一种使用深度全卷积编码‑解码网络的图像降噪方法与流程
本发明涉及一种图像降噪方法,尤其是涉及一种使用深度全卷积编码-解码网络的图像降噪方法。
背景技术:
图像降噪是低层视觉领域中的一个经典问题,它在图像处理和计算机视觉领域得到了广泛地研究,但目前仍然是一个具有挑战性的问题。传统的图像降噪方法主要是基于小波收缩、全差分或图像的先验知识的方法。其中,基于小波收缩的方法将小波变换系数建模为拉普拉斯分布模型。基于全差分的方法假设图像的梯度符合拉普拉斯分布。基于图像先验知识的方法中的一个代表就是基于字典的方法。受益于K-SVD算法的成功,学习用于图像降噪的字典的方法已经获得了广泛的研究。
图像降噪另一个比较活跃也可能更有前景的研究方向是基于神经网络的方法。基于神经网络的方法与其它方法的一个最大不同点就是它是从训练数据中直接学习得到用于降噪的参数,而不是依赖于先验知识。堆叠降噪自动编码器是其中一个最为著名的用于图像降噪的深度神经网络模型。它是堆叠自动编码器的一种扩展,最初设计时是为了将其用于无监督特征学习。降噪自动编码器可以堆叠起来组成一个深度的网络结构。还有一些基于神经网络的降噪方法使用多层感知器或卷积神经网络。研究发现,越深的网络结构,越多的训练数据集可以帮助神经网络获得越好的降噪性能。使用神经网络进行图像降噪的一个优势是模型可以直接从数据中学习降噪参数,也就是说可以进行端到端的学习而不需要对自然图像做出假设。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种使用神经网络结构进行的深度全卷积编码-解码网络的图像降噪方法。
本发明的目的可以通过以下技术方案来实现:
一种使用深度全卷积编码-解码网络的图像降噪方法,该方法采用神经网络模型进行图像降噪,所述模型的输入为带噪声图像,输出为降噪后的图像,其特征在于,所述的模型采用对称的编码-解码网络结构,包括依次连接的N个卷积层和N个解卷积层,其中第i个卷积层与第N+1-i个解卷积层为对称关系,i=1,2…N,卷积层作为特征提取器,用于对图像的主要内容进行编码并消减噪声,解卷积层用于对图像的抽象内容进行解码并对图像的细节内容进行恢复。
所述的模型还包括跳跃连接结构,所述的跳跃连接结构用于连接相互对应的卷积特征映射与解卷积特征映射,所述的卷积特征映射为相邻两个卷积层之间的卷积特征映射,所述的解卷积特征映射为相邻两个解卷积层之间的解卷积特征映射,具体的,第i个卷积层与第i+1个卷积层之间的卷积特征映射,对应第N+1-i个解卷积层与第N+2-i个解卷积层之间的解卷积特征映射,这些跳跃连接将整个网络结构分割成几个模块,来自卷积层的响应通过这些跳跃连接直接传递给对应的镜像解卷积层。
所述的跳跃连接结构每隔2~3个卷积层设置一个,即:若第i个卷积层后设置一个跳跃连接结构,则第i+2或第i+3个卷积层后设置一个跳跃连接结构。
模型训练过程包括:给定N个训练样本对Xi,Yi,Xi为第i幅带噪声图像,Yi是对应的第i幅无噪声图像,模型的目标为下式的最小值,
其中,为参数为Θ时得到的无噪声图像与干净图像之间的均方根误差,Θ为卷积和解卷积核的参数,N为训练集中样本个数。
该方法在多个方向上对图像进行降噪,用于平滑图像,具体为:对模型中的滤波器核进行旋转、镜像和/或翻转操作,得到不同的滤波器核,分别利用不同的滤波器核将图像进行前向传播,得到多个输出图像,再对多个输出图像求均值,得到平滑的降噪图像。
不同于以往的方法,本发明的网络结构是一个基于跳跃连接的编码-解码框架,其中使用卷积和解卷积操作进行图像降噪,使用跳跃连接结构解决模型训练问题。该结构在网络层数很深的时候,也可以进行有效的端到端的训练,并取得比已有方法更好的降噪性能。
