数据防泄露系统中一种文档指纹提取及匹配方法与流程
本发明涉及数据防泄漏领域,特别是指数据防泄露系统中一种文档指纹提取及匹配方法。
背景技术:
电子文档、数字化产品在办公、教学等工作中给人们方便的同时,也存在着巨大的安全风险。现有的数字版权保护技术主要基于现代密码学理论,如加密系统、数字签名系统等。它主要解决的是数字产品在存储和传输过程中安全问题。但是一旦这些数字产品内容被解密后,就可以被复制、传播和泄露,必须使用基于内容识别的数据防泄露(DLP)技术进行防护。
传统的数据防泄露技术主要依赖于关键词匹配和正则表达式匹配,这些方法有很大的局限性。比如对待识别的数据进行简单地增删改后,这些传统的匹配方法就会失效,导致无法正常对敏感数据进行有效的防护了。
“文档指纹”匹配可确保准确检测以文档形式存储的非结构化数据,文件格式包括Microsoft Word文件、PowerPoint文件、PDF文档等等。受保护的文档包括财务、并购文档,以及其他敏感或专有信息。DLP系统会利用指纹算法为文档创建指纹特征,以匹配原始文档的已检索部分、草稿或不同版本的受保护文档。
技术实现要素:
本发明提出数据防泄露系统中一种文档指纹提取及匹配方法,其特殊之处是使用两次滑动窗口的方式计算哈希值,该哈希值作为文档指纹构成部分,指纹匹配计算方法简洁高效。
本发明的技术方案是这样实现的:
数据防泄露系统中一种文档指纹提取及匹配方法,包括以下步骤:
S1)文档指纹提取:根据文件头信息识别出相应类型的文档文件,解析并保存为文本文件,并对文本文件进行规格化预处理;
S2)指纹计算:
S21)对步骤S1)预处理过后的文本串s,长度为n,选取一个长度窗口为k(O<k<n)在文本串s上滑动,每次滑动一个固定的步长;
S22)通过滑动得到一个子字符串序列,对每个子字符串,利用特定的哈希算法,分别计算哈希值,形成一个哈希值序列;
S23)选取长度为w的另一个窗口,用来按步长分割步骤S22)所得到的哈希值序列,总共分割成n-k-w+2个哈希值子序列;
S24)分别对步骤S23)得到的每个子序列,通过一种算法提取出一个最能代表这个子序列的哈希值,作为这个子序列的局部指纹;
S3)设步骤S2)得到的指纹为FP2,源文档的指纹为FP1,计算FP2和FP1的交集进行指纹匹配,目标文档的匹配源文件的比例为:
r=((FP1∩FP2)/FP1)*100%;
如果r大于实现设定的阈值(如75%),则认为该目标文档是一个敏感文件。
上述技术方案中,步骤S1)中,根据文件头信息识别出的相应类型的文档文件包括但不限于.doc(x)、.ppt(x)、.txt或者.pdf类型的文档文件。
上述技术方案中,步骤S1)中,所述对文本文件进行规格化预处理,具体包括去除页眉页脚信息、去除页码信息,去掉空行、多余的空格、标点符号信息,还包括编码统一化。
其数据预处理根据不同的文件类型会有所不同,比如Word文档会去除页眉页脚、页码等信息。但是比较通用的方法是去掉空行、多余的空格、标点符号等信息。预处理还有一项工作就是编码统一化,比如统一使用UTF-8编码,具体编码不做要求只要在匹配的时候使用的统一编码格式就可以了。
上述技术方案中,步骤S24)中,取模法、取最大值法或者取最小值法,取平均数法,优选采用取最小值法。
这些局部指纹联合起来组成一个集合,这个集合就是整个文档的指纹特征信息。由于这个局部指纹信息可以看做是这个子序列的摘要,具有随机性,另外加上集合的无序性,保证了指纹到源数据的不可逆性。
现有公开的指纹计算方法,只是简单的计算每个数据段的哈希值,这就导致指纹数据特别大,不利于保存和传输,并且还保持原文以及对应原文哈希值序列顺序,导致有被破解的可能。同时在匹配的时候也会花费大量的时间,效率较低。本发明的文档指纹提取及匹配方法有以下优点:
(1)计算复杂度不高,提高指纹提取效率;
