快速连续历史轨迹距离查询技术的制作方法
本发明是移动对象数据库领域,用于快速查询移动对象历史轨迹的距离查询技术。
二、
背景技术:
近年来,随着智能移动设备的普及,无线通讯技术的不断发展,定位技术越来越精确和方便。移动对象的位置信息的采集、管理与查询,促进了各种基于移动对象数据库的应用的研究,如地理信息系统、交通管理、城市规划和大量基于定位的服务(LBS)。通过研究移动对的轨迹,可以发掘移动对象的行为模式,可以研究移动对象的社会关系,通过这些研究,可以为决策提供参考,例如车辆的行为模式,可以为交通管理提供参考。
查询操作作为数据库的基本操作,它的效率的高低决定着这个数据库是否能够提供高效的服务。因此,有一个高效的查询操作,能够返回用户的查询结果,是至关重要的。如何处理这种查询请求,最简单直接的方法是计算数据库中每个移动对象的轨迹与查询轨迹,在查询时间区间内,每个时刻所在位置之间的欧式距离。然后将每个移动对象与查询移动对象轨迹的距离在查询范围[d1,d2]内的点组成的轨迹作为查询结果返回。这种方法,计算量大,需要计算每条移动对象轨迹与查询轨迹之间的距离,其计算时间复杂度随着移动对象的数量的增加呈线性递增。所以必须要有一个索引机制来提高数据的访问效率,增大过滤过程的精度,减少轨迹数据的访问和轨迹距离的计算。
三、
技术实现要素:
【发明目的】
为了提高查询的效率,本发明提供了包含对移动对象轨迹的轨迹分割预处理和建立轨迹段的3D R-Tree索引的距离查询算法,以解决查询算法的高效问题,增加了查询效率。
【技术方案】
本发明所述的快速连续历史轨迹距离查询技术是通过对移动对象轨迹建立索引机制,在索引的基础上,通过过滤-精细计算阶段来实现移动对象历史轨迹的距离查询。基于移动对象索引的过滤算法,可以提高对结果轨迹集合的过滤精度,减少候选轨迹的集合,从而减少精确计算阶段磁盘I/O次数和CPU的计算量。主要步骤如下:
(1)数据预处理;
本发明处理移动对象轨迹,所有移动对象保存在数据库的表中。每一条对象记录有一个轨迹数据,保存了该对象的所有历史轨迹。轨迹由轨迹单元组成,每个轨迹单元在平面和时间的三维空间里表示一个线段,对象的轨迹由一系列前后相连的轨迹单元构成,在三维空间中形成一条折线,如图1。将轨迹段分割成较小的轨迹段,用于提高轨迹过滤的精度。计算每个轨迹段的最小边框盒子(Minimum Bounding Box),即最小包含轨迹的空间盒子。
(2)建立移动对象轨迹移动对象索引3D R-Tree;
完成轨迹的预处理之后,以每个轨迹段和轨迹段的最小边框盒子为R-Tree叶子节点,插入到3D R-Tree中,建立所有对象轨迹的索引。
(3)基于移动对象轨迹索引的距离查询;
基于移动对象轨迹索引的距离查询包括两个步骤:过滤阶段和精细计算阶段。在过滤阶段,通过遍历3D R-Tree,过滤不可能为结果的轨迹,留下较小的轨迹集合,用于计算轨迹之间的距离。在精细计算阶段,计算轨迹在时间上的距离函数,即计算时间与距离的映射,求得距离在查询范围内的时间区间,在这个时间区间内的轨迹,即为查询的结果。
