一种可疑洗钱账户的确定方法及装置与流程
本发明涉及计算机
技术领域:
,尤其涉及一种可疑洗钱账户的确定方法及装置。
背景技术:
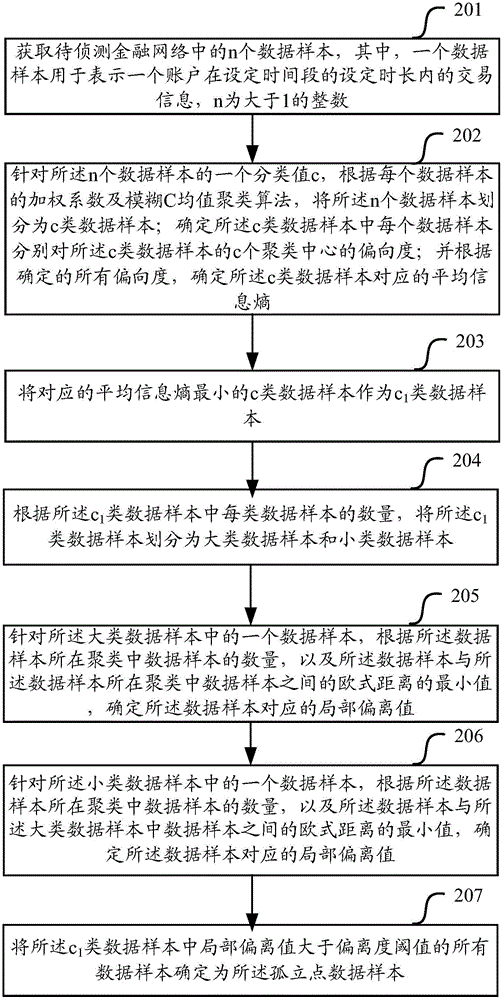
:在金融网络中存在着洗钱账户,进行着非法交易,洗钱账户是金融网络中洗钱路径中的节点,如何从错综复杂的金融网络中找到可疑洗钱账户,对打击洗钱行为有重要意义。现有技术在查找洗钱账户时,一般通过下列方法实现:将一段时间内具有较高交易金额的账户或者是交易较为频繁的账户筛选出来,然后由专家通过人工方式确认筛选出的账户是否为可疑洗钱账户。上述方法主要存在的问题是:该方式通过人工方式来确定可疑洗钱账户,过于依赖专家的主观经验,不仅效率低下,而且精确度不高,并且很难发现一些隐藏较深的可疑洗钱账户。综上所述,现有技术通过人工方式侦测可疑洗钱账户,效率比较低下,精确度不高,并且很难发现一些隐藏较深的可疑洗钱账户。技术实现要素:本发明提供一种可疑洗钱账户的确定方法及装置,用以解决现有技术中存在的通过人工方式侦测可疑洗钱账户,效率比较低下,精确度不高,并且很难发现一些隐藏较深的可疑洗钱账户的技术问题。一方面,本发明实施例提供一种可疑洗钱账户的确定方法,包括:获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,所述加权系数用于表示一个数据样本对分类的影响程度,所述平均信息熵是根据所有数据样本的偏向度得到的,所述偏向度用于表示一个数据样本偏向聚类中心的程度;确定所述c1类数据样本中的孤立点数据样本,并将所述孤立点数据样本对应的账户确定为可疑洗钱账户。可选地,所述根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,包括:针对所述n个数据样本的一个分类值c,根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度;并根据确定的所有偏向度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本,包括:使用随机数初始化所述n个数据样本对应的隶属度矩阵,以及将所述n个数据样本对应的目标函数值设定为预设值;根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心;根据所述c类数据样本及所述c类数据样本中每个类的聚类中心,更新所述目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则得到所述c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则根据隶属度矩阵更新公式,更新所述隶属度矩阵,并返回到根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心的步骤。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Jd(U,v1,v2,...,vc,X)=Σi=1cΣj=1nwjμijmdij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n;]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,X为所述n个数据样本的集合,wj为数据样本xj的加权系数,m为预设的加权指数,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,所述确定所述c1类数据样本中的孤立点数据样本,包括:根据所述c1类数据样本中每类数据样本的数量,将所述c1类数据样本划分为大类数据样本和小类数据样本;针对所述大类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述数据样本所在聚类中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;针对所述小类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述大类数据样本中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;将所述c1类数据样本中局部偏离值大于偏离度阈值的所有数据样本确定为所述孤立点数据样本。可选地,根据下列方式确定每个数据样本的加权系数:wi=CiΣi=1nCi,]]>Ci=NirD,rmin<r<rmax,]]>rmin=min{||xi-xj||},1≤i,j≤n,rmax=max{||xi-xj||},1≤i,j≤n;其中,wi表示数据样本xi的加权系数,Ci表示数据样本xi的粒子数密度,Ni表示以数据样本xi为球心,r为半径的球体内包含的数据样本的数量且r值预先设定,D表示数据样本xi的维度,||xi-xj||为数据样本xi与数据样本xj之间的欧氏距离。