彼此的差异系数τij,构成p×p的差异系数方阵DSM;
③根据样本间的相互差异系数,去除孤立样本,重新排列出新差异系数方阵:
③-1.找出差异系数方阵DSM中每列的相互差异系数的最小值,即是每个样本与其他样本的差异系数τij(i≠j)中的最小值,构成数组D={min(τij), i≠j};
③-2.找出数组D中元素的w个上侧离群值和p1个保留的下侧元素,p=w+p1;离群值代表的样本与其他样本不存在相似,不与样本集中的任一样本属于同一类;
③-3.将离群值从差异系数方阵DSM的行列中去除,重新排列出新差异系数方阵DSM1;
④从新差异系数方阵中依次聚类出样本集的各类:
④-1.选取新差异系数方阵DSM1第1行的p1个元素,作升序排列,完成狄克逊(Dixon)检验,区分出p2个上侧离群值元素和n1个下侧数值较小的系列元素,p1=p2+n1;
④-2.按照上下侧所包含的元素,从新差异系数方阵DSM1中分割出尺寸为n1×n1的第1类样本方阵N1,N1={τij; i,j∈n1 };
④-3.将N1方阵中每列的相互差异系数的最小值,即每个样本与其他样本的差异系数τi(i≠j)的最小值,构成数组D1={min(τij),i≠j};如果经狄克逊检验出现了上侧离群值,则将离群值归入步骤④-1中产生的p2个上侧离群元素集合;
④-4.将剩余的p2个上侧元素构成尺寸为p2×p2的其他类样本方阵DSM2,DSM2={τij; i,j∈p2};
⑤重复步骤④,直至所有元素区分完毕;至此,样本集中的所有样本完成聚类;
⑥按照聚类顺序重新排列原始样本顺序,重新绘制差异系数方阵,使各类样本被准确区分成相应区块,实现对各类样本的准确识别。
以下是本发明的具体实施例:
实施例一
一种采用拉曼光谱对物质进行聚类分析识别的方法,该方法是选用采用相同辅料,但API存在差异的药物片剂A、B、C三类样本进行拉曼光谱识别,包括步骤:
①通过拉曼光谱仪采集样本的拉曼光谱,样本集由样本数分别为15个、10个和10个的A、B、C三类样本,以及5个各自独立的孤立样本组成,共40个样本。
图1是40个样本经主成分分析(PCA)得到第1和第2主成分的得分图,图中各类样本和孤立样本交叠,无法确定分区。
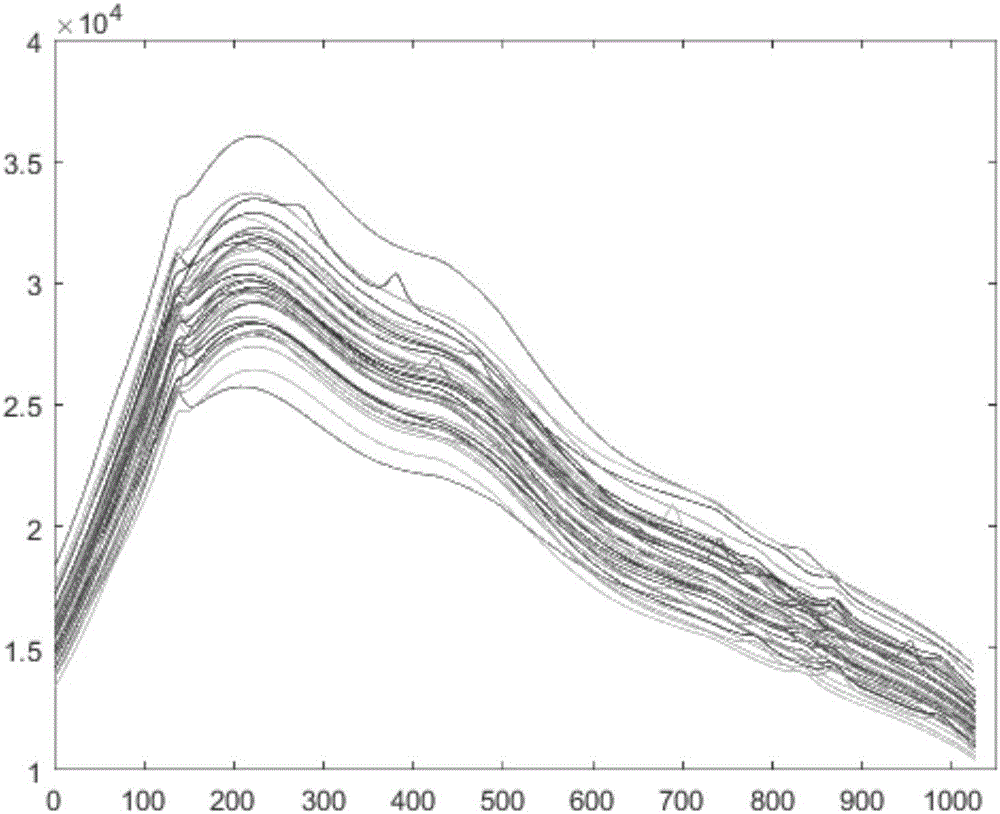
全部样本的光谱如图2,样本的辅料荧光效应较强,由图2直观上看,谱线相似,直接辨识难度大。图3是从A、B、C三类中任选的一个光谱。从图3中可看出由于背景荧光和拉曼光谱本身相似,光谱不易准确辨认。在强荧光背景下,如果以常见的主成分分析(PCA)做可视化描述,难以识别,无法聚类。