与现有技术相比,本发明具有以下优点:
(1)提出了一种非常深的用于图像降噪的网络结构,该网络结构由对称的卷积层和解卷积层构成,其中的卷积层作为特征提取器,在对图像的主要内容进行编码的过程中同时消减噪声,之后,解卷积层用于对图像的抽象内容进行解码并对图像的细节内容进行恢复,可最大程度保留图像的细节内容。
(2)为了更好地训练深度网络,在卷积层和与之对应的解卷积层之间增加跳跃连接结构。这种跳跃连接有助于将梯度反向传播到底层并使图像细节得以传播到顶层,同时使训练过程更加容易和高效,利于网络层次的加深,从而带来更优的降噪性能。
(3)跳跃连接结构每隔2~3个卷积层设置一个,可达到理想降噪效果。
(4)本发明中使用的网络模型中的滤波器核只用于消除噪声,对于图像内容的方向并不敏感,在多个方向上对图像进行降噪,可平滑图像。
(5)由于卷积层和解卷积层是对称的,所以输入图像可以是任意尺寸的,对图像尺寸无要求。
附图说明
图1为本发明提出的图像降噪模型的网络结构图;
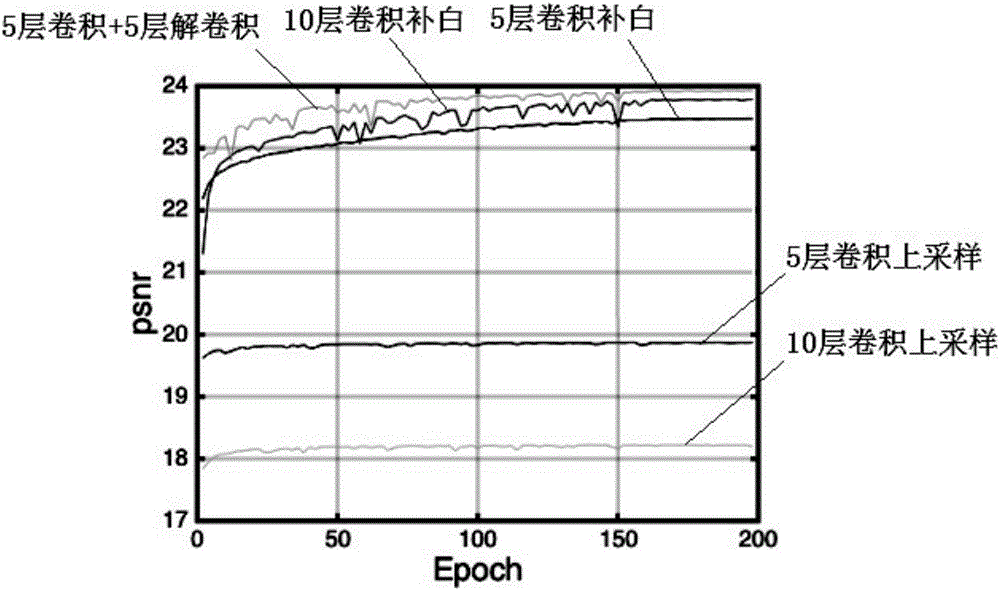
图2为全卷积网络和卷积-解卷积网络的性能对比图;
图3(a)~图3(f)为10层的全卷积网络降噪效果的可视化图,依次为:干净图像、带噪声图像、第2层卷积层的输出、第5层卷积层的输出、第8层卷积层的输出、第10层卷积层的输出;
图4(a)~图4(f)为10层卷积-解卷积网络降噪效果的可视化图,依次为;干净图像、带噪声图像、第2层卷积层的输出、第5层卷积层的输出、第3层解卷积层的输出、第5层解卷积层的输出;
图5为卷积-解卷积网络结构中一个模块的结构图;
图6为5种网络结构模型在训练过程中的训练损失;
图7为5种网络结构模型在验证集上的峰值信噪比(PSNR);
图8为跳跃连接结构中采用不同跳跃步长的网络结构在训练过程中的损失;
图9为跳跃连接结构中采用不同跳跃步长的网络结构在验证集上的峰值信噪比(PSNR);
图10为14张用于测试降噪性能的通用测试图像;
图11(a)~图11(c)为噪声级别为30时,各种降噪方法分别在“飞机”、“摄影师”和“Lena”图像上的降噪结果的可视化;
图12(a)~图12(c)为噪声级别为70时,各种降噪方法分别在“飞机”、“摄影师”和“Lena”图像上的降噪结果的可视化;
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
一种使用深度全卷积编码-解码网络的图像降噪方法,模型的输入是一幅带噪声图片,输出是降噪后的干净图片。该模型具有一种非常深的编码-解码框架。与传统的使用图像的先验知识的方法不同,该框架直接从训练数据集中学习得到将输入的带噪声图像映射到干净的输出图像的端到端的全卷积映射关系。该网络模型由多层卷积和解卷积操作构成。由于越深的网络训练越困难,本方法使用层间跳跃连接结构将卷积层和与之对称的解卷积层连接起来,使训练收敛得更快并且可以获得一个更高质量的局部最优解。
模型框架如图1所示,主要包含一系列卷积层和与之对称的解卷积层。该网络结构由对称的卷积层(编码器)和解卷积层(解码器)构成。在每隔几层(图中和实施例中的设置是2层,也可以是其它设置)之间有跳跃连接结构将卷积特征映射和与之镜像对应的解卷积特征映射连接起来。这些跳跃连接将整个网络结构分割成几个模块。来自卷积层的响应通过这些跳跃连接直接传递给对应的镜像解卷积层。
卷积层作为特征提取器,在保留图中主要内容的同时,又消减了其中的噪声。输入的噪声图像前向传播通过卷积层之后就转化成一幅干净的图像,但在该过程中图像内容的细节信息可能会有所损失。因此,解卷积层被用来对图像的细节信息进行恢复。解卷积层的最终输出就是所要的降噪后的干净图像。由于卷积层和解卷积层是对称的,所以输入图像可以是任意尺寸的。