可选地,所述n个数据样本中的任一个数据样本可用下列部分或全部的内容来表示:总交易金额、总转出金额、总转入金额、交易金额离散系数、转出金额离散系数、转入金额离散系数、转出频率、转入频率;其中所述交易金额离散系数为所述数据样本在设定时间段的设定时长内交易金额方差与交易金额均值的比值,所述转出金额离散系数为所述数据样本在设定时间段的设定时长内转出金额方差与转出金额均值的比值,所述转入金额离散系数为所述数据样本在设定时间段的设定时长内转入金额方差与转入金额均值的比值。可选地,根据下列公式确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度:pij=e-dij2Σi=1ce-dij2,]]>其中,pij表示数据样本xj对第i个聚类中心的偏向度,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,根据下列公式确定所述c类数据样本中每个类的聚类中心:vi=Σj=1nwjμij2xjΣj=1nwjμij2,(1≤i≤c),]]>其中,vi表示聚类中心,wi表示数据样本xi的加权系数,μij为数据样本xj对第i个聚类的隶属度。另一方面,本发明实施例提供一种可疑洗钱账户的确定装置,包括:获取单元,用于获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;划分单元,用于根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,所述加权系数用于表示一个数据样本对分类的影响程度,所述平均信息熵是根据所有数据样本的偏向度得到的,所述偏向度用于表示一个数据样本偏向聚类中心的程度;可疑洗钱账户确定单元,用于确定所述c1类数据样本中的孤立点数据样本,并将所述孤立点数据样本对应的账户确定为可疑洗钱账户。可选地,所述划分单元,具体用于:针对所述n个数据样本的一个分类值c,根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度;并根据确定的所有偏向度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述划分单元,具体用于:使用随机数初始化所述n个数据样本对应的隶属度矩阵,以及将所述n个数据样本对应的目标函数值设定为预设值;根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心;根据所述c类数据样本及所述c类数据样本中每个类的聚类中心,更新所述目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则得到所述c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则根据隶属度矩阵更新公式,更新所述隶属度矩阵,并返回到根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心的步骤。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Jd(U,v1,v2,...,vc,X)=Σi=1cΣj=1nwjμijmdij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n;]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,X为所述n个数据样本的集合,wj为数据样本xj的加权系数,m为预设的加权指数,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,所述可疑洗钱账户确定单元,具体用于:根据所述c1类数据样本中每类数据样本的数量,将所述c1类数据样本划分为大类数据样本和小类数据样本;针对所述大类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述数据样本所在聚类中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;针对所述小类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述大类数据样本中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;将所述c1类数据样本中局部偏离值大于偏离度阈值的所有数据样本确定为所述孤立点数据样本。