一种基于大数据分析建立疾病云图的方法与流程
本发明涉及疾病预测分析
技术领域:
方法,尤其涉及一种基于大数据分析建立疾病云图的方法。
背景技术:
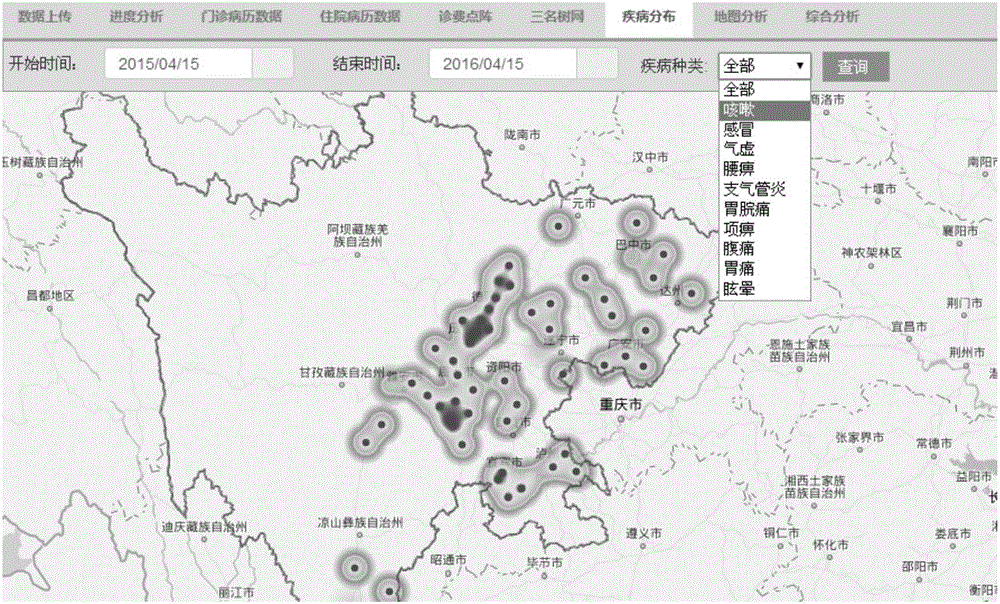
:在医疗临床诊断信息中,存在着大量的关于患者病情和个人的信息,包括患者的病史和某种疾病与各种症状,对这些医学数据进行关联分析,挖掘出其中隐藏着的大量的关联规则,如症状属性之间的关系,可以预测疾病的发展趋势并且辅助医生评估健康情况,做出诊断,对疾病的预防和治疗都有重要的意义。在数据挖掘技术中,若两个或多个变量的取值之间存在着某种规律性,就称其为关联(association)。关联反映一个事件和其它事件之间的依赖关系或频繁出现的程度。关联可分为简单关联、时序关联、因果关联和数量关联等。数据之间的关联是复杂的,大部分是蕴藏在大量数据后无法观察得知的。关联分析(associationanalysis)就是用于发现隐藏在大型数据集中的有价值的联系。关联分析所发现的联系可以用关联规则或者频繁项集的形式表示。关联规则(associationrule)是指在同一时间中出现的不同属性项的相关性。从广义上讲,关联分析是数据挖掘的本质,既然数据挖掘的目的是发现潜藏在数据背后的知识,那么这种知识一定是反映不同对象之间的关系;狭义上讲,关联分析是指一类特定的数据挖掘技术,主要目的是挖掘数据库中对象之间的关联。关联规则挖掘就是从大量的数据中挖掘出描述数据项之间相互联系的有价值的知识。GIS具有对海量空间数据存储、分析的特点,又能迅速而又直观地输出分析结果,所以成为现代医学研究有力的辅助工具,也被逐渐应用于疾病预防和控制领域。大部分的流行病学研究资料都具有空间属性,如人群和动物的发病感染情况、宿主媒介的分布、温湿度、降雨、土壤和卫生设施等都与地理位置有关,GIS可以通过空间关系将这些数据连接起来,进行交互显示和分析,同时也为以后的统计分析提供基础。技术实现要素:本发明旨在提供一种基于大数据分析建立疾病云图的方法,为达到上述目的,本发明采用的技术方案如下:一种基于大数据分析建立疾病云图的方法,利用GIS地图和大数据架构技术,展示疾病在空间、时间上的分布情况,包括以下步骤:步骤1.采集数据:获取电子病历数据;步骤2.数据清洗和处理;对步骤1获得的数据进行转换和清洗;转换包括将不规范的病名进行转换,通过转换将不规范的病名统一为标准规范的病名;通过清洗,将不合理、可能影响预测结果的数据进行剔除;步骤3.采用数据挖掘技术对步骤2转换和清理后的数据进行关联分析,挖掘出频繁项集,根据频繁项集获得症状属性之间的关联规则,根据关联规则建立“疾病种类-患病时间-患病人数-地理位置”的结果集;步骤4.调用GIS地图数据,读取步骤3获得的结果集,根据结果集展示出疾病在空间、时间上的分布情况。进一步的,所述步骤2中,对于有属性值的数据进行规范属性取值:其中对取值既有文字又有离散数据的属性将文字量化分类,转化为离散属性;对于只有文字的属性根据业务定性,并将文字属性转化为离散属性;对于只有离散数据的属性则删除该属性;对于属性缺值的数据有两种处理方式:方式1:将缺值作为一种取值形式;方式2:忽略此属性。进一步的,所述步骤3中,设定最小支持度和最小信任度,将大于和/或等于最小支持度和最小信任度的关联规则作为强关联规则,如果一个患者的患病症状满足某种疾病症状属性的强关联规则,则认为其是这种疾病的患者,继而获取该患者的患病时间和地理位置,同时对患病人数进行统计。