【有益效果】
本发明所述快速连续历史轨迹距离查询技术通过对轨迹数据的预处理,建立移动对象索引3D R-Tree,在所建立的3D R-Tree索引上,实现对连续历史轨迹的距离查询。下面通过测试数据来说明本发明的有效性。实验环境为:Intel(R)、Xeon(R)、CPU为E5-2650v2、主频260GHz、内存1GB、Linux环境Ubuntu14.04、C++语言、可扩充移动对象数据库SECONDO,实验数据柏林地铁轨迹数据。
表1
表2
表1显示了数据集的信息,表2显示了本发明在距离查询操作时与普通距离查询算法在不同查询范围参数上的时间比较,分别是表明本算法的性能有较大的提高。
四、附图说明
图1移动对象轨迹在空间的表示图
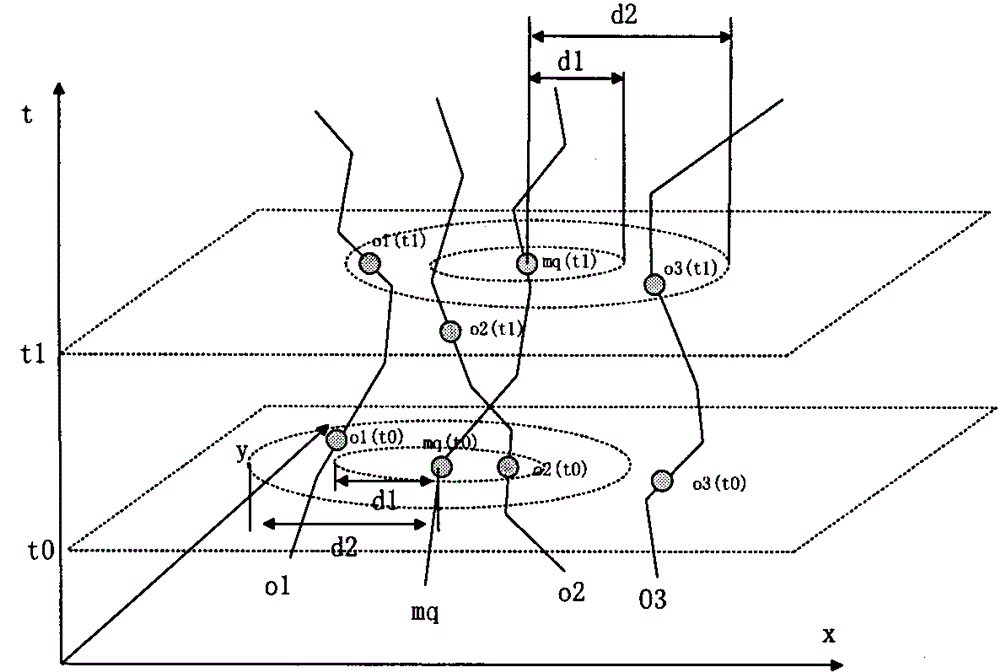
图2连续历史轨迹距离查询示意图
图3轨迹分割
图4 3D R-Tree索引移动对象轨迹
图5过滤移动对象轨迹的三种情况
五、具体实施方式
下面结合附图对本发明进一步说明。
本发明所述的快速连续历史轨迹距离查询技术是通过将移动对象历史轨迹进行预处理,以图3的结构存储在数据库中。通过对移动对象历史轨迹建立3D R-Tree索引,提高移动对象轨迹数据的访问速度和过滤精度。主要步骤如下:
(1)移动对象轨迹数据预处理;
本发明将移动对象(例如出租车、人、地铁等)的运动GPS位置作为输入,保存到可扩充数据库系统SECONDO中。每一条对象记录有一个轨迹数据,保存了该对象的所有历史轨迹。轨迹由轨迹单元组成,每个轨迹单元在平面和时间的三维空间里表示一个线段,对象的轨迹由一系列前后相连的轨迹单元构成,在三维空间中形成一条折线,如图1所示。
通过对移动对象的轨迹分割,得到较小的轨迹段。轨迹段分割的大小根据数据范围大小设定。移动对象轨迹分割较小,会增加轨迹段的数量,降低查询效率;而分割过大的话,过滤的精度降低,增加轨迹距离的计算时间,降低查询性能。
在移动对象轨迹分割之后,以轨迹段的时间和空间范围,生成一个最小边框盒子,用来最小表示轨迹的时空范围。
在对移动对象轨迹数据预处理后,得到所有对象和轨迹的数据表。表的每个元组由三个属性组成,包括TID、OID、Trip和MBR,分别存储移动对象所在元组位置、移动对象ID、移动对象的轨迹以及移动对象轨迹在时间和空间所组成的三维空间中的最小边框盒子,如图4所示。表中Trip对应分割后的轨迹段,移动对象的轨迹由多个元组构成,它们的轨迹在时间和空间上是相连的。
(2)建立3D R-Tree索引;
以对象轨迹表中的TID和MBR组成3D R-Tree的叶子节点,插入到3D R-Tree的root节点中,完成对移动对象轨迹的索引的建立。3D R-Tree与移动对象轨迹表的关系如图4所示。
(3)快速连续历史轨迹距离查询;