可选地,所述装置还包括加权系数确定单元,用于根据下列方式确定每个数据样本的加权系数:wi=CiΣi=1nCi,]]>Ci=NirD,rmin<r<rmax,]]>rmin=min{||xi-xj||},1≤i,j≤n,rmax=max{||xi-xj||},1≤i,j≤n;其中,wi表示数据样本xi的加权系数,Ci表示数据样本xi的粒子数密度,Ni表示以数据样本xi为球心,r为半径的球体内包含的数据样本的数量且r值预先设定,D表示数据样本xi的维度,||xi-xj||为数据样本xi与数据样本xj之间的欧氏距离。可选地,所述n个数据样本中的任一个数据样本可用下列部分或全部的内容来表示:总交易金额、总转出金额、总转入金额、交易金额离散系数、转出金额离散系数、转入金额离散系数、转出频率、转入频率;其中所述交易金额离散系数为所述数据样本在设定时间段的设定时长内交易金额方差与交易金额均值的比值,所述转出金额离散系数为所述数据样本在设定时间段的设定时长内转出金额方差与转出金额均值的比值,所述转入金额离散系数为所述数据样本在设定时间段的设定时长内转入金额方差与转入金额均值的比值。可选地,所述装置还包括偏向度确定单元,用于根据下列公式确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度:pij=e-dij2Σi=1ce-dij2,]]>其中,pij表示数据样本xj对第i个聚类中心的偏向度,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,所述装置还包括聚类中心确定单元,用于根据下列公式确定所述c类数据样本中每个类的聚类中心:vi=Σj=1nwjμij2xjΣj=1nwjμij2,(1≤i≤c),]]>其中,vi表示聚类中心,wi表示数据样本xi的加权系数,μij为数据样本xj对第i个聚类的隶属度。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后将n个数据样本进行分类,得到c1类数据样本,其中,该分类方式是一个最佳分类,以及从所述c1类数据样本中确定出孤立点数据样本,并将孤立点数据样本确定为可疑洗钱账户。本发明实施例方法一方面无需人工参与,可自动实现确定出可疑洗钱账户,提高了效率;另一方面,由于首先将数据样本进行合理分类,然后根据可疑洗钱账户的特点,从分类后的数据样本中找到孤立点作为可疑洗钱账户,因而提高了查找可疑洗钱账户的准确率。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的一种可疑洗钱账户的确定方法流程图;图2为本发明实施例提供的一种可疑洗钱账户的确定方法详细流程图;图3为本发明实施例提供的一种可疑洗钱账户的确定装置示意图。具体实施方式为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。下面结合说明书附图对本发明实施例作进一步详细描述。如图1所示,本发明实施例提供的一种可疑洗钱账户的确定方法,包括:步骤101、获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;步骤102、根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,所述加权系数用于表示一个数据样本对分类的影响程度,所述平均信息熵是根据所有数据样本的偏向度得到的,所述偏向度用于表示一个数据样本偏向聚类中心的程度;步骤103、确定所述c1类数据样本中的孤立点数据样本,并将所述孤立点数据样本对应的账户确定为可疑洗钱账户。在待侦测金融网络中,有很多账户,其中有些账户是洗钱账户,从事着非法洗钱交易,如何侦破获取这些洗钱账户对打击洗钱犯罪活动有着重大意义。本发明方法通过以上步骤101~步骤103可以实现找到可疑洗钱账户。上述步骤101中,首先获取待侦测金融网络中的n个数据样本,其中一个数据样本表示一个账户在设定时间段的设定时长内的交易信息,且n为大于1的整数。举例来说,假设设定时间段为最近一个月(假设有30天),设定时长为10天,则每个账户对应有3个数据样本;再比如,假设设定时间段为一年时间,设定时长为1个月,则每个账户对应有12个数据样本。可选地,本发明实施例中,对于得到的n个数据样本中的每个数据样本,定义为一个8维向量(当然也可以不是8维向量,根据实际需要来定义),具体地,任意一个数据样本xi形式如下:xi=(Tai0,Tai1,Tai2,Tadi0,Tadi1,Tadi2,Tfwi,Tfdi)。