进一步的,所述步骤3中采用以下步骤挖掘频繁项集:3.1遍历某种疾病的所有候选症状属性,确定各项属性的支持频度,其中所有候选症状属性组成候选1项集:H1;3.2设定最小支持频度,将H1中所有属性的支持频度与最小支持频度进行比较,将H1中支持频度大于最小支持频度的属性组成频繁1项集F1;3.3然后采用下列方法挖掘出频繁k+1项集:Fk+1;(1)利用连接操作(Fk)⊕(Fk),来确定候选k+1项集:Hk+1,其中K=1,2…n;(2)对Hk+1中的属性进行扫描,计算出Hk+1中每个属性的支持频度,将Hk+1中所有支持频度大于或等于最小支持频度的属性组成频繁K+1项集:Fk+1;Fk中项集数目为|Fk|,则Ck+1中有个属性;Ck+1是频繁项集的候选集,即Ck+1包括了H1、…HK+1;(3)当项集中所有属性元素的支持频度都小于最小支持频度时,结束算法;根据挖掘出的频繁项集Fk+1获取满足最小支持度和最小信任度的强关联规则,其中K=0,1,…n。进一步的,利用公式(1)计算所获关联规则的信任度;Confidence(H⇒F)=P(H/F)=support_count(H∪F)support_count(H)---(1)]]>式(1)中,support_count(H∪F)为包含项集H∪F的事物数,support_count(H)为包含项集H的事物数,其中H是候选项集,F为频繁项集,若则认为这个关联规则为强关联规则,其中min_counf为设置的最小信任度阀值。根据该公式,关联原则可以产生如下:对于每个频繁项集L,产生L的所有非空子集,对于L的每个非空子集,若则产生一个强关联规则其中,min_counf为设置的最小信任度阀值。由于规则是通过频繁项集直接产生的,因此关联规则所涉及的所有项集均满足最小支持度阈值。频繁项集及其支持频度可以存储在列表中,使得他们能够被快速存取。使用Apriori算法对所统计的病历信息进行关联规则挖掘。进一步的,所述步骤3中,根据强关联规则,将结果数据储存在结果表中,其中疾病种类、患病时间、患病人数和地理位置作为结果表的列族成员。优选的,所述步骤4中,在百度地图上增加图层,以热力图的形式展示某种疾病在空间、时间和人群中的地理分布情况,其中图层的覆盖区域根据地理位置获得,图层透明度根据该区域内的患病人数获得。进一步的,所述步骤1之前还包括,对图层数据进行初始化。进一步的,所述步骤4中对百度地图做二次接口开发,实现数据模型和GIS地图的互联互通和应用响应。本发明具有以下有益效果:1.本发明利用GIS地图和大数据架构技术,展示疾病在空间、时间中的地理分布情况,为研究疾病的流行规律和探索疾病病因的提供基础数据;2.整合不同平台的电子病历数据,解决以前数据分散、效率低下难以进行数据集成和综合分析的问题;3.通过对疾病云图数据分布的描述,认识疾病流行的基本特征,是临床诊断很有价值的重要信息;4.对疾病分布规律和决定因素的分析有助于为合理地制订疾病的防制、保健对策及措施提供科学依据。附图说明图1是胃脘痛的地理分布效果图;图2是咳嗽的地理分布效果图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明作进一步详细说明。