基于组合方法的越南语兼类词消歧方法与流程
本发明涉及基于组合方法的越南语兼类词消歧方法,属于自然语言处理
技术领域:
。
背景技术:
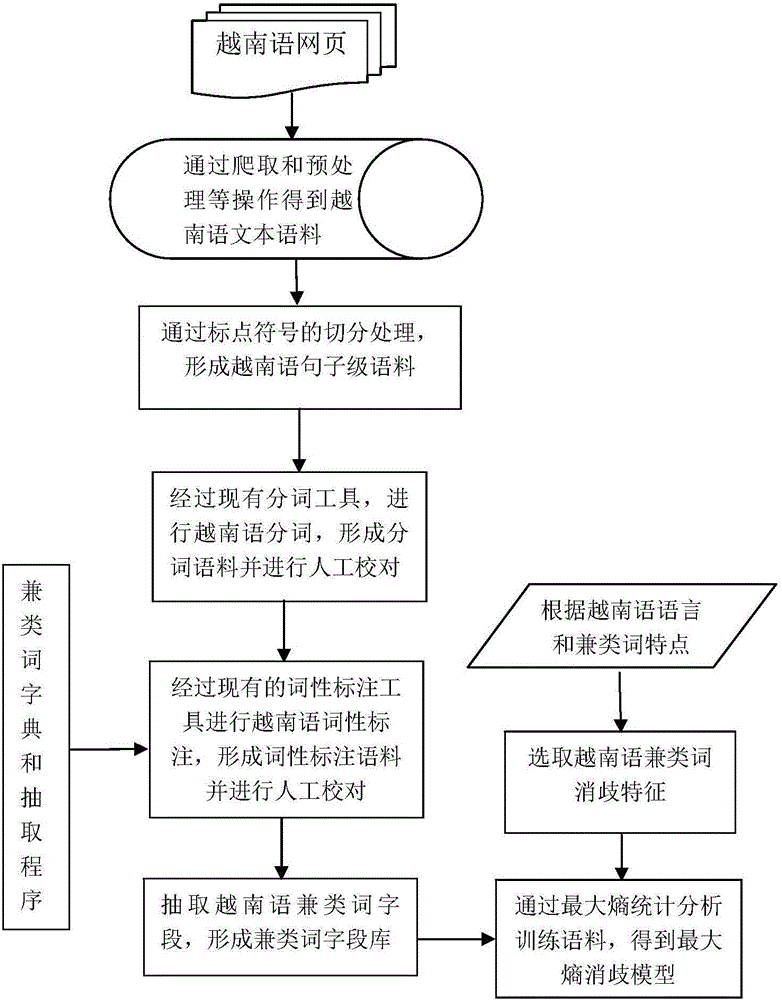
:在越南语自然语言处理领域中,高质量的越南语语料库建设是后续工作的基础、前提和支柱,其可以广泛应用于多个方面,例如:实体识别、名词短语分析、句法分析、语义分析和上层的机器翻译等。越南语兼类词是越南语词性标注工作中的重点和难点,其直接影响着词性标注的准确率,同时对于构建高质量的越南语词性标注语料库有着极其促进的作用;为了解决后续工作的质量和性能,需要构建高质量的词性标注语料库。因此,要构建高质量的越南语词性语料库,需要解决兼类词问题。技术实现要素:本发明提供了基于组合方法的越南语兼类词消歧方法,以用于解决兼类词的消歧、后续越南语词性标注的正确率不高、单一模型识别不足等问题,解决了对于单一学习器会造成泛化性能不佳问题。本发明的技术方案是:基于组合方法的越南语兼类词消歧方法,所述基于组合方法的越南语兼类词消歧方法的具体步骤如下:Step1、首先对越南语句子级词性标注语料,结合越南语兼类词字典,抽取得到越南语兼类词字段库,然后结合越南语语言和兼类词特点,获取越南语消歧特征;Step2、使用最大熵统计分析方法对已形成越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到最大熵的越南语兼类词消歧模型;Step3、使用条件随机场统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到条件随机场的越南语兼类词消歧模型;Step4、使用支撑向量机统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到支持向量机的越南语兼类词消歧模型;Step5、从越南语兼类词字段语料中随机选取部分测试语料分别通过已构建的最大熵的越南语兼类词消歧模型、条件随机场的越南语兼类词消歧模型、支持向量机的越南语兼类词消歧模型进行消歧,分别得到消歧的参数序列;Step6、对分别得到的消歧参数序列进行投票方法确定最终消歧结果,得到最终的兼类词消歧结果。作为本发明的优选方案,所述步骤Step1的具体步骤为:Step1.1、首先利用网络爬虫程序,从互联网上爬取越南语网页语料;Step1.2、把已爬取出的越南语网页语料,经过过滤、去噪音等处理,构建出越南语文本级语料,并把越南语文本级语料存放到数据库中;本发明考虑到爬取到的越南语网页语料中存在一些重复网页、网页标签等噪音,这些噪音是无效的。因此,要通过过滤、去噪音等操作去除,得到只含有越南语的高质量的文本级语料,存放在数据库是为了能方便数据的管理和下一步使用。Step1.3、从Step1.2数据库中取出越南语文本级越南语语料,经过人工处理形成越南语句子级语料,使用越南语分词工具对越南语句子级语料进行分词,并进行人工校对,形成越南语分词句子级语料库,并把越南语分词句子级语料库的语料存放到数据库中;本发明是在已词性标注的基础上进行消歧,若进行词性标注首先进行分词,是不可缺少的一步,同时由于越南语的词是由一个或者多个音节构成,不能按照空格对来确定分词。使用越南语分词工具进行分词之后,需要人工校对,考虑到越南语分词工具不可能正确地切分所有的越南语词,分词错误会影响到下一步的越南语词性标注结果的正确性和兼类词消歧的正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.4、从Step1.3数据库中取出已分词的越南语句子级语料,根据越南语词性标注工具进行越南语句子级分词语料进行词性标注,并进行人工校对,形成越南语词性句子级的语料库,并把越南语句子级词性语料库存放到数据中;本发明是在已词性标注的基础上进行消歧,同时根据本专利已选取的词性及上下文信息作为有效特征,因此需要进行词性标注;使用词性标注工具进行词性标注之后,需要人工校对,主要考虑到任何越南语词性标注工具都不可能完全