另外,在卷积层和它对应的镜像解卷积层之间增加了一个跳跃连接结构,在每个卷积和解卷积层之后有修正层。在获得卷积层特征映射和对应的解卷积层特征映射之后,通过跳跃连接结构在两个特征映射之间进行元素级别的加和,之后经过修正层后传递给下一层。
在卷积层中,一个滤波器窗中的多个输入激活值被融合起来输出一个单独的激活值。与该过程相反,解卷积层将一个输入激活值与多个输出联系起来。与传统的使用卷积层和解卷积层进行语义分割的模型不同,本发明中所提出的模型完全由卷积层和解卷积层构成,不包含池化和逆池化过程。原因是图像降噪的目的是为了在保留图像细节的同时消除噪声而不是为了学到用于分类的图像抽象。不同于分割或识别等高层应用,池化倾向于使降噪性能恶化。
通过简单地将解卷积层替换为卷积层,就得到类似于最近提出的全卷积神经网络的结构。但是,在全卷积网络和本发明所提出的网络之间存在着本质的差别。在全卷积网路中,噪声是一步一步消除的,也就是说经过一层噪声减少一点。在该过程中,图像内容的细节信息可能会丢失。然而,在本发明提出的模型中,卷积层保留了图像的主要内容。之后,解卷积层被用于补偿卷积过程中损失的图像细节。两种模型的对比实验结果见图2、图3(a)~图3(f)、图4(a)~图4(f)所示。图2中,全卷积网络有5层和10层两种结构,对输入图像使用补白(padding)或上采样(upsampling)操作获得同样尺寸的输入输出。卷积-解卷积网络由5层的卷积层和5层的解卷积层构成,在该结构中不使用跳跃连接结构。本发明使用的网络模型由5层卷积层和5层解卷积层构成,不使用跳跃连接结构。参与对比的全卷积网络模型分为5层和10层两种网络结构。在全卷积网络中,使用补白(padding)和上采样操作来使输入和输出具有保持相同的尺寸。其它所有训练参数都保持相同。实验结果表明,本发明中提出的模型的降噪性能优于全卷积网络模型。从图2、图3(a)~图3(f)、图4(a)~图4(f)中分析可知,在全卷积网络中噪声是逐层减少的,而在本发明的模型中,卷积层可以捕获图像的主要内容,解卷积层可以有效地对卷积层中丢失的图像的细节信息进行修复。
要学习从噪声图像到干净图像的端到端的映射,需要对卷积和解卷积核的权重进行估计。通过最小化输出图像和干净图像之间的欧式损失来实现这一过程。具体来说,给定N个训练样本对Xi、Yi,其中Xi是第i幅带噪声图像,Yi是其对应的第i幅干净图像,模型的训练就转化为最小化下面的均方根误差(MSE):
在训练阶段,该框架首先从训练数据集中学习得到将输入的带噪声图像映射到干净的输出图像的端到端的全卷积映射关系。该网络模型由多层卷积和解卷积操作构成。其中,卷积层作为特征提取器,在保留图中主要内容的同时,又消减了其中的噪声。输入的噪声图像前向传播通过卷积层之后就转化成一幅干净的图像,但在该过程中图像内容的细节信息会有所损失。因此,解卷积层被用来对图像的细节信息进行恢复。解卷积层的最终输出就是所要的降噪后的干净图像。
在浅层网络中,解卷积可以恢复图像细节。但是,随着网络结构的加深或使用一些类似最大池化等操作时,由于在卷积过程中丢失了太多的细节信息,解卷积操作的效果并不好。另外,随着网络结构的加深,梯度消失问题使得模型的训练变得困难。