实施例1本实施例公开的基于大数据分析建立疾病云图的方法,利用GIS地图和大数据架构技术,展示疾病在空间、时间中的地理分布情况,包括以下步骤:步骤1.采集数据:获取电子病历数据。进一步的,电子病历数据来源于大数据采集平台。大数据采集平台,采用云计算模式的医疗数据采集技术,采集80多家医院的临床病历资料,数据采用xml文件形式处理,提供统一、便捷的上传接口,支持实时文件处理情况查询、上传批次管理以及问题数据回滚,同时兼容其他数据格式处理和接口方式。步骤2.数据清洗和处理;对步骤1获得的数据进行转换和清洗,转换包括将不规范的病名进行转换,比如‘胃脘小痛'转换为‘胃脘痛',通过转换将不规范的病名统一为标准规范的病名。然后通过清洗,对不合理、可能影响预测结果的数据进行剔除,如删除病名为空的记录。步骤3.采用数据挖掘技术对步骤2转换和清理后的数据进行关联分析,挖掘出频繁项集,根据频繁项集获得症状属性之间的关联规则,根据关联规则建立“疾病种类-患病时间-患病人数-地理位置”的结果集;步骤4.调用GIS地图数据,根据数据模型展示出疾病在空间、时间上的分布情况。本实施例中利用前端技术,读取后台数据挖掘后的结果集,然后将疾病的分别情况展现在GIS的图层上即可。前端技术又称前端技术开发,是通过java语言开发前端页面,并读取后台数据,展现到前端页面。前端页面可以是已经存在的前端平台,也可以通过以下方法针对疾病云图单独建立一个前端页面:1.编写前端html页面,并在java代码里调用百度地图的接口,从而实现基础地图的加载;2.在代码里编写一个图层,定义时间、病种、人数、地区等传入参数,以及参数的分档;3.在java代码里编写数据库接口函数,实现从数据挖掘的结果集里查询出满足条件的记录,并传给参数;4.参数接到数据后则会根据步骤3建立的关联规则,展示在GIS地图上。参数分档:对不同程度级别采用不同颜色表示,最小值=0、最大值=病人总数,然后按照占比分档,并用不同颜色代表,然后根据各个地区所在的档级,在GIS地图上显示各个地区对应的颜色。进一步的,所述步骤2中,对于有属性值的数据进行规范属性取值:其中对取值既有文字又有离散数据的属性将文字量化分类,转化为离散属性;对于只有文字的属性根据业务定性,并将文字属性转化为离散属性;对于只有离散数据的属性则删除该属性;对于属性缺值的数据有两种处理方式:方式1:将缺值作为一种取值形式;方式2:忽略此属性。根据数据情况来看,对于病名相对完整可以确定属性的,可取;对于属性模糊不可确定属性的,则忽略。进一步的,所述步骤3中,设定最小支持度和最小信任度,将大于和/或等于最小支持度和最小信任度的关联规则作为强关联规则,如果一个患者的患病症状满足某种疾病症状属性的强关联规则,则认为其是这种疾病的患者,继而获取该患者的患病时间和地理位置,同时对患病人数进行统计。进一步的,所述步骤3中采用以下步骤挖掘频繁项集:3.1遍历某种疾病的所有候选症状属性,确定各项属性的支持频度,其中所有候选症状属性组成候选1项集:H1。频度就是出现的次数,用统计方法统计出来即可。