正确,为了确保语料的高质量和兼类词消歧正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.5、从Step1.4数据库中取出越南语句子级词性标注语料,根据人工编写抽取越南语兼类词程序,结合越南语兼类词字典,进行抽取越南语的兼类词字段,形成越南语兼类词字段库,并把越南语兼类词字段库的字段存放到数据库中;本发明编写越南语兼类词抽取程序;生成越南语兼类词字典,考虑到首先要知道越南语词中那些是兼类词,才能进行越南语兼类词字段信息的抽取,若没有兼类词字典是不能判断句子中越南语词是否是兼类词,更抽取不了相关的字段信息;生成越南语字典,考虑到越南语兼类词是字典当中的一部分,除了越南语词有一个词性之外,其他都是越南语兼类词;收集越南语字典,考虑到要收集到完整的越南语字典(收集的字典越完整,兼类词考虑越全面),需要从多方面途径进行收集,然后对于重复的词,进行去重,综合得到最终的越南语字典。Step1.6、根据越南语语言和兼类词特点,并对Step1.5数据库中越南语兼类词字段进行分析,选取越南语兼类词消歧特征,包括:词信息特征以及上下文特征、词性信息以及上下文特征、成分特征。此优选方案设计是本发明的重要组成部分,主要为本专利提供语料预处理过程,为后续工作提供模型训练时所需训练语料和为模型测试时提供测试语料;并且为本专利选取消歧特征提供了支撑和挖掘的对象。作为本发明的优选方案,所述步骤Step1.5的具体步骤:Step1.5.1、从Step1.4数据库中取出越南语句子级词性标注的语料,得到越南语句子级词性标注语料;Step1.5.2、从网站和字典中收集越南语字典,形成越南语字典;Step1.5.3、从Step1.5.2中得到越南语字典,通过人工进行筛选和抽取,得到越南语兼类词字典;Step1.5.4、通过人工编写的抽取兼类词程序,并结合Step1.5.3中的越南语兼类词字典,对Step1.5.1中得到的越南语句子级词性标注语料进行抽取越南语兼类词,得到越南语兼类词字段信息,并把抽取到的越南语兼类词字段信息存放到数据中。此优选方案设计是抽取越南语兼类词字段信息的重要过程,根据编写的抽取程序并结合越南语兼类词字典,进行抽取越南语兼类词字段,为下一步形成训练与测试语料提供语料基础。作为本发明的优选方案,所述步骤Step2的具体步骤为:Step2.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定最大熵模型中所需要的基本特征模板训练样式语料;Step2.2、用最大熵统计分析方法对Step2.1中训练语料进行建模,得到基于最大熵的越南语兼类词消歧模型。此优选方案设计是生成基于最大熵的越南语兼类词消歧模型,是本发明组合方法之一。最大熵统计分析方法对训练语料进行训练,生成最大熵消歧模型,为本发明兼类词消歧提供一种消歧模型。作为本发明的优选方案,所述步骤Step3的具体步骤为:Step3.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定条件随机场模型中所需要的基本特征模板训练样式语料;Step3.2、用条件随机场统计分析方法对Step3.1中训练语料进行建模,得到基于条件随机场的越南语兼类词消歧模型。此优选方案设计是生成基于条件随机场的越南语兼类词消歧模型,是本发明组合方法之二。条件随机场统计分析方法对训练语料进行训练,生成条件随机场消歧模型,为本发明兼类词消歧提供第二种消歧模型。作为本发明的优选方案,所述步骤Step4的具体步骤为:Step4.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定支撑向量机模型中所需要的基本特征模板训练样式语料;Step4.2、用支撑向量机统计分析方法对Step4.1中训练语料进行建模,得到基于支撑向量机的越南语兼类词消歧模型。此优选方案设计是生成基于支持向量机的越南语兼类词消歧模型,是本发明组合方法之二。支持向量机统计分析方法对训练语料进行训练,生成支持向量机消歧模型,为本发明兼类词消歧提供第三种消歧模型。