一种向目标对象播放音频信息的方法及装置与流程
本发明涉及信息处理技术领域,尤其涉及一种向目标对象播放音频信息的方法及装置。
背景技术:
据第二次全国残疾人抽样调查数据推算,中国目前视力残疾人数约为1233万人,且每年约有45万人失明。视障人士(包括盲人)由于视觉感官受限导致其行动十分不便,给生活带来很大困扰。
目前主要采用如下几种方式来解决视障人士由于视觉感官受限带来的不便:
一种为采用盲杖的方式,盲杖作为一种辅助用具,探测方法为手动往复逐点扫描,但是采用盲杖这种方式所获得的空间信息有限,例如,高处的障碍(如树枝)、细小的障碍(如铁丝)等无法及时扫到的区域以及移动物体,无法准确确定出障碍物;
还有一种为采用导盲犬的方式,但是导盲犬只能记住固定几条线路,视障人士的活动范围受限,同时由于训练和养护成本高,该方法难以普及。
因此,目前避障的方式存在准确度较低及活动范围受限的缺陷。
技术实现要素:
鉴于上述问题,提出了本发明,以便提供一种克服上述问题或者至少部分地解决上述问题的一种向目标对象播放音频信息的方法及装置,用于解决现有技术中存在的准确度较低及视障人士的活动范围受限的缺陷。
依据本发明的第一方面,提供了一种向目标对象播放音频信息的方法,包括:
确定目标对象相对的方向为预设方向;
确定处于所述预设方向且与所述目标对象相距预设距离的环境区域;
确定所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面;
将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
在一个实施方式中,根据本发明的上述实施方式所述的方法,确定所述环境区域针对所述目标对象的包络面之前,所述方法还包括:
采集所述环境区域的表象信息,所述表象信息包括能够用肉眼观察到的和/或能够用设备采集到的用于表征物体的电磁场光谱信息;
根据所述表象信息检测出所述环境区域中的路面,并基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物;
确定所述环境区域针对所述目标对象的包络面,包括:
根据所述障碍物确定所述环境区域的包络面。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,根据所述表象信息检测出所述环境区域中的路面,包括:
根据所述表象信息计算所述环境区域的三维信息;
根据所述三维信息检测出所述环境区域中的路面;
基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物,包括:
基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物,包括:
将包括的任意一点A满足如下规则的物体作为凹陷障碍物:
d<d1
其中,所述d为所述任意一点A与所述路面的距离;所述d1为低于所述路面,且被认为是凹陷障碍物的最大阈值,所述d1<0;
将包括的任意一点A满足如下规则的物体作为凸起障碍物:
d2<d<d3
其中,所述d2为高于所述路面,且被认为是凸起障碍物的最小阈值,所述d2>0;所述d3为所述目标对象所需的安全空间的高度。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,确定所述环境区域针对所述目标对象的包络面,包括:
识别所述环境区域中包括障碍物的第一类子区域和不包括障碍物的第二类子区域;
针对所述第一类子区域中的每一个子区域,确定该区域包括的障碍物上与所述目标对象之间的距离为最小值的第一类点;
针对所述第二类子区域中的每一个子区域,确定该区域边界上与所述目标对象之间的距离为最大值的第二类点;
连接所述第一类点和所述第二类点构成包络面。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,针对包括障碍物的环境区域的所述包络面满足如下规则:
E(x)=f(x,y*)
其中,所述y*满足如下规则:
其中,所述E(x)为针对包括障碍物的环境区域的包络面,所述x为所述环境区域中的物体的横坐标,所述y为所述环境区域中的物体的纵坐标。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,将所述包络面包括的点对应的音频信息向所述目标对象进行播放,包括:
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量;或者
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调;或者
将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
在一些实施方式中,根据本发明的上述任一实施方式所述的方法,将所述包络面包括的点对应的音频信息向所述目标对象进行播放,包括:
