一种基于交往频度和交往指数的超大规模用户的社交网络分析及家庭关系识别算法的制作方法
本发明涉及运营商社交圈口碑营销与家庭套餐推荐营销的应用领域,尤其涉及口碑营销中社交网络构建及家庭关系识别的方法;
背景技术:
互联网时代传统的单客户大规模群发营销方式已很难吸引用户,营销成本回报率较低,而且很容易引起用户投诉;
现有技术中,由于主要面向单客户营销推荐,在营销推荐过程中存在如下缺陷:
1)单客户群发式营销容易引起用户反感,引发用户投诉;
2)对客户群体特征不了解,不能抓住群体兴趣点;
3)不了解家庭构成,家庭套餐无法针对性推荐;
4)对异网营销没有合适的切入点;
总之,现有的针对单客户的群发式营销针对性较差,成本回报率较低,且容易造成用户投诉;
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种基于交往频度和交往指数的超大规模用户的社交网络分析及家庭关系识别算法,构建用户社交网络模型,以及构建用户家庭关系;
为达到上述目的,本发明的技术方案是这样实现的:
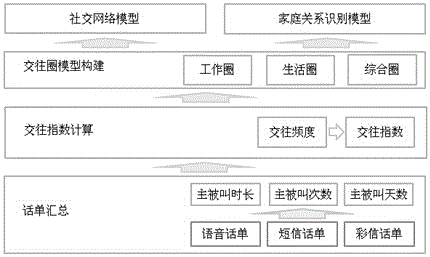
本发明提供一种社交网络分析及家庭关系识别算法,包括:交往频度/交往指数计算、交往圈模型构建、社交网络模型构建、家庭关系识别模型构建;其中,
交往频度/交往指数,用于基于语音通话信息、短彩信通话信息以及通话频度计算用户交往频度指标,并结合次数、时长等信息计算交往指数,反映用户间联系紧密度;
交往圈模型,用于根据交往指数排名构建用户交往圈模型,同时结合交往时段偏好(工作时段、生活时段、时段不明显),建立工作圈、生活圈、综合圈模型;
社交网络模型,用于构建交往圈的社交网络,找出联系密集群,这里从共同联系人的角度思考,当考虑将两个用户划入一个群组时,希望两个用户有较多的共同联系人;而主体通过快速迭代的方式,将用户逐步加入到对应的群体中;
家庭关系识别模型,用于构建家庭关系识别模型,计算联系双方的相似度,与客户下多号码相似度较高,且交往时段集中于生活时段的,认为与客户同一家庭的可能性较高;
上述系统中,所述交往频度指标、交往指数指标为:
整理用户语音话单、短彩信话单,分别计算工作时段、生活时段通话时长、通话次数;
用户本月有通话日数+周数+旬数除以当月天数计算得出交往频度;
交往频度、通话次数、通话时长、短彩信次数分别乘以权重累加得出交往指数;
上述系统中,所述交往圈模型为:
分别将工作时段、生活时段、不区分时段的交往频度、通话次数、通话时长等指标乘以权重累加,计算出工作圈交往指数、生活圈交往指数、综合圈交往指数,指数最大的即为该用户所属的交往圈;
上述系统中,所述通过交往圈信息建立社交网络模型为:
按照迭代方式分群,将所有用户都分入到一个群体中,计算用户间交往相似度,删除用户间的弱联系;弱连接的删除也避免了所有用户划入同一个群中。进行此步骤后,社交网络会退化成几个内部联系多、外部联系少的次网络,以及很多孤立的节点;每个次网络对应一个群体(group),称为这个群体的核 (kernel);
将剩余用户分成联系密集的小群体,如何保证网络内部联系较为密集,我们优先将共同联系人较多的用户分到一个群体中,在此前提条件下,通过迭代的方法依照通话记录依次将用户划入相应的群中;
上述系统中,所述识别客户家庭关系为:
根据用户的同客户ID、同客户家庭套餐、同客户账号等信息构建家庭关系骨干模型;
根据家庭骨干用户的交往圈信息计算交往相似度、交往时段偏好,将生活圈中相似度较高用户识别成同家庭用户;
附图说明
图1是本发明实现社交网络分析及家庭关系识别算法的结构示意图;
图2是本发明实现社交网络分析及家庭关系识别算法的流程示意图;
具体实施方式
本发明的基本思想是:整理语音话单、短彩信话单信息,计算用户两两间联系交往频度、交往指数;根据交往频度、交往指数及联系时段偏好建立工作圈、生活圈、综合圈模型;基于交往圈计算用户间共同联系人,并计算用户间相似度指标,建立社交网络;基于同客户、同家庭套餐、通账户信息建立家庭骨干成员,根据成员与用户相似度计算,寻找高相似度的本网/异网用户纳入同家庭关系客户;
下面通过具体实施例对本发明再做进一步的详细说明;
本发明提供一种基于交往频度和交往指数的超大规模用户的社交网络分析及家庭关系识别算法,用于种子营销、口碑营销及家庭关系识别,该系统包括:交往频度/交往指数计算、交往圈模型构建、社交网络模型构建、家庭关系识别模型构建;其中:
交往频度/交往指数,用于基于语音通话信息、短彩信通话信息以及通话频度计算用户交往频度指标,并结合次数、时长等信息计算交往指数,反映用户间联系紧密度;
交往圈模型,用于根据交往指数排名构建用户交往圈模型,同时结合交往时段偏好(工作时段、生活时段、时段不明显),建立工作圈、生活圈、综合圈模型;
社交网络模型,用于构建交往圈的社交网络,找出联系密集群,这里从共同联系人的角度思考,当考虑将两个用户划入一个群组时,希望两个用户有较多的共同联系人。而主体通过快速迭代的方式,将用户逐步加入到对应的群体中;
家庭关系识别模型,用于构建家庭关系识别模型,计算联系双方的相似度,与客户下多号码相似度较高,且交往时段集中于生活时段的,认为与客户同一家庭的可能性较高;
所述交往频度/交往指数算法流程为:
整理用户语音话单、短彩信话单,分别计算工作时段、生活时段通话时长、通话次数;
用户本月有通话日数+周数+旬数除以当月天数计算得出交往频度;
交往频度、通话次数、通话时长、短彩信次数分别乘以权重累加得出交往指数;
所述交往圈模型构建为:
分别将工作时段、生活时段、不区分时段的交往频度、通话次数、通话时长等指标乘以权重累加,计算出工作圈交往指数、生活圈交往指数、综合圈交往指数,指数最大的即为该用户所属的交往圈;
所述社交网络模型构建为:
按照迭代方式分群,将所有用户都分入到一个群体中,计算用户间交往相似度,删除用户间的弱联系;弱连接的删除也避免了所有用户划入同一个群中;进行此步骤后,社交网络会退化成几个内部联系多、外部联系少的次网络,以及很多孤立的节点;每个次网络对应一个群体(group),称为这个群体的核 (kernel);
将剩余用户分成联系密集的小群体,如何保证网络内部联系较为密集,我们优先将共同联系人较多的用户分到一个群体中,在此前提条件下,通过迭代的方法依照通话记录依次将用户划入相应的群中;
所述家庭关系识别模型构建为:
根据用户的同客户ID、同客户家庭套餐、同客户账号等信息构建家庭关系骨干模型;
根据家庭骨干用户的交往圈信息计算交往相似度、交往时段偏好,将生活圈中相似度较高用户识别成同家庭用户;
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!