作为本发明的优选方案,所述步骤Step5的具体步骤为:Step5.1、从数据库中随机选取部分的越南语兼类词字段语料做为测试语料,得到越南语兼类词的测试语料;Step5.2、对越南语兼类词测试语料,使用已构建的基于最大熵的越南语兼类词消歧模型进行消歧,得到最大熵消歧结果;Step5.3、对越南语兼类词测试语料,使用已构建的基于条件随机场的越南语兼类词消歧模型进行消歧,得到条件随机场消歧结果;Step5.4、对越南语兼类词测试语料,使用已构建的基于支持向量机的越南语兼类词消歧模型进行消歧,得到支持向量机消歧结果。此优选方案设计是对本发明中混合方法进行测试。为了验证最大熵、条件随机场、支持向量机模型的性能,为下一步使用使用投票法进行综合最终消歧结果做铺垫。作为本发明的优选方案,所述步骤Step6的具体步骤为:Step6.1、根据得到的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果;如果对同一个兼类词的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果有2个或2个以上的结构一致时,使用投票法进行决定越南语兼类词消歧结果,同一个兼类词选取票数多的为消歧结果;Step6.2、对同一个兼类词的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果都不一致时,选择条件随机场消歧结果作为最终消歧结果。因为条件随机机场该模型能够使用复杂、有重叠性和非独立性的特征进行训练和推理,同时在一定程度上避免歧义问题和数据标注偏执问题。此优选方案设计是对消歧结果进行综合。主要综合三种消歧结果,为越南语兼类词消歧结果确定一个唯一的消歧结果。对本发明作进一步解释的,所述步骤Step1.6中:1)提取到的词信息特征以及上下文特征:越南语词是有一个或多个词素构成,词素的形态含有丰富的信息;本发明可以利用词信息统计词素或词的形态在语料中存在的比例;进行统计分析。选取概率值较大的标记为兼类词标记符号。2)选取的词性信息以及上下文特征:词性特征除了词信息特征外,另一个重要的特征。当前词的词性标记会影响周围词的词性标注,因此本发明选取词性特征;同时词性信息特征是最基本的特征,它能表征词所具有的性质,有利于兼类词的消歧。3)选取的成分特征:成分特征是根据句法分析中获取,即表示当前词在句子中充当何种成分,兼类词在句子中担任不同的成分或角色,兼类词也就选取不同的词性和含义。本发明的有益效果是:1、本发明的基于组合方法的越南语兼类词消歧方法,对越南语的兼类词字段的消歧做了前所未有的工作,目前没有发现越南语在做相关的兼类词消歧方面的报告,本发明取得了很好的效果;2、本发明的基于组合方法的越南语兼类词消歧方法,对越南语兼类词字段实现了有效的消歧,为后续越南语词性标注、词法分析、句法分析、语义分析、信息抽取、信息检索和机器翻译等工作提供强有力的支撑;3、本发明的基于组合方法的越南语兼类词消歧方法,解决了对于单一学习器会造成泛化性能不佳问题;4、本发明的基于组合方法的越南语兼类词消歧方法,有效地集成最大熵、条件随机场、支持向量机各模型的优势,互相弥补不足,能够有利于兼类词的识别。附图说明图1为本发明中的总的流程图;图2为本发明中的最大熵方法建模流程图;图3为本发明中的条件随机场方法建模流程图;图4为本发明中的支持向量机方法建模流程图;图5为本发明中的兼类词消歧方法应用的流程图。