其中,Tai0表示在设定时间段的设定时长内的总交易金额,Tai1表示在设定时间段的设定时长内的总转出交易金额,Tai2表示在设定时间段的设定时长内的总转入交易金额,Tadi0表示交易金额离散系数,Tadi1表示转出金额离散系数,Tadi2表示转入金额离散系数,Tfwi表示转出频率,Tfdi表示转入频率,其中所述交易金额离散系数Tadi0为数据样本在设定时间段的设定时长内交易金额方差与交易金额均值的比值,所述转出金额离散系数Tadi1为数据样本在设定时间段的设定时长内转出金额方差与转出金额均值的比值,所述转入金额离散系数Tadi2为数据样本在设定时间段的设定时长内转入金额方差与转入金额均值的比值。举例来说,假设设定时间段为一个月,设定时长为10天,则对于任意一个账户k,可以得到3个数据样本,假设分别为xk1,xk2,xk3,其中xk1表示在这一个月中的前10天的相关交易信息,xk2表示在这一个月中的中间10天的相关交易信息,xk3表示在这一个月中的后10天的相关交易信息,并且每个数据样本都是1个由8个量组成的向量。对于每个数据样本的8个分量,具体地,可以通过下列方式得到:1、总交易金额Tai0假设数据样本i在设定时长内总共有ni0笔交易,每笔交易金额taij按照时序排列为则数据样本的总交易金额为:2、总转出交易金额Tai1假设数据样本i在设定时长内总共有ni1笔转出交易,每笔交易金额tbij按照时序排列为则数据样本的总转出交易金额为:3、总转入交易金额Tai2假设数据样本i在设定时长内总共有ni2笔转出交易,每笔交易金额tcij按照时序排列为则数据样本的总转出交易金额为:4、交易金额离散系数Tadi0假设数据样本i在设定时长内总交易金额均值为:总交易金额的方差为则交易金额离散系数Tadi0为:5、转出金额离散系数Tadi1假设数据样本i在设定时长内总转出交易金额均值为:总转出交易金额的方差为则转出金额离散系数Tadi1为:6、转入金额离散系数Tadi2假设数据样本i在设定时长内总转入交易金额均值为:总转入交易金额的方差为则转入金额离散系数Tadi2为:7、转出频率Tfwi将数据样本i在设定时长内转出交易次数与总交易次数的比值,定义为转出频率Tfwi。8、转入频率Tfdi将数据样本i在设定时长内转入交易次数与总交易次数的比值,定义为转入频率Tfdi。通过上述步骤101,可以得到n个数据样本,假设这n个数据样本构成的集合为X={x1,x2,…,xn}。在上述步骤102中,对n个数据样本进行分类,分成c1类数据样本,并且c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,其中,信息熵是信息论中的概念,当信源发出的信息越确定,其信息熵越小,因此在本发明中当分类的划分越合理,数据样本偏向于分类中心越确定,即表明该分类的信息熵越小。因此满足条件的c1类是最合理的分类。在本发明中所述平均信息熵是根据所有数据样本的偏向度得到的,所述偏向度用于表示一个数据样本偏向聚类中心的程度。具体地,在本发明中是根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,所述加权系数用于表示一个数据样本对分类的影响程度。如何根据数据样本的加权系数将n个数据样本划分为c1类数据样本,是有很多种方式的,下面给出一种结合模糊C均值聚类算法的方法来得到c1类数据样本,可选地,所述根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,包括:针对所述n个数据样本的一个分类值c,根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度;并根据确定的所有偏向度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。其中,可选地,所述根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本,包括以下步骤:步骤1、使用随机数初始化所述n个数据样本对应的隶属度矩阵,以及将所述n个数据样本对应的目标函数值设定为预设值;步骤2、根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心;步骤3、根据所述c类数据样本及所述c类数据样本中每个类的聚类中心,更新所述目标函数值;步骤4、判断所述目标函数值的更新变化量是否小于或等于变化量阈值,若是,则得到所述c类数据样本,否则,转到步骤5;步骤5、根据隶属度矩阵更新公式,更新所述隶属度矩阵,并返回到步骤2。下面利用公式对步骤102中将n个数据样本划分成c1类数据样本的过程做详细描述。首先,对本发明中使用到的一些名词作如下定义。定义1、数据样本的粒子数密度。