为了解决这两个问题,本发明提出在卷积层和对应的解卷积层之间增加跳跃连接结构,如图1所示,它由多个模块组成。其中,单个模块的组成如图5所示。图中实线矩形和虚线矩形分别表示卷积和解卷积层,表示特征映射中对应元素之间的加和操作。之所以使用这种连接结构有两个原因,首先,如前所述,随着网络结构的加深,图像细节信息大量损失,这使解卷积操作进行细节修复变得困难。而通过跳跃连接传递过来的特征映射携带着大量的图像细节信息,这有助于解卷积操作修复得到一个更好的干净图像。另外,由于反向传播过程中梯度消失问题的存在,越深的网络训练越困难,跳跃连接也可以使梯度反向传播到底层,这使得训练更深的网络模型变得更加容易,可以设计更深的网络结构用于提升图像的降噪效果。
特征映射(feature map)就是输入图像经过一个特征提取层后所得到的特征输出。输入图像通过一层神经网络就会得到一个特征输出,这个特征输出就叫特征映射,实质上就是特征数据的一个集合,就相当于一个二维数组,里面存放的每个数据点就是输入图像经过神经网络处理后得到的特征,每经过一层神经网络就会得到一个。
每隔2~3个卷积层设置一个跳跃连接结构,跳跃步长也可以设置为其它。使用跳跃连接结构的优点是可以解决深层网络在训练过程中的梯度消散问题。越深的网络往往可以获得越好的性能,但之前的网络结构都不会很深,因为在训练过程中需要将误差反向传播到前面的层,若网络太深,误差在传递过程中越来越小,网络无法进行有效训练,即梯度消散问题。而采用跳跃连接结构之后,就可以直接将误差从后面的层传到前面,就解决了深层网络训练困难的问题,这样就可以设计很深的网络结构来获得理想的降噪性能。
与直接学习从输入X到输出Y的映射不同,本发明中所使用的网络模型拟合的是图像降噪问题的残差,也就是F(X)=Y-X。在网络的内部模块中使用这种学习策略可以获得更加高效的训练过程。通过跳跃连接,每两个卷积层和它们对应的镜像解卷积层连接起来,也就是说跳跃步长可以设置为2。当然,其它设置也是可以的。这种跳跃连接结构使得模型更容易训练并且可以通过增加网络层数的深度来获得更好的降噪性能。
本发明的模型被用于对任意尺寸的图像进行降噪,给定一个用于测试的带噪声图像,只是将其简单地前向传播通过网络就可以获得一个比当前其它降噪方法还要好的结果。为了获得一个更加平滑的降噪结果,本发明中提出在多个方向上对噪声图像进行降噪。由于本发明中使用的网络模型中的滤波器核只用于消除噪声,对于图像内容的方向并不敏感,因此可以将滤波器核进行旋转、镜像、翻转等操作,然后将一幅图像进行多次前向传播得到多个输出,再对多个输出求均值得到一个平滑的降噪图像。
本实施例的效果可以通过以下实验进一步说明:
1.训练数据
本实施例使用的用于评估模型性能的数据集是灰度图像。当然,该模型同样适用于彩色图像。本实施例使用300张来自伯克利分割数据集的图像来生成训练集。对于每幅图像,从中采样50*50大小的不重叠图像面片作为类标。在实验中发现,较小的图像面片尺寸会导致较差的性能,这可能是因为太少的像素不足以代表噪声的分布。对于每个图像面片,为其增加高斯噪声后作为噪声图像。为了获得大量的训练数据集,一张图像面片被使用多次来生成多幅噪声图像,最终可以获得一个包含50万幅图像的训练数据集。对于不同的噪声级别,本实施例使用相应的训练数据集来训练对应的模型。本实施例使用的噪声是常用的均值为0,标准差为σ的高斯噪声。噪声级别σ包括10、30、50和70。
2.网络模型
本发明中提出的方法记为“RED-Net”(Residual Encoder Decoder Networks)。基于图1中的网络结构,在本实验中设计了三个网络模型,分别为RED10、RED20和RED30。RED10包含5个卷积层和5个解卷积层,但不包含跳跃连接结构。RED20包含10个卷积层和10个解卷积层,具有步长为2的跳跃连接结构。RED30包含15个卷积层和15个解卷积层,具有步长为2的跳跃连接结构。