具体实施方式实施例1:如图1-5所示,基于组合方法的越南语兼类词消歧方法,所述基于组合方法的越南语兼类词消歧方法的具体步骤如下:Step1、首先对越南语句子级词性标注语料,结合越南语兼类词字典,抽取得到越南语兼类词字段库,然后结合越南语语言和兼类词特点,获取越南语消歧特征;Step2、使用最大熵统计分析方法对已形成越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到最大熵的越南语兼类词消歧模型;Step3、使用条件随机场统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到条件随机场的越南语兼类词消歧模型;Step4、使用支撑向量机统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到支持向量机的越南语兼类词消歧模型;Step5、从越南语兼类词字段语料中随机选取部分测试语料分别通过已构建的最大熵的越南语兼类词消歧模型、条件随机场的越南语兼类词消歧模型、支持向量机的越南语兼类词消歧模型进行消歧,分别得到消歧的参数序列;Step6、对分别得到的消歧参数序列进行投票方法确定最终消歧结果,得到最终的兼类词消歧结果。实施例2:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例1相同,其中:作为本发明的优选方案,所述步骤Step1的具体步骤为:Step1.1、首先利用网络爬虫程序,从互联网上爬取越南语网页语料;Step1.2、把已爬取出的越南语网页语料,经过过滤、去噪音等处理,构建出越南语文本级语料,并把越南语文本级语料存放到数据库中;本发明考虑到爬取到的越南语网页语料中存在一些重复网页、网页标签等噪音,这些噪音是无效的。因此,要通过过滤、去噪音等操作去除,得到只含有越南语的高质量的文本级语料,存放在数据库是为了能方便数据的管理和下一步使用。Step1.3、从Step1.2数据库中取出越南语文本级越南语语料,经过人工处理形成越南语句子级语料,使用越南语分词工具对越南语句子级语料进行分词,并进行人工校对,形成越南语分词句子级语料库,并把越南语分词句子级语料库的语料存放到数据库中;本发明是在已词性标注的基础上进行消歧,若进行词性标注首先进行分词,是不可缺少的一步,同时由于越南语的词是由一个或者多个音节构成,不能按照空格对来确定分词。使用越南语分词工具进行分词之后,需要人工校对,考虑到越南语分词工具不可能正确地切分所有的越南语词,分词错误会影响到下一步的越南语词性标注结果的正确性和兼类词消歧的正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.4、从Step1.3数据库中取出已分词的越南语句子级语料,根据越南语词性标注工具进行越南语句子级分词语料进行词性标注,并进行人工校对,形成越南语词性句子级的语料库,并把越南语句子级词性语料库存放到数据中;本发明是在已词性标注的基础上进行消歧,同时根据本专利已选取的词性及上下文信息作为有效特征,因此需要进行词性标注;使用词性标注工具进行词性标注之后,需要人工校对,主要考虑到任何越南语词性标注工具都不可能完全正确,为了确保语料的高质量和兼类词消歧正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.5、从Step1.4数据库中取出越南语句子级词性标注语料,根据人工编写抽取越南语兼类词程序,结合越南语兼类词字典,进行抽取越南语的兼类词字段,形成越南语兼类词字段库,并把越南语兼类词字段库的字段存放到数据库中;本发明编写越南语兼类词抽取程序;生成越南语兼类词字典,考虑到首先要知道越南语词中那些是兼类词,才能进行越南语兼类词字段信息的抽取,若没有兼类词字典是不能判断句子中越南语词是否是兼类词,更抽取不了相关的字段信息;生成越南语字典,考虑到越南语兼类词是字典当中的一部分,除了越南语词有一个词性之外,其他都是越南语兼类词;收集越南语字典,考虑到要收集到完整的越南语字典(收集的字典越完整,兼类词考虑越全面),需要从多方面途径进行收集,然后对于重复的词,进行去重,综合得到最终的越南语字典。Step1.6、根据越南语语言和兼类词特点,并对Step1.5数据库中越南语兼类词字段进行分析,选取越南语兼类词消歧特征,包括:词信息特征以及上下文特征、词性信息以及上下文特征、成分特征。此优选方案设计是本发明的重要组成部分,主要为本专利提供语料预处理过程,为后续工作提供模型训练时所需训练语料和为模型测试时提供测试语料;并且为本专利选取消歧特征提供了支撑和挖掘的对象。