确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放;或者
确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
在本发明实施方式的第二方面中,提供了一种向目标对象播放音频信息的装置,包括:
确定模块,用于确定目标对象相对的方向为预设方向;
所述确定模块还用于,确定处于所述预设方向且与所述目标对象相距预设距离的环境区域;
所述确定模块还用于,确定所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面;
播放模块,用于将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
在一个实施方式中,根据本发明的上述实施方式所述的装置,所述装置还包括采集模块、检测模块和识别模块,其中:
所述采集模块,用于采集所述环境区域的表象信息,所述表象信息包括能够用肉眼观察到的和/或能够用设备采集到的用于表征物体的电磁场光谱信息;
所述检测模块,用于根据所述表象信息检测出所述环境区域中的路面;
所述识别模块,用于基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物;
所述确定模块确定所述环境区域针对所述目标对象的包络面时,具体为:
根据所述障碍物确定所述环境区域的包络面。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,所述检测模块根据所述表象信息检测出所述环境区域中的路面时,具体为:
根据所述表象信息计算所述环境区域的三维信息;
根据所述三维信息检测出所述环境区域中的路面;
所述识别模块基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物时,具体为:
基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,所述识别模块基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物时,具体为:
将包括的任意一点A满足如下规则的物体作为凹陷障碍物:
d<d1
其中,所述d为所述任意一点A与所述路面的距离;所述d1为低于所述路面,且被认为是凹陷障碍物的最大阈值,所述d1<0;
将包括的任意一点A满足如下规则的物体作为凸起障碍物:
d2<d<d3
其中,所述d2为高于所述路面,且被认为是凸起障碍物的最小阈值,所述d2>0;所述d3为所述目标对象所需的安全空间的高度。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,所述确定模块确定所述环境区域针对所述目标对象的包络面时,具体为:
识别所述环境区域中包括障碍物的第一类子区域和不包括障碍物的第二类子区域;
针对所述第一类子区域中的每一个子区域,确定该区域包括的障碍物上与所述目标对象之间的距离为最小值的第一类点;
针对所述第二类子区域中的每一个子区域,确定该区域边界上与所述目标对象之间的距离为最大值的第二类点;
连接所述第一类点和所述第二类点构成包络面。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,针对包括障碍物的环境区域的所述包络面满足如下规则:
E(x)=f(x,y*)
其中,所述y*满足如下规则:
其中,所述E(x)为针对包括障碍物的环境区域的包络面,所述E(x)为所述包络面,所述x为所述环境区域中的物体的横坐标,所述y为所述环境区域中的物体的纵坐标。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,所述播放模块将所述包络面中点对应的音频信息向所述目标对象进行播放时,具体为:
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述包络面包括的第一类点对应的距离值大于所述包络面包括的第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量;或者
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调;或者
将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
在一些实施方式中,根据本发明的上述任一实施方式所述的装置,所述播放模块将所述包络面包括的点对应的音频信息向所述目标对象进行播放时,具体为:
确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放;或者
确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