3.2设定最小支持频度:min_support,将H1中所有属性的支持频度与min_support进行比较,将H1中支持频度大于min_support的属性组成频繁1项集F1;3.3然后采用下列方法挖掘出频繁k+1项集:Fk+1;(1)利用连接操作(Fk)⊕(Fk),来确定候选k+1项集:Hk+1,其中K=1,2…n;(2)对Hk+1中的属性进行扫描,计算出Hk+1中每个属性的支持频度,将Hk+1中所有支持频度大于min_support的属性组成频繁K+1项集:Fk+1;Fk中项集数目为|Fk|,则Ck+1中有个属性;Ck+1是频繁项集的候选集,即Ck+1包括了H1、…HK+1;(3)当项集中所有属性元素的支持频度都小于min_support时,结束算法;根据挖掘出的频繁项集Fk+1获取满足最小支持度和最小信任度的强关联规则,其中K=0,1,…n。进一步的,利用公式(1)计算所获关联规则的信任度;Confidence(H⇒F)=P(H/F)=support_count(H∪F)support_count(H)---(1)]]>式(1)中,support_count(H∪F)为包含项集H∪F的事物数,support_count(H)为包含项集H的事物数,其中H是候选项集,F为频繁项集,若则认为这个关联规则为强关联规则,其中min_counf为设置的最小信任度阀值。根据该公式,关联原则可以产生如下:对于每个频繁项集L,产生L的所有非空子集,对于L的每个非空子集,若则产生一个强关联规则其中,min_counf为设置的最小信任度阀值。由于规则是通过频繁项集直接产生的,因此关联规则所涉及的所有项集均满足最小支持度阈值。频繁项集及其支持频度可以存储在列表中,使得它们能够被快速存取。进一步的,在步骤3中,根据强关联规则,将结果数据储存在结果表中,其中疾病种类、患病时间、患病人数和地理位置作为结果表的列族成员。优选的,步骤4中在百度地图上增加图层,以热力图的形式展示某种疾病在空间、时间和人群中的地理分布情况,其中图层的覆盖区域根据地理位置获得,图层透明度根据该区域内的患病人数获得。进一步的,在步骤1之前对图层数据进行初始化。进一步的,在步骤4中对百度地图做二次接口开发,实现数据模型和GIS地图的互联互通和应用响应。实施例2本实施例以胃脘痛疾病为例,对本发明方法进行详细说明。(1)原始病历数据的预处理数据来源某医院大数据仓库中的1000例胃脘痛疾病患者的病历数据。所有数据均来源于实际病历,排除在收录、采集和抽取中的操作人员等人为因素,此病历信息是完全真实可信的医学数据。由于医学数据的复杂性、多样性和冗余性,为了避免数据挖掘过程陷入混乱,得到更精确的实验结果,首先我对患者的病历数据进行了预处理。原始病历数据的属性共有36个。通过观察研究,发现原始数据中存在着大量的数据噪音和冗余数据等问题,如属性“疾病疼痛持续时间”有诸如“0”、“5~6分钟”、“30分钟”、“1~10分钟”等近10余个取值且极不规范,而“阵发性夜间呼吸困难”和“疼痛放散部位”属性中的取值也极不规范,包括空值、0、1类型的离散数据与“不能平卧”“双肩背部”“肩背部颈部下颌部及左手臂至左指未端”等文字描述,一些属性存在着绝大部分取值缺值的情况。对于这种情况,本实施例中采取如下方法对数据进行预处理:1.规范属性取值:对取值既有文字又有离散数据的属性根据具体情况将文字描述量化分类,转化为离散属性。例如对“疾病疼痛持续时间”,本文将不规范描述如“0”、“5~6分钟”、“30分钟”等量化为“0”——“无疼痛”,“1”——“疼痛持续时间小于10分钟”,“2”——“疼痛持续时间大于10分钟且小于30分钟”,“3”——“疼痛持续时间大于30分钟”。