实施例3:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例2相同,其中:作为本发明的优选方案,所述步骤Step1.5的具体步骤:Step1.5.1、从Step1.4数据库中取出越南语句子级词性标注的语料,得到越南语句子级词性标注语料;Step1.5.2、从网站和字典中收集越南语字典,形成越南语字典;Step1.5.3、从Step1.5.2中得到越南语字典,通过人工进行筛选和抽取,得到越南语兼类词字典;Step1.5.4、通过人工编写的抽取兼类词程序,并结合Step1.5.3中的越南语兼类词字典,对Step1.5.1中得到的越南语句子级词性标注语料进行抽取越南语兼类词,得到越南语兼类词字段信息,并把抽取到的越南语兼类词字段信息存放到数据中。此优选方案设计是抽取越南语兼类词字段信息的重要过程,根据编写的抽取程序并结合越南语兼类词字典,进行抽取越南语兼类词字段,为下一步形成训练与测试语料提供语料基础。实施例4:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例3相同,其中:作为本发明的优选方案,所述步骤Step2的具体步骤为:Step2.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定最大熵模型中所需要的基本特征模板训练样式语料;Step2.2、用最大熵统计分析方法对Step2.1中训练语料进行建模,得到基于最大熵的越南语兼类词消歧模型。此优选方案设计是生成基于最大熵的越南语兼类词消歧模型,是本发明组合方法之一。最大熵统计分析方法对训练语料进行训练,生成最大熵消歧模型,为本发明兼类词消歧提供一种消歧模型。实施例5:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例4相同,其中:作为本发明的优选方案,所述步骤Step3的具体步骤为:Step3.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定条件随机场模型中所需要的基本特征模板训练样式语料;Step3.2、用条件随机场统计分析方法对Step3.1中训练语料进行建模,得到基于条件随机场的越南语兼类词消歧模型。此优选方案设计是生成基于条件随机场的越南语兼类词消歧模型,是本发明组合方法之二。条件随机场统计分析方法对训练语料进行训练,生成条件随机场消歧模型,为本发明兼类词消歧提供第二种消歧模型。实施例6:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例5相同,其中:作为本发明的优选方案,所述步骤Step4的具体步骤为:Step4.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定支撑向量机模型中所需要的基本特征模板训练样式语料;Step4.2、用支撑向量机统计分析方法对Step4.1中训练语料进行建模,得到基于支撑向量机的越南语兼类词消歧模型。此优选方案设计是生成基于支持向量机的越南语兼类词消歧模型,是本发明组合方法之二。支持向量机统计分析方法对训练语料进行训练,生成支持向量机消歧模型,为本发明兼类词消歧提供第三种消歧模型。实施例7:如图1-5所示,基于组合方法的越南语兼类词消歧方法,本实施例与实施例6相同,其中:作为本发明的优选方案,所述步骤Step5的具体步骤为:Step5.1、从数据库中随机选取部分的越南语兼类词字段语料做为测试语料,得到越南语兼类词的测试语料;Step5.2、对越南语兼类词测试语料,使用已构建的基于最大熵的越南语兼类词消歧模型进行消歧,得到最大熵消歧结果;Step5.3、对越南语兼类词测试语料,使用已构建的基于条件随机场的越南语兼类词消歧模型进行消歧,得到条件随机场消歧结果;Step5.4、对越南语兼类词测试语料,使用已构建的基于支持向量机的越南语兼类词消歧模型进行消歧,得到支持向量机消歧结果。