②计算所有样本间的差异系数,构造差异系数方阵:
计算出40个样本光谱彼此间差异系数,构造差异系数方阵DSM,得到的差异系数方阵DSM是一个对角为0的对称方阵。该矩阵用灰度深浅表示,如图4。
③根据样本间的相互差异系数,去除孤立样本,重新排列出新差异系数方阵:
③-1.去除对角元素后,找出矩阵每列的最小值,构成数组D,图5为数组D中的元素。
③-2.从图5中直接看出,或采用狄克逊检验,可知数组D中(1,8,25,30,31)号元素为上侧离群值,也就是说,在样本集中所对应的这些样本是孤立的,不与其他样本同类。
③-3.将离群值从差异系数方阵DSM的行列中去除,重新排列出新差异系数方阵DSM1。
④从新差异系数方阵中依次聚类出样本集的各类:
④-1.选取新差异系数方阵DSM1第1行作升序排列,如图6所示,由图6可直接看出或采用狄克逊检验,可知前10个样本为同类,即原始样本集的第(2,26,4,23,10,34,24,29,40,16)号共10个样本为同类。
④-2.从新差异系数方阵DSM1中选出这些样本构成第1类样本N1,如图7所示,图7中各元素分布均匀,即从整体样本中区分出了第1类样本N1。
④-3.从新差异系数方阵DSM1中扣除第1类样本N1;
④-4. 将剩余的上侧元素构成其他类样本方阵DSM2;
⑤重复步骤④,对其他类样本方阵DSM2的第1行做升序排列,如图8所示,从图8直接看出,或按狄克逊检验,原始样本集的第(3,27,19,39,11,36,21,6,37,15,20,18,28,14,32)号共15个样本为同类。从其他类样本方阵DSM2中选出这些样本构成第2类样本N2方阵,如图9所示,图9中元素分布均匀,即从整体样本中区分出了第2类样本N2。
剩余的10个样本,即第(5,7,12,17,35,38,33,13,9,22)号,构成DSM3,对其第1行作升序排列,如图10所示,按狄克逊检验,发现不存在上侧离群值,这10个样本归属为同类,构成第3类样本N3方阵,如图 11,图11中元素分布均匀,即从整体样本中区分出了第3类样本N3。至此,完成了三类样本聚类。
⑥按照聚类顺序重新排列原始样本顺序,重新绘制差异系数方阵,如图12所示,图12中三类样本被准确区分成相应区块,实现对各类样本的准确识别。从图12中还可看出第1类样本N1和第3类样本N3的相似度最高,第1类样本N1和第2类样本N2的相似度大于第2类样本N2和第3类样本N3的相似度。
- 还没有人留言评论。精彩留言会获得点赞!