快速连续历史轨迹距离查询包括两个步骤:1)过滤,2)精细计算。过滤阶段将过滤掉那些不可能为结果的移动对象轨迹,在精细计算阶段对留下的候选轨迹做轨迹距离计算,得到查询结果。
1)过滤:查找候选移动对象轨迹
在查找候选移动对象轨迹时,最基本的思想是去掉完全不可能的移动对象轨迹。使用最大距离-最小距离的过滤方法用于过滤这种完全不可能的移动对象轨迹,从而减少计算量。通过比较两个轨迹在相同时间范围内的空间距离,可以判断轨迹是否符合查询的条件,从而去掉其中不符合查询条件的轨迹,对剩下的轨迹再做精细的计算。在轨迹的空间距离的比较中,有三种情况,如图5所示:
情况一:如图5a和如图5b所示,o1轨迹的MBR到查询轨迹mq在[t1,t2]上的轨迹的MBR的最小距离大于查询距离范围[d1,d2],因此o1的轨迹不可能是查询结果,将o1的轨迹排除在结果之外。o2轨迹的MBR到查询轨迹mq在[t1,t2]上的轨迹的MBR的最大距离小于查询距离范围[d1,d2],因此o2的轨迹不可能是查询结果,将o2的轨迹排除在结果之外。
情况二:图5c所示,o3轨迹的MBR到查询轨迹mq在[t1,t2]上的轨迹的MBR的最小距离和最大距离在查询距离范围[d1,d2]内,因此o3的轨迹一定是查询结果,将o3的轨迹添加在结果集合中。
情况三:除了情况一和情况二之外的情况的移动对象,都为候选对象,需要进一步精细计算。
在过滤时,从3D R树的根节点开始,遍历所有的子节点,如果子节点的时间维度的时间间隔与查询的对象的时间间隔有重叠,则判断该子节点的空间分布的最小边框矩形(MBR)与查询轨迹的最小边框矩形之间的最大距离和最小距离,如果这个子节点中中不可能包含有查询结果的轨迹,则不再对该节点继续深入搜索,否则继续搜索该子节点的子节点,直到搜索到叶子节点。对于叶子节点的处理与内部节点相似,将不可能是查询结果的轨迹抛弃,将其他的轨迹加入到候选集合中,等待精确计算,具体算法如下所示:
2)精细计算:对过滤后的候选轨迹计算距离
过滤阶段会过滤掉一部分不可能是查询结果的移动对象轨迹。对剩下的候选轨迹,通过计算两条轨迹在每个时刻的距离,将符合查询条件的移动对象轨迹作为结果输出。有以下主要步骤:
1.移动轨迹的动态时间规整;
2.计算相同时间间隔内移动对象轨迹的最小“水平”距离;
3.获取在查询条件[d1,d2]内的轨迹;
移动轨迹的动态时间规整,将两条轨迹分割为同步时间的轨迹片段,在这个轨迹片段中,两个轨迹的开始时间和结束时间相同。规整过后的轨迹,计算两个相同时间间隔的轨迹片段的“水平”距离,即两条轨迹的在时间上的距离映射。通过扫描轨迹片段的“水平”距离,得到在查询范围[d1,d2]内的轨迹片段。这些轨迹片段的集合,即为查询的结果。
精细计算算法如下所示:
其中,计算两个对象轨迹的距离的算法如下:
算法Refine返回的Result即为查询的结果集合。
- 还没有人留言评论。精彩留言会获得点赞!