rmin=min{||xi-xj||},1≤i,j≤n,rmax=max{||xi-xj||},1≤i,j≤n;其中,Ci表示数据样本xi的粒子数密度,Ni表示以数据样本xi为球心,r为半径的球体内包含的数据样本的数量且r值预先设定,D表示数据样本xi的维度(本发明中,D取值为8,表示一个样本有8个分量),||xi-xj||为数据样本xi与数据样本xj之间的欧氏距离。在上述定义1中,本发明中一个数据样本的粒子数密度的概念来源于普通物理学,在普通物理学中,粒子数密度的定义为:假设空间中任意一个封闭区域内含有N′个粒子,则该区域的粒子数密度为其中V为该封闭区域的体积。对于D维欧氏空间中半径为r的球体的体积为则该球体内的粒子数密度为定义2、数据样本的加权系数。其中,wi表示数据样本xi的加权系数,Ci表示定义1中数据样本xi的粒子数密度。上述定义2中,一个数据样本的加权系数用于表示一个数据样本对分类的影响程度。定义3、对传统模糊C均值聚类算法的中的目标函数的重新定义。假设数据样本集合X={x1,x2,…,xn}将被分成c类,{A1,A2,…,Ac}表示相应的c个类,U是一个c*n的隶属矩阵且μij为U中的元素,U中的任意一个元素μij表示数据样本xj对第i个聚类的隶属度,各类别的聚类中心为{v1,v2,…,vc},本发明中,将模糊C均值聚类算法对应的目标函数定义为:Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n;]]>其中,wj为数据样本xj的加权系数,m为预设的加权指数,dij为第i个聚类中心与数据样本xj之间的欧氏距离。在传统的模糊C均值聚类算法中,将目标函数定义为其中不包含加权系数wj,而本发明中将模糊C均值聚类算法对应的目标函数进行重新定义,主要在传统的模糊C均值聚类算法对应的目标函数中增加了加权系数wj,之所以如此定义,原因在于:由于基于传统的目标函数的划分方法,每个样本对最终划分结果的影响程度相同的,然而实际应用中不同的账户在洗钱的频繁程度、交易金额的大小等方面都是不一样的,因此金融交易数据的分布不可能是均匀或对称的,传统的模糊C均值聚类算法对数据集的样本等划分特性将造成很大的误差;而本发明中在目标函数中增加了加权系数wj之后,表明每个数据样本对最终的分类结果造成的影响程度是不一样的,因而可以得到的样本划分结果也更加真实和准确。定义4、c类数据样本中每个类的聚类中心。其中,vi表示聚类中心,wi表示数据样本xi的加权系数,μij为数据样本xj对第i个聚类的隶属度。上述定义4用于计算每个类的聚类中心。定义5、隶属度矩阵的更新公式。其中,μij为数据样本xj对第i个聚类的隶属度,m为预设的加权指数,dij为第i个聚类中心与数据样本xj之间的欧氏距离,dkj为第k个聚类中心与数据样本xj之间的欧氏距离。定义6、c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度:其中,pij表示数据样本xj对第i个聚类中心的偏向度,dij为第i个聚类中心与数据样本xj之间的欧氏距离。定义7、定义平均信息熵。其中,H(c)表示c个数据样本的分类的平均信息熵,pij表示数据样本xj对第i个聚类中心的偏向度,n为数据样本数量。信息熵是信息论中的概念,当信源发出的信息越确定,其信息熵越小。在模糊聚类中,当聚类的划分越合理,数据偏向于聚类中心越确定,该聚类的信息熵越小。因此平均信息熵越小,对应的分类越合理,也即最小的平均信息熵所对应的分类方式是最佳分类方式。在有了以上的定义之后,下面对步骤102中,将n个数据样本划分为c1类数据样本的具体过程做详细描述,其中,c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小。步骤1、初始化工作。设定变化量阈值为ε,确定初始聚类中心个数的取值范围[cmin,cmax]。一般取cmin=2,步骤2、在聚类中心数目c从c=cmin增加到c=cmax的过程中,对于任意确定的c,由以下步骤A~步骤E确定对应的隶属矩阵U=(μij)cxn,和此时的平均信息熵H(c):步骤A、用值在区间[0,1]内的随机数初始化隶属矩阵U=Ucxn=(μij)cxn,使其满足约束条件步骤B、根据公式1和公式2,计算每个数据样本的加权系数wj,j=1,2,…,n;步骤C、根据隶属度矩阵U得到c个分类,以及根据公式4,计算每个分类的聚类中心;具体地,对于一个隶属度矩阵U,可以根据下列方式得到c个分类:根据最大隶属度原则对数据集合X={x1,x2,…,xn}进行分类:在U=Ucxn的第k列中,如果则将xk归入第i1类。步骤D、根据公式3计算目标函数J,以及计算目标函数值的更新变化量(更新变化量指的是此次计算得到的目标函数值与上次计算得到的目标函数值的差值),若更新变化量小于或等于变化量阈值ε,则输出当前数据样本的分类方式,并且根据公式6和公式7计算该分类方式对应的平均信息熵;若更新变化量大于变化量阈值ε,则转到步骤E;步骤E、根据公式5更新当前隶属度矩阵U,并返回到步骤C。