此优选方案设计是对本发明中混合方法进行测试。为了验证最大熵、条件随机场、支持向量机模型的性能,为下一步使用使用投票法进行综合最终消歧结果做铺垫。实施例8:如图1-5所示,基于组合方法的越南语兼类词消歧方法,所述基于组合方法的越南语兼类词消歧方法的具体步骤如下:Step1、首先对越南语句子级词性标注语料,结合越南语兼类词字典,抽取得到越南语兼类词字段库,然后结合越南语语言和兼类词特点,获取越南语消歧特征;Step2、使用最大熵统计分析方法对已形成越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到最大熵的越南语兼类词消歧模型;Step3、使用条件随机场统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到条件随机场的越南语兼类词消歧模型;Step4、使用支撑向量机统计分析方法对已形成的越南语兼类词字段库中的越南语兼类词字段语料进行消歧建模,得到支持向量机的越南语兼类词消歧模型;Step5、从越南语兼类词字段语料中随机选取部分测试语料分别通过已构建的最大熵的越南语兼类词消歧模型、条件随机场的越南语兼类词消歧模型、支持向量机的越南语兼类词消歧模型进行消歧,分别得到消歧的参数序列;Step6、对分别得到的消歧参数序列进行投票方法确定最终消歧结果,得到最终的兼类词消歧结果。作为本发明的优选方案,所述步骤Step1的具体步骤为:Step1.1、首先利用网络爬虫程序,从互联网上爬取越南语网页语料;Step1.2、把已爬取出的越南语网页语料,经过过滤、去噪音等处理,构建出越南语文本级语料,并把越南语文本级语料存放到数据库中;本发明考虑到爬取到的越南语网页语料中存在一些重复网页、网页标签等噪音,这些噪音是无效的。因此,要通过过滤、去噪音等操作去除,得到只含有越南语的高质量的文本级语料,存放在数据库是为了能方便数据的管理和下一步使用。Step1.3、从Step1.2数据库中取出越南语文本级越南语语料,经过人工处理形成越南语句子级语料,使用越南语分词工具对越南语句子级语料进行分词,并进行人工校对,形成越南语分词句子级语料库,并把越南语分词句子级语料库的语料存放到数据库中;本发明是在已词性标注的基础上进行消歧,若进行词性标注首先进行分词,是不可缺少的一步,同时由于越南语的词是由一个或者多个音节构成,不能按照空格对来确定分词。使用越南语分词工具进行分词之后,需要人工校对,考虑到越南语分词工具不可能正确地切分所有的越南语词,分词错误会影响到下一步的越南语词性标注结果的正确性和兼类词消歧的正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.4、从Step1.3数据库中取出已分词的越南语句子级语料,根据越南语词性标注工具进行越南语句子级分词语料进行词性标注,并进行人工校对,形成越南语词性句子级的语料库,并把越南语句子级词性语料库存放到数据中;本发明是在已词性标注的基础上进行消歧,同时根据本专利已选取的词性及上下文信息作为有效特征,因此需要进行词性标注;使用词性标注工具进行词性标注之后,需要人工校对,主要考虑到任何越南语词性标注工具都不可能完全正确,为了确保语料的高质量和兼类词消歧正确性,存放到数据库为了能方便数据的管理和下一步使用。Step1.5、从Step1.4数据库中取出越南语句子级词性标注语料,根据人工编写抽取越南语兼类词程序,结合越南语兼类词字典,进行抽取越南语的兼类词字段,形成越南语兼类词字段库,并把越南语兼类词字段库的字段存放到数据库中;本发明编写越南语兼类词抽取程序;生成越南语兼类词字典,考虑到首先要知道越南语词中那些是兼类词,才能进行越南语兼类词字段信息的抽取,若没有兼类词字典是不能判断句子中越南语词是否是兼类词,更抽取不了相关的字段信息;生成越南语字典,考虑到越南语兼类词是字典当中的一部分,除了越南语词有一个词性之外,其他都是越南语兼类词;收集越南语字典,考虑到要收集到完整的越南语字典(收集的字典越完整,兼类词考虑越全面),需要从多方面途径进行收集,然后对于重复的词,进行去重,综合得到最终的越南语字典。