本发明实施例中,提出一种向目标对象播放音频信息的方法,包括:确定目标对象相对的方向为预设方向;确定处于所述预设方向且与所述目标对象相距预设距离的环境区域;确定所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面;将所述包络面包括的点对应的音频信息向所述目标对象进行播放;在该方案中,确定出处于所述预设方向且与所述目标对象相距预设距离的环境区域,再确定出所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面,并将将所述包络面包括的点对应的音频信息向所述目标对象进行播放,这样,目标对象可以根据听到的音频信息来确定环境区域中哪些地方存在障碍物,进而避开障碍物,该方案可以将盲杖扫不到的地方的障碍物确定出来,并且也可以将目标对象之前没到过的区域的障碍物确定出来,因此,可以解决现有技术中存在的准确度较低及活动范围受限的缺陷。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1A是根据本发明的实施例提出的向目标对象播放音频信息的一种流程图;
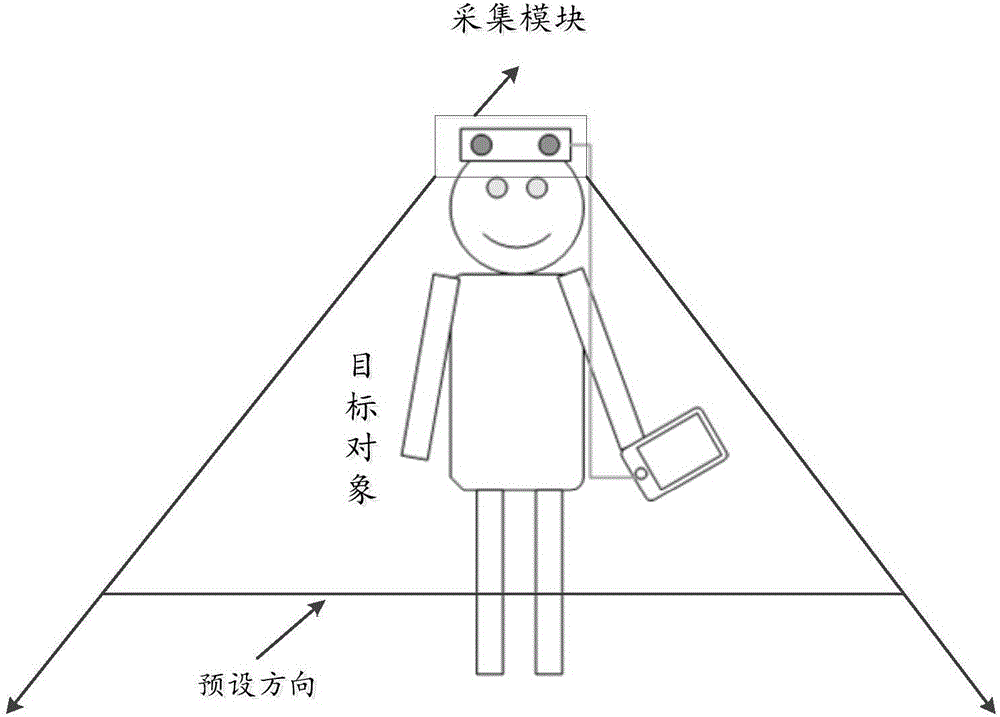
图1B为根据本发明的实施例提出的预设方向的示意图;
图1C为根据本发明的实施例提出的存在障碍物的场景的一种前视图;
图1D为根据本发明的实施例提出的存在障碍物的场景的一种俯视图;
图1E为根据本发明的实施例提出的第一类点和第二类点的一种示意图;
图1F为根据本发明的实施例提出的第一类点和第二类点的另一种示意图;
图1G为根据本发明的实施例提出的第一类点和第二类点的另一种示意图;
图1H为本发明实施例中所适用的坐标系的示意图;
图2A是根据本发明实施例提出的向目标对象播放音频信息的装置的示意图;
图2B是根据本发明实施例提出的采集模块的外部结构示意图;
图2C是根据本发明实施例提出的采集模块的内部结构示意图;
图2D是根据本发明实施例提出的向目标对象播放音频信息的装置的具体示意图;
图2E是根据本发明实施例提出的向目标对象播放音频信息的装置的具体示意图的一种应用场景示意图;
图2F是根据本发明实施例提出的向目标对象播放音频信息的装置的具体示意图的另一种应用场景示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
图1A示意性地示出了根据本发明实施方式的向目标对象播放音频信息的方法10的流程示意图。如图1A所示,该方法10可以包括步骤100、110、120和130。
步骤100:确定目标对象相对的方向为预设方向。
本发明实施例中,预设方向可以为目标对象持有的采集模块所能够采集的视线范围,如图1B所示,其中,采集模块可以为双目镜头,或者也可以为其他镜头设备,在此不做具体限定。
步骤110:确定处于所述预设方向且与所述目标对象相距预设距离的环境区域。
步骤120:确定所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面。
本发明实施例中,进一步地,确定所述环境区域针对所述目标对象的包络面之前,所述方法还包括如下操作:
采集所述环境区域的表象信息,所述表象信息包括能够用肉眼观察到的和/或能够用设备采集到的用于表征物体的电磁场光谱信息;
根据所述表象信息检测出所述环境区域中的路面,并基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物。
确定所述环境区域针对所述目标对象的包络面时,可选地,可以采用如下方式:
根据所述障碍物确定所述环境区域的包络面。
本发明实施例中,前面所描述的电磁场光谱信息可以是物体发射的,也可以是物体反射的,或者也可以是物体折射的,在此不做具体限定。
本发明实施例中,前面所描述的电磁场光谱信息可以包括无线电波信息、红外线信息、可见光信息、紫外线信息、X射线信息,及伽马射线信息中的至少一种,其中,可见光信息可以包括激光。
本发明实施例中,采集表象信息时,每秒可获取1帧至120帧。
本发明实施例中,根据所述表象信息检测出所述环境区域中的路面时,可选地,可以采用如下方式:
根据所述表象信息计算所述环境区域的三维信息;
根据所述三维信息检测出所述环境区域中的路面;
基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物时,可选地,可以采用如下方式:
基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物。
实际应用中,障碍物可以分为两种,一种为凹下去的障碍物,例如,地面上出现的坑;一种为地面以上的障碍物,例如,垂下来的树枝、前面的自行车。
因此,基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物时,可选地,可以采用如下方式:
将包括的任意一点A满足如下规则的物体作为凹陷障碍物:
d<d1
其中,所述d为所述任意一点A与所述路面的距离;所述d1为低于所述路面,且被认为是凹陷障碍物的最大阈值,所述d1<0;
将包括的任意一点A满足如下规则的物体作为凸起障碍物:
d2<d<d3
其中,所述d2为高于所述路面,且被认为是凸起障碍物的最小阈值,所述d2>0;所述d3为所述目标对象所需的安全空间的高度。
例如,d1为-5cm,则将朝向地面向下,且与路面之间的距离小于-5cm的障碍物作为凹陷障碍物。
又例如,d2为5cm,d3为1.75m,则将朝向地面向上,且与路面之间的距离大于5cm,且小于1.75m的障碍物作为凸起障碍物。
本发明实施例中,确定所述环境区域针对所述目标对象的包络面时,可选地,可以采用如下方式:
识别所述环境区域中包括障碍物的第一类子区域和不包括障碍物的第二类子区域;
针对所述第一类子区域中的每一个子区域,确定该区域包括的障碍物上与所述目标对象之间的距离为最小值的第一类点;
针对所述第二类子区域中的每一个子区域,确定该区域边界上与所述目标对象之间的距离为最大值的第二类点;
连接所述第一类点和所述第二类点构成包络面。
例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,图1C所示的示意图为该场景的前视图,图1D所示的示意图为该场景的俯视图,图1E为第一类点和第二类点的示意图。
又例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,其中,障碍物1位于左边,障碍物2位于右边,图1F为该场景下的第一类点和第二类点的示意图。
又例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,图1G为该场景下的第一类点和第二类点的示意图。
本发明实施例中,针对包括障碍物的环境区域的所述包络面满足如下规则:
E(x)=f(x,y*)
其中,所述y*满足如下规则:
其中,所述E(x)为针对包括障碍物的环境区域的包络面,所述x为所述环境区域中的物体的横坐标,所述y为所述环境区域中的物体的纵坐标。
需要说明的是,本发明实施例中可以采用如图1H所示的坐标系。
若所述环境区域中可被观测到的障碍物的集合为O0,O1,O2,…On,障碍物Ow(w=0,1,…n)的可被观测到的表面的点的集合为Sw,给定一个x,可以找到一个y*使得Sw(x,y*)在所有Sw(x,y)点里面距离所述目标对象最近,则E(x)={S0(x,y*),S1(x,y*),S2(x,y*),…Sn(x,y*)}。
所述f(x,y)为所述环境区域中可被观察到的曲面的方程的集合。
本发明实施例中,执行完步骤120之后,还可以执行步骤130:将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
其中,将所述包络面包括的点对应的音频信息向所述目标对象进行播放时,可选地,可以采用如下方式:
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量;或者
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调;或者
将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
其中,可选地,将所述包络面包括的点对应的音频信息向所述目标对象进行播放时,也可以采用如下方式:
确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放;或者
确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
当然,上述几种方式也可以结合使用,例如,确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量。
又例如,确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调。
又例如,确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
又例如,确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量。
又例如,确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调。
又例如,确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
这样,盲人听到从左到右或者从右到左的播放的音频信息时,可以在脑海中构造出前方哪些地方有障碍物,从而有效避障。