对于上述步骤E,下面举一个具体的例子进行说明。假设数据样本数量n=6,分别用N1,N2,N3,N4,N5,N6来表示。假设当前要对c=2确定一个分类方式。则在步骤A中,首先对隶属矩阵U进行初始化,假设初始化后的U为:U=0.40.80.60.70.90.30.60.20.40.30.10.7]]>由于0.6>0.4,因此数据样本N1划分到第二类中;由于0.8>0.2,因此数据样本N2划分到第一类中,以此类推,得到的两个分类分别为:第一类:N2,N3,N4,N5;第二类:N1,N6。然后计算上述两个分类的聚类中心,以及根据这两个聚类中心及计算得到的加权系数,得到目标函数J,假设上述两个分类对应的目标函数J=5,并且上次计算得到的J=4,并且初始化的变化量阈值ε=0.5,由于当前计算得到的目标函数与上次计算得到的目标函数的差值为1,因此大于变化量阈值,则不满足迭代停止条件,需要通过步骤E更新隶属度矩阵U,假设更新后的隶属度矩阵为:U=0.70.70.60.80.30.30.30.30.40.20.70.7]]>则得到的新的两类分别为:第一类:N1,N2,N3,N4;第二类:N5,N6。然后得到新的目标函数值,假设为5.3,则本次得到的目标函数值5.3与上次得到的目标函数值5之间的差值为0.3,因此小于变化量阈值0.5,因此迭代停止,将c=2时对应的分类方式确定为:第一类:N1,N2,N3,N4;第二类:N5,N6。然后计算对应的平均信息熵,假设为2.5。从而根据上述步骤A~步骤E,对于任意一个c值,都可以计算得到一种分类方式以及对应的平均信息熵。步骤3、对比聚类中心数目c在不同取值时的平均信息熵H(c),找到使平均信息熵H(c)取最小值的聚类中心数目c1,H(c1)=minH(c),从而最终的聚类数目为c1以及对应的分类方式。根据上述步骤1~步骤3,可以得到一个最佳分类c1及对应的分类方式。从而有利于提高最终确定可疑洗钱账户的精度和准确度。基于上述步骤102中得到的一个最佳分类c1及对应的分类方式,下面通过步骤103,从该分类方式中找到可疑洗钱账户,具体地,在上述步骤103中,确定所述c1类数据样本中的孤立点数据样本,并将所述孤立点数据样本对应的账户确定为可疑洗钱账户。举例来说,假设一共有20个样本,分别为N1,N2,N3,N4,N5,N6,N7,N8,N9,N10,N11,N12,N13,N14,N15,N16,N17,N18,N19,N20,且得到的最佳分类为c1=5且对应的分类方式为:第1类:N1,N8,N12;第2类:N3,N9,N13,N19;第3类:N2,N6,N7,N15,N17;第4类:N4,N10,N14,N18,N20;第5类:N5,N11,N16。则在步骤103中,从上述20个数据样本中找到孤立点数据样本,并将孤立点数据样本对应的账户确定为可疑洗钱账户。之所以将孤立点数据样本对应的账户确定为可疑洗钱账户,是因为洗钱行为通常隐藏在正常的账户交易过程中,同时洗钱行为有别于正常的账户交易行为,因此它们以孤立点的形式表现在数据集中。所谓孤立点数据样本指的是该数据样本周围不存在其他数据样本,或者说,孤立点数据样本与其他数据样本之间的欧式距离都比较大,因此该数据样本以孤立的形式存在。对于如何确定c1类数据样本中的孤立点数据样本,有很多种方式,本发明不做限定。为方便说明,下面给出一种具体的确定孤立点数据样本的方式,可选地,所述确定所述c1类数据样本中的孤立点数据样本,包括:步骤1、根据所述c1类数据样本中每类数据样本的数量,将所述c1类数据样本划分为大类数据样本和小类数据样本;通过前面的步骤102中,已经将数据集合X={x1,x2,…,xn}划分成了c1个类,即{A1,A2,…,Ac},现在把这些类进行划分,求出大小类。假设|Ai|代表类Ai中包含的数据点的个数,则对这些类按照包含点个数的多少进行排序,假设排序结果为|A1|>|A2|>…>|Ac|。给定两个参数α和β,根据以下条件划分大类和小类:|A1|+|A2|+…+|Ab|≥|X|·α|Ab||Ab+1|≥β]]>从而,大类的集合为LC={Ai|i≤b},小类的集合为SC={Ak|k>b}。步骤2、针对所述大类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述数据样本所在聚类中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;步骤3、针对所述小类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述大类数据样本中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;对于上述步骤2和步骤3分别是确定大类数据样本中数据样本对应的局部偏离值,以及确定小类数据样本中数据样本对应的局部偏离值,下面用一个公式来表示:对于任意一点x∈X,该点的局部偏离值(LOF)定义如下:LOF(x)=|Ai|·min(distance(x,Aj))wherex∈Ai,Ai∈SCandAj∈LCforj=1tob|Ai|·distance(x,Aj))wherex∈AiandAi∈LC]]>其中,distance(x,Ai)=min{d(x,xk)|xx∈Ai,1≤k≤|Ai|},而d(x,xk)指x和xk之间的欧氏距离。