对于“阵发性夜间呼吸困难”中的“不能平卧”就设置为“0”“1”之外的第三种取值“2”;2.对于属性缺值情况,有两种处理方式,一是将缺值作为一种取值形式,二是忽略此属性。选择哪种方式要具体问题具体分析,如原始数据中“病理性Q波”属性,450例病历中完全没有一例取值,故将此属性忽略;而对“心律失常”“心电图检测”两个属性,只存在少量缺值,而且根据医学常识可知这两项属性在诊断胃脘痛时占有重要地位,在处理时本文将两个属性的缺值假定设置为“无异常”。除上述处理方法外,还要注重对患者隐私的保护,确保所使用数据不暴露患者任何隐私信息。(2)频繁项集的挖掘过程模型算法的选取:针对同一种模型选择适合的算法,本实施例以apriori算法为参考,并做了适度优化。表1为胃脘痛的病历信息数据表,胃脘痛共有6个症状体征属性,为了挖掘出各种症状属性之间的关联,使用Apriori的改进算法对数据进行关联规则挖掘。表1:胃脘痛患者病历信息表1中各属性及取值含义如下:A=打嗝;B=胀气;C=恶心;D=呕吐;E=腹泻;F=胸闷;G=胃病史;H=劳累或活动后加重;I=休息后可自行缓解;J=含服硝酸脂类等药物能缓解;K=阵发性疼痛。属性取值为“1”代表此项症状存在,“0”代表此项症状为不存在。如序号为1的患者病历信息显示此患者有打嗝,且有恶心与腹泻症状。使用Apriori改进算法对表4.1中症状属性之间的关系进行关联分析,其中的关键步骤是使用频繁K-1项集:Fk-1生成频繁K项集Fk,这一过程分为两个步骤:首先,将Fk-1中任一两个子项集连接,获得一个候选集合Ck;然后,对Ck中的各元素进行筛选,因为Ck中的各项集未必都是频繁项集,继而得到符合要求的项集组成Fk。下面结合此病历数据详细说明频繁项集的挖掘过程:2.1将所有候选症状属性遍历一次,确定各项的支持频度,所有属性组成候选1项集:H1;2.2设定最小支持频度:min_support=10%,将H1中所有属性的支持频度与min_support比较,其中所有支持频度大于min_support的属性组成频繁1项集:F1,在本病历数据中,F1中所有组成元素和支持频度如表2所示:表2:频繁1项集属性Support%打嗝40.909胀气54.541恶心27.273呕吐63.636腹泻63.636胸闷54.541胃病史63.636劳累或活动后加重22.727休息后可自行缓解27.273含服硝酸脂类等药物能缓解22.727阵发性疼痛40.9092.3利用连接操作(F1)⊕(F1)确定候选2项集H2,频繁1项集中项集数目为|F1|,则C2中有个属性,C2是频繁2项集的候选集,即C2包括了H1、H2;2.4对H2中的属性进行扫描,计算出每个属性的支持频度;2.5将2.4中得到的所有支持频度大于min_support的属性组成频繁2项集:F2。在本实施例中,频繁2项集如表3所示(因为此病历中频繁2项集较大,只选取其中一部分作为例子):表3:频繁2项集2.6依照上述算法进行迭代,可依次生成频繁项集F3至F5,过程略。频繁5项集:F5如表4所示:表4:频繁5项集2.7当算法再次迭代,项集中只有一个元素,经过计算其支持频度为9.091,小于min_support,故没有新的项集发现,算法结束。(3)强关联规则的提取在从数据库中挖掘出所有的频繁项集后,就可以较容易获得相应的关联规则。