例如,播放图1E中的点构造出来的包络面时,以4444 11 444 333333的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,播放图1F中的点构造出来的包络面时,以1111 333333 22222的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,播放图1G中的点构造出来的包络面时,以1111 3 22222 33333的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,在类似走廊这样的场景中,从左到右的音频987611116789所对应的场景往往是一个走廊,这里以1代表低音,9代表高音,数字越大代表声音频率越高,反之声音频率越低,左边墙壁向远方延伸依次是9876的音频,1111是走廊向远方延伸的音频,6789是从远方回归到右边的墙壁的音频。通过实时播放这样的音频,盲人能够在脑海中恢复出类似走廊这样的场景。
需要说明的是,为了使得目标对象能够比较准确地确定出环境区域中的障碍物,可以将所述包络面包括的点对应的音频信息循环进行播放,例如每秒播放三次,或者多次,此处只是循环播放的例子,在此不做具体限定。
在该方案中,确定出处于预设方向且与目标对象相距预设距离的环境区域,再确定出环境区域针对目标对象的包络面,包络面是指环境区域中的部分或者全部子区域中与目标对象之间的距离为最小值和/或最大值的点构成的面,并将包络面包括的点对应的音频信息向目标对象进行播放,这样,目标对象可以根据听到的音频信息来确定环境区域中哪些地方存在障碍物,进而避开障碍物,该方案可以将盲杖扫不到的区域,及目标对象之前没到过的区域的障碍物都可以确定出来,因此,可以解决现有技术中存在的准确度较低及视障人士的活动范围受限的缺陷。
图2A示意性地示出了根据本发明实施方式的向目标对象播放音频信息的装置20的示意图,该装置包括确定模块200和播放模块210,其中:
确定模块200,用于确定目标对象相对的方向为预设方向;
所述确定模块200还用于,确定处于所述预设方向且与所述目标对象相距预设距离的环境区域;
所述确定模块200还用于,确定所述环境区域针对所述目标对象的包络面,所述包络面是指所述环境区域中的部分或者全部子区域中与所述目标对象之间的距离为最小值和/或最大值的点构成的面;
播放模块210,用于将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
本发明实施例中,预设方向可以为目标对象持有的采集模块220所能够采集的视线范围,如图1B所示,其中,采集模块220可以为双目镜头,或者也可以为其他镜头设备,在此不做具体限定。
本发明实施例中,进一步地,所述装置还包括采集模块220、检测模块230和识别模块240,其中:
所述采集模块220,用于采集所述环境区域的表象信息,所述表象信息包括能够用肉眼观察到的和/或能够用设备采集到的用于表征物体的电磁场光谱信息;
所述检测模块230,用于根据所述表象信息检测出所述环境区域中的路面;
所述识别模块240,用于基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物;
所述确定模块200确定所述环境区域针对所述目标对象的包络面时,可选地,具体为:
根据所述障碍物确定所述环境区域的包络面。
本发明实施例中,前面所描述的电磁场光谱信息可以是物体发射的,也可以是物体反射的,或者也可以是物体折射的,在此不做具体限定。
本发明实施例中,前面所描述的电磁场光谱信息可以包括无线电波信息、红外线信息、可见光信息、紫外线信息、X射线信息,及伽马射线信息中的至少一种,其中,可见光信息可以包括激光。
本发明实施例中,采集表象信息时,每秒可获取1帧至120帧。
本发明实施例中,所述检测模块230根据所述表象信息检测出所述环境区域中的路面时,具体为:
根据所述表象信息计算所述环境区域的三维信息;
根据所述三维信息检测出所述环境区域中的路面。
所述识别模块240基于检测出的路面和所述表象信息识别出所述环境区域中的障碍物时,可选地,具体为:
基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物。
实际应用中,障碍物可以分为两种,一种为凹下去的障碍物,例如,地面上出现的坑;一种为地面以上的障碍物,例如,垂下来的树枝、前面的自行车。
因此,所述识别模块240基于检测出的路面和所述三维信息识别出所述环境区域中的障碍物时,可选地,具体为:
将包括的任意一点A满足如下规则的物体作为凹陷障碍物:
d<d1
其中,所述d为所述任意一点A与所述路面的距离;所述d1为低于所述路面,且被认为是凹陷障碍物的最大阈值,所述d1<0;
将包括的任意一点A满足如下规则的物体作为凸起障碍物:
d2<d<d3
其中,所述d2为高于所述路面,且被认为是凸起障碍物的最小阈值,所述d2>0;所述d3为所述目标对象所需的安全空间的高度。
例如,d1为-5cm,则将朝向地面向下,且与路面之间的距离小于-5cm的障碍物作为凹陷障碍物。