由以上公式,我们可以求出每个数据样本的局部偏离值。步骤4、将所述c1类数据样本中局部偏离值大于偏离度阈值的所有数据样本确定为所述孤立点数据样本。在确定了所有的孤立点数据样本之后,将孤立点数据样本对应的账户确定为可疑洗钱账户。举例来说,针对上述20个数据样本,假设最终得到的孤立点数据样本为N3,N9和N15,并且N3对应的账户为账户A,N9对应的账户为账户B,N15对应的账户也为账户B,则最终确定的可疑洗钱账户为账户A和账户B。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后将n个数据样本进行分类,得到c1类数据样本,其中,该分类方式是一个最佳分类,以及从所述c1类数据样本中确定出孤立点数据样本,并将孤立点数据样本确定为可疑洗钱账户。本发明实施例,一方面无需人工参与,可自动实现确定出可疑洗钱账户,提高了效率;另一方面,由于首先将数据样本进行合理分类,然后根据可疑洗钱账户的特点,从分类后的数据样本中找到孤立点作为可疑洗钱账户,因而提高了查找可疑洗钱账户的准确率。下面对本发明实施例提供的一种可疑洗钱账户的确定做详细描述,如图2所示,包括:步骤201、获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;步骤202、针对所述n个数据样本的一个分类值c,根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度;并根据确定的所有偏向度,确定所述c类数据样本对应的平均信息熵;步骤203、将对应的平均信息熵最小的c类数据样本作为c1类数据样本;步骤204、根据所述c1类数据样本中每类数据样本的数量,将所述c1类数据样本划分为大类数据样本和小类数据样本;步骤205、针对所述大类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述数据样本所在聚类中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;步骤206、针对所述小类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述大类数据样本中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;步骤207、将所述c1类数据样本中局部偏离值大于偏离度阈值的所有数据样本确定为所述孤立点数据样本。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后将n个数据样本进行分类,得到c1类数据样本,其中,该分类方式是一个最佳分类,以及从所述c1类数据样本中确定出孤立点数据样本,并将孤立点数据样本确定为可疑洗钱账户。本发明实施例,一方面无需人工参与,可自动实现确定出可疑洗钱账户,提高了效率;另一方面,由于首先将数据样本进行合理分类,然后根据可疑洗钱账户的特点,从分类后的数据样本中找到孤立点作为可疑洗钱账户,因而提高了查找可疑洗钱账户的准确率。基于相同的技术构思,本发明实施例还提供一种可疑洗钱账户的确定装置,如图3所示,包括:获取单元301,用于获取待侦测金融网络中的n个数据样本,其中,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,n为大于1的整数;划分单元302,用于根据每个数据样本的加权系数,将所述n个数据样本划分为c1类数据样本,其中c1满足使得划分得到的所述c1类数据样本对应的平均信息熵最小,所述加权系数用于表示一个数据样本对分类的影响程度,所述平均信息熵是根据所有数据样本的偏向度得到的,所述偏向度用于表示一个数据样本偏向聚类中心的程度;可疑洗钱账户确定单元303,用于确定所述c1类数据样本中的孤立点数据样本,并将所述孤立点数据样本对应的账户确定为可疑洗钱账户。可选地,所述划分单元302,具体用于:针对所述n个数据样本的一个分类值c,根据每个数据样本的加权系数及模糊C均值聚类算法,将所述n个数据样本划分为c类数据样本;确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度;并根据确定的所有偏向度,确定所述c类数据样本对应的平均信息熵;将对应的平均信息熵最小的c类数据样本作为所述c1类数据样本。