也就是要产生满足最小支持度和最小信任度的强关联规则,可以利用公式(1)来计算所获关联规则的信任度。这里的条件概率是利用项集的支持度来计算的。Confidence(H⇒F)=P(H/F)=support_count(H∪F)support_count(H)---(1)]]>式(1)中,support_count(H∪F)为包含项集H∪F的事物数,support_count(H)为包含项集H的事物数,其中H是候选项集,F为频繁项集,若则认为这个关联规则为强关联规则,其中min_counf为设置的最小信任度阀值。由于关联规则是通过频繁项集直接产生的,因此关联规则所涉及的所有项集均满足最小支持度阈值。频繁项集及其支持频度可以存储在列表中,使得他们能够被快速存取。本实施例使用Apriori算法对所统计的1000例胃脘痛患者的病历信息进行关联规则挖掘,设置最小支持度min_support为30%,最小信任度min_conf为90%,得到强关联规则部分如表5所示:表5:胃脘痛患者病历症状属性间的强关联规则如果一个患者的症状满足上述列表中任一项症状时,则认为其是胃脘痛的患者。比如这个患者前期的症状为:同时有恶心、腹泻和胸闷三个症状,在含服硝酸脂类等药物后能缓解上述症状,则认为其是胃脘痛的患者。在确定这个患者患有胃脘痛时,继而获取该患者的患病时间和地理位置,同时对患病人数进行统计。根据上述方法,将数据库中所有患有胃脘痛的患者都找出来,同时统计患者人数。建立“疾病种类-患病时间-患病人数-地理位置”的结果表(如表6所示):表6:结果表由于患病时间和患病地理位置不好准确统计。本实施例表6中,将就医医院的坐标作为地理位置,将就医时间作为患病时间。本实施例以胃脘痛为例(如表7所示),对参数分档及颜色标识举例说明:表7:胃脘痛参数分档本实施例中用红色代表1档,即地图显示的红色区域说明这个地区的患病情况最严重,调用GIS地图数据,根据表6中的数据展示胃脘痛在空间、时间和人群中的地理分布情况,效果图如图1所示。根据上述方法,也可展示咳嗽在空间、时间和人群中的地理分布情况,效果图如图2所示。进一步的,前台中设有开始时间、结束时间、病种种类,前台的开始和结束时间是两个时间控件。在前台选择好时间段和疾病种类后,后台程序将结果表里满足这个时间段和疾病种类的患病人数、地理坐标传给图层,然后通过地图展示出来。进一步的,在结果表中对患者的年龄段进行区分,将年龄段作为结果表的列族成员,展示疾病在不同年龄段中的分布情况。由于致病因子、人群特征以及自然、社会环境等多种因素综合作用的影响,疾病在不同人群、不同地区及不同时间的流行强度不一,存在状态也不完全相同。疾病的分布的研究既反映了疾病本身的生物学特性,也集中表现了疾病有关的各种内外环境因素的效应及其互相作用的特点。本发明利用GIS地图和大数据架构技术,展示疾病在空间、时间和人群中的地理分布情况。整合不同平台的电子病历数据,解决以前数据分散、效率低下难以进行数据集成和综合分析的问题;为研究疾病的流行规律和探索疾病病因的提供基础数据,通过对疾病云图数据分布的描述,认识疾病流行的基本特征,是临床诊断很有价值的重要信息;对疾病分布规律和决定因素的分析有助于为合理地制订疾病的防制、保健对策及措施提供科学依据。当然,本发明还可有其它多种实施方式,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1