Step1.6、根据越南语语言和兼类词特点,并对Step1.5数据库中越南语兼类词字段进行分析,选取越南语兼类词消歧特征,包括:词信息特征以及上下文特征、词性信息以及上下文特征、成分特征。此优选方案设计是本发明的重要组成部分,主要为本专利提供语料预处理过程,为后续工作提供模型训练时所需训练语料和为模型测试时提供测试语料;并且为本专利选取消歧特征提供了支撑和挖掘的对象。作为本发明的优选方案,所述步骤Step1.5的具体步骤:Step1.5.1、从Step1.4数据库中取出越南语句子级词性标注的语料,得到越南语句子级词性标注语料;Step1.5.2、从网站和字典中收集越南语字典,形成越南语字典;Step1.5.3、从Step1.5.2中得到越南语字典,通过人工进行筛选和抽取,得到越南语兼类词字典;Step1.5.4、通过人工编写的抽取兼类词程序,并结合Step1.5.3中的越南语兼类词字典,对Step1.5.1中得到的越南语句子级词性标注语料进行抽取越南语兼类词,得到越南语兼类词字段信息,并把抽取到的越南语兼类词字段信息存放到数据中。此优选方案设计是抽取越南语兼类词字段信息的重要过程,根据编写的抽取程序并结合越南语兼类词字典,进行抽取越南语兼类词字段,为下一步形成训练与测试语料提供语料基础。作为本发明的优选方案,所述步骤Step2的具体步骤为:Step2.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定最大熵模型中所需要的基本特征模板训练样式语料;Step2.2、用最大熵统计分析方法对Step2.1中训练语料进行建模,得到基于最大熵的越南语兼类词消歧模型。此优选方案设计是生成基于最大熵的越南语兼类词消歧模型,是本发明组合方法之一。最大熵统计分析方法对训练语料进行训练,生成最大熵消歧模型,为本发明兼类词消歧提供一种消歧模型。作为本发明的优选方案,所述步骤Step3的具体步骤为:Step3.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定条件随机场模型中所需要的基本特征模板训练样式语料;Step3.2、用条件随机场统计分析方法对Step3.1中训练语料进行建模,得到基于条件随机场的越南语兼类词消歧模型。此优选方案设计是生成基于条件随机场的越南语兼类词消歧模型,是本发明组合方法之二。条件随机场统计分析方法对训练语料进行训练,生成条件随机场消歧模型,为本发明兼类词消歧提供第二种消歧模型。作为本发明的优选方案,所述步骤Step4的具体步骤为:Step4.1、根据选取的越南语兼类词消歧特征,并结合获取得到的越南语兼类词字段语料,制定支撑向量机模型中所需要的基本特征模板训练样式语料;Step4.2、用支撑向量机统计分析方法对Step4.1中训练语料进行建模,得到基于支撑向量机的越南语兼类词消歧模型。此优选方案设计是生成基于支持向量机的越南语兼类词消歧模型,是本发明组合方法之二。支持向量机统计分析方法对训练语料进行训练,生成支持向量机消歧模型,为本发明兼类词消歧提供第三种消歧模型。作为本发明的优选方案,所述步骤Step5的具体步骤为:Step5.1、从数据库中随机选取部分的越南语兼类词字段语料做为测试语料,得到越南语兼类词的测试语料;Step5.2、对越南语兼类词测试语料,使用已构建的基于最大熵的越南语兼类词消歧模型进行消歧,得到最大熵消歧结果;Step5.3、对越南语兼类词测试语料,使用已构建的基于条件随机场的越南语兼类词消歧模型进行消歧,得到条件随机场消歧结果;Step5.4、对越南语兼类词测试语料,使用已构建的基于支持向量机的越南语兼类词消歧模型进行消歧,得到支持向量机消歧结果。此优选方案设计是对本发明中混合方法进行测试。为了验证最大熵、条件随机场、支持向量机模型的性能,为下一步使用使用投票法进行综合最终消歧结果做铺垫。