可选地,所述划分单元302,具体用于:使用随机数初始化所述n个数据样本对应的隶属度矩阵,以及将所述n个数据样本对应的目标函数值设定为预设值;根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心;根据所述c类数据样本及所述c类数据样本中每个类的聚类中心,更新所述目标函数值;若确定所述目标函数值的更新变化量小于或等于变化量阈值,则得到所述c类数据样本;若确定所述目标函数值的变化量大于所述变化量阈值,则根据隶属度矩阵更新公式,更新所述隶属度矩阵,并返回到根据所述隶属度矩阵,将所述n个数据样本划分为c类数据样本,以及确定所述c类数据样本中每个类的聚类中心的步骤。可选地,所述模糊C均值聚类算法对应的目标函数为:J=Jd(U,v1,v2,...,vc,X)=Σi=1cΣj=1nwjμijmdij2,]]>Σi=1cμij=1,∀j=1,2,...,n;1≤j≤n;]]>其中,μij为数据样本xj对第i个聚类的隶属度,{v1,v2,…,vc}为各个聚类的聚类中心,U是一个c*n的隶属矩阵且μij为U中的元素,X为所述n个数据样本的集合,wj为数据样本xj的加权系数,m为预设的加权指数,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,所述可疑洗钱账户确定单元303,具体用于:根据所述c1类数据样本中每类数据样本的数量,将所述c1类数据样本划分为大类数据样本和小类数据样本;针对所述大类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述数据样本所在聚类中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;针对所述小类数据样本中的一个数据样本,根据所述数据样本所在聚类中数据样本的数量,以及所述数据样本与所述大类数据样本中数据样本之间的欧式距离的最小值,确定所述数据样本对应的局部偏离值;将所述c1类数据样本中局部偏离值大于偏离度阈值的所有数据样本确定为所述孤立点数据样本。可选地,所述装置还包括加权系数确定单元304,用于根据下列方式确定每个数据样本的加权系数:wi=CiΣi=1nCi,]]>rmin<r<rmax,rmin=min{||xi-xj||},1≤i,j≤n,rmax=max{||xi-xj||},1≤i,j≤n;其中,wi表示数据样本xi的加权系数,Ci表示数据样本xi的粒子数密度,Ni表示以数据样本xi为球心,r为半径的球体内包含的数据样本的数量且r值预先设定,D表示数据样本xi的维度,||xi-xj||为数据样本xi与数据样本xj之间的欧氏距离。可选地,所述n个数据样本中的任一个数据样本可用下列部分或全部的内容来表示:总交易金额、总转出金额、总转入金额、交易金额离散系数、转出金额离散系数、转入金额离散系数、转出频率、转入频率;其中所述交易金额离散系数为所述数据样本在设定时间段的设定时长内交易金额方差与交易金额均值的比值,所述转出金额离散系数为所述数据样本在设定时间段的设定时长内转出金额方差与转出金额均值的比值,所述转入金额离散系数为所述数据样本在设定时间段的设定时长内转入金额方差与转入金额均值的比值。可选地,所述装置还包括偏向度确定单元305,用于根据下列公式确定所述c类数据样本中每个数据样本分别对所述c类数据样本的c个聚类中心的偏向度:pij=e-dij2Σi=1ce-dij2,]]>其中,pij表示数据样本xj对第i个聚类中心的偏向度,dij为第i个聚类中心与数据样本xj之间的欧氏距离。可选地,所述装置还包括聚类中心确定单元306,用于根据下列公式确定所述c类数据样本中每个类的聚类中心:vi=Σj=1nwjμij2xjΣj=1nwjμij2,(1≤i≤c),]]>其中,vi表示聚类中心,wi表示数据样本xi的加权系数,μij为数据样本xj对第i个聚类的隶属度。本发明实施例,首先确定n个数据样本,一个数据样本用于表示一个账户在设定时间段的设定时长内的交易信息,然后将n个数据样本进行分类,得到c1类数据样本,其中,该分类方式是一个最佳分类,以及从所述c1类数据样本中确定出孤立点数据样本,并将孤立点数据样本确定为可疑洗钱账户。本发明实施例,一方面无需人工参与,可自动实现确定出可疑洗钱账户,提高了效率;另一方面,由于首先将数据样本进行合理分类,然后根据可疑洗钱账户的特点,从分类后的数据样本中找到孤立点作为可疑洗钱账户,因而提高了查找可疑洗钱账户的准确率。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1