又例如,d2为5cm,d3为1.75m,则将朝向地面向上,且与路面之间的距离大于5cm,且小于1.75m的障碍物作为凸起障碍物。
本发明实施例中,所述确定模块200确定所述环境区域针对所述目标对象的包络面时,可选地,具体为:
识别所述环境区域中包括障碍物的第一类子区域和不包括障碍物的第二类子区域;
针对所述第一类子区域中的每一个子区域,确定该区域包括的障碍物上与所述目标对象之间的距离为最小值的第一类点;
针对所述第二类子区域中的每一个子区域,确定该区域边界上与所述目标对象之间的距离为最大值的第二类点;
连接所述第一类点和所述第二类点构成包络面。
例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,图1C所示的示意图为该场景的前视图,图1D所示的示意图为该场景的俯视图,图1E为第一类点和第二类点的示意图。
又例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,其中,障碍物1位于左边,障碍物2位于右边,图1F为该场景下的第一类点和第二类点的示意图。
又例如,目标对象前方的环境区域中有两个障碍物:障碍物1、障碍物2,图1G为该场景下的第一类点和第二类点的示意图。
本发明实施例中,针对包括障碍物的环境区域的所述包络面满足如下规则:
E(x)=f(x,y*)
其中,所述y*满足如下规则:
其中,所述E(x)为针对包括障碍物的环境区域的包络面,所述E(x)为所述包络面,所述x为所述环境区域中的物体的横坐标,所述y为所述环境区域中的物体的纵坐标。
需要说明的是,本发明实施例中可以采用如图1H所示的坐标系。
若所述环境区域中可被观测到的障碍物的集合为O0,O1,O2,…On,障碍物Ow(w=0,1,…n)的可被观测到的表面的点的集合为Sw,给定一个x,可以找到一个y*使得Sw(x,y*)在所有Sw(x,y)点里面距离所述目标对象最近,则E(x)={S0(x,y*),S1(x,y*),S2(x,y*),…Sn(x,y*)}。
所述f(x,y)为所述环境区域中可被观察到的曲面的方程的集合。
本发明实施例中,所述播放模块210将所述包络面中点对应的音频信息向所述目标对象进行播放时,可选地,具体为:
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述包络面包括的第一类点对应的距离值大于所述包络面包括的第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量;或者
将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调;或者
将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
其中,所述播放模块210将所述包络面包括的点对应的音频信息向所述目标对象进行播放时,具体为:
确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放;或者
确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的音频信息向所述目标对象进行播放。
当然,上述几种方式也可以结合使用,例如,所述播放模块210确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量。
又例如,所述播放模块210确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调。
又例如,所述播放模块210确定出所述包络面相对于所述目标对象从左到右的方向,并按照确定出的从左到右的方向,将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
又例如,所述播放模块210确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音幅度向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音量低于所述第二类点播放的第二音量。
又例如,所述播放模块210确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的对应的距离值不同的点对应的音频信息以不同声音频率向所述目标对象进行播放,所述第一类点对应的距离值大于所述第二类点对应的距离值,所述第一类点播放的第一音调低于所述第二类点播放的第二音调。
又例如,所述播放模块210确定出所述包络面相对于所述目标对象从右到左的方向,并按照确定出的从右到左的方向,将所述包络面包括的点对应的距离值以语音形式向所述目标对象进行播放。
这样,盲人听到从左到右或者从右到左的播放的音频信息时,可以在脑海中构造出前方哪些地方有障碍物,从而有效避障。