作为本发明的优选方案,所述步骤Step6的具体步骤为:Step6.1、根据得到的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果;如果对同一个兼类词的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果有2个或2个以上的结构一致时,使用投票法进行决定越南语兼类词消歧结果,同一个兼类词选取票数多的为消歧结果;Step6.2、对同一个兼类词的最大熵消歧结果、条件随机场消歧结果、支持向量机消歧结果都不一致时,选择条件随机场消歧结果作为最终消歧结果。因为条件随机机场该模型能够使用复杂、有重叠性和非独立性的特征进行训练和推理,同时在一定程度上避免歧义问题和数据标注偏执问题。此优选方案设计是对消歧结果进行综合。主要综合三种消歧结果,为越南语兼类词消歧结果确定一个唯一的消歧结果。从构建好的越南语兼类词字段语料中取出兼类词字段测试语料;这些待消歧的兼类词最好是没有包含在组合方法模型中所需要的基本特征模板训练样式的训练语料当中,这样为了测试消歧模型的正确率;正确率是评价一个模型被消歧兼类词正确的个数与被消歧兼类词总个数的比值,可以用来衡量模型的好坏;本发明采用准确率作为对越南语组合方法的兼类词消歧模型的测评标准,准确率为正确的消歧结果。定义如下:p=NrNc×100%]]>其中,Nr为测试语料中兼类词正确标记的个数,Nc为测试语料中的兼类词标记总数,正确率越高,说明组合方法越好。为了弄清楚两类特征对兼类词消歧组合模型的贡献程度,我们将词信息特征以及上下文特征、词性信息以及上下文特征分别作为独立特征构建越南语兼类词组合方法消歧模型,各个特征的贡献程度通过准确率进行比较,如表1所示。表1两类特征分别实验编号特征实验方式准确率1词信息特征以及上下文特征组合方式72.36%2词性信息以及上下文特征组合方式71.37%从表1可以看出,独立使用词信息特征以及上下文特征兼类词消歧模型时的准确率为72.36%,比独立使用词性信息以及上下文特征高出0.99%。由此可见,词信息特征对兼类词消歧有巨大影响,然后是词性信息的上下文特征,而本发明采用了两个结合的特征,能更好的表征词所具有的性质,有利于兼类词的消歧。为了评估歧义组合模型的效果,我们将越南语兼类词字段语料库中含有的396946条兼类词字段分别为五份,其中一份做测试语料,另外四份作为训练语料,做五倍交叉验证实验,然后求其平均准确率,作为越南语组合方法的兼类词消歧模型的测评结果。实验结果如表2所示。表2五倍交叉验证实验编号特征实验方式准确率1第一份作为测试语料,剩余四份作为训练语料组合方式90.86%2第二份作为测试语料,剩余四份作为训练语料组合方式89.39%3第三份作为测试语料,剩余四份作为训练语料组合方式88.23%4第四份作为测试语料,剩余四份作为训练语料组合方式89.05%5第五份作为测试语料,剩余四份作为训练语料组合方式88.76%从表2中可以看出,编号1实验的准确率达到了90.86%,为局部最高。对五倍交叉验证的实验结果求平均,得到越南语组合方法的兼类词消歧模型的准确率为89.26%。目前没有发现越南语做相关的兼类词消歧的研究,为了进一步评估越南语组合方法的兼类词消歧模型的效果,我们同时也用单一模型与本发明组合方法进行对比实验。实验结果如表3所示。表3模型对比实验模型实验方式平均准确率条件随机场(CRFs)五倍交叉验证85.40%最大熵(Maxent)五倍交叉验证80.63%支持向量机(SVM)五倍交叉验证85.23%CRFs+Maxent+SVM五倍交叉验证89.26%从表3中可以看出,通过组合方法训练得到的兼类词词性标记模型的平均准确率比CRFs高3.86%、比Maxent高8.63%、比SVM高4.03%。可见组合方法在在兼类词消歧问题上比单一方法消歧的效果好。主要体现:1)组合方法可以弥补各方法的不足;2)通过组合方法的投票法进行最终确定兼类词的识别结果,增加可信度。上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1