(2)生成的指纹数据小(源数据和指纹文件大小比平均为40∶1),便于保存和传输;
(3)数据匹配是指纹与指纹之间的比对,不需要源文档,防止二次泄密;
(4)指纹的哈希值是不可逆的,即使拿到了指纹数据也不能破解出源文档,保证了源文件的机密性;
(5)指纹匹配方法简洁有效,无需进行大量的比对计算。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
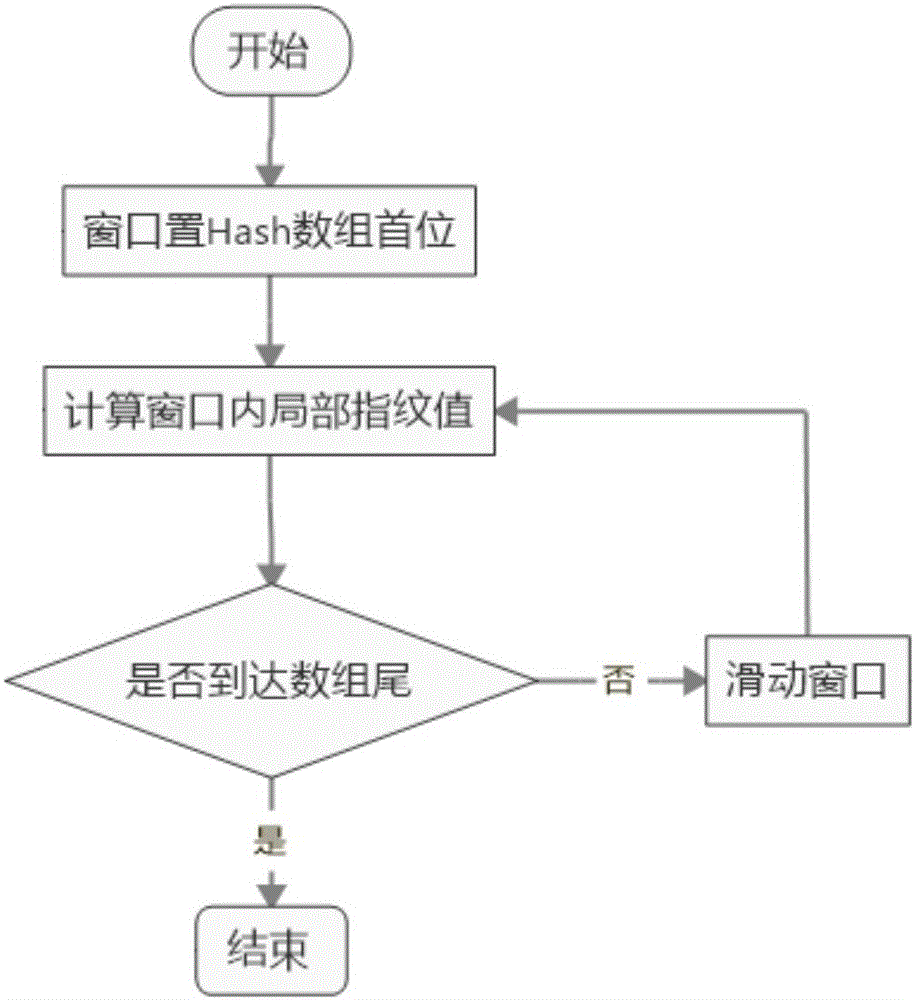
图1是本发明的文档指纹提取及匹配方法指纹计算中第一次滑动窗口并计算哈希值的流程示意图。
图2是本发明的文档指纹提取及匹配方法指纹计算中第二次滑动窗口计算哈希值并得到局部指纹的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1和图2所示,本发明的数据防泄露系统中一种文档指纹提取及匹配方法,包括以下步骤:
S1)文档指纹提取:根据文件头信息识别出相应类型的文档文件,解析并保存为文本文件,并对文本文件进行规格化预处理;
S2)指纹计算:
S21)对步骤S1)预处理过后的文本串s,长度为n,选取一个长度窗口为k(0<k<n)在文本串s上滑动,每次滑动一个固定的步长;
S22)通过滑动得到一个子字符串序列,对每个子字符串,利用特定的哈希算法,分别计算哈希值,形成一个哈希值序列;
S23)选取长度为w的另一个窗口,用来按步长分割步骤S22)所得到的哈希值序列,总共分割成n-k-w+2个哈希值子序列;
S24)分别对步骤S23)得到的每个子序列,通过一种算法提取出一个最能代表这个子序列的哈希值,作为这个子序列的局部指纹;
S3)设步骤S2)得到的指纹为FP2,源文档的指纹为FP1,计算FP2和FP1的交集进行指纹匹配,目标文档的匹配源文件的比例为:
r=((FP1∩FP2)/FP1)*100%;
如果r大于实现设定的阈值(如75%),则认为该目标文档是一个敏感文件。
上述技术方案中,步骤S1)中,根据文件头信息识别出的相应类型的文档文件包括但不限于.doc(x)、.ppt(x)、.txt或者.pdf类型的文档文件。
上述技术方案中,步骤S1)中,所述对文本文件进行规格化预处理,具体包括去除页眉页脚信息、去除页码信息,去掉空行、多余的空格、标点符号信息,还包括编码统一化。
其数据预处理根据不同的文件类型会有所不同,比如Word文档会去除页眉页脚、页码等信息。但是比较通用的方法是去掉空行、多余的空格、标点符号等信息。预处理还有一项工作就是编码统一化,比如统一使用UTF-8编码,具体编码不做要求只要在匹配的时候使用的统一编码格式就可以了。
上述技术方案中,步骤S24)中,取模法、取最大值法或者取最小值法,取平均数法,优选采用取最小值法。
这些局部指纹联合起来组成一个集合,这个集合就是整个文档的指纹特征信息。由于这个局部指纹信息可以看做是这个子序列的摘要,具有随机性,另外加上集合的无序性,保证了指纹到源数据的不可逆性。
现有公开的指纹计算方法,只是简单的计算每个数据段的哈希值,这就导致指纹数据特别大,不利于保存和传输,并且还保持原文以及对应原文哈希值序列顺序,导致有被破解的可能。同时在匹配的时候也会花费大量的时间,效率较低。本发明的文档指纹提取及匹配方法有以下优点:
(1)计算复杂度不高,提高指纹提取效率;
(2)生成的指纹数据小(源数据和指纹文件大小比平均为40∶1),便于保存和传输;
(3)数据匹配是指纹与指纹之间的比对,不需要源文档,防止二次泄密;
(4)指纹的哈希值是不可逆的,即使拿到了指纹数据也不能破解出源文档,保证了源文件的机密性;
(5)指纹匹配方法简洁有效,无需进行大量的比对计算。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!