例如,所述播放模块210播放图1E中的点构造出来的包络面时,以4444 11 444 333333的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,所述播放模块210播放图1F中的点构造出来的包络面时,以1111 333333 22222的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,所述播放模块210播放图1G中的点构造出来的包络面时,以1111 3 22222 33333的声音幅度进行播放,数字越大表示的声音幅度越大,这样,目标对象(即盲人)在听到播放的音频信息后,脑海中构造出前方障碍物所处的位置。
又例如,在类似走廊这样的场景中,从左到右的音频987611116789所对应的场景往往是一个走廊,这里以1代表低音,9代表高音,数字越大代表声音频率越高,反之声音频率越低,左边墙壁向远方延伸依次是9876的音频,1111是走廊向远方延伸的音频,6789是从远方回归到右边的墙壁的音频。通过实时播放这样的音频,盲人能够在脑海中恢复出类似走廊这样的场景。
需要说明的是,为了使得目标对象能够比较准确地确定出环境区域中的障碍物,可以将所述包络面包括的点对应的音频信息循环进行播放,例如每秒播放三次,或者多次,此处只是循环播放的例子,在此不做具体限定。
需要说明的是,本发明实施例中的向目标对象播放音频信息的装置20或者采集模块220可以为双目镜头,如图2B、2C所示,也就是说,双目镜头可以具备装置20的所有功能,或者,也可以只具备采集模块220的功能,在此不做具体限定,其中图2B为双目镜头的外部结构,图2C为双目镜头的内部结构。
本发明实施例中,向目标对象播放音频信息的装置20中还可以添加结构光传感器、飞行时间(ToF)传感器、激光(LiDAR)传感器、加速度计、磁力计、陀螺仪在内的惯性传感器中的一种或者任意组合,结构光传感器、飞行时间(ToF)传感器、激光(LiDAR)传感器、加速度计、磁力计、陀螺仪在内的惯性传感器在本方案中所起的作用可以为各个部件目前能够实现的功能,在此不进行一一详述。
本发明实施例中,向目标对象播放音频信息的装置20可以是手机、平板电脑、笔记本电脑、嵌入式系统、以及基于专用芯片(包括FPGA(Field-Programmable Gate Array,现场可编程门阵列),ASIC((Application Specific Integrated Circuits,专用集成电路)在内)的系统中的至少一种。
本发明实施例中,采集模块220可以为单独的模块,装置20中除采集模块220之外的其他模块可以位于终端中,然后,采集模块220和终端通过USB(Universal Serial Bus,通用串行总线)接口相连,如图2D所示。
图2D所示的装置20在具体应用中,可以如图2E所示,目标对象,例如盲人将采集模块220戴在头上,将终端持在手中,或者,也可以如图2F所示,目标对象,例如盲人将采集模块220戴在其他地方,如胸前或者腰上,将终端持在手中。
在该方案中,确定出处于预设方向且与目标对象相距预设距离的环境区域,再确定出环境区域针对目标对象的包络面,包络面是指环境区域中的部分或者全部子区域中与目标对象之间的距离为最小值和/或最大值的点构成的面,并将包络面包括的点对应的音频信息向目标对象进行播放,这样,目标对象可以根据听到的音频信息来确定环境区域中哪些地方存在障碍物,进而避开障碍物,该方案可以将盲杖扫不到的区域,及目标对象之前没到过的区域的障碍物都可以确定出来,因此,可以解决现有技术中存在的准确度较低及视障人士的活动范围受限的缺陷。
在此提供的方法和装置不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类装置所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的装置中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个装置中。可以把实施例中的若干模块组合成一个模块或模块或组件,以及此外可以把它们分成多个子模块或子模块或子组件。除了这样的特征和/或过程或者模块中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或模块进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本发明的各个装置实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的装置中的一些或者全部模块的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的模块权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
- 还没有人留言评论。精彩留言会获得点赞!