20层和30层的RED-Net网络结构具体配置信息如表1所示。其中“conv3”和“deconv3”分别代表卷积和解卷积核的尺寸为3*3,128、256和512表示经过每一层卷积或解卷积之后得到的特征映射的数量。“c”是输入输出图像的通道数,由于本实施例进行的实验是在灰度图像上进行测试的,所以c=1。当然,该算法可以直接应用于彩色图像。
表1 RED-Net20和RED-Net30网络结构具体配置信息
3.跳跃连接结构
为了验证跳跃连接结构对降噪性能的影响,本实施例中对比了5种不同的网络结构的降噪性能,分别是10层、20层和30层3种无跳跃连接结构的网络模型和20层、30层两种有跳跃连接结构的网络模型。结果如图6和图7所示。图6为5种网络结构模型在训练过程中的训练损失;图7为5种网络结构模型在验证集上的峰值信噪比(PSNR)。在训练集上,随着网络层数的加深,无跳跃连接结构的网络模型训练误差越来越大,有跳跃连接结构的网络模型训练误差越来越小。在验证集上,对于没有跳跃连接结构的网络模型,越深的网络有越低的峰值信噪比,对于30层的网络模型,甚至出现了过拟合。然而,使用跳跃连接结构的网络模型随着网络层数的加深,可以获得较高的峰值信噪比和较好的泛化性能。
对于不同的跳跃连接步长(2、4、7),对比结果如图8和图9所示。图8为跳跃连接结构中采用不同跳跃步长的网络结构在训练过程中的损失;图9为跳跃连接结构中采用不同跳跃步长的网络结构在验证集上的峰值信噪比(PSNR)。结果表明,较小的跳跃步长可以获得较好的降噪性能,因为较小的跳跃步长有助于梯度反向传播到底层,同时小的跳跃步长可以传播更多的信息。
4.降噪性能分析
在本部分,本发明中提出的RED10、RED20和RED30降噪模型的降噪效果将与BM3D、NCSR、EPLL、PCLR、PDPD和WMMN 6种降噪模型进行对比。降噪性能评估实验在两个数据集上进行,一个是14张通用的基准图像(如图10所示),一个是伯克利图像分割数据集。
当噪声级别分别为10、30、50和70时,在14张通用的基准图像上的降噪效果见表2和表3所示。其中,表2是在峰值信噪比(PSNR)上的评估结果,表3是在结构相似性(SSIM)上的评估结果。从实验数据可知,本发明所提出的无跳跃连接结构的10层的卷积-解卷积网络所取得的降噪性能早已超过了其它降噪方法,这说明本发明所提出的将卷积和解卷积结合起来用于图像降噪的方法可以取得理想的降噪效果。另外,随着网络结构的加深,本发明中所提出的跳跃连接结构可以进一步提升降噪性能,它所取得的降噪效果超过了目前最好的降噪方法。最后,实验结果表明,图像中所加的噪声越复杂,本发明所提出的模型所取得的降噪性能的提升效果越明显。
表2各降噪方法在多种噪声级别的噪声图像上所取得的峰值信噪比
表3各降噪方法在多种噪声级别的噪声图像上所取得的结构相似性
对于伯克利图像分割数据集,其中的300幅图像用作训练数据,剩余的200幅图像用作对降噪性能的测试。当噪声级别σ分别为10、30、50和70时,降噪效果如表4所示。从中可知,本发明中所提出的方法取得了优于其它方法的降噪效果。
表4各降噪方法在伯克利图像分割数据集上的降噪结果
各种降噪方法的降噪结果的可视化见图11和图12所示。图11(a)~图11(c)为噪声级别为30时,各种降噪方法在“飞机”、“摄影师”和“Lena”图像上的降噪结果的可视化;图12(a)~图12(c)为噪声级别为70时,各种降噪方法在“飞机”、“摄影师”和“Lena”图像上的降噪结果的可视化。其中,在每幅图像中,从左上角到右下角的图像依次是:噪声图像,BM3D,NPLL,NCSR,PCLR,PGPD,WNNM,RED10,RED20,RED30。
